Learn more about Search Results Transformer - Page 4

- You may be interested
- 「カスタマイズされたLLMパワードAIアシス...
- リアルワールドのMLOpsの例:Brainlyでの...
- 「LlaMA 2の始め方 | メタの新しい生成AI」
- GoogleのプロジェクトOpen Se Curaをご紹...
- 「データ冗長性とは何ですか?利点、欠点...
- 世界に向けて:非営利団体がGPUパワードの...
- ジオのHaptikがビジネス向けのAIツールを...
- AIがリードジェネレーションにどのように...
- 「Amazon Qをご紹介します:ビジネスの卓...
- 「衛星データ、山火事、そしてAI:気候の...
- GradioがHugging Faceに参加します!
- Hugging FaceとIBMは、AIビルダー向けの次...
- メタAIは、122の言語に対応した初の並列読...
- AIの今週、8月18日:OpenAIが財政的な問題...
- 「Underrepresented Groupsの存在下での学...

「VAEs、GANs、およびTransformersによる創発的AIの解放」
イントロダクション 生成AIは、人工知能と創造性の交差点に位置する興奮する分野であり、機械が新しいオリジナルなコンテンツを生成することによって、さまざまな産業を革新しています。リアルな画像や音楽の作曲から生き生きとしたテキストや没入型の仮想環境の作成まで、生成AIは機械が達成できる範囲を広げています。このブログでは、VAEs、GANs、およびTransformersを使って生成AIの有望な領域を探求し、その応用、進歩、そして将来における深い影響について検討します。 学習目標 VAEs、GANs、およびTransformersを含む生成AIの基本的な概念を理解する。 生成AIモデルの創造的なポテンシャルとその応用を探求する。 VAEs、GANs、およびTransformersの実装についての洞察を得る。 生成AIの将来の方向性と進歩を探求する。 この記事は、データサイエンスブログマラソンの一部として公開されました。 生成AIの定義 生成AIは、本質的には既存のデータから学習し、類似した特性を持つ新しいコンテンツを生成するためにモデルをトレーニングすることを含みます。既存の情報に基づいてパターンを認識し予測する従来のAIアプローチとは異なり、生成AIは完全に新しいものを作成し、創造性とイノベーションの領域を広げることを目指しています。 生成AIの力 生成AIは、創造性を解放し、機械が達成できる範囲を広げる力を持っています。VAEs、GANs、およびTransformersなど、生成AIで使用される基本原理とモデルを理解することで、この創造的な技術の背後にある技術と手法を把握することができます。 生成AIの力は、創造性を解放し、人間の創造性を模倣し、さらには超える新しいコンテンツを生成する能力にあります。アルゴリズムとモデルを活用することにより、生成AIは画像、音楽、テキストなど多様な出力を生成し、インスピレーションを与え、革新し、芸術的表現の領域を広げることができます。 VAEs、GANs、およびTransformersなどの生成AIモデルは、この力を解放するために重要な役割を果たしています。VAEsはデータの基本的な構造を捉え、学習された潜在空間からサンプリングすることで新しいサンプルを生成することができます。GANsは生成器と識別器の間の競争的なフレームワークを導入し、非常にリアルな出力を生み出します。Transformersは長距離の依存関係を捉えることに優れており、一貫性のあるコンテンツを生成するのに適しています。 詳細を探求しましょう。 変分オートエンコーダ(VAEs) 生成AIで使用される基本的なモデルの1つは変分オートエンコーダまたはVAEです。エンコーダ-デコーダのアーキテクチャを用いて、VAEsは入力データの本質を低次元の潜在空間に圧縮することによって、新しいサンプルを生成します。 