Learn more about Search Results 公式ドキュメント - Page 4

- You may be interested
- グーグルの研究者たちは、差分プライバシ...
- 北京大学とマイクロソフトの研究者がCOLE...
- オライリー「2023年エンタープライズにお...
- 「ESAのセンチネルAPIに深く潜入」
- NLP、NN、時系列:Google Trendsのデータ...
- AIがUPSのパッケージ窃盗を監視しています
- 「Pythonを用いた巡回セールスマン問題の...
- LLMツールはソフトウェアの脆弱性を発見し...
- 「注目のAI GitHubリポジトリ:2023年11月...
- 「バックテストの重要性と正しい方法」
- 学ぶための勇気: L1&L2正則化の解明(パ...
- FermiNet(フェルミネット):第一原理に...
- Amazon BedrockとAmazon Transcribeを使用...
- 「GPT4Readability — リードミーをもう一...
- 検索で創発的AIにインスピレーションを受...

Hugging Face Transformersでより高速なTensorFlowモデル
ここ数か月、Hugging FaceチームはTransformersのTensorFlowモデルの改良に取り組んできました。目標はより堅牢で高速なモデルを実現することです。最近の改良は主に次の2つの側面に焦点を当てています: 計算パフォーマンス:BERT、RoBERTa、ELECTRA、MPNetの計算時間を大幅に短縮するための改良が行われました。この計算パフォーマンスの向上は、グラフ/イージャーモード、TF Serving、CPU/GPU/TPUデバイスのすべての計算アスペクトで顕著に見られます。 TensorFlow Serving:これらのTensorFlowモデルは、TensorFlow Servingを使用して展開することができ、推論においてこの計算パフォーマンスの向上を享受することができます。 計算パフォーマンス 計算パフォーマンスの向上を実証するために、v4.2.0のTensorFlow ServingとGoogleの公式実装との間でBERTのパフォーマンスを比較するベンチマークを実施しました。このベンチマークは、GPU V100上でシーケンス長128を使用して実行されました(時間はミリ秒単位で表示されます): v4.2.0の現行のBertの実装は、Googleの実装よりも最大で約10%高速です。また、4.1.1リリースの実装よりも2倍高速です。 TensorFlow Serving 前のセクションでは、Transformersの最新バージョンでブランドニューのBertモデルが計算パフォーマンスが劇的に向上したことを示しました。このセクションでは、製品環境で計算パフォーマンスの向上を活用するために、TensorFlow Servingを使用してBertモデルを展開する手順をステップバイステップで説明します。 TensorFlow Servingとは何ですか? TensorFlow Servingは、モデルをサーバーに展開するタスクをこれまで以上に簡単にするTensorFlow Extended(TFX)が提供するツールの一部です。TensorFlow Servingには、HTTPリクエストを使用して呼び出すことができるAPIと、サーバー上で推論を実行するためにgRPCを使用するAPIの2つがあります。 SavedModelとは何ですか? SavedModelには、ウェイトとアーキテクチャを含むスタンドアロンのTensorFlowモデルが含まれています。SavedModelは、モデルの元のソースを実行する必要がないため、Java、Go、C++、JavaScriptなどのSavedModelを読み込むバックエンドをサポートするすべてのバックエンドと共有または展開するために役立ちます。SavedModelの内部構造は次のように表されます:…

