Learn more about Search Results Shell - Page 4

- You may be interested
- 「Meta AIは、社会的な具現化されたAIエー...
- 「LLMランドグラブ:AWS、Azure、およびGC...
- 人工知能に投資するのですか? 考慮すべき...
- 探索的なノートブックの使い方[ベストプラ...
- AWS Inferentia2を使用して、安定したディ...
- 『Gradioを使ったリテンションの理解』
- 「モノのインターネット:進化と例」
- (Samsung no AI to chippu gijutsu no mir...
- 「LLMを使用して、会話型のFAQ機能を搭載...
- A. Michael West 医療現場における人間と...
- 「生成型AI:CHATGPT、Dall-E、Midjourney...
- チューリングテスト、中国の部屋、そして...
- 「教師たちはAIチュータリングボットを試...
- 事前学習済みのViTモデルを使用した画像キ...
- 「Streamlit、OpenAI、およびElasticsearc...

「PIP、Conda、requirements.txtを忘れましょう!代わりにPoetryを使って、私に感謝してください」
「痛みのない依存関係管理がついに実現しました」

「ChatGPTの王座陥落:クロードが新しいAIリーダーとなった経緯」
世界を恥ずかしい思いさせる

fairseqのwmt19翻訳システムをtransformersに移植する
Stas Bekmanさんによるゲストブログ記事 この記事は、fairseq wmt19翻訳システムがtransformersに移植された方法をドキュメント化する試みです。 私は興味深いプロジェクトを探していて、Sam Shleiferさんが高品質の翻訳者の移植に取り組んでみることを提案してくれました。 私はFacebook FAIRのWMT19ニュース翻訳タスクの提出に関する短い論文を読み、オリジナルのシステムを試してみることにしました。 最初はこの複雑なプロジェクトにどう取り組むか分からず、Samさんがそれを小さなタスクに分解するのを手伝ってくれました。これが非常に助けになりました。 私は、両方の言語を話すため、移植中に事前学習済みのen-ru / ru-enモデルを使用することを選びました。ドイツ語は話せないので、de-en / en-deのペアで作業するのははるかに難しくなります。移植プロセスの高度な段階で出力を読んで意味を理解することで翻訳の品質を評価できることは、多くの時間を節約することができました。 また、最初の移植をen-ru / ru-enモデルで行ったため、de-en / en-deモデルが統合されたボキャブラリを使用していることに全く気づいていませんでした。したがって、2つの異なるサイズのボキャブラリをサポートするより複雑な作業を行った後、統合されたボキャブラリを動作させるのは簡単でした。 手抜きしましょう 最初のステップは、もちろん手抜きです。大きな努力をするよりも小さな努力をする方が良いです。したがって、fairseqへのプロキシとして機能し、transformersのAPIをエミュレートする数行のコードで短いノートブックを作成しました。 もし基本的な翻訳以外のことが必要なければ、これで十分でした。しかし、もちろん、完全な移植を行いたかったので、この小さな勝利の後、より困難な作業に移りました。 準備 この記事では、~/portingの下で作業していると仮定し、したがってこのディレクトリを作成します:…

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…

データセットとモデルにおけるDOI(デジタルオブジェクト識別子)の紹介
私たちの使命は、良い機械学習を民主化することです。それには、MLモデルやデータセットの再現性を高め、より良くドキュメント化し、使いやすく共有できるようなベストプラクティスが含まれます。 この課題を解決するために、喜んでお知らせしますが、ハブからモデルまたはデータセットのDOIを直接生成できるようになりました! DOIはリポジトリの設定から直接生成することができ、誰でもモデルまたはデータセットのページで「このモデル/データセットを引用する」とクリックすることであなたの作品を引用することができます🔥。 DOIとは何か、なぜ重要なのか? DOI(Digital Object Identifier)は、記事から図表、データセットやモデルなど、デジタルオブジェクトを一意に識別する文字列です。DOIはオブジェクトのメタデータに関連しており、オブジェクトのURL、バージョン、作成日、説明などが含まれます。DOIは研究や学術コミュニティでデジタルリソースを参照するための一般的に受け入れられた手段であり、書籍のISBNに相当します。 DOIを持つことで、モデルやデータセットに関する情報を見つけやすくし、世界と共有するための永続的なリンクを提供します。そのため、DOIを持つデータセットやモデルは永続的に存在し、サポートへの要求を行わない限り削除されることはありません。 Hugging FaceでDOIが割り当てられる方法は? 私たちはDataCiteと提携しており、登録されたハブのユーザーは自分のモデルやデータセットのDOIをリクエストすることができます。必要なメタデータを入力すると、新しい輝かしいDOIがもらえます🌟! モデルやデータセットの新しいバージョンがある場合、DOIは簡単に更新でき、以前のDOIのバージョンは古くなります。これにより、オブジェクトの特定のバージョンを参照するのが簡単になります。 私たちがさらに改善できるアイデアはありますか?このような多くの機能は、コミュニティのフィードバックから直接提供されています。ご意見やご要望があれば、お知らせください。または、huggingface/hub-docsの問題を開いてください🤗 このパートナーシップにはDataCiteチームに感謝します!また、このhub-docsのGitHubの問題に関する議論を開始し、育ててくれたAlix Leroyさん、Bram Vanroyさん、Daniel van Strienさん、Yoshitomo Matsubaraさんにも感謝します。