VAEsは画像生成、テキスト合成などに応用され、機械が魅了し、インスピレーションを与える新しいコンテンツを作成することが可能になりました。 VAEの実装 このセクションでは、変分オートエンコーダ(VAE)をスクラッチから実装します。 エンコーダとデコーダモデルの定義 エンコーダは入力データを受け取り、ReLU活性化関数を持つ密な層を通過させ、潜在空間分布の平均と対数分散を出力します。 デコーダネットワークは、潜在空間表現を入力として受け取り、ReLU活性化関数を持つ密な層を通過させ、シグモイド活性化関数を適用することでデコーダの出力を生成します。 import…
「Transformerモデルの実践的な導入 BERT」
ハンズオンチュートリアルでBERTを探索してください:トランスフォーマーを理解し、プレトレーニングとファインチューニングをマスターし、PythonとHugging Faceを使用して感情分析を実行します

「HuggingFace Transformers ツールとエージェント:ハンズオン」
Transformersバージョンv4.29.0は、ツールとエージェントのコンセプトを基に構築され、transformersの上に自然言語APIを提供しますそれらの使い方は?言語学習を目的として詳しく調べてみましょう…

「TransformersとTokenizersを使用して、ゼロから新しい言語モデルを訓練する方法」
ここ数か月間で、私たちはtransformersとtokenizersライブラリにいくつかの改良を加え、新しい言語モデルをゼロからトレーニングすることをこれまで以上に簡単にすることを目指しました。 この記事では、”小さな”モデル(84 Mパラメータ = 6層、768隠れユニット、12アテンションヘッド)を「エスペラント」でトレーニングする方法をデモンストレーションします。その後、モデルを品詞タグ付けの下流タスクでファインチューニングします。 エスペラントは学習しやすいことを目標とした人工言語です。このデモンストレーションのために選んだ理由は以下のとおりです: 比較的リソースが少ない言語です(約200万人が話すにもかかわらず)、このデモンストレーションはもう1つの英語モデルのトレーニングよりも面白くなります 😁 文法が非常に規則的です(例:一般的な名詞は-oで終わり、すべての形容詞は-aで終わります)。そのため、小さなデータセットでも興味深い言語的結果が得られるはずです。 最後に、この言語の基盤となる目標は人々をより近づけることです(世界平和と国際理解を促進すること)。これはNLPコミュニティの目標と一致していると言えるでしょう 💚 注:この記事を理解するためにはエスペラントを理解する必要はありませんが、学びたい場合はDuolingoには280,000人のアクティブな学習者がいる素敵なコースがあります。 私たちのモデルの名前は…待ってください…EsperBERTo 😂 1. データセットを見つける まず、エスペラントのテキストコーパスを見つけましょう。ここでは、INRIAのOSCARコーパスのエスペラント部分を使用します。OSCARは、WebのCommon Crawlダンプの言語分類とフィルタリングによって得られた巨大な多言語コーパスです。 データセットのエスペラント部分はわずか299Mですので、Leipzig Corpora Collectionのエスペラントサブコーパスと連結します。このサブコーパスには、ニュース、文学、ウィキペディアなど様々なソースのテキストが含まれています。 最終的なトレーニングコーパスのサイズは3 GBですが、モデルに先行学習するためのデータが多ければ多いほど、より良い結果が得られます。 2.…

TransformersとRay Tuneを使用したハイパーパラメータの検索
