Learn more about Search Results V100 - Page 4

- You may be interested
- ストラテゴをマスターする:情報の不完全...
- 「BlindChat」に会いましょう:フルブラウ...
- イクイノックスに会いましょう:ニューラ...
- 「GPTの内部- I:テキスト生成の理解」
- 「月に10000ドルを稼ぐために私が使用する...
- チャーン予測とチャーンアップリフトを超えて
- チェサピーク保護協会の保護イノベーショ...
- 大規模言語モデル、MirrorBERT — モデルを...
- 「KPMG、AIに20億ドル以上の賭けをし、120...
- 「Amazon LexとAmazon Kendra、そして大規...
- ネットワークフローアルゴリズムの探求:...
- 「スタンフォード大学の新しいAI研究は、...
- 「自然言語処理の技術比較:RNN、トランス...
- なぜNASAが国家の秘密を月に送っているのか
- ネットワークXによるソーシャルネットワー...

DeepSpeedとAccelerateを使用した非常に高速なBLOOM推論
この記事では、176BパラメータのBLOOMモデルを使用してトークンごとのスループットを非常に高速に取得する方法を紹介します。 モデルは352GBのbf16(bfloat16)ウェイト(176*2)を必要とするため、最も効率的なセットアップは8x80GBのA100 GPUです。また、2x8x40GBのA100または2x8x48GBのA6000も使用できます。これらのGPUを使用する主な理由は、この執筆時点ではこれらのGPUが最大のGPUメモリを提供しているためですが、他のGPUも使用できます。たとえば、24x32GBのV100を使用することもできます。 単一のノードを使用すると、通常、最速のスループットが得られます。なぜなら、ほとんどの場合、ノード内のGPUリンクハードウェアの方がノード間のものよりも速いためですが、常にそうとは限りません。 もしハードウェアがそれほど多くない場合でも、CPUやNVMeのオフロードを使用してBLOOM推論を実行することは可能ですが、もちろん、生成時間は遅くなります。 また、GPUメモリの半分の容量を必要とする8ビット量子化ソリューションについても説明します。これにはBitsAndBytesとDeepspeed-Inferenceライブラリが必要です。 ベンチマーク さらなる遅延なしでいくつかの数値を示しましょう。 一貫性を保つために、この記事のベンチマークはすべて同じ8x80GBのA100ノードで実行され、512GBのCPUメモリを持つJean Zay HPCで行われました。JeanZay HPCのユーザーは、約3GB/sの読み取り速度(GPFS)で非常に高速なIOを利用しています。これはチェックポイントの読み込み時間に重要です。遅いディスクは読み込み時間が遅くなります。特に複数のプロセスでIOを同時に行っている場合はさらに重要です。 すべてのベンチマークは、100トークンの出力を貪欲に生成しています: Generate args {'max_length': 100, 'do_sample': False} 入力プロンプトはわずかなトークンで構成されています。以前のトークンのキャッシュもオンになっています。常にそれらを再計算すると非常に遅くなるためです。 まず、生成の準備が完了するまでにかかった時間(つまり、モデルの読み込みと準備にかかった時間)を見てみましょう: Deepspeed-Inferenceには、事前にシャードされたウェイトリポジトリが付属しており、読み込みに約1分かかります。Accelerateの読み込み時間も優れており、わずか2分です。他のソリューションはここでははるかに遅いです。 読み込み時間は重要であるかどうかは、一度読み込んだら追加の読み込みオーバーヘッドなしに繰り返しトークンを生成できるため、場合によります。 次に、トークン生成の最も重要なベンチマークです。ここでのスループット指標は単純であり、100個の新しいトークンを生成するのにかかった時間を100で割り、バッチサイズで割ったものです。…
SetFit プロンプトなしで効率的なフューショット学習
