Learn more about Search Results Faiss - Page 4

- You may be interested
- AWS Inferentia2は、AWS Inferentia1をベ...
- OpenAIのAI安全性へのアプローチ
- 「HuggingFace Transformers ツールとエー...
- オックスフォードの研究者たちは、「Farm3...
- ビデオゲームのGPUが人工知能の発展につな...
- 「アマゾン対アリババ:会話型AI巨大企業...
- ファイル共有を簡単にする
- 「AWSは、人工知能、機械学習、生成AIのガ...
- 「生成AIはその環境への足跡に値するのか?」
- 「接続から知能へ:ブロックチェーンとAI...
- 「ミリオンドルのホームサービスビジネス...
- メタAIは、リアルタイムに高品質の再照明...
- 「LLMアライメントの活用:AIをより利用し...
- 『Google Vertex AI Search&Conversation...
- バックフィリングの熟練:データエンジニ...

PDFとのチャット | PythonとOpenAIによるテキストの対話力の向上
イントロダクション 情報に満ちた世界で、PDFドキュメントは貴重なデータを共有および保存するための必須アイテムとなっています。しかし、PDFから洞察を抽出することは常に簡単ではありませんでした。それが「Chat with PDFs」が登場する理由です。この革新的なプロジェクトは、私たちがPDFと対話する方法を変革します。 この記事では、言語モデルライブラリ(LLM)のパワーとPyPDFのPythonライブラリの多様性を組み合わせた「Chat with PDFs」という魅力的なプロジェクトを紹介します。このユニークな融合により、PDFドキュメントと自然な会話を行うことができ、質問をすることや関連のある回答を得ることが容易になります。 学習目標 言語モデルライブラリ(LLM)についての洞察を得る。これは人間の言語パターンを理解し、意味のある応答を生成する高度なAIモデルです。 PyPDFを探求し、PDFの操作におけるテキスト抽出、マージ、分割などの機能を理解する。 言語モデルライブラリ(LLM)とPyPDFの統合により、PDFとの自然な会話を可能にする対話型チャットボットの作成方法を認識する。 この記事はData Science Blogathonの一環として公開されました。 言語モデルライブラリ(LLM)の理解 「Chat with PDFs」の中心にあるのは、言語モデルライブラリ(LLM)です。これは大量のテキストデータで訓練された高度なAIモデルです。これらは言語の専門家のような存在であり、人間の言語パターンを理解し、意味のある応答を生成することができます。 私たちのプロジェクトでは、LLMは対話型チャットボットの作成において重要な役割を果たしています。このチャットボットは、あなたの質問を処理し、PDFから必要な情報を理解することができます。PDFに隠された知識を活用して、役立つ回答と洞察を提供することができます。 PyPDFs – あなたのPDFスーパーアシスタント PyPDFは、PDFファイルとのやり取りを簡素化する多機能なPythonライブラリです。テキストの抽出、結合、分割など、さまざまな機能を利用できます。このライブラリは、PDFの処理と分析を効率化するために私たちのプロジェクトにおいて重要な役割を果たしています。 PyPDFを使用することで、PDFファイルをロードし、そのテキストを抽出することができます。これにより、効率的な処理と分析の準備が整いました。この強力なアシスタントを使用して、PDFとの対話をスムーズに行うことができます。…

「Amazon SageMaker 上での LLM を使用した多言語対応の知識型ビデオおよび音声の質疑応答システム」
「デジタルアセットは、ますますデジタル化される世界において、ビジネスにとって製品やサービス、文化、ブランドアイデンティティの重要な視覚的表現ですデジタルアセットは、記録されたユーザーの行動とともに、インタラクティブでパーソナライズされた体験を提供することにより、顧客エンゲージメントを促進し、企業がターゲットオーディエンスとより深い関係を築くことができます特定のデジタルアセットを効率的に見つけたり検索したりすることは、[…]」

「Pythonベクトルデータベースとベクトルインデックス:LLMアプリの設計」
ベクトルデータベースは、データポイント間での高速な類似度検索とスケーラビリティを可能にしますLLMアプリケーションでは、ベクトルインデックスを既存のストレージにアタッチすることで、完全なベクトルデータベースよりもアーキテクチャを簡素化することができますインデックスとデータベースの選択は、特殊なニーズ、既存のインフラストラクチャ、およびより広範な企業の要件に依存します
「LLMsを使用したEコマース製品検索の強化」
近年、ウェブ検索エンジンは、検索能力を向上させるために、急速に大規模言語モデル(LLM)を取り入れるようになっています最も成功した例の一つはBERTによってパワードされたGoogle検索です...