🤗 Transformersでn-gramを使ってWav2Vec2を強化する
Wav2Vec2は音声認識のための人気のある事前学習モデルです。2020年9月にMeta AI Researchによってリリースされたこの新しいアーキテクチャは、音声認識のための自己教師あり事前学習の進歩を促進しました。例えば、G. Ng et al.、2021年、Chen et al、2021年、Hsu et al.、2021年、Babu et al.、2021年などが挙げられます。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは現在、月間ダウンロード数25万以上です。 コネクショニスト時系列分類(CTC)を使用して、事前学習済みのWav2Vec2のようなチェックポイントは、ダウンストリームの音声認識タスクで非常に簡単にファインチューニングできます。要するに、事前学習済みのWav2Vec2のチェックポイントをファインチューニングする方法は次のとおりです。 事前学習チェックポイントの上にはじめに単一のランダムに初期化された線形層が積み重ねられ、生のオーディオ入力を文字のシーケンスに分類するために訓練されます。これは以下のように行います。 生のオーディオからオーディオ表現を抽出する(CNN層を使用する) オーディオ表現のシーケンスをトランスフォーマーレイヤーのスタックで処理する 処理されたオーディオ表現を出力文字のシーケンスに分類する 以前のオーディオ分類モデルでは、分類されたオーディオフレームのシーケンスを一貫した転写に変換するために、追加の言語モデル(LM)と辞書が必要でした。Wav2Vec2のアーキテクチャはトランスフォーマーレイヤーに基づいているため、各処理されたオーディオ表現は他のすべてのオーディオ表現から文脈を得ることができます。さらに、Wav2Vec2はファインチューニングにCTCアルゴリズムを利用しており、変動する「入力オーディオの長さ」と「出力テキストの長さ」の比率の整列の問題を解決しています。 文脈化されたオーディオ分類と整列の問題がないため、Wav2Vec2には受け入れ可能なオーディオ転写を得るために外部の言語モデルや辞書は必要ありません。 公式論文の付録Cに示されているように、Wav2Vec2は言語モデルを使用せずにLibriSpeechで印象的なダウンストリームのパフォーマンスを発揮しています。ただし、付録からも明らかなように、Wav2Vec2を10分間の転写済みオーディオのみで訓練した場合、言語モデルと組み合わせると特に改善が見られます。 最近まで、🤗 TransformersライブラリにはファインチューニングされたWav2Vec2と言語モデルを使用してオーディオファイルをデコードするための簡単なユーザーインターフェースがありませんでした。幸いにも、これは変わりました。🤗…

🤗 Hubでのスーパーチャージド検索
huggingface_hubライブラリは、ホスティングエンドポイント(モデル、データセット、スペース)を探索するためのプログラム的なアプローチを提供する軽量なインタフェースです。 これまでは、このインタフェースを介してハブでの検索は難しく、ユーザーは「知っているだけ」で慣れなければならない多くの側面がありました。 この記事では、huggingface_hubに追加されたいくつかの新機能を紹介し、ユーザーにJupyterやPythonインタフェースを離れずに使用したいモデルやデータセットを検索するためのフレンドリーなAPIを提供します。 始める前に、システムに最新バージョンのhuggingface_hubライブラリがない場合は、次のセルを実行してください: !pip install huggingface_hub -U 問題の位置づけ: まず、自分がどのようなシナリオにいるか想像してみましょう。テキスト分類のためにハブでホストされているすべてのモデルを見つけたいとします。これらのモデルはGLUEデータセットでトレーニングされ、PyTorchと互換性があります。 https://huggingface.co/models を単に開いてそこにあるウィジェットを使用することもできます。しかし、これによりIDEを離れて結果をスキャンする必要がありますし、必要な情報を得るためにはいくつかのボタンクリックが必要です。 もしもIDEを離れずにこれを解決する方法があったらどうでしょうか?プログラム的なインタフェースであれば、ハブを探索するためのワークフローにも簡単に組み込めるかもしれません。 ここでhuggingface_hubが登場します。 このライブラリに慣れている方は、すでにこの種のモデルを検索できることを知っているかもしれません。しかし、クエリを正しく取得することは試行錯誤の痛ましいプロセスです。 それを簡略化することはできるでしょうか?さあ、見てみましょう! 必要なものを見つける まず、HfApiをインポートします。これはHugging Faceのバックエンドホスティングと対話するのに役立つクラスです。モデル、データセットなどを通じて対話することができます。さらに、いくつかのヘルパークラスもインポートします:ModelFilterとModelSearchArguments from huggingface_hub import HfApi, ModelFilter,…

DeepSpeedを使用して大規模モデルトレーニングを高速化する
この投稿では、Accelerate ライブラリを活用して、ユーザーが DeeSpeed の ZeRO 機能を利用して大規模なモデルをトレーニングする方法について説明します。 大規模なモデルをトレーニングしようとする際にメモリ不足 (OOM) エラーに悩まされていますか?私たちがサポートします。大規模なモデルは非常に高性能ですが、利用可能なハードウェアでトレーニングするのは困難です。大規模なモデルのトレーニングに利用可能なハードウェアの最大限の性能を引き出すために、ZeRO – Zero Redundancy Optimizer [2] を使用したデータ並列処理を活用することができます。 以下は、このブログ記事からの図を使用した ZeRO を使用したデータ並列処理の短い説明です。 (出典: リンク) a. ステージ 1 :…