SetFitは、通常のファインチューニングよりもサンプル効率が高く、ノイズに強いです。 事前学習済みの言語モデルを用いたフューショット学習は、データサイエンティストの悪夢であるほとんどラベルのないデータを扱うための有望な解決策として浮上しています 😱。 Intel LabsとUKP Labとの共同研究を通じて、Hugging FaceはSetFitを紹介できることを嬉しく思っています。SetFitは、Sentence Transformersのフューショットファインチューニングの効率的なフレームワークです。SetFitは少量のラベル付きデータで高い精度を達成します – 例えば、顧客レビュー(CR)感情データセットでクラスごとにわずか8つのラベル付きの例を使用すると、SetFitはフルトレーニングセットの3,000の例でRoBERTa Largeのファインチューニングと競争力を持ちます 🤯! 他のフューショット学習手法と比較して、SetFitにはいくつかの特徴があります: 🗣 プロンプトや口述者不要:フューショットファインチューニングの現在の技術は、例を基に言語モデルに適した形式に変換するための手作りのプロンプトや口述者が必要です。SetFitはプロンプトを一切必要とせず、わずかな数のラベル付きテキスト例から直接豊かな埋め込みを生成します。 🏎 高速トレーニング:SetFitは、高い精度を実現するためにT0やGPT-3のような大規模なモデルを必要としません。そのため、トレーニングと推論の速度は通常1桁以上速くなります。 🌎 多言語対応:SetFitはHubの任意のSentence Transformerと組み合わせて使用できるため、マルチリンガルなチェックポイントをファインチューニングするだけで、複数の言語でテキストを分類することができます。 詳細については、私たちの論文、データ、コードをご覧ください。このブログ投稿では、SetFitの動作方法と独自のモデルをトレーニングする方法について説明します。さあ、始めましょう! どのように動作するのか? SetFitは効率とシンプルさを考慮して設計されています。SetFitはまず、少数のラベル付き例(通常はクラスごとに8または16個)でSentence Transformerモデルをファインチューニングします。次に、ファインチューニングされたSentence…

制御ネット(ControlNet)は、🧨ディフューザー内での使用です
Stable Diffusionが世界中で大流行した以来、人々は生成プロセスの結果に対してより多くの制御を持つ方法を探してきました。ControlNetは、ユーザーが生成プロセスを非常に大きな範囲でカスタマイズできる最小限のインターフェースを提供します。ControlNetを使用すると、ユーザーは深度マップ、セグメンテーションマップ、スクリブル、キーポイントなど、さまざまな空間的なコンテキストを使用して簡単に生成を条件付けることができます! 私たちは、驚くほどの一貫性を持つ写実的な写真に漫画の絵を変えることができます。 写実的なLofiガール また、それをあなたのインテリアデザイナーとして使用することもできます。 Before After あなたはスケッチのスクリブルを芸術的な絵に変えることができます。 Before After さらに、有名なロゴを生き生きとさせることもできます。 Before After ControlNetを使用すると、可能性は無限大です🌠 このブログ記事では、まずStableDiffusionControlNetPipelineを紹介し、さまざまな制御条件にどのように適用できるかを示します。さあ、制御しましょう! ControlNet: TL;DR ControlNetは、Lvmin ZhangとManeesh AgrawalaによってText-to-Image Diffusion Modelsに条件付き制御を追加することで導入されました。これにより、Stable DiffusionなどのDiffusionモデルに追加の条件として使用できるさまざまな空間的コンテキストをサポートするフレームワークが導入されます。ディフュージョンモデルの実装は、元のソースコードから適応されています。 ControlNetのトレーニングは次の手順で行われます:…
.jpg)
プロテオームスケールでの高精度なタンパク質構造予測を可能にする
多くの新しい機械学習のイノベーションがAlphaFoldの現在の精度に貢献しています以下にシステムの概要を高レベルで示しますネットワークアーキテクチャの技術的な説明については、私たちのAlphaFoldのメソッド論文と特に詳細な補足情報をご覧ください

