Learn more about Search Results DataLoader - Page 4

- You may be interested
- ジェネレーティブAIアプリケーションを構...
- 「MITの研究者が開発した機械学習技術によ...
- 「スポーツアナリストになるにはどうすれ...
- 「Scikit-LearnとMatplotlibによる外れ値...
- デジタル変革によって打撃を受ける可能性...
- 「Amazon SageMakerデータパラレルライブ...
- マイクロソフトAzure Functionsとは何です...
- 中国からのこのAI論文では、「モンキー」...
- 小さなオーディオ拡散:クラウドコンピュ...
- 「マイクロソフトの研究者がSpeechXを紹介...
- 「Amazon SageMaker Data Wranglerを使用...
- 「飛躍的進展:UCCの研究者が量子コンピュ...
- 「私はデータクリーニングのタスクでChatG...
- 「Rasaパワードチャットボット:シームレ...
- 7月にGeForce NOWに参加する14のゲームの...

Amazon SageMakerを使用して、オーバーヘッドイメージで自己教師ありビジョン変換モデルをトレーニングする
この記事では、Amazon SageMakerを使用して、オーバーヘッドのイメージに対して自己教師ありビジョン変換器をトレーニングする方法を示しますトラベラーズは、Amazon Machine Learning Solutions Lab(現在はGenerative AI Innovation Centerとして知られています)と協力して、このフレームワークを開発し、航空写真モデルのユースケースをサポートおよび強化しました
「PyTorchモデルのパフォーマンス分析と最適化 – パート3」
これは、PyTorch ProfilerとTensorBoardを使用してPyTorchモデルの分析と最適化を行うトピックに関するシリーズ投稿の3部目です私たちの意図は、...の利点を強調することでした

テキスト分類におけるトランスフォーマーエンコーダー
「Transformerは、間違いなく、ディープラーニングの分野で最も重要なブレークスルーの一つですこのモデルのエンコーダー・デコーダーアーキテクチャは、異なるドメイン間で強力であることが証明されています...」

「ダウンストリームタスクのためのFine-tuningを通じたBERTの適応」
はじめに BERTを下流タスクに適応させるには、事前学習されたBERTモデルを利用し、特定のタスクに合わせてカスタマイズするためのレイヤーを追加し、そのターゲットタスクでトレーニングする必要があります。この技術により、モデルはトレーニングに使用されるデータのタスクの詳細に依存しながら、事前学習されたBERTモデルの広範な言語表現の知識を活用して学習することができます。Pythonのhugging face transformersパッケージを使用してBERTを微調整することができます。入力テキストとラベルを含むトレーニングデータを記述します。BertForSequenceClassificationクラスのfit()関数を使用して、データに基づいて事前学習されたBERTモデルを微調整します。 学習目標 この記事の目的は、BERTの微調整について詳しく説明することです。 詳細な分析により、下流タスクのための微調整の利点が明らかにされます。 下流の操作メカニズムについて包括的に説明されます。 下流の活動に対してBERTを微調整するための完全な順次概要が提供されます。 BERTはどのように微調整されるのですか? BERTの微調整では、トレーニングデータを使用して事前学習済みモデルを特定の下流タスクに合わせてトレーニングすることにより、新しいレイヤーでモデルを適応させます。このプロセスにより、モデルはタスク固有の知識を獲得し、対象のタスクでのパフォーマンスを向上させることができます。 BERTの微調整プロセスの主なステップ 1: hugging face transformersライブラリを使用して事前学習済みのBERTモデルとトークナイザーをロードします。 import torch # 使用可能なデバイスを利用します(CUDAまたはCPU) gpu_available = torch.cuda.is_available() device…
「PyTorchにおける複数GPUトレーニングとそれに代わる勾配蓄積」
この記事では、まず、データ並列化(DP)と分散データ並列化(DDP)アルゴリズムの違いを説明し、次に勾配蓄積(GA)が何であるかを説明します