Anyscale チームの Richard Liaw によるゲストブログ投稿 最先端の研究実装や数千ものトレーニング済みモデルへの簡単なアクセスが可能な Hugging Face transformers ライブラリは、自然言語処理の成功と成長において重要な存在となっています。 良いパフォーマンスを達成するために、ほとんどのユーザーはパラメータのチューニングを行う必要があります。しかし、ほとんどの人はハイパーパラメータのチューニングを無視するか、小さな探索空間で簡素なグリッドサーチを行うことを選択します。 しかし、簡単な実験でも高度なチューニング手法の利点を示すことができます。以下は、Hugging Face transformers の BERT モデルを RTE データセットで実行した最近の実験結果です。PBT のような遺伝的最適化手法は、標準的なハイパーパラメータ最適化手法と比較して大幅なパフォーマンス向上を提供できます。 アルゴリズム 最高の検証精度 最高のテスト精度 合計…

fairseqのwmt19翻訳システムをtransformersに移植する
Stas Bekmanさんによるゲストブログ記事 この記事は、fairseq wmt19翻訳システムがtransformersに移植された方法をドキュメント化する試みです。 私は興味深いプロジェクトを探していて、Sam Shleiferさんが高品質の翻訳者の移植に取り組んでみることを提案してくれました。 私はFacebook FAIRのWMT19ニュース翻訳タスクの提出に関する短い論文を読み、オリジナルのシステムを試してみることにしました。 最初はこの複雑なプロジェクトにどう取り組むか分からず、Samさんがそれを小さなタスクに分解するのを手伝ってくれました。これが非常に助けになりました。 私は、両方の言語を話すため、移植中に事前学習済みのen-ru / ru-enモデルを使用することを選びました。ドイツ語は話せないので、de-en / en-deのペアで作業するのははるかに難しくなります。移植プロセスの高度な段階で出力を読んで意味を理解することで翻訳の品質を評価できることは、多くの時間を節約することができました。 また、最初の移植をen-ru / ru-enモデルで行ったため、de-en / en-deモデルが統合されたボキャブラリを使用していることに全く気づいていませんでした。したがって、2つの異なるサイズのボキャブラリをサポートするより複雑な作業を行った後、統合されたボキャブラリを動作させるのは簡単でした。 手抜きしましょう 最初のステップは、もちろん手抜きです。大きな努力をするよりも小さな努力をする方が良いです。したがって、fairseqへのプロキシとして機能し、transformersのAPIをエミュレートする数行のコードで短いノートブックを作成しました。 もし基本的な翻訳以外のことが必要なければ、これで十分でした。しかし、もちろん、完全な移植を行いたかったので、この小さな勝利の後、より困難な作業に移りました。 準備 この記事では、~/portingの下で作業していると仮定し、したがってこのディレクトリを作成します:…

🤗 APIのお客様のためにTransformerの推論を100倍高速化する方法
🤗 トランスフォーマーは、データサイエンティストが世界中で利用するデフォルトのライブラリとなり、最新のNLPモデルを探索し、新しいNLP機能を構築するためのものです。5,000以上の事前学習済みモデルとファインチューニングモデルが250以上の言語で提供されており、どのフレームワークを使用していても簡単にアクセスできる、豊富なプレイグラウンドです。 🤗 トランスフォーマーでモデルを試すことは簡単ですが、これらの大規模なモデルをパフォーマンス最大化で本番環境に展開し、使用状況にスケーリングするアーキテクチャで管理することは、どの機械学習エンジニアにとっても困難なエンジニアリングの課題です。 この100倍のパフォーマンス向上と組み込みのスケーラビリティのために、私たちのホストされたアクセラレーテッドインフェランスAPIのサブスクライバーは、その上にNLP機能を構築することを選択しました。パフォーマンスを最後の10倍向上させるためには、最適化はモデルに特化し、ターゲットのハードウェアに特化して低レベルで行う必要があります。 