AlphaTensorを使用して新しいアルゴリズムを発見する
本日、Natureに掲載された私たちの論文では、AlphaTensorという初めての人工知能(AI)システムを紹介しましたこのシステムは、行列の乗算といった基礎的なタスクのための新しい効率的で証明可能なアルゴリズムを発見するためのものですこれにより、50年にわたる数学の未解決問題である行列の乗算を最速で行う方法を見つけることが可能となりましたこの論文はDeepMindがAIを使って科学を進め、最も基本的な問題を解決するための礎となるものです私たちのAlphaTensorシステムは、将棋やチェス、囲碁などのボードゲームで超人的な成績を収めたエージェントであるAlphaZeroを基にしており、この論文ではAlphaZeroがゲームから未解決の数学の問題に挑戦するまでの道のりを示しています

ゼロから大規模言語モデルを構築するための初心者ガイド
はじめに TwitterやLinkedInなどで、私は毎日多くの大規模言語モデル(LLMs)に関する投稿に出会います。これらの興味深いモデルに対してなぜこれほど多くの研究と開発が行われているのか、私は疑問に思ったこともあります。ChatGPTからBARD、Falconなど、無数のモデルの名前が飛び交い、その真の性質を解明したくなるのです。これらのモデルはどのように作成されるのでしょうか?大規模言語モデルを構築するにはどうすればよいのでしょうか?これらのモデルは、あなたが投げかけるほとんどの質問に答える能力を持つのはなぜでしょうか?これらの燃えるような疑問は私の心に長く残り、好奇心をかき立てています。この飽くなき好奇心は私の内に火をつけ、LLMsの領域に飛び込む原動力となっています。 私たちがLLMsの最先端について議論する刺激的な旅に参加しましょう。一緒に、彼らの開発の現状を解明し、彼らの非凡な能力を理解し、彼らが言語処理の世界を革新した方法に光を当てましょう。 学習目標 LLMsとその最新の状況について学ぶ。 利用可能なさまざまなLLMsとこれらのLLMsをゼロからトレーニングするアプローチを理解する。 LLMsのトレーニングと評価におけるベストプラクティスを探究する。 準備はいいですか?では、LLMsのマスタリングへの旅を始めましょう。 大規模言語モデルの簡潔な歴史 大規模言語モデルの歴史は1960年代にさかのぼります。1967年にMITの教授が、自然言語を理解するための最初のNLPプログラムであるElizaを作成しました。Elizaはパターンマッチングと置換技術を使用して人間と対話し理解することができます。その後、1970年にはMITチームによって、人間と対話し理解するための別のNLPプログラムであるSHRDLUが作成されました。 1988年には、テキストデータに存在するシーケンス情報を捉えるためにRNNアーキテクチャが導入されました。2000年代には、RNNを使用したNLPの研究が広範に行われました。RNNを使用した言語モデルは当時最先端のアーキテクチャでした。しかし、RNNは短い文にはうまく機能しましたが、長い文ではうまく機能しませんでした。そのため、2013年にはLSTMが導入されました。この時期には、LSTMベースのアプリケーションで大きな進歩がありました。同時に、アテンションメカニズムの研究も始まりました。 LSTMには2つの主要な懸念がありました。LSTMは長い文の問題をある程度解決しましたが、実際には非常に長い文とはうまく機能しませんでした。LSTMモデルのトレーニングは並列化することができませんでした。そのため、これらのモデルのトレーニングには長い時間がかかりました。 2017年には、NLPの研究において Attention Is All You Need という論文を通じてブレークスルーがありました。この論文はNLPの全体的な景色を変革しました。研究者たちはトランスフォーマーという新しいアーキテクチャを導入し、LSTMに関連する課題を克服しました。トランスフォーマーは、非常に多数のパラメータを含む最初のLLMであり、LLMsの最先端モデルとなりました。今日でも、LLMの開発はトランスフォーマーに影響を受けています。 次の5年間、トランスフォーマーよりも優れたLLMの構築に焦点を当てた重要な研究が行われました。LLMsのサイズは時間とともに指数関数的に増加しました。実験は、LLMsのサイズとデータセットの増加がLLMsの知識の向上につながることを証明しました。そのため、BERT、GPTなどのLLMsや、GPT-2、GPT-3、GPT 3.5、XLNetなどのバリアントが導入され、パラメータとトレーニングデータセットのサイズが増加しました。 2022年には、NLPにおいて別のブレークスルーがありました。 ChatGPT は、あなたが望むことを何でも答えることができる対話最適化されたLLMです。数か月後、GoogleはChatGPTの競合製品としてBARDを紹介しました。…