打ち上げ!最初のMLプロジェクトを始める方法 🚀
機械学習の世界に初めて入る人々は、2つの頻繁な stumbling block によく遭遇します。最初の stumbling block は、学習するための適切なライブラリを選ぶことであり、選択肢が多い場合には困難な課題です。適切なライブラリを選び、いくつかのチュートリアルを終えた後でも、次の問題は最初の大規模プロジェクトを考え出し、適切にスコープを設定して学習を最大化することです。これらの問題にぶつかったことがある場合、またはツールキットに追加する新しい ML ライブラリを探している場合は、正しい場所にいます! この記事では、Sentence Transformers (ST) を例に挙げながら、新しいライブラリを使って0から100まで進むためのいくつかのヒントを紹介します。まず、STの基本的な機能を理解し、学習に適した素晴らしいライブラリであることを強調します。次に、最初の自己主導プロジェクトに取り組むための戦術を共有します。また、最初のSTプロジェクトの構築方法と、その過程で学んだことについても話しましょう 🥳 Sentence Transformers とは何ですか? Sentence embeddings?Semantic search?Cosine similarity?!?! 😱 数週間前まで、これらの用語は私にとって混乱して頭がクラクラするほどでした。Sentence Transformers…
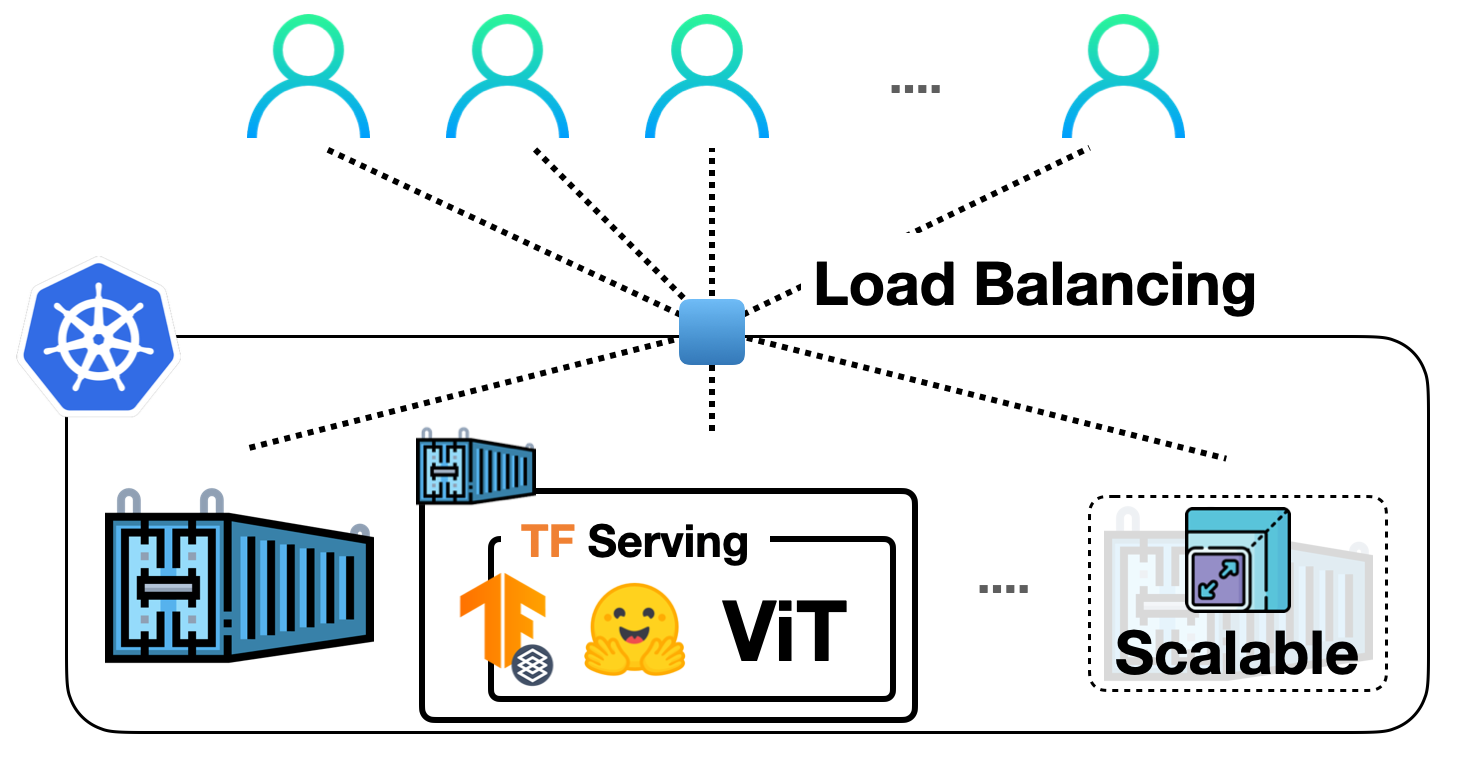
TF Servingを使用してKubernetes上に🤗 ViTをデプロイする
前の投稿では、TensorFlow Servingを使用して🤗 TransformersからVision Transformer(ViT)モデルをローカルに展開する方法を示しました。ビジョントランスフォーマーモデル内での埋め込み前処理および後処理操作、gRPCリクエストの処理など、さまざまなトピックをカバーしました! ローカル展開は、有用なものを構築するための優れたスタート地点ですが、実際のプロジェクトで多くのユーザーに対応できる展開を実行する必要があります。この投稿では、前の投稿のローカル展開をDockerとKubernetesでスケーリングする方法を学びます。したがって、DockerとKubernetesに関する基本的な知識が必要です。 この投稿は前の投稿に基づいていますので、まずそれをお読みいただくことを強くお勧めします。この投稿で説明されているコードは、このリポジトリで確認することができます。 私たちの展開をスケールアップする基本的なワークフローは、次のステップを含みます: アプリケーションロジックのコンテナ化:アプリケーションロジックには、リクエストを処理して予測を返すサービスモデルが含まれます。コンテナ化するために、Dockerが業界標準です。 Dockerコンテナの展開:ここにはさまざまなオプションがあります。最も一般的に使用されるオプションは、DockerコンテナをKubernetesクラスターに展開することです。Kubernetesは、展開に便利な機能(例:自動スケーリングとセキュリティ)を提供します。ローカルでKubernetesクラスターを管理するためのMinikubeのようなソリューションや、Elastic Kubernetes Service(EKS)のようなサーバーレスソリューションを使用することもできます。 