「インテルCPU上での安定したディフューションモデルのファインチューニング」
拡散モデルは、テキストのプロンプトから写真のようなリアルな画像を生成するというその驚異的な能力によって、生成型AIの普及に貢献しました。これらのモデルは現在、合成データの生成やコンテンツ作成などの企業のユースケースに取り入れられています。Hugging Faceハブには、5,000以上の事前学習済みのテキストから画像へのモデルが含まれています。Diffusersライブラリと組み合わせることで、実験や画像生成ワークフローの構築がこれまで以上に簡単になりました。 Transformerモデルと同様に、Diffusionモデルをファインチューニングしてビジネスニーズに合ったコンテンツを生成することができます。初期のファインチューニングはGPUインフラストラクチャー上でのみ可能でしたが、状況は変わってきています!数か月前、インテルはSapphire Rapidsというコードネームの第4世代のXeon CPUを発売しました。Sapphire Rapidsは、ディープラーニングワークロードのための新しいハードウェアアクセラレータであるIntel Advanced Matrix Extensions (AMX)を導入しています。私たちはすでにいくつかのブログ記事でAMXの利点を実証しています:NLP Transformerのファインチューニング、NLP Transformerの推論、およびStable Diffusionモデルの推論。 この投稿では、Intel Sapphire Rapids CPUクラスター上でStable Diffusionモデルをファインチューニングする方法を紹介します。わずかな例の画像のみを必要とするテキスト反転という技術を使用します。たった5つの画像だけです! さあ、始めましょう。 クラスターのセットアップ Intelの友人たちが、最新のIntelプロセッサとパフォーマンス最適化されたソフトウェアスタックを使用したIntel®最適化デプロイメント環境でのワークロードの開発と実行を行うためのサービスプラットフォームであるIntel Developer Cloud(IDC)にホストされた4つのサーバーを提供してくれました。 各サーバーには、2つのIntel…

