Learn more about Search Results k-means - Page 4

- You may be interested
- 増強と生産性のための人工知能
- DevOpsGPTとは、LLMとDevOpsツールを組み...
- 「DeepMindがデスクトップコンピュータ上...
- 私たちの原則がAlphaFoldの公開を定義する...
- ピクトリーレビュー(2023年7月):最高の...
- 「マーク・A・レムリー教授による生成AIと...
- 「オープンソースLLMの完全ガイド」
- ミリモバイルの自律走行ロボットは、光と...
- 線形代数の鳥瞰図:地図の尺度—行列式
- 「PySpark UDFを使用して合成テーブルの列...
- CycleGANによる画像から画像への変換
- 「不正行為の恐れにもかかわらず、学校はC...
- 「パフォーマンスと使いやすさを向上させ...
- プリンストン大学の研究者が、MeZOという...
- 「SQLで「NOT IN」を使用する際には注意し...

(LLMを活用した こきゃくセグメンテーションの マスタリング)
LLMを使用して高度な顧客セグメンテーション技術を解除しましょう高度な技術を用いてクラスタリングモデルを向上させ、エキスパートになりましょう

自己学習のためのデータサイエンスカリキュラム
はじめに データサイエンティストになる予定ですが、どこから始めればいいかわからないですか?心配しないでください、私たちがお手伝いします。この記事では、自己学習のためのデータサイエンスカリキュラム全体と、プロセスを早めるためのリソースとプログラムのリストをカバーします。 このカリキュラムでは、優れたデータサイエンティストになるために必要なツール、トリック、知識の基礎をカバーしています。もし科学と統計について少し知識があるなら、良い位置にいます。これらのことについて初めて知る場合は、まずそれらについて学ぶと役立つかもしれません。そして、既にデータに詳しい場合は、これはクイックな復習になるかもしれません。 覚えておいてください、すべてのプロジェクトでこれらのスキルをすべて使うわけではありません。一部のプロジェクトでは、このリストにない特別なトリックやツールが必要です。しかし、このカリキュラムの内容を十分に理解し、習得すると、ほとんどのデータサイエンスの仕事に対応できるようになります。そして、必要なときに新しいことを学ぶ方法も知っています。 さあ、始めましょう! データサイエンスカリキュラムをなぜフォローするのか? データサイエンスのカリキュラムに従うことは、構造化された効果的な学習には欠かせません。これにより、知識とスキルを習得するための明確なパスが提供され、この分野の広大さに圧倒されることなく学ぶことができます。良いカリキュラムは包括的なカバレッジを保証し、基礎的な概念から高度なテクニックまでを案内します。このステップバイステップのアプローチは、複雑なトピックに深入りする前に、堅固な基盤を築くための基礎となります。 さらに、カリキュラムは実践的な応用を促進します。多くのプログラムにはハンズオンのプロジェクトや演習が含まれており、理論的な知識を実世界のスキルに変換することができます。進捗を体系的に追跡することで、学習の旅においてモチベーションを保ち、集中する助けとなります。 即効的な利点を超えて、カリキュラムに従うことは職業にも役立ちます。データサイエンスの構造化された教育を完了することは、潜在的な雇用主に対してコミットメントと熟練度を示し、仕事の見通しを向上させます。さらに、このアプローチは適応性を育成し、自身のニーズに合わせてペースを調整し、困難なテーマに深入りすることができるようにします。 要するに、データサイエンスのカリキュラムは必須のスキルを身につけるだけでなく、データサイエンスの常に進化する分野で独立して学び続ける能力を養うことも可能です。 自己学習のためのデータサイエンスカリキュラム 以下は、データサイエンスの旅を始める際に探索するための主要な領域の簡略化されたロードマップです: 数学の基礎 多変数微積分:複数の変数の関数、導関数、勾配、ステップ関数、シグモイド関数、コスト関数などを理解する。 線形代数:ベクトル、行列、転置や逆行列などの行列演算、行列式、内積、固有値、固有ベクトルを習得する。 最適化手法:コスト関数、尤度関数、誤差関数などについて学び、勾配降下法(および確率的勾配降下法などの変種)などのアルゴリズムを理解する。 プログラミングの基礎 PythonまたはRを主要な言語として選択する。 Pythonの場合、NumPy、pandas、scikit-learn、TensorFlow、PyTorchなどのライブラリを習得する。 データの基礎 さまざまな形式(CSV、PDF、テキスト)でのデータ操作を学ぶ。 データのクリーニング、補完、スケーリング、インポート、エクスポート、Webスクレイピングのスキルを習得する。 PCAやLDAなどのデータ変換や次元削減の手法を探索する。 確率と統計の基礎…