SagemakerやVertex AIのような、MLデプロイメント固有の機能をすぐに利用できる時代に、なぜこのような明示的なセットアップを使用するのか疑問に思うかもしれません。それは考えるのは当然です。 上記のワークフローは、業界で広く採用され、多くの組織がその恩恵を受けています。長年にわたってすでに実戦投入されています。また、複雑な部分を抽象化しながら、展開に対してより細かな制御を持つことができます。 この投稿では、Google Kubernetes Engine(GKE)を使用してKubernetesクラスターをプロビジョニングおよび管理することを前提としています。GKEを使用する場合、請求を有効にしたGCPプロジェクトが既にあることを想定しています。また、GKEで展開を行うためにgcloudユーティリティを構成する必要があります。ただし、Minikubeを使用する場合でも、この投稿で説明されているコンセプトは同様に適用されます。 注意:この投稿で表示されるコードスニペットは、gcloudユーティリティとDocker、kubectlが構成されている限り、Unixターミナルで実行できます。詳しい手順は、付属のリポジトリで入手できます。 サービングモデルは、生のイメージ入力をバイトとして処理し、前処理および後処理を行うことができます。 このセクションでは、ベースのTensorFlow Servingイメージを使用してそのモデルをコンテナ化する方法を示します。TensorFlow Servingは、モデルをSavedModel形式で消費します。前の投稿でSavedModelを取得した方法を思い出してください。ここでは、SavedModelがtar.gz形式で圧縮されていることを前提としています。万が一必要な場合は、ここから入手できます。その後、SavedModelは<MODEL_NAME>/<VERSION>/<SavedModel>という特別なディレクトリ構造に配置する必要があります。これにより、TensorFlow Servingは異なるバージョンのモデルの複数の展開を同時に管理できます。 Dockerイメージの準備…

ディフューザーの新着情報は何ですか?🎨
1か月半前に、モダリティを横断する拡散モデルのためのモジュールツールボックスを提供するdiffusersライブラリをリリースしました。数週間後には、高品質なテキストから画像への変換モデルであるStable Diffusionのサポートを追加し、誰でも無料のデモを試すことができるようにしました。最後の3週間では、チームはライブラリに1つまたは2つの新機能を追加することを決定しました。このブログ投稿では、diffusersバージョン0.3の新機能について概説します!GitHubリポジトリに⭐を付けるのを忘れないでください。 画像から画像へのパイプライン テキストの逆転 インペインティング より小さなGPUに最適化 Mac上で実行 ONNXエクスポーター 新しいドキュメント コミュニティ SD潜在空間での動画生成 モデルの説明可能性 日本語のStable Diffusion 高品質なファインチューニングモデル Stable Diffusionによるクロスアテンション制御 再利用可能なシード 画像から画像へのパイプライン 最も要望の多かった機能の1つは、画像から画像の生成を行うことです。このパイプラインでは、画像とプロンプトを入力すると、それに基づいて画像が生成されます! 公式のColabノートブックに基づいたコードを見てみましょう。 from diffusers import…

