Learn more about Search Results Ding et al. 2021 - Page 4

- You may be interested
- 「NVIDIA H100 Tensor Core GPUを使用した...
- 「世界は誰も知らない60年前のコードに依...
- 「Amazon SageMakerを使用して数千のMLモ...
- 「LLMsの信頼性のあるフューショットプロ...
- オムニヴォアに出会おう:スタートアップ...
- データベーススキーマのレトロエンジニア...
- 「産業4.0の未来を探索する:プロセスマイ...
- レコメンドシステムの評価指標 — 概要
- 「ドラッグ&ドロップ、分析:ノーコード...
- 「CLIP、直感的にも網羅的に解説」
- 「LangChain、Activeloop、およびDeepInfr...
- いつでもどんな人にでもメッセージを明確...
- データのアルトリズム:企業エンジンのデ...
- 「トランスフォーマーは長い入力をどのよ...
- コードのための大規模な言語モデルの構築...

🤗 Transformersを使用して、Wav2Vec2を使用して大規模なファイルで自動音声認識を行う方法
Tl;dr: この投稿では、Connectionist Temporal Classification(CTC)アーキテクチャの特性を活用して、任意の長さのファイルやライブ推論中でも非常に良い品質の自動音声認識(ASR)を実現する方法を説明します。 Wav2Vec2は、音声認識のための人気のある事前学習モデルです。Meta AI Researchによって2020年9月にリリースされ、この新しいアーキテクチャは、自己教師あり事前学習における音声認識の進歩を促進しました(例:G. Ng et al.、2021年、Chen et al.、2021年、Hsu et al.、2021年、Babu et al.、2021年)。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは、現在月間25万回以上ダウンロードされています。 Wav2Vec2は、その核としてtransformersモデルを使用しており、transformersの注意点の1つは、通常、扱えるシーケンスの長さに限界があることです。それは位置符号化を使用するためではなく(この場合は違います)、単純にtransformersの注意コストが実際にはO(n²)となり、非常に大きなシーケンス長を使用すると複雑さやメモリの使用量が爆発します。したがって、非常に長いファイルでさえWav2Vec2を実行することはできません(たとえA100のような非常に大きなGPUを使用しても)。プログラムはクラッシュします。試してみましょう! pip install transformers from transformers…

注釈付き拡散モデル
このブログ記事では、Denoising Diffusion Probabilistic Models(DDPM、拡散モデル、スコアベースの生成モデル、または単にオートエンコーダーとも呼ばれる)について詳しく見ていきます。これらのモデルは、(非)条件付きの画像/音声/ビデオの生成において、驚くべき結果が得られています。具体的な例としては、OpenAIのGLIDEやDALL-E 2、University of HeidelbergのLatent Diffusion、Google BrainのImageGenなどがあります。 この記事では、(Hoら、2020)による元のDDPMの論文を取り上げ、Phil Wangの実装をベースにPyTorchでステップバイステップで実装します。なお、このアイデアは実際には(Sohl-Dicksteinら、2015)で既に導入されていました。ただし、改善が行われるまでには(Stanford大学のSongら、2019)を経て、Google BrainのHoら、2020)が独自にアプローチを改良しました。 拡散モデルにはいくつかの視点がありますので、ここでは離散時間(潜在変数モデル)の視点を採用していますが、他の視点もチェックしてください。 さあ、始めましょう! from IPython.display import Image Image(filename='assets/78_annotated-diffusion/ddpm_paper.png') まず必要なライブラリをインストールしてインポートします(PyTorchがインストールされていることを前提としています)。 !pip install -q -U…

最初のデシジョン トランスフォーマーをトレーニングする
以前の投稿で、transformersライブラリでのDecision Transformersのローンチを発表しました。この新しい技術は、Transformerを意思決定モデルとして使用するというもので、ますます人気が高まっています。 今日は、ゼロからオフラインのDecision Transformerモデルをトレーニングして、ハーフチータを走らせる方法を学びます。このトレーニングは、Google Colab上で直接行います。こちらで見つけることができます👉 https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb *ジムのHalfCheetah環境でオフラインRLを使用して学習された「専門家」Decision Transformersモデルです。 ワクワクしませんか?では、始めましょう! Decision Transformersとは何ですか? Decision Transformersのトレーニング データセットの読み込みとカスタムデータコレータの構築 🤗 transformers Trainerを使用したDecision Transformerモデルのトレーニング 結論 次は何ですか? 参考文献 Decision Transformersとは何ですか? Decision…

人間のフィードバックからの強化学習(RLHF)の説明
この記事は以下の言語に翻訳されています:中国語(簡体字)とベトナム語。他の言語に翻訳に興味がありますか?nathan at huggingface.co までお問い合わせください。 言語モデルは、過去数年間に人間の入力プロンプトから多様で魅力的なテキストを生成する能力を示してきました。しかし、「良い」テキストとは何かは、主観的で文脈に依存するため、本質的に定義するのは難しいです。創造性を求める物語の執筆などの多くのアプリケーションでは、真実であるべき情報の断片、または実行可能なコードのスニペットなどが必要です。 これらの属性を捉えるための損失関数を作成することは困難であり、ほとんどの言語モデルはまだ単純な次のトークン予測の損失(例:クロスエントロピー)で訓練されています。損失自体の欠点を補うために、人々はBLEUやROUGEなど、人間の優先順位をより適切に捉えるように設計されたメトリクスを定義しています。これらのメトリクスは、パフォーマンスを測定する上で損失関数自体より適しているものの、生成されたテキストを単純なルールで参照テキストと比較するだけなので、制約もあります。生成されたテキストに対する人間のフィードバックをパフォーマンスの指標として使用するか、さらに進んでそのフィードバックを損失としてモデルを最適化することができれば、素晴らしいことではないでしょうか?それが「人間のフィードバックによる強化学習(RLHF)」のアイデアです。強化学習の手法を使用して、言語モデルを人間のフィードバックで直接最適化するのです。RLHFにより、言語モデルは一般的なテキストデータのコーパスで訓練されたモデルを複雑な人間の価値に合わせることができるようになりました。 RLHFの最近の成功例は、ChatGPTでの使用です。ChatGPTの印象的な能力を考慮して、RLHFについて説明してもらいました: それは驚くほどうまくいっていますが、すべてをカバーしているわけではありません。それらのギャップを埋めましょう! 人間のフィードバックによる強化学習(RL from human preferencesとも呼ばれます)は、複数のモデルのトレーニングプロセスと異なる展開の段階を伴うため、難しい概念です。このブログ記事では、トレーニングプロセスを次の3つの主要なステップに分解します: 言語モデル(LM)の事前トレーニング データの収集と報酬モデルのトレーニング 強化学習によるLMの微調整 まず、言語モデルの事前トレーニングについて見ていきましょう。 言語モデルの事前トレーニング RLHFの出発点として、クラシカルな事前トレーニング目標で既に事前トレーニングされた言語モデルを使用します(詳細については、このブログ記事を参照してください)。OpenAIは、最初の人気のあるRLHFモデルであるInstructGPTに対して、より小さなバージョンのGPT-3を使用しました。Anthropicは、このタスクのためにトレーニングされた1,000万から520億のパラメータを持つトランスフォーマーモデルを使用しました。DeepMindは、2800億のパラメータモデルGopherを使用しました。 この初期モデルは、追加のテキストや条件で微調整することもできますが、必ずしも必要ではありません。たとえば、OpenAIは「好ましい」とされる人間が生成したテキストを微調整し、Anthropicは彼らの「助けになり、正直で無害な」基準に基づいて元のLMを蒸留することで、RLHFのための初期LMを生成しました。これらは共に、私が高価な増強データと呼ぶものの一部ですが、RLHFを理解するために必要なテクニックではありません。 一般的に、「どのモデル」がRLHFの出発点として最適かは明確な答えがありません。このブログ記事では、RLHFのトレーニングにおけるオプションの設計空間が完全に探索されていないという共通のテーマになります。 次に、言語モデルが必要なデータを生成して、人間の優先順位がシステムに統合される「報酬モデル」をトレーニングする必要があります。 報酬モデルのトレーニング 人間の優先順位に合わせてキャリブレーションされた報酬モデル(RM、優先モデルとも呼ばれます)を生成することは、RLHFの比較的新しい研究の出発点です。その基本的な目標は、テキストのシーケンスを受け取り、数値で人間の優先順位を表すべきスカラー報酬を返すモデルまたはシステムを取得することです。システムはエンドツーエンドのLMであるか、報酬を出力するモジュラーシステム(例:モデルが出力をランク付けし、ランキングが報酬に変換される)である場合があります。出力がスカラーの報酬であることは、既存のRLアルゴリズムが後のRLHFプロセスにシームレスに統合されるために重要です。 報酬モデリングのためのこれらの言語モデルは、別の微調整された言語モデルまたは好みのデータでスクラッチからトレーニングされた言語モデルのいずれかです。例えば、Anthropicは、これらのモデルを事前トレーニング(好みモデルの事前トレーニング、PMP)の後に初期化するために専門の微調整方法を使用しています。彼らは、これが微調整よりもサンプル効率が高いと結論付けましたが、報酬モデリングのバリエーションの中で明確な最良の選択肢はありません。…

CLIPSegによるゼロショット画像セグメンテーション
このガイドでは、🤗 transformersを使用して、ゼロショットの画像セグメンテーションモデルであるCLIPSegを使用する方法を紹介します。CLIPSegは、ロボットの知覚、画像補完など、さまざまなタスクに使用できるラフなセグメンテーションマスクを作成します。より正確なセグメンテーションマスクが必要な場合は、Segments.aiでCLIPSegの結果を改善する方法も紹介します。 画像セグメンテーションは、コンピュータビジョンの分野でよく知られたタスクです。これにより、コンピュータは画像内の物体を知るだけでなく(分類)、画像内の物体の位置を知ることもできます(検出)、さらには物体の輪郭も知ることができます。物体の輪郭を知ることは、ロボット工学や自動運転などの分野では重要です。たとえば、ロボットは物体の形状を正しく把握するために、その形状を知る必要があります。セグメンテーションは、画像補完と組み合わせることもでき、ユーザーが画像のどの部分を置き換えたいかを説明することができます。 ほとんどの画像セグメンテーションモデルの制限の1つは、固定されたカテゴリのリストでのみ機能するということです。たとえば、オレンジでトレーニングされたセグメンテーションモデルを使用して、リンゴをセグメント化することはできません。セグメンテーションモデルに追加のカテゴリを教えるには、新しいカテゴリのデータをラベル付けし、新しいモデルをトレーニングする必要があります。これは費用と時間がかかる場合があります。しかし、さらなるトレーニングなしにほとんどどのような種類のオブジェクトでもセグメント化できるモデルがあったらどうでしょうか?それがCLIPSeg、ゼロショットのセグメンテーションモデルが達成するものです。 現時点では、CLIPSegにはまだ制限があります。たとえば、モデルは352 x 352ピクセルの画像を使用するため、出力はかなり低解像度です。したがって、モダンなカメラの画像を使用すると、ピクセルパーフェクトな結果を期待することはできません。より正確なセグメンテーションを必要とする場合、前のブログ記事で示したように、最新のセグメンテーションモデルを微調整することができます。その場合、CLIPSegを使用してラフなラベルを生成し、Segments.aiなどのラベリングツールでそれらを調整することができます。それについて説明する前に、まずCLIPSegの動作を見てみましょう。 CLIP: CLIPSegの背後にある魔法のモデル CLIP(Contrastive Language–Image Pre-training)は、OpenAIが2021年に開発したモデルです。CLIPに画像またはテキストの一部を与えると、CLIPは入力の抽象的な表現を出力します。この抽象的な表現、または埋め込みとも呼ばれるものは、実際にはベクトル(数値のリスト)です。このベクトルは、高次元空間のポイントと考えることができます。CLIPは、似たような画像とテキストの表現も似たようにするようにトレーニングされています。つまり、画像とそれに合致するテキストの説明を入力すると、画像とテキストの表現が似ている(つまり、高次元のポイントが近くにある)ことになります。 最初はあまり役に立たないように思えるかもしれませんが、実際には非常に強力です。例えば、CLIPを使用して訓練されたことがないタスクで画像を分類する方法を簡単に見てみましょう。画像を分類するには、画像と選択肢となる異なるカテゴリをCLIPに入力します(例えば、画像と「りんご」、「オレンジ」などの単語を入力します)。CLIPは、画像と各カテゴリの埋め込みを返します。今、画像の埋め込みに最も近いカテゴリの埋め込みを確認するだけです。これで完了です!まるで魔法のようですね。 CLIPを使用した画像分類の例(出典)。 さらに、CLIPは分類だけでなく、画像検索(これが分類と似ていることがわかりますか?)、テキストから画像への変換モデル(DALL-E 2はCLIPで動作します)、物体検出(OWL-ViT)などにも使用できます。そして、私たちにとって最も重要なのは、画像セグメンテーションです。これでCLIPが機械学習において本当に画期的なものである理由がお分かりいただけるでしょう。 CLIPが非常にうまく機能する理由は、モデルがテキストのキャプション付きの膨大なデータセットでトレーニングされたからです。そのデータセットには、インターネットから取得した4億枚の画像テキストペアが含まれています。これらの画像にはさまざまなオブジェクトや概念が含まれており、CLIPはそれぞれのオブジェクトに対して表現を生成するのに優れています。 CLIPSeg: CLIPによる画像セグメンテーション CLIPSegは、CLIPの表現を使用して画像セグメンテーションマスクを作成するモデルです。Timo LüddeckeさんとAlexander Eckerさんによって公開されました。彼らは、CLIPモデルを凍結したまま、TransformerベースのデコーダをCLIPモデルの上にトレーニングすることで、ゼロショット画像セグメンテーションを達成しました。デコーダは、画像のCLIP表現とセグメンテーションしたい対象のCLIP表現を入力として受け取り、これらの2つの入力を使用して、CLIPSegデコーダは2値のセグメンテーションマスクを作成します。より詳しく言うと、デコーダはセグメンテーションしたい画像の最終的なCLIP表現だけでなく、CLIPのいくつかのレイヤーの出力も使用します。 ソース デコーダは、PhraseCutデータセットでトレーニングされています。このデータセットには、340,000以上のフレーズと対応する画像セグメンテーションマスクが含まれています。著者たちはまた、データセットのサイズを拡大するためにさまざまな拡張方法も試みました。ここでの目標は、データセットに存在するカテゴリだけでなく、未知のカテゴリもセグメンテーションできるようにすることです。実験の結果、デコーダは未知のカテゴリにも対応できることが示されています。…

カカオブレインからの新しいViTとALIGNモデル
Kakao BrainとHugging Faceは、新しいオープンソースの画像テキストデータセットCOYO(700億ペア)と、それに基づいてトレーニングされた2つの新しいビジュアル言語モデル、ViTとALIGNをリリースすることを発表しました。ALIGNモデルが無料かつオープンソースで公開されるのは初めてであり、ViTとALIGNモデルのリリースにトレーニングデータセットが付属するのも初めてです。 Kakao BrainのViTとALIGNモデルは、オリジナルのGoogleモデルと同じアーキテクチャとハイパーパラメータに従っていますが、オープンソースのCOYOデータセットでトレーニングされています。GoogleのViTとALIGNモデルは、巨大なデータセット(ViTは3億枚の画像、ALIGNは18億の画像テキストペア)でトレーニングされていますが、データセットが公開されていないため、複製することはできません。この貢献は、データへのアクセスも含めて、視覚言語モデリングを再現したい研究者にとって特に価値があります。Kakao ViTとALIGNモデルの詳細な情報は、こちらで確認できます。 このブログでは、新しいCOYOデータセット、Kakao BrainのViTとALIGNモデル、およびそれらの使用方法について紹介します!以下が主なポイントです: 史上初のオープンソースのALIGNモデル! オープンソースのデータセットCOYOでトレーニングされた初のViTとALIGNモデル Kakao BrainのViTとALIGNモデルは、Googleのバージョンと同等のパフォーマンスを示します ViTとALIGNのデモはHFで利用可能です!選んだ画像サンプルでオンラインでViTとALIGNのデモを試すことができます! パフォーマンスの比較 Kakao BrainのリリースされたViTとALIGNモデルは、Googleが報告した内容と同等またはそれ以上のパフォーマンスを示します。Kakao BrainのALIGN-B7-Baseモデルは、トレーニングペアが少ない(700億ペア対18億ペア)にもかかわらず、Image KNN分類タスクではGoogleのALIGN-B7-Baseと同等のパフォーマンスを発揮し、MS-COCO検索の画像からテキスト、テキストから画像へのタスクではより優れた結果を示します。Kakao BrainのViT-L/16は、モデル解像度384および512でImageNetとImageNet-ReaLで評価された場合、GoogleのViT-L/16と同様のパフォーマンスを発揮します。つまり、コミュニティはKakao BrainのViTとALIGNモデルを使用して、特にトレーニングデータへのアクセスが必要な場合に、GoogleのViTとALIGNリリースを再現することができます。最先端の性能を発揮しつつ、オープンソースで透明性のあるこれらのモデルのリリースを見ることができるのはとても興奮します! COYOデータセット これらのモデルのリリースの特徴は、モデルが無料かつアクセス可能なCOYOデータセットでトレーニングされていることです。COYOは、GoogleのALIGN 1.8B画像テキストデータセットに似た700億ペアの画像テキストデータセットであり、ウェブページから取得した「ノイズのある」代替テキストと画像のペアのコレクションですが、オープンソースです。COYO-700MとALIGN 1.8Bは「ノイズのある」データセットですが、最小限のフィルタリングが適用されています。COYOは、他のオープンソースの画像テキストデータセットであるLAIONとは異なり、以下の点が異なります。…

はい、トランスフォーマーは時系列予測に効果的です(+オートフォーマー)
イントロダクション 数ヶ月前、AAAI 2021のベストペーパーアワードを受賞したTime Series TransformerであるInformerモデル(Zhou, Haoyiら、2021)を紹介しました。また、Informerを使用した多変量確率予測の例も提供しました。この記事では、「Transformerは時系列予測に効果的か?」(AAAI 2023)という疑問について議論します。見ていくとわかりますが、それらは効果的です。 まず、Transformerは確かに時系列予測に効果的であることを経験的に証明します。私たちの比較では、線形モデルであるDLinearが主張されるほど優れていないことが示されています。線形モデルと同じ設定の同等の大きさのモデルと比較した場合、Transformerベースのモデルは私たちが考慮するテストセットのメトリックでより優れた性能を発揮します。その後、Informerモデルの後にNeurIPS 2021で発表されたAutoformerモデル(Wu, Haixuら、2021)を紹介します。Autoformerモデルは現在🤗 Transformersで利用できます。最後に、Autoformerの分解層を使用するシンプルなフィードフォワードネットワークであるDLinearモデルについて説明します。DLinearモデルは、「Transformerは時系列予測に効果的か?」という論文で初めて紹介され、Transformerベースのモデルを時系列予測で上回ると主張されています。 さあ、始めましょう! ベンチマーキング – Transformers vs. DLinear 最近AAAI 2023で発表された「Transformerは時系列予測に効果的か?」という論文では、著者らはTransformerが時系列予測に効果的ではないと主張しています。彼らは、DLinearと呼ばれるシンプルな線形モデルとTransformerベースのモデルを比較しています。DLinearモデルはAutoformerモデルの分解層を使用しており、後ほどこの記事で紹介します。著者らは、DLinearモデルがTransformerベースのモデルを時系列予測で上回ると主張しています。本当にそうなのでしょうか?さあ、確かめましょう。 上記の表は、論文で使用された3つのデータセットにおけるAutoformerモデルとDLinearモデルの比較結果を示しています。結果からわかるように、Autoformerモデルは3つのデータセットすべてでDLinearモデルを上回っています。 次に、上記の表のTrafficデータセットを使用してAutoformerモデルとDLinearモデルを比較し、得られた結果の説明を提供します。 要約: 簡単な線形モデルは一部の場合において有利ですが、ユニバリエートの設定では変数を組み込む能力がTransformerのようなより複雑なモデルに比べてありません。 Autoformer…

AIを活用した亀の顔認識による保全の推進
私たちは、Zindiと出会いましたZindiは、補完的な目標を持つ専門のパートナーであり、アフリカのデータサイエンティストの最大のコミュニティであり、アフリカの最も切迫した問題を解決するために焦点を当てた競技会を開催しています私たちの科学チームの多様性、公正性、包括性(DE&I)チームは、Zindiと協力して、保全活動を進め、AIへの参加を促進することができる科学的な課題を特定しましたZindiのバウンディングボックスカメの課題に触発され、私たちは実際の影響を持つ可能性のあるプロジェクトに着地しました:カメの顔認識です
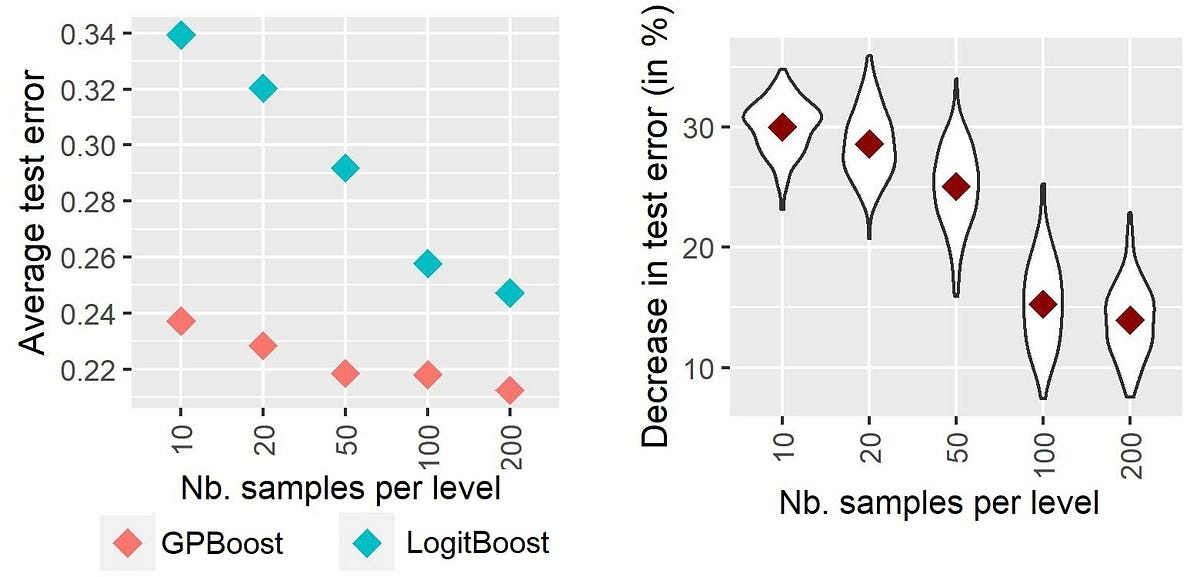
ハイカーディナリティのカテゴリカル変数に対する混合効果機械学習-第I部:異なる手法の実証的比較
高次元のカテゴリー変数のモデリングを向上させるための機械学習におけるランダム効果:アプローチの紹介と比較

2023年の最高の人工知能(AI)ニュースレター
人工知能(AI)分野では、AIの進展について情報を得て先を見るために、様々なAIニュースレターが登場しています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.