Learn more about Search Results StableDiffusion - Page 4

- You may be interested
- 画像拡張のための生成的対立ネットワーク...
- このAI論文は、効率的な水素燃焼予測のた...
- 最適化ストーリー:ブルーム推論
- In Japanese, the translation of Time Se...
- メタがコードラマをリリース:コーディン...
- 「ワードエンベディング:より良い回答の...
- 「EPFLとAppleの研究者が4Mをオープンソー...
- 「Rasaパワードチャットボット:シームレ...
- 「AI安全性の議論がシリコンバレーを引き...
- 「OWLv2のご紹介:ゼロショット物体検出に...
- 化学プロセス開発のためのモデルフリー強...
- 「AWSとAccelが「ML Elevate 2023」を立ち...
- 思っているベイダーではありません 3D VAD...
- 「ジェネラティブAIサミットのオンデマン...
- インフレクション-2はGoogleのPaLM-2を超...

「インテルCPU上での安定したディフューションモデルのファインチューニング」
拡散モデルは、テキストのプロンプトから写真のようなリアルな画像を生成するというその驚異的な能力によって、生成型AIの普及に貢献しました。これらのモデルは現在、合成データの生成やコンテンツ作成などの企業のユースケースに取り入れられています。Hugging Faceハブには、5,000以上の事前学習済みのテキストから画像へのモデルが含まれています。Diffusersライブラリと組み合わせることで、実験や画像生成ワークフローの構築がこれまで以上に簡単になりました。 Transformerモデルと同様に、Diffusionモデルをファインチューニングしてビジネスニーズに合ったコンテンツを生成することができます。初期のファインチューニングはGPUインフラストラクチャー上でのみ可能でしたが、状況は変わってきています!数か月前、インテルはSapphire Rapidsというコードネームの第4世代のXeon CPUを発売しました。Sapphire Rapidsは、ディープラーニングワークロードのための新しいハードウェアアクセラレータであるIntel Advanced Matrix Extensions (AMX)を導入しています。私たちはすでにいくつかのブログ記事でAMXの利点を実証しています:NLP Transformerのファインチューニング、NLP Transformerの推論、およびStable Diffusionモデルの推論。 この投稿では、Intel Sapphire Rapids CPUクラスター上でStable Diffusionモデルをファインチューニングする方法を紹介します。わずかな例の画像のみを必要とするテキスト反転という技術を使用します。たった5つの画像だけです! さあ、始めましょう。 クラスターのセットアップ Intelの友人たちが、最新のIntelプロセッサとパフォーマンス最適化されたソフトウェアスタックを使用したIntel®最適化デプロイメント環境でのワークロードの開発と実行を行うためのサービスプラットフォームであるIntel Developer Cloud(IDC)にホストされた4つのサーバーを提供してくれました。 各サーバーには、2つのIntel…

🧨ディフューザーを使用した安定した拡散
…🧨 ディフューザーを使用して Stable Diffusionは、CompVis、Stability AI、およびLAIONの研究者とエンジニアによって作成されたテキストから画像への潜在的な拡散モデルです。これは、LAION-5Bデータベースのサブセットから512×512の画像でトレーニングされています。LAION-5Bは現在存在する最大の、自由にアクセス可能な多様性のあるデータセットです。 この記事では、Stable Diffusionと🧨 ディフューザーのライブラリを使用する方法、モデルの動作の説明、およびディフューザーを使用して画像生成パイプラインをカスタマイズする方法について説明します。 注意:ディフュージョンモデルの動作原理を基本的に理解することを強くお勧めします。ディフュージョンモデルが完全に新しいものである場合、次のブログ記事のいずれかを読むことをお勧めします: 注釈付きディフュージョンモデル 🧨 ディフューザーの始め方 それでは、いくつかの画像を生成しましょう 🎨。 Stable Diffusionの実行 ライセンス モデルを使用する前に、モデルのライセンスを受け入れて重みをダウンロードして使用する必要があります。 注意:ライセンスはもはやUIを介して明示的に受け入れる必要はありません。 このライセンスは、このような強力な機械学習システムの潜在的な有害な影響を緩和するために設計されています。ユーザーには、ライセンスを完全かつ注意深く読むことをお願いします。以下に要約を提供します: モデルを意図的に違法または有害な出力やコンテンツの生成や共有に使用することはできません。 生成した出力に対する権利は主張しません。使用は自由であり、使用に関してはライセンスで設定された規定に違反してはならず、その使用については責任があります。 重みを再配布し、モデルを商業的および/またはサービスとして使用することができます。ただし、その場合、ライセンスで設定された使用制限とCreativeML OpenRAIL-Mのコピーをすべてのユーザーに提供する必要があります。…