「教師なし学習の解明」
「教師なし学習のパラダイムを探求してください主要な概念、技術、および人気のある教師なし学習アルゴリズムに慣れてください」
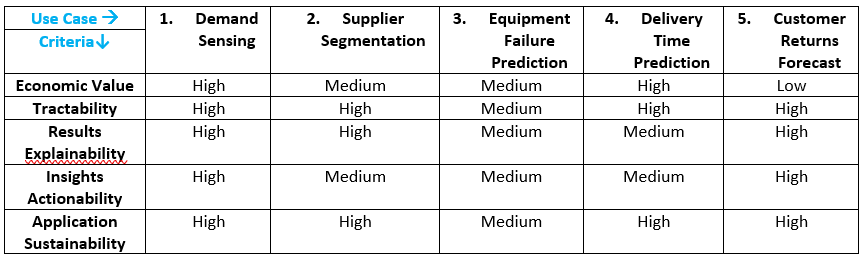
AI/MLを活用してインテリジェントなサプライチェーンを構築するための始め方
「異なる供給チェーンの要素に対するAI/MLの使用事例と価値提案:計画、調達、製造、配送、逆物流」

5つのステップでScikit-learnを始める
このチュートリアルでは、Scikit-learnを使用した機械学習の包括的なハンズオンの手順を提供します読者は、データの前処理、モデルのトレーニングと評価、ハイパーパラメータのチューニング、およびパフォーマンスを向上させるためのアンサンブルモデルのコンパイルなど、キーコンセプトと技術を学びます
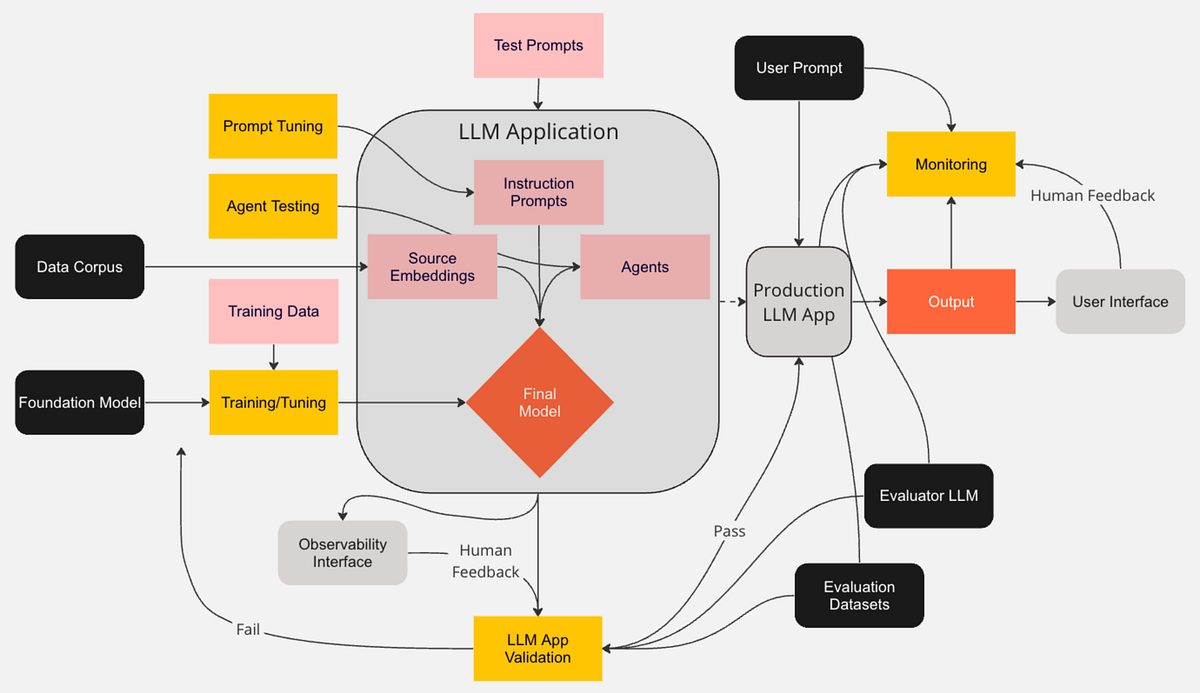
「LLMモニタリングと観測性 – 責任あるAIのための手法とアプローチの概要」
対象読者:実践者が利用可能なアプローチと実装の始め方を学びたい方、そして構築する際に可能性を理解したいリーダーたち…