PythonでのZeroからAdvancedなPromptエンジニアリングをLangchainで
大規模言語モデル(LLM)の重要な要素は、これらのモデルが学習に使用するパラメータの数ですモデルが持つパラメータが多いほど、単語やフレーズの関係をより理解することができますつまり、数十億のパラメータを持つモデルは、さまざまな創造的なテキスト形式を生成し、開放的な質問に回答する能力を持っています

「GPTCacheとは:LLMクエリセマンティックキャッシュの開発に役立つライブラリを紹介します」
ChatGPTと大規模言語モデル(LLM)は非常に柔軟性があり、多くのプログラムの作成が可能です。ただし、LLM APIの呼び出しに関連するコストは、アプリケーションが人気を集め、トラフィック量が増加するときに重要になる可能性があります。多くのクエリを処理する場合、LLMサービスには長い待ち時間が生じることもあります。 この困難に立ち向かうために、研究者はGPTCacheというプロジェクトを開発しました。GPTCacheは、LLMの回答を格納するためのセマンティックキャッシュを作成することを目指しています。オープンソースのGPTCacheプログラムは、LLMの出力回答をキャッシュすることにより、LLMを高速化することができます。キャッシュにリクエストされた応答がすでに格納されている場合、それを取得する時間を大幅に短縮することができます。 GPTCacheは柔軟でシンプルであり、どのアプリケーションにも適しています。OpenAIのChatGPTなど、多くの言語学習機械(LLM)と互換性があります。 どのように動作するのか? GPTCacheは、LLMの最終的な応答をキャッシュします。キャッシュは、最近使用された情報を迅速に取得するために使用されるメモリバッファです。新しいリクエストがLLMに送信されるたびに、GPTCacheはまずキャッシュを調べて要求された応答が既にそこに格納されているかどうかを判断します。キャッシュ内で応答が見つかった場合、すぐに返されます。そうでない場合は、LLMが応答を生成してキャッシュに追加します。 GPTCacheのモジュラーアーキテクチャにより、カスタムのセマンティックキャッシュソリューションを簡単に実装することができます。ユーザーはさまざまな設定を選択することで、各モジュールとの経験をカスタマイズすることができます。 LLMアダプターは、さまざまなLLMモデルで使用されるAPIとリクエストプロトコルを統一し、それらをOpenAI APIで標準化します。LLMアダプターは、コードの書き直しや新しいAPIの理解を必要とせずにLLMモデル間を移動できるため、テストと実験を簡素化します。 埋め込み生成器は、要求されたモデルを使用して埋め込みを作成し、類似性検索を実行します。サポートされているモデルでは、OpenAIの埋め込みAPIを使用できます。これには、GPTCache/paraphrase-albert-onnxモデルを使用するONNX、Hugging Face埋め込みAPI、Cohere埋め込みAPI、fastText埋め込みAPI、SentenceTransformers埋め込みAPIが含まれます。 キャッシュストレージでは、ChatGPTなどのLLMからの応答が取得できるまで保持されます。2つのエンティティが意味的に類似しているかどうかを判断する際には、キャッシュされた応答が取得され、要求されたパーティーに送信されます。GPTCacheはさまざまなデータベース管理システムと互換性があります。ユーザーは、パフォーマンス、拡張性、および最も一般的にサポートされているデータベースのコストに関する要件を最も満たすデータベースを選択することができます。 ベクトルストアの選択肢:GPTCacheには、オリジナルのリクエストから派生した埋め込みを使用して、K個の最も類似したリクエストを特定するベクトルストアモジュールが含まれています。