OpenRAIL オープンで責任あるAIライセンスフレームワークに向けて
オープン&レスポンシブAIライセンス(「OpenRAIL」)は、後者の責任ある使用を求めながら、AIアーティファクトのオープンアクセス、使用、配布を可能にするAI特有のライセンスです。 OpenRAILライセンスは、現在のオープンソフトウェアライセンスがコードに対して、およびクリエイティブコモンズが一般コンテンツに対して行っていることと同様に、オープンで責任あるMLに対する広範なコミュニティライセンスツールです。 機械学習と他のAI関連分野の進歩は、情報通信技術(ICT)セクターにおけるオープンソース文化の普及の一部によって、過去数年間で著しく発展してきました。これは、MLの研究開発ダイナミクスに浸透しています。イノベーションのための核としてのオープンさの利点にもかかわらず、(まだそうではない)最近の機械学習モデルの開発と使用に関する倫理的および社会経済的懸念に関連する出来事は明確なメッセージを広めています。オープンさだけでは十分ではありません。しかし、問題は、企業のプライベートAI開発プロセスの不透明性の下で問題が持続しているため、閉じたシステムも答えではありません。 オープンソースライセンスはすべてに適合しません MLモデルのアクセス、開発、使用は、オープンソースライセンスのスキームに非常に影響を受けています。たとえば、ML開発者は、公式のオープンソースライセンスやその他のオープンソースソフトウェアまたはコンテンツライセンス(Creative Commonsなど)を添付して重みを利用可能にすると、非公式に「モデルのオープンソース化」と呼ぶことがあります。これは次の疑問を投げかけます:なぜ彼らはそれをやるのですか?MLアーティファクトとソースコードは本当に似ているのでしょうか?技術的な観点から十分に共有できるほど共有していますか(たとえば、Apache 2.0など)。 ほとんどの現在のモデル開発者はそう考えているようですが、公開されたモデルの大部分はオープンソースライセンスを持っています(例:Apache 2.0)。たとえば、Hugging Face Model HubやMuñoz Ferrandis & Duque Lizarralde(2022)を参照してください。 しかし、経験的な証拠は、オープンソース化と/またはフリーソフトウェアダイナミクスへの厳格なアプローチと、MLアーティファクトのリリースにおけるFreedom 0への公理的な信念が、MLモデルの使用における社会倫理的な歪みを生み出していることを示しています(Widder et al. (2022)参照)。より簡単に言えば、オープンソースライセンスは、モデルがソフトウェア/ソースコードとは異なるアーティファクトであることを考慮に入れず、MLモデルの責任ある使用を可能にするには適応されていないため、適応されていません。 モデルのドキュメンテーション、透明性、倫理的な使用に専念した特定の特別なプラクティスが既に存在し、日々改善されています(例:モデルカード、評価ベンチマーク)。なぜ、MLモデルに関するオープンライセンスのプラクティスも、MLモデルから生じる特定の能力と課題に適応されていないのでしょうか? 同様の懸念は、商業および政府のMLライセンスプラクティスでも浮上しています。Bowe & Martin(2022)の言葉によれば、「Anduril…

ディフューザーの新着情報は何ですか?🎨
1か月半前に、モダリティを横断する拡散モデルのためのモジュールツールボックスを提供するdiffusersライブラリをリリースしました。数週間後には、高品質なテキストから画像への変換モデルであるStable Diffusionのサポートを追加し、誰でも無料のデモを試すことができるようにしました。最後の3週間では、チームはライブラリに1つまたは2つの新機能を追加することを決定しました。このブログ投稿では、diffusersバージョン0.3の新機能について概説します!GitHubリポジトリに⭐を付けるのを忘れないでください。 画像から画像へのパイプライン テキストの逆転 インペインティング より小さなGPUに最適化 Mac上で実行 ONNXエクスポーター 新しいドキュメント コミュニティ SD潜在空間での動画生成 モデルの説明可能性 日本語のStable Diffusion 高品質なファインチューニングモデル Stable Diffusionによるクロスアテンション制御 再利用可能なシード 画像から画像へのパイプライン 最も要望の多かった機能の1つは、画像から画像の生成を行うことです。このパイプラインでは、画像とプロンプトを入力すると、それに基づいて画像が生成されます! 公式のColabノートブックに基づいたコードを見てみましょう。 from diffusers import…