この記事では、お客様のために計算リソースを最大限に活用するための私たちのアプローチの一部を共有します。🍋 最初の10倍のスピードアップへの取り組み 最初の最適化のステップは最もアクセスしやすく、ターゲットのハードウェアに依存しないHugging Faceライブラリが提供する最適な技術の組み合わせを使用することです。 Hugging Faceモデルパイプラインに組み込まれた最も効率的な方法を使用して、各フォワードパス中の計算量を減らします。これらの方法はモデルのアーキテクチャとターゲットのタスクに固有であり、例えばGPTアーキテクチャのテキスト生成タスクでは、各パスの最後のトークンの新しいアテンションに焦点を当てることでアテンション行列の次元削減を行います。 トークン化は推論中の効率性においてボトルネックとなることが多いです。私たちは🤗 Tokenizersライブラリから最も効率的な方法を使用し、モデルのトークナイザーのRust実装とスマートキャッシングを組み合わせて、全体のレイテンシーを10倍高速化します。 Hugging Faceライブラリの最新機能を活用することで、特定のモデル/ハードウェアのデフォルト展開に比べて確実な10倍のスピードアップを実現します。TransformersとTokenizersの新リリースは通常毎月提供されるため、APIのお客様は常に新しい最適化の機会に合わせる必要はありません。彼らのモデルは単により高速に実行され続けます。 コンパイルFTW: 難しい10倍のスピードアップ ここからが本当に難しくなります。最高のパフォーマンスを得るためには、モデルを変更し、推論の特定のハードウェアをターゲットにしてコンパイルする必要があります。ハードウェアの選択そのものは、モデル(メモリサイズ)と需要プロファイル(リクエストのバッチ処理)に依存します。同じモデルから予測を提供する場合でも、一部のAPIのお客様はアクセラレートされたCPU推論から、他のお客様はアクセラレートされたGPU推論から、それぞれ異なる最適化技術とライブラリを適用することでより大きな恩恵を受けることがあります。 計算プラットフォームがユースケースに選択されたら、作業に取り掛かることができます。ここでは、静的グラフで適用できるいくつかのCPU固有のテクニックを示します: グラフの最適化(未使用のフローの削除) レイヤーのフュージョン(特定のCPU命令との組み合わせ) 演算の量子化 オープンソースライブラリ(例: 🤗…

Hugging Face Transformersでより高速なTensorFlowモデル
ここ数か月、Hugging FaceチームはTransformersのTensorFlowモデルの改良に取り組んできました。目標はより堅牢で高速なモデルを実現することです。最近の改良は主に次の2つの側面に焦点を当てています: 計算パフォーマンス:BERT、RoBERTa、ELECTRA、MPNetの計算時間を大幅に短縮するための改良が行われました。この計算パフォーマンスの向上は、グラフ/イージャーモード、TF Serving、CPU/GPU/TPUデバイスのすべての計算アスペクトで顕著に見られます。 TensorFlow Serving:これらのTensorFlowモデルは、TensorFlow Servingを使用して展開することができ、推論においてこの計算パフォーマンスの向上を享受することができます。 計算パフォーマンス 計算パフォーマンスの向上を実証するために、v4.2.0のTensorFlow ServingとGoogleの公式実装との間でBERTのパフォーマンスを比較するベンチマークを実施しました。このベンチマークは、GPU V100上でシーケンス長128を使用して実行されました(時間はミリ秒単位で表示されます): v4.2.0の現行のBertの実装は、Googleの実装よりも最大で約10%高速です。また、4.1.1リリースの実装よりも2倍高速です。 