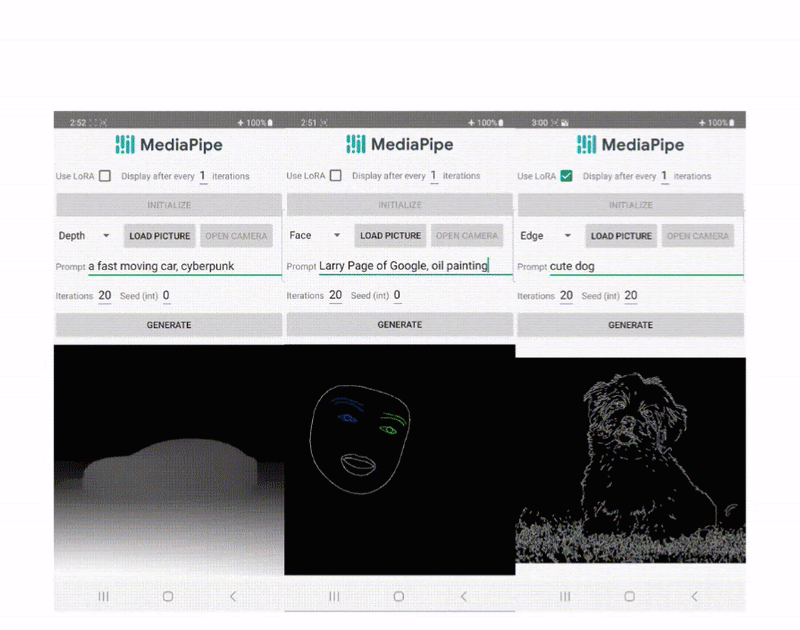
デバイス上での条件付きテキストから画像生成のための拡散プラグイン
Yang ZhaoとTingbo Houによる投稿、ソフトウェアエンジニア、Core ML 近年、拡散モデルはテキストから画像を生成する際に非常に成功を収め、高品質な画像、改善された推論パフォーマンス、そして創造的なインスピレーションの拡大を実現しています。しかし、特にテキストで説明しづらい条件での生成を効率的に制御することはまだ困難です。 本日、MediaPipe拡散プラグインを発表し、コントロール可能なテキストから画像をデバイス上で実行できるようにします。オンデバイスの大規模生成モデルにおけるGPU推論に関する以前の作業を拡張し、既存の拡散モデルとその低ランク適応(LoRA)バリアントにプラグインを追加し、コントロール可能なテキストから画像を生成するための低コストなソリューションを提供します。 デバイス上で動作するコントロールプラグインによるテキストからの画像生成。 背景 拡散モデルでは、画像生成はイテレーションのノイズ除去プロセスとしてモデル化されます。ノイズ画像から始め、各ステップで、拡散モデルは画像を徐々にノイズ除去して目標のコンセプトの画像を明らかにします。研究によると、テキストプロンプトを介した言語理解を活用することで、画像生成を大幅に改善できます。テキストから画像を生成する場合、テキストの埋め込みはモデルにクロスアテンションレイヤーを介して接続されます。しかし、位置や姿勢など、一部の情報はテキストプロンプトで説明することが難しいです。この問題を解決するために、研究者は拡散に追加のモデルを追加して、条件画像から制御情報を注入します。 制御されたテキストから画像を生成するための一般的なアプローチには、Plug-and-Play、ControlNet、T2I Adapterなどがあります。Plug-and-Playは、広く使用されているノイズ除去拡散暗黙モデル(DDIM)の逆操作アプローチを適用し、入力画像から初期ノイズ入力を導出し、拡散モデルのコピー(安定拡散1.5用の860Mパラメータ)を使用して入力画像から条件をエンコードします。Plug-and-Playは、コピーされた拡散から自己注意で空間特徴を抽出し、それらをテキストから画像への拡散に注入します。ControlNetは、拡散モデルのエンコーダーの学習可能なコピーを作成し、ゼロで初期化されたパラメータを持つ畳み込み層を介してデコーダーレイヤーに接続し、条件情報をエンコードします。しかし、その結果、サイズが大きく、拡散モデルの半分(安定拡散1.5用の430Mパラメータ)になります。T2I Adapterはより小さなネットワーク(77Mパラメータ)であり、制御可能な生成に似た効果を実現します。T2I Adapterは条件画像のみを入力とし、その出力はすべての拡散イテレーションで共有されます。ただし、アダプターモデルはポータブルデバイス向けに設計されていません。 MediaPipe拡散プラグイン 条件付き生成を効率的かつカスタマイズ可能、スケーラブルにするために、MediaPipe拡散プラグインを別個のネットワークとして設計しました。これは以下のような特徴を持っています: プラグ可能:事前にトレーニングされたベースモデルに簡単に接続できます。 スクラッチからトレーニング:ベースモデルの事前トレーニング済みの重みを使用しません。 ポータブル:ベースモデル外でモバイルデバイス上で実行され、ベースモデルの推論と比較して無視できるコストです。 メソッド パラメーターサイズ プラグ可能 スクラッチからトレーニング ポータブル Plug-and-Play…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.