🧨 JAX / Flax での安定した拡散!
🤗 Hugging Face Diffusersはバージョン0.5.1からFlaxをサポートしています!これにより、Colab、Kaggle、またはGoogle Cloud PlatformなどのGoogle TPU上での超高速な推論が可能になります。 この投稿では、JAX / Flaxを使用して推論を実行する方法を示します。Stable Diffusionの動作詳細やGPUでの実行方法について詳細を知りたい場合は、このColabノートブックを参照してください。 一緒に進める場合は、上のボタンをクリックしてこの投稿をColabノートブックとして開きます。 まず、TPUバックエンドを使用していることを確認してください。このノートブックをColabで実行している場合は、上のメニューでランタイムを選択し、「ランタイムのタイプを変更」オプションを選択し、ハードウェアアクセラレータの設定でTPUを選択します。 JAXはTPUに限定されているわけではありませんが、TPUサーバーごとに8つのTPUアクセラレータが並列に動作するため、そのハードウェア上で輝きます。 セットアップ import jax num_devices = jax.device_count() device_type = jax.devices()[0].device_kind print(f"Found…

Apple SiliconでのCore MLを使用した安定した拡散を利用する
Appleのエンジニアのおかげで、Core MLを使用してApple SiliconでStable Diffusionを実行できるようになりました! このAppleのレポジトリは、🧨 Diffusersを基にした変換スクリプトと推論コードを提供しており、私たちはそれが大好きです!できるだけ簡単にするために、私たちは重みを変換し、モデルのCore MLバージョンをHugging Face Hubに保存しました。 更新:この投稿が書かれてから数週間後、私たちはネイティブのSwiftアプリを作成しました。これを使用して、自分自身のハードウェアでStable Diffusionを簡単に実行できます。私たちはMac App Storeにアプリをリリースし、他のプロジェクトがそれを使用できるようにソースコードも公開しました。 この投稿の残りの部分では、変換された重みを自分自身のコードで使用する方法や、追加の重みを変換する方法について説明します。 利用可能なチェックポイント 公式のStable Diffusionのチェックポイントはすでに変換されて使用できる状態です: Stable Diffusion v1.4:変換されたオリジナル Stable Diffusion v1.5:変換されたオリジナル Stable…

効率的で安定した拡散微調整のためのLoRAの使用
LoRA:Large Language Modelsの低ランク適応は、Microsoftの研究者によって導入された新しい技術で、大規模言語モデルの微調整の問題に取り組むためのものです。GPT-3などの数十億のパラメータを持つ強力なモデルは、特定のタスクやドメインに適応させるために微調整することが非常に高価です。LoRAは、事前学習済みモデルの重みを凍結し、各トランスフォーマーブロックにトレーニング可能な層(ランク分解行列)を注入することを提案しています。これにより、トレーニング可能なパラメータとGPUメモリの要件が大幅に削減されます。なぜなら、ほとんどのモデルの重みの勾配を計算する必要がないからです。研究者たちは、大規模言語モデルのトランスフォーマーアテンションブロックに焦点を当てることで、LoRAと完全なモデルの微調整と同等の品質を実現できることを発見しました。さらに、LoRAはより高速で計算量が少なくなります。 DiffusersのためのLoRA 🧨 LoRAは、当初大規模言語モデルに提案され、トランスフォーマーブロック上でデモンストレーションされたものですが、この技術は他の場所でも適用することができます。Stable Diffusionの微調整の場合、LoRAは画像表現とそれらを説明するプロンプトとの関連付けを行うクロスアテンションレイヤーに適用することができます。以下の図(Stable Diffusion論文から引用)の詳細は重要ではありませんが、黄色のブロックが画像とテキスト表現の関係を構築する役割を担っていることに注意してください。 私たちの知る限りでは、Simo Ryu(@cloneofsimo)がStable Diffusionに適応したLoRAの実装を最初に考案しました。興味深いディスカッションや洞察がたくさんあるGitHubのプロジェクトをご覧いただくために、彼らのGitHubプロジェクトをぜひご覧ください。 クロスアテンションレイヤーにLoRAトレーニング可能行列を深く注入するために、以前はDiffusersのソースコードを工夫(しかし壊れやすい方法)してハックする必要がありました。Stable Diffusionが私たちに示してくれたことの一つは、コミュニティが常に創造的な目的のためにモデルを曲げて適応する方法を見つけ出すことです。クロスアテンションレイヤーを操作する柔軟性を提供することは、xFormersなどの最適化技術を採用するのが容易になるなど、他の多くの理由で有益です。Prompt-to-Promptなどの創造的なプロジェクトには、これらのレイヤーに簡単にアクセスできる方法が必要です。そのため、ユーザーがこれを行うための一般的な方法を提供することにしました。私たちは昨年12月末からそのプルリクエストをテストしており、昨日のdiffusersリリースと共に公式にローンチしました。 私たちは@cloneofsimoと協力して、Dreamboothと完全な微調整方法の両方でLoRAトレーニングサポートを提供しています!これらの技術は次の利点を提供します: 既に議論されているように、トレーニングがはるかに高速です。 計算要件が低くなります。11 GBのVRAMを持つ2080 Tiで完全な微調整モデルを作成できました! トレーニングされた重みははるかに小さくなります。元のモデルが凍結され、新しいトレーニング可能な層が注入されるため、新しい層の重みを1つのファイルとして保存できます。そのサイズは約3 MBです。これは、UNetモデルの元のサイズの約1000分の1です。 私たちは特に最後のポイントに興奮しています。ユーザーが素晴らしい微調整モデルやドリームブーストモデルを共有するためには、最終モデルの完全なコピーを共有する必要がありました。それらを試すことを望む他のユーザーは、お気に入りのUIで微調整された重みをダウンロードする必要があり、膨大なストレージとダウンロードコストがかかります。現在、Dreamboothコンセプトライブラリには約1,000のDreamboothモデルが登録されており、おそらくさらに多くのモデルがライブラリに登録されていません。 LoRAを使用することで、他の人があなたの微調整モデルを使用できるようにするためのたった1つの3.29 MBのファイルを公開することができるようになりました。 (@mishig25への感謝、普通の会話で「dreamboothing」という動詞を使った最初の人です)。…