PyTorch / XLA TPUsでのHugging Face
お気に入りのトランスフォーマーをPyTorch / XLAを使用してCloud TPUsでトレーニングする PyTorch-TPUプロジェクトは、Facebook PyTorchチームとGoogle TPUチームの共同作業として始まり、2019年のPyTorch Developer Conference 2019で正式に開始されました。それ以来、私たちはHugging Faceチームと協力して、PyTorch / XLAを使用してCloud TPUsでトレーニングをサポートするための一流のサポートを提供してきました。この新しい統合により、PyTorchユーザーはHugging Faceトレーナーインターフェースをそのまま維持しながら、Cloud TPUs上でモデルを実行しスケーリングすることができます。 このブログ記事では、Hugging Faceライブラリで行われた変更の概要、PyTorch / XLAライブラリの機能、Cloud TPUsでお気に入りのトランスフォーマーをトレーニングするための例、およびいくつかのパフォーマンスベンチマークについて説明します。TPUsで始めるのが待ちきれない場合は、「Cloud TPUsでトランスフォーマーをトレーニングする」セクションにスキップしてください – 私たちはTrainerモジュール内でPyTorch…
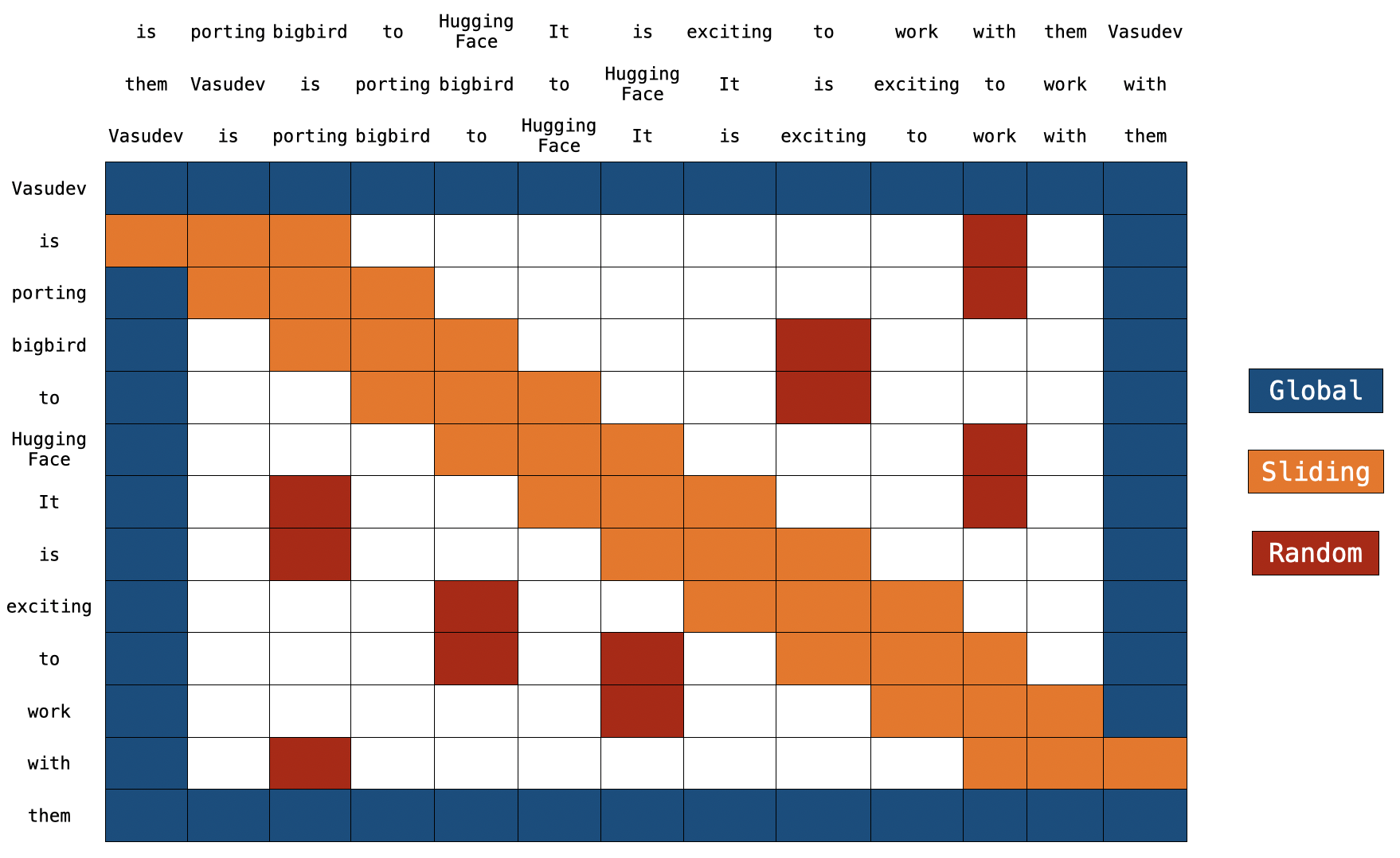
BigBirdのブロック疎な注意機構の理解
イントロダクション トランスフォーマーベースのモデルは、多くの自然言語処理タスクにおいて非常に有用であることが示されています。ただし、トランスフォーマーベースのモデルの主な制限は、O(n^2) の時間とメモリの複雑さ(ここで n はシーケンスの長さです)です。したがって、長いシーケンス n > 512 に対してトランスフォーマーベースのモデルを適用するのは計算上非常に高コストです。最近のいくつかの論文では、Longformer、Performer、Reformer、Clustered attention などが、完全な注意行列を近似することでこの問題を解決しようとしています。これらのモデルについて詳しく知りたい場合は、🤗の最近のブログ記事をチェックしてください。 BigBird(論文で紹介)は、この問題に対処するための最近のモデルの1つです。 BigBird は通常の注意(つまり、BERTの注意)ではなく、ブロックスパースな注意を使用し、BERTよりも低い計算コストで長さ 4096 のシーケンスを処理することができます。 BigBird は、長いドキュメントの要約、長いコンテキストを持つ質問応答など、非常に長いシーケンスを含むさまざまなタスクでSOTAを達成しています。 BigBird RoBERTa-like モデルは現在、🤗Transformersで利用できます。この記事の目的は、読者に 詳細な BigBird の実装の理解を提供し、🤗Transformers…