TensorFlow Serving 前のセクションでは、Transformersの最新バージョンでブランドニューのBertモデルが計算パフォーマンスが劇的に向上したことを示しました。このセクションでは、製品環境で計算パフォーマンスの向上を活用するために、TensorFlow Servingを使用してBertモデルを展開する手順をステップバイステップで説明します。 TensorFlow Servingとは何ですか? TensorFlow Servingは、モデルをサーバーに展開するタスクをこれまで以上に簡単にするTensorFlow Extended(TFX)が提供するツールの一部です。TensorFlow Servingには、HTTPリクエストを使用して呼び出すことができるAPIと、サーバー上で推論を実行するためにgRPCを使用するAPIの2つがあります。 SavedModelとは何ですか? SavedModelには、ウェイトとアーキテクチャを含むスタンドアロンのTensorFlowモデルが含まれています。SavedModelは、モデルの元のソースを実行する必要がないため、Java、Go、C++、JavaScriptなどのSavedModelを読み込むバックエンドをサポートするすべてのバックエンドと共有または展開するために役立ちます。SavedModelの内部構造は次のように表されます:…
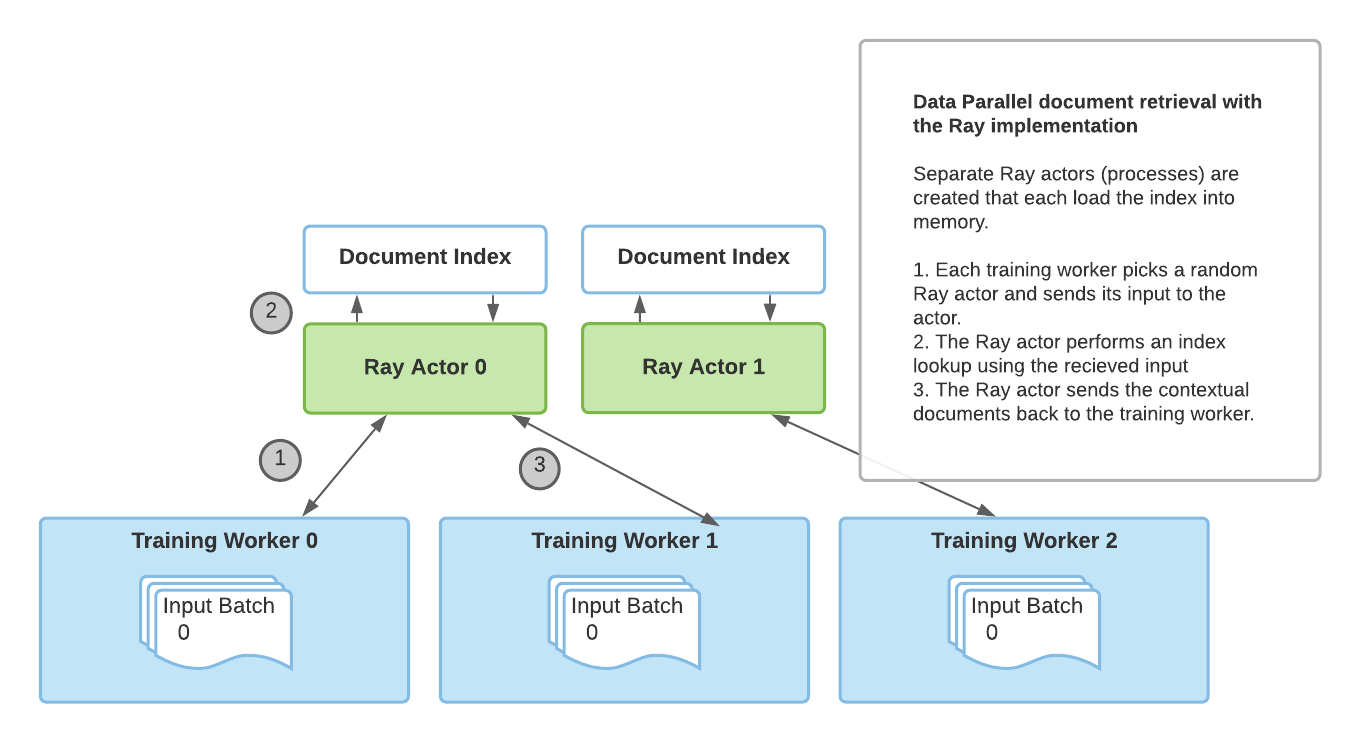
Huggingface TransformersとRayを使用した検索増強生成
アノスケールのチームからのゲストブログ投稿:Amog Kamsetty氏 Huggingface Transformersは最近、Retrieval Augmented Generation(RAG)モデルを追加しました。これは、外部のドキュメント(ウィキペディアなど)を活用して知識を拡充し、知識集約的なタスクで最先端の結果を実現する新しいNLPアーキテクチャです。このブログ投稿では、スケーラブルなアプリケーションを構築するためのライブラリであるRayをRAGの文脈におけるドキュメント検索メカニズムに統合する方法を紹介します。これにより、検索呼び出しの速度が2倍に向上し、RAGの分散ファインチューニングのスケーラビリティが向上します。 Retrieval Augmented Generation(RAG)とは何ですか? RAGの概要です。モデルは外部のデータセットから文脈ドキュメントを取得し、実行の一環として使用します。これらの文脈ドキュメントは元の入力と組み合わせて出力を生成するために使用されます。このGIFはFacebookのオリジナルのブログ投稿から取得されました。 最近、HuggingfaceはFacebook AIと提携して、RAGモデルをTransformersライブラリの一部として導入しました。 RAGは他のseq2seqモデルと同様に機能しますが、外部の知識ベース(ウィキペディアのテキストコーパスなど)から文脈ドキュメントを取得する中間コンポーネントを持っています。これらのドキュメントは入力シーケンスと組み合わせて基礎となるseq2seqジェネレータに渡されます。 この情報検索ステップにより、RAGはモデルパラメータに埋め込まれた知識と文脈のパッセージに含まれる情報という複数の知識源を活用することができます。これにより、質問応答などのタスクで他の最先端モデルを上回るパフォーマンスを発揮します。Huggingfaceが提供するデモを使用して、自分自身で試すこともできます。 ファインチューニングのスケーリング これらの文脈ドキュメントの取得は、RAGの最先端の結果にとって重要ですが、追加の複雑さをもたらします。データ並列トレーニングルーチンを介してトレーニングプロセスをスケーリングアップする際、ドキュメントの検索の単純な実装はトレーニングのボトルネックになることがあります。さらに、検索コンポーネントで使用されるドキュメントインデックスは非常に大きいため、各トレーニングワーカーが自分自身の複製されたインデックスを読み込むことは不可能です。 