制御ネット(ControlNet)は、🧨ディフューザー内での使用です
Stable Diffusionが世界中で大流行した以来、人々は生成プロセスの結果に対してより多くの制御を持つ方法を探してきました。ControlNetは、ユーザーが生成プロセスを非常に大きな範囲でカスタマイズできる最小限のインターフェースを提供します。ControlNetを使用すると、ユーザーは深度マップ、セグメンテーションマップ、スクリブル、キーポイントなど、さまざまな空間的なコンテキストを使用して簡単に生成を条件付けることができます! 私たちは、驚くほどの一貫性を持つ写実的な写真に漫画の絵を変えることができます。 写実的なLofiガール また、それをあなたのインテリアデザイナーとして使用することもできます。 Before After あなたはスケッチのスクリブルを芸術的な絵に変えることができます。 Before After さらに、有名なロゴを生き生きとさせることもできます。 Before After ControlNetを使用すると、可能性は無限大です🌠 このブログ記事では、まずStableDiffusionControlNetPipelineを紹介し、さまざまな制御条件にどのように適用できるかを示します。さあ、制御しましょう! ControlNet: TL;DR ControlNetは、Lvmin ZhangとManeesh AgrawalaによってText-to-Image Diffusion Modelsに条件付き制御を追加することで導入されました。これにより、Stable DiffusionなどのDiffusionモデルに追加の条件として使用できるさまざまな空間的コンテキストをサポートするフレームワークが導入されます。ディフュージョンモデルの実装は、元のソースコードから適応されています。 ControlNetのトレーニングは次の手順で行われます:…
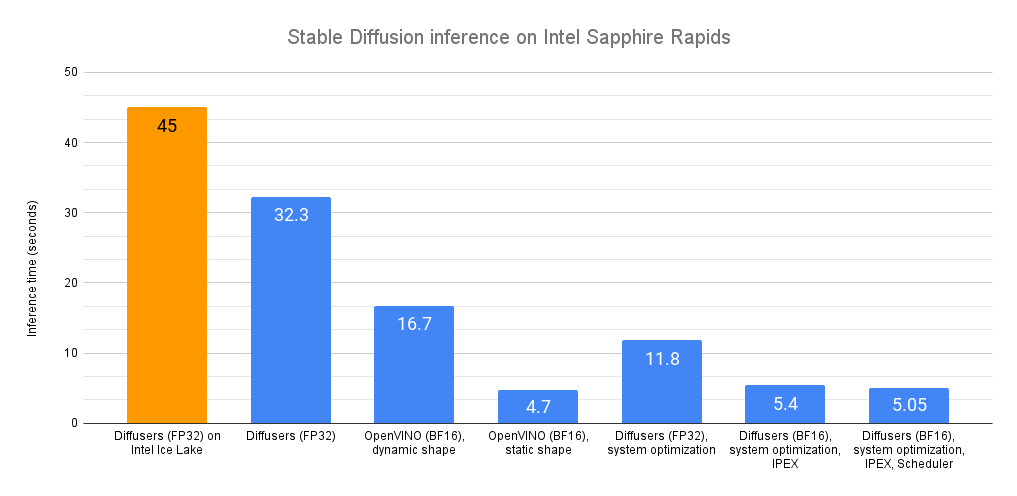
Intel CPU上での安定な拡散推論の高速化
最近、私たちは最新世代のIntel Xeon CPU(コードネームSapphire Rapids)を紹介しました。これには、ディープラーニングの高速化に対応した新しいハードウェア機能があります。また、これらを使用して自然言語処理のトランスフォーマーの分散微調整と推論を加速する方法も紹介しました。 この投稿では、Sapphire Rapids CPU上で安定拡散モデルを加速するための異なる技術を紹介します。次の投稿では、分散微調整について同様の内容を紹介します。 執筆時点では、Sapphire Rapidsサーバーにアクセスする最も簡単な方法は、Amazon EC2 R7izインスタンスファミリーを使用することです。まだプレビュー段階ですので、アクセスするためにはサインアップする必要があります。前の投稿と同様に、私はUbuntu 20.04 AMI(ami-07cd3e6c4915b2d18)を使用してr7iz.metal-16xlインスタンス(64 vCPU、512GB RAM)を使用しています。 さあ、始めましょう!コードサンプルはGitlabで利用できます。 Diffusersライブラリ Diffusersライブラリは、安定拡散モデルを使用して画像を生成するのが非常に簡単です。これらのモデルに詳しくない場合は、こちらの素晴らしいイラスト入りの紹介をご覧ください。 まず、必要なライブラリ(Transformers、Diffusers、Accelerate、PyTorch)を使用して仮想環境を作成しましょう。 virtualenv sd_inference source sd_inference/bin/activate pip…