「衛星データ、山火事、そしてAI:気候の課題に立ち向かうワイン産業の保護」
「オーストラリアは、世界で5番目に大きなワイン輸出国としてランク付けされており、ワインの世界で重要な位置を占めていますハンターバレーは、オーストラリアで最も古いワイン生産地域であり、わずか数時間でアクセスできます...」

機械学習:中央化とスケーリングの目的を理解する
この記事では、センタリングとスケーリングの概念について紹介します 実世界の使用例を通じて、データのセンタリングとスケーリングの利点を説明します技術的には、MinMaxScalerを比較します...
「機械学習のための現実世界のデータ収集ガイド」
「データサイエンスに完全に初めてであるか、大規模な組織のチーフデータサイエンティストであるかに関わらず、おそらくあなたは完璧に作りこまれたデータセットを使って、おもちゃの機械学習の問題を解決するために遊んだことがあるでしょうたぶん…」
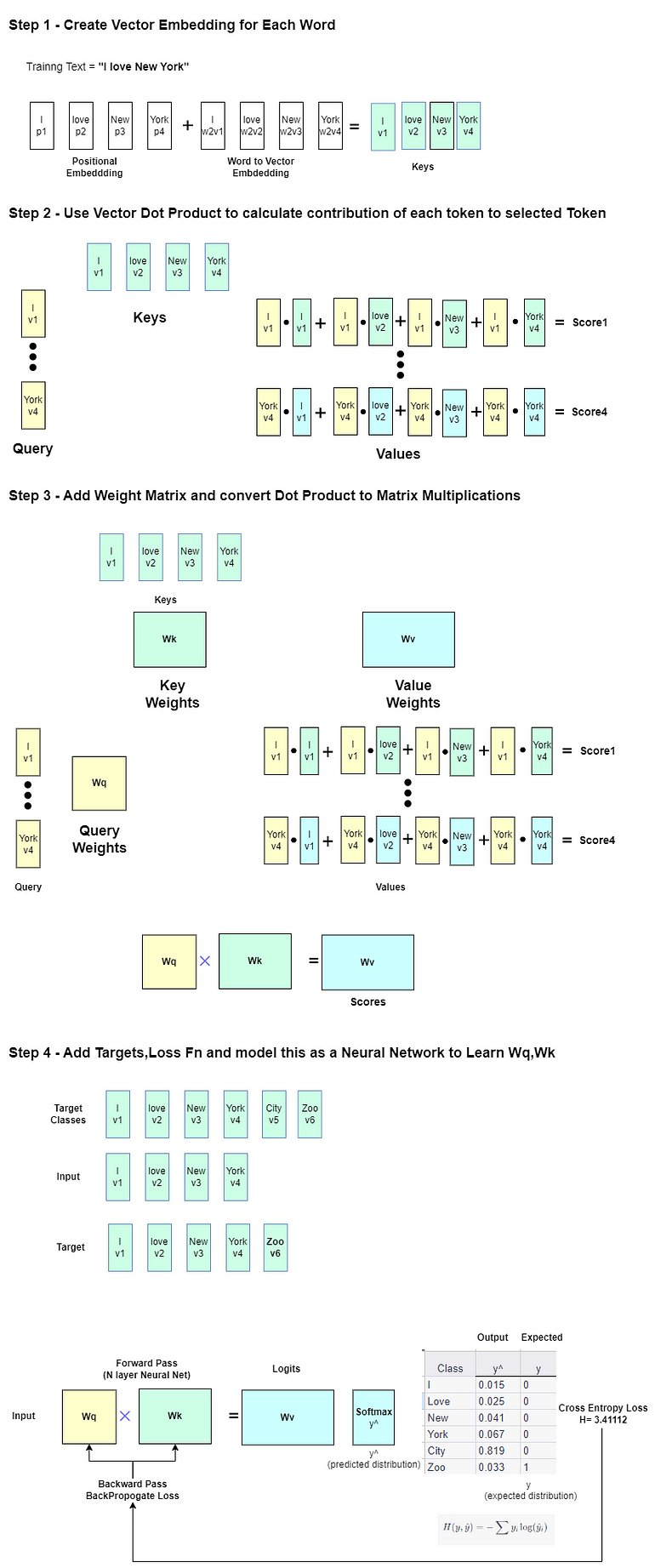
大規模言語モデルの探索 -Part 1
この記事は主に自己学習のために書かれていますそのため、広範囲かつ深い内容です興味のあるセクションをスキップしたり、自分が興味を持っている分野を探求するために、自由に特定のセクションをスキップしてください以下にいくつかの…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.