デプロイ可能な機械学習パイプラインの構築
多くのデータサイエンティストは、最初のコーディング体験をノートブックスタイルのユーザーインターフェースを通じて行いますノートブックは、探索のために欠かせないものであり、私たちのワークフローの重要な要素ですしかし...

混乱するデータサイエンティストのためのPATH変数:管理方法
WindowsとUnix系システムの両方で、PATHとは何か、およびそれにパスを追加する方法を理解する
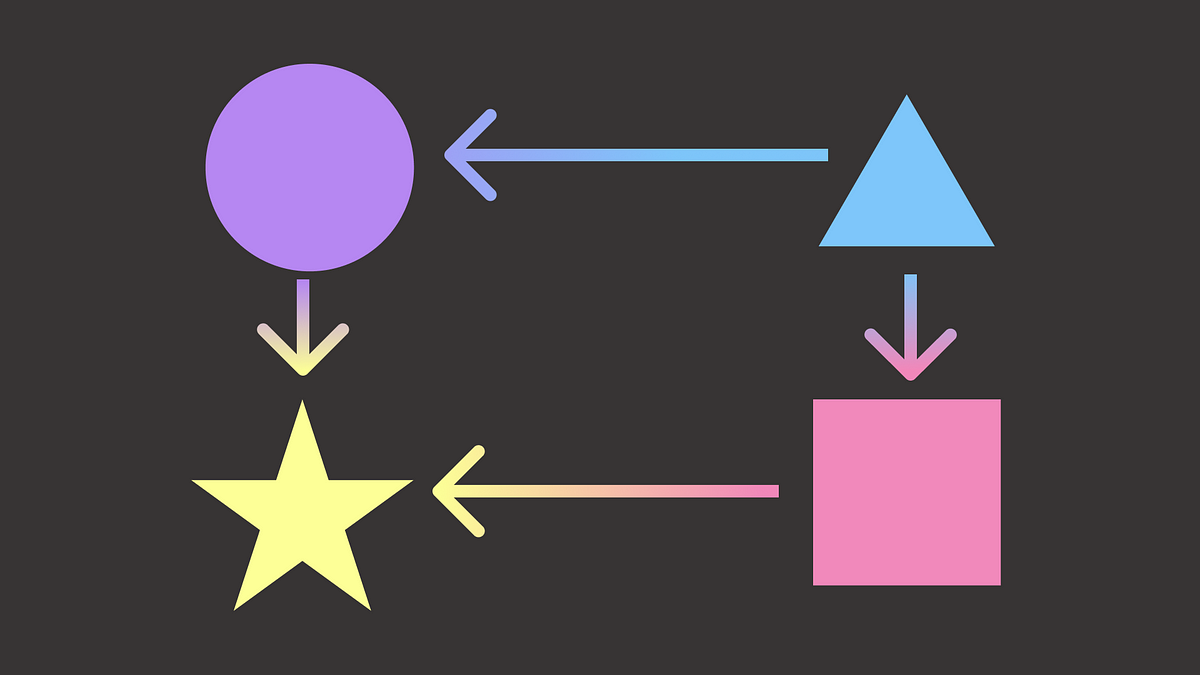
Pythonの依存関係管理:どのツールを選ぶべきですか?
あなたのデータサイエンスプロジェクトが拡大するにつれて、依存関係の数も増えますプロジェクトの環境を再現可能かつメンテナンス可能に保つために、効率的な依存関係を使用することが重要です...

AWS CDK を使用して Amazon SageMaker Studio ライフサイクル構成をデプロイします
Amazon SageMaker Studioは、機械学習(ML)のための最初の完全に統合された開発環境(IDE)ですStudioは、データを準備し、モデルを構築、トレーニング、展開するために必要なすべてのML開発ステップを実行できる単一のWebベースのビジュアルインターフェースを提供しますライフサイクル設定は、Studioライフサイクルイベントによってトリガーされるシェルスクリプトです [...]
生成型AIによる検索のスーパーチャージ
私たちは、ジェネレーティブAIを使用するSGE(Search Generative Experience)という名前の検索ラボの実験から始めます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.