Intel CPUのNNCFと🤗 Optimumを使用した安定したディフュージョンの最適化
潜在的な拡散モデルは、テキストから画像の生成問題を解決する際にゲームチェンジャーとなります。 安定した拡散は、コミュニティや産業界で広く採用されている最も有名な例の一つです。 安定した拡散モデルのアイデアはシンプルで魅力的です:ノイズベクトルから画像を複数の小さなステップで生成し、ノイズを潜在的な画像表現に洗練させます。 ただし、このようなアプローチは、全体的な推論時間を増加させ、クライアントマシンで展開された場合にユーザーエクスペリエンスの低下を引き起こします。 通常のように、強力なGPUがここで役立つことに注意することができますが、これに伴うコストも著しく増加します。 参考までに、H1’23では、8つのvCPUと64GBのRAMを備えた強力なCPU r6i.2xlargeインスタンスの価格は1時間あたり$0.504であり、同様のNVIDIA T4を搭載したg4dn.2xlargeインスタンスの価格は1時間あたり$0.75で、これは1.5倍以上です.. これにより、画像生成サービスは所有者とユーザーにとって非常に高価になります。 クライアントアプリケーションでは、GPUがまったくない場合もあります! これにより、安定した拡散パイプラインの展開は困難な問題となります。 過去5年間、OpenVINO Toolkitは高性能推論のための多くの機能をカプセル化しました。 最初はコンピュータビジョンモデルに設計されたものですが、現在でも最先端のモデルを含む多くのコンテンポラリーモデルにおいて、最高の推論パフォーマンスを示しています。 ただし、リソース制約のあるアプリケーションに安定した拡散モデルを最適化するには、ランタイム最適化にとどまらず、さらに進んだモデル最適化機能がOpenVINO Neural Network Compression Framework(NNCF)から必要とされます。 このブログ記事では、安定した拡散モデルの最適化の問題を概説し、CPUなどのリソース制約のあるHWで実行される場合に、そのようなモデルのレイテンシを大幅に削減するワークフローを提案します。 特に、PyTorchと比較して5.1倍の推論高速化と4倍のモデルフットプリントの削減を達成しました。 安定した拡散の最適化 安定した拡散パイプラインでは、UNetモデルが計算上最もコストがかかります。そのため、単一のモデルの最適化によって推論速度が大幅に向上します。 しかし、このモデルに対しては、従来のモデル最適化手法であるポストトレーニングの8ビット量子化は機能しないことがわかりました。その理由は2つあります。まず、セマンティックセグメンテーション、スーパーレゾリューションなどのピクセルレベル予測モデルは、タスクの複雑さにより、モデル最適化の観点では最も複雑なものの一つであり、モデルパラメータと構造の微調整が結果を多数の方法で崩してしまいます。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.