この機能を使用すると、2つのリクエストがどれだけ類似しているかを判断することができます。さらに、GPTCacheはMilvus、Zilliz Cloud、FAISSなどの複数のベクトルストアをサポートし、それらとの作業に対して簡単なインターフェースを提供します。ユーザーは、さまざまなベクトルストアオプションを選択できます。これらのオプションのいずれかが、GPTCacheの類似性検索のパフォーマンスに影響を与える可能性があります。さまざまなベクトルストアをサポートすることで、GPTCacheは適応性があり、さまざまなユースケースとユーザーの要件を満たすことができます。 GPTCacheキャッシュマネージャーは、キャッシュストレージとベクトルストアコンポーネントのエビクションポリシーを管理します。キャッシュが一杯になったときに新しいデータのためのスペースを作るために、置換ポリシーが古いデータを削除するかどうかを決定します。 類似性評価器の情報は、GPTCacheのキャッシュストレージとベクトルストアのセクションから取得されます。入力リクエストをベクトルストア内のリクエストと比較することで、類似度を測定します。リクエストがキャッシュから提供されるかどうかは、類似度の程度に依存します。GPTCacheは類似性アルゴリズムを使用してキャッシュの一致を判断する能力を持つため、さまざまなユースケースとユーザーの要件に適応することができます。 特徴と利点 GPTCacheによるLLMクエリの待ち時間の短縮により、応答性と速度が向上します。 トークンベースおよびリクエストベースの価格体系により、LLMサービスに共通のコスト削減が可能です。GPTCacheはAPIの呼び出し回数を制限することで、サービスのコストを削減することができます。 GPTCacheはLLMサービスからの作業をオフロードする能力を持つため、スケーラビリティが向上します。リクエスト数が増えるにつれて、ピークの効率で運営を続けるのに役立ちます。 GPTCacheの助けを借りて、LLMアプリケーションの作成に関連するコストを最小限に抑えることができます。LLMで生成されたデータをキャッシュしたり、模擬したりすることで、LLMサービスにAPIリクエストを行わずにアプリをテストすることができます。 GPTCacheは、選択したアプリケーション、LLM(ChatGPT)、キャッシュストア(SQLite、PostgreSQL、MySQL、MariaDB、SQL Server、またはOracle)、およびベクトルストア(FAISS、Milvus、Ziliz Cloud)と連携して使用することができます。GPTCacheプロジェクトの目標は、毎回ゼロから始めるのではなく、できる限り以前に生成された返信を再利用することによって、GPTベースのアプリケーションで言語モデルを最も効率的に活用することです。
類似検索、パート6:LSHフォレストによるランダム射影
「類似検索」とは、クエリが与えられた場合に、データベース内のすべてのドキュメントの中から、それに最も類似したドキュメントを見つけることを目指す問題ですデータサイエンスにおいては、類似検索はしばしばNLP(自然言語処理)で現れます...

OpenAIを使用してカスタムチャットボットを開発する
はじめに チャットボットは自動化されたサポートと個別の体験を提供し、ビジネスが顧客とつながる方法を革新しました。人工知能(AI)の最新の進展により、チャットボットの機能性の基準が引き上げられました。この詳細な書籍では、強力な言語モデルで知られるAIプラットフォームのリーディングカンパニーであるOpenAIを使用してカスタムチャットボットを作成するための詳細な手順が提供されています。 この記事はData Science Blogathonの一環として公開されました。 チャットボットとは何ですか? チャットボットは人間の会話を模倣するコンピュータプログラムです。自然言語処理(NLP)の技術を使用して、ユーザーの言っていることを理解し、関連性のある助言を提供します。 大量のデータセットと優れた機械学習アルゴリズムの利用可能性により、チャットボットは近年ますます賢くなっています。これらの機能により、チャットボットはユーザーの意図をより良く把握し、より本物らしい返答を提供することができます。 チャットボットの具体的な利用例: 顧客サービスのチャットボットは、よく寄せられる質問に答えて、消費者に24時間体制でサポートを提供します。 マーケティングのチャットボットは、リードの質を確認し、リードを生成し、製品やサービスに関する質問に答えるのを支援することができます。 教育のチャットボットは、個別指導を提供し、学生が自分のペースで学ぶことができるようにします。 医療のチャットボットは、健康に関する情報を提供し、薬に関する質問に答え、患者を医師や他の医療専門家とつなげることができます。 OpenAIの紹介 OpenAIは人工知能の研究開発の最前線にあります。自然言語の解釈と生成に優れた言語モデルの開発に先駆けて取り組んでいます。 OpenAIは、GPT-4、GPT-3、Text-davinciなどの高度な言語モデルを提供しており、チャットボットの構築などのNLP活動に広く使用されています。 チャットボットの利点 コーディングと実装に入る前に、チャットボットの利点を理解しましょう。 24時間365日の利用可能性: チャットボットはユーザーに24時間体制でサポートを提供し、人間の顧客サービス担当者の制約をなくし、ビジネスが顧客の要求に対応できるようにします。 改善された顧客サービス: チャットボットは頻繁に問い合わせられる質問に迅速かつ正確に応答することができます。これにより、顧客サービス全体の品質が向上します。 コスト削減: ビジネスは顧客サポートの業務を自動化し、大規模なサポートスタッフの必要性を減らすことで、長期的に多額の費用を節約することができます。…
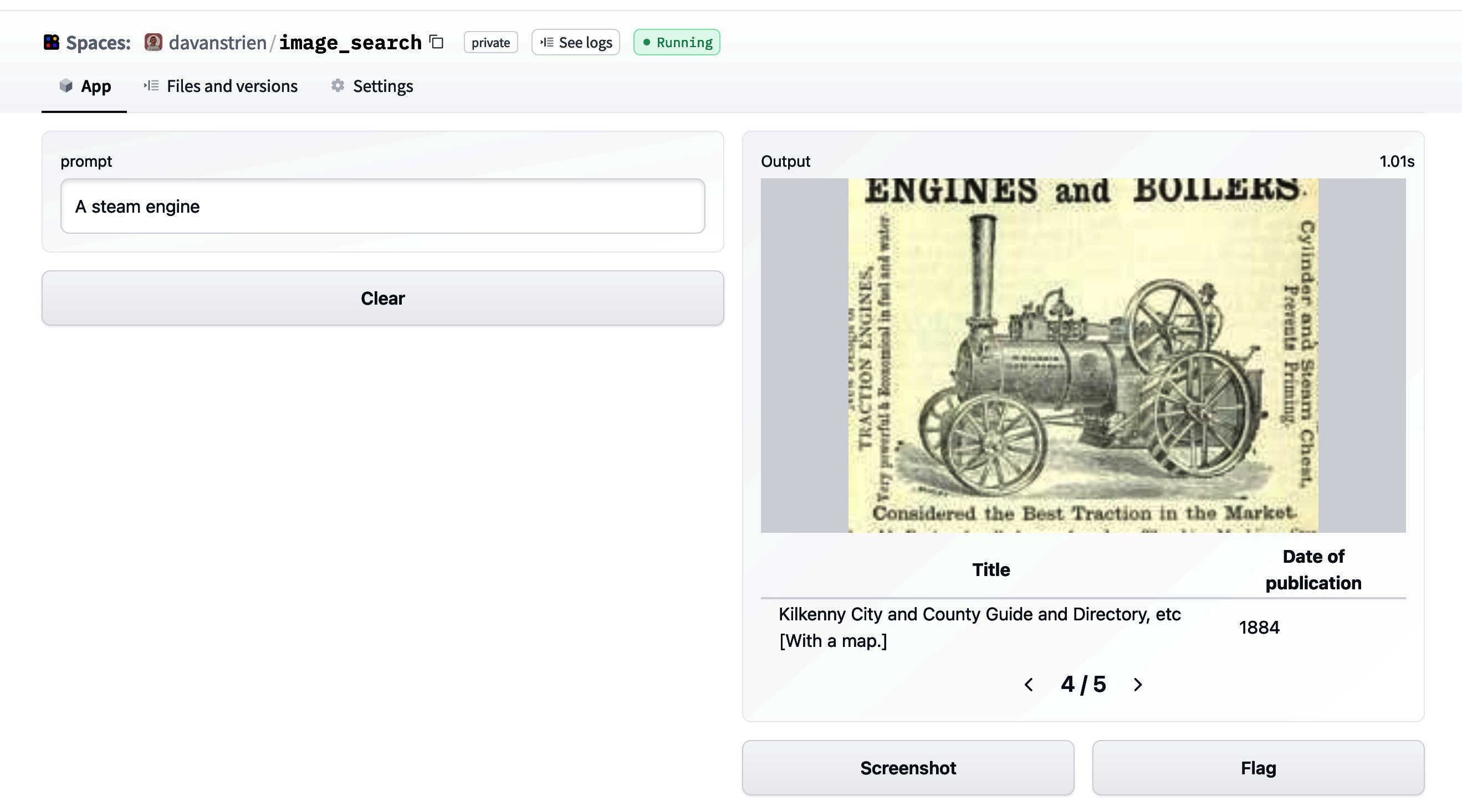
🤗データセットを使った画像検索
🤗 datasetsは、データセットに簡単にアクセスして共有することができるライブラリです。また、メモリに収まらないデータを効率的に処理することも容易にします。 datasetsが最初にリリースされた当初は、主にテキストデータと関連していました。しかし、最近では、datasetsは音声や画像に対するサポートを増やしています。特に、画像のためのdatasetsの機能タイプが追加されました。以前のブログ投稿では、datasetsと🤗 transformersを組み合わせて画像分類モデルのトレーニング方法を紹介しました。このブログ投稿では、datasetsと他のいくつかのライブラリを組み合わせて画像検索アプリケーションを作成する方法を見ていきます。 まず、datasetsをインストールします。画像を扱うために、pillowもインストールします。さらに、sentence_transformersとfaissも必要です。これらについては後ほど詳しく説明します。また、richもインストールします。ここでは簡単に使用するだけですが、非常に便利なパッケージなので、ぜひ詳しく探索してみてください! !pip install datasets pillow rich faiss-gpu sentence_transformers まずは、画像の特徴を見てみましょう。素晴らしいライブラリであるrichを使用して、Pythonオブジェクト(関数、クラスなど)を調べることができます。 from rich import inspect import datasets inspect(datasets.Image, help=True) ╭───────────────────────── <class 'datasets.features.image.Image'>…

埋め込みを使った始め方
ノートブックコンパニオンを使用したこのチュートリアルをチェックしてください: 埋め込みの理解 埋め込みは、テキスト、ドキュメント、画像、音声などの情報の数値表現です。この表現は、埋め込まれているものの意味を捉え、多くの産業アプリケーションに対して堅牢です。 テキスト「投票の主な利点は何ですか?」に対する埋め込みは、たとえば、384個の数値のリスト(例:[0.84、0.42、…、0.02])でベクトル空間で表現されることがあります。このリストは意味を捉えているため、異なる埋め込み間の距離を計算して、2つの文の意味がどれだけ一致するかを判断するなど、興味深いことができます。 埋め込みはテキストに限定されません!画像の埋め込み(たとえば、384個の数値のリスト)を作成し、テキストの埋め込みと比較して文が画像を説明しているかどうかを判断することもできます。この概念は、画像検索、分類、説明などの強力なシステムに適用されています! 埋め込みはどのように生成されるのでしょうか?オープンソースのライブラリであるSentence Transformersを使用すると、画像やテキストから最先端の埋め込みを無料で作成することができます。このブログでは、このライブラリを使用した例を紹介しています。 埋め込みの用途は何ですか? 「[…] このMLマルチツール(埋め込み)を理解すると、検索エンジンからレコメンデーションシステム、チャットボットなど、さまざまなものを構築できます。データサイエンティストやMLの専門家である必要はありませんし、大規模なラベル付けされたデータセットも必要ありません。」- デール・マルコウィッツ、Google Cloud。 情報(文、ドキュメント、画像)が埋め込まれると、創造性が発揮されます。いくつかの興味深い産業アプリケーションでは、埋め込みが使用されます。たとえば、Google検索ではテキストとテキスト、テキストと画像をマッチングさせるために埋め込みを使用しています。Snapchatでは、「ユーザーに適切な広告を適切なタイミングで提供する」ために埋め込みを使用しています。Meta(Facebook)では、ソーシャルサーチに埋め込みを使用しています。 埋め込みから知識を得る前に、これらの企業は情報を埋め込む必要がありました。埋め込まれたデータセットを使用することで、アルゴリズムは素早く検索、ソート、グループ化などを行うことができます。ただし、これは費用がかかり、技術的にも複雑な場合があります。この投稿では、シンプルなオープンソースのツールを使用して、データセットを埋め込み、分析する方法を紹介します。 埋め込みの始め方 小規模なよく寄せられる質問(FAQ)エンジンを作成します。ユーザーからのクエリを受け取り、最も類似したFAQを特定します。米国社会保障メディケアFAQを使用します。 しかし、まず、データセットを埋め込む必要があります(他のテキストでは、エンコードと埋め込みの用語を交換可能に使用します)。Hugging FaceのInference APIを使用すると、簡単なPOSTコールを使用してデータセットを埋め込むことができます。 質問の意味を埋め込みが捉えるため、異なる埋め込みを比較してどれだけ異なるか、または類似しているかを確認することができます。これにより、クエリに最も類似した埋め込みを取得し、最も類似したFAQを見つけることができます。このメカニズムの詳細な説明については、セマンティックサーチのチュートリアルをご覧ください。 要するに、以下の手順を実行します: Inference APIを使用してメディケアのFAQを埋め込む。 埋め込まれた質問を無料ホスティングするためにHubにアップロードする。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.