以前のRAGファインチューニングの実装では、torch.distributed通信パッケージを使用してドキュメント検索部分を活用していました。しかし、この実装は柔軟性に欠け、スケーラビリティに制約がありました。 その代わりに、フレームワークに依存しないアドホックな並行プログラミングのためのより柔軟な実装が必要です。それには、Rayが完璧に適しています。Rayは一般的な分散および並列プログラミングのためのシンプルで強力なPythonライブラリです。Rayを使用して分散ドキュメント検索を行うことで、torch.distributedに比べて検索呼び出しごとに2倍の高速化と、ファインチューニングのスケーラビリティの向上を実現しました。 ドキュメント検索のためのRay torch.distributedの実装によるドキュメント検索 torch.distributedを使用したドキュメント検索の主な欠点は、トレーニングに使用されるプロセスグループに依存していて、ランク0のトレーニングワーカーのみがインデックスをメモリに読み込んでいたことです。 その結果、この実装にはいくつかの制限がありました: 同期のボトルネック:ランク0のワーカーはすべてのワーカーから入力を受け取り、インデックスクエリを実行し、その結果を他のワーカーに送信する必要がありました。これにより、複数のトレーニングワーカーでのパフォーマンスが制限されました。 PyTorch固有の:ドキュメント検索プロセスグループはトレーニングに使用される既存のプロセスグループに依存する必要があり、トレーニングにはPyTorchを使用する必要がありました。…
ハギングフェイスの読書会、2021年2月 – Long-range Transformers
Efficient Transformersの分類法(TayらによるEfficient Transformers:サーベイ) 共著者:Teven Le Scao、Patrick Von Platen、Suraj Patil、Yacine Jernite、Victor Sanh 毎月、私たちは特定のトピックに焦点を当て、そのトピックについて最近発表された4つの論文を読みます。それらの研究結果と共通のトレンド、そして読んだ後の追加研究についての質問を短いブログ投稿でまとめます。2021年1月の最初のトピックは「スパース化とプルーニング」であり、2021年2月には「Transformerにおけるロングレンジアテンション」に取り組みました。 イントロダクション 2018年と2019年に大型Transformerモデルが台頭した後、その計算要件を下げるために2つのトレンドが急速に現れました。第一に、条件付き計算、量子化、蒸留、プルーニングにより、計算制約のある環境で大型モデルの推論が可能になりました。私たちは既に前回の読書グループの投稿でこれに触れています。研究コミュニティはその後、事前トレーニングのコストを削減するために動きました。 特に、トランスフォーマーモデルのメモリと時間に関するシーケンス長に対する二次的なコストが問題となっていました。非常に大きなモデルの効率的なトレーニングを可能にするために、2020年には通常のNLPでは512または1024のシーケンス長がデフォルトであった範囲を超えるトランスフォーマーをスケールするための論文が数多く発表されました。 このトピックは私たちの研究討論の中心的な要素であり、私たち自身のPatrick Von PlatenはすでにReformerに4部作を捧げています。この読書グループでは、すべてのアプローチをカバーしようとせずに(アプローチは非常に多いです!)、次の4つの主なアイデアに焦点を当てます: カスタムアテンションパターン(Longformerを使用) 再帰(Compressive Transformerを使用) 低ランク近似(Linformerを使用) カーネル近似(Performerを使用) 詳細な視点については、「Efficient…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.