🤗 Accelerate のご紹介
🤗 アクセラレート あらゆる種類のデバイスで、生の PyTorch のトレーニングスクリプトを実行できます。 PyTorch の上位レベルの多くのライブラリは、分散トレーニングや混合精度のサポートを提供していますが、それらが導入する抽象化により、ユーザーは基礎となるトレーニングループをカスタマイズするために新しい API を学ぶ必要があります。🤗 アクセラレートは、トレーニングループを完全に制御したい PyTorch ユーザーのために作成されましたが、分散トレーニング(複数のノード上のマルチ GPU、TPU など)、混合精度トレーニングに必要な骨格コードの記述(および保守)を行いたくないユーザーも対象です。今後の計画には、fairscale、deepseed、AWS SageMaker 特定のデータ並列処理とモデル並列処理のサポートも含まれます。 それは次の2つのことを提供します:骨格コードを抽象化するシンプルで一貫した API と、さまざまなセットアップでこれらのスクリプトを簡単に実行するための起動コマンドです。 簡単な統合! まずは例を見てみましょう: import torch import…

スクラッチからCodeParrot 🦜をトレーニングする
このブログポストでは、GitHub CoPilotの背後にある技術を構築するために必要なものについて説明します。GitHub CoPilotは、プログラマがコードを書く際に提案を行うアプリケーションです。このステップバイステップガイドでは、ゼロから完全にトレーニングされた大規模なGPT-2モデルであるCodeParrot 🦜を訓練する方法を学びます。CodeParrotはPythonのコードを自動補完することができます – こちらで試してみてください。さあ、ゼロから構築してみましょう! ソースコードの大規模なデータセットの作成 まず必要なものは、大規模なトレーニングデータセットです。Pythonのコード生成モデルを訓練することを目指して、GoogleのBigQueryで利用可能なGitHubのダンプにアクセスし、すべてのPythonファイルに絞り込みました。その結果、180GBのデータセットがあり、2000万のファイルが含まれています(こちらで入手可能)。初期のトレーニング実験の結果、データセットの重複はモデルの性能に深刻な影響を与えることがわかりました。データセットを調査すると、次のことがわかりました: ユニークなファイルの0.1%が全ファイルの15%を占めています ユニークなファイルの1%が全ファイルの35%を占めています ユニークなファイルの10%が全ファイルの66%を占めています 詳細は、このTwitterスレッドで調査結果について詳しくご覧いただけます。重複を削除し、CoPilotの背後にあるモデルであるCodexの論文で見つかった同じクリーニングヒューリスティックを適用しました。CodexはGitHubのコードでファインチューニングされたGPT-3モデルです。 クリーニングされたデータセットはまだ50GBの大きさであり、Hugging Face Hubで利用可能です:codeparrot-clean。これで新しいトークナイザーを設定し、モデルを訓練することができます。 トークナイザーとモデルの初期化 まず、トークナイザーが必要です。コードを適切にトークンに分割するために、コード専用のトークナイザーをトレーニングしましょう。既存のトークナイザー(例えばGPT-2)を取り、train_new_from_iterator()メソッドで独自のデータセットでトレーニングします。それから、Hubにプッシュします。コードの例からインポートや引数のパース、ログ出力は省略していますが、前処理やダウンストリームタスクの評価を含めた完全なコードはこちらで見つけることができます。 # トレーニング用のイテレーター def batch_iterator(batch_size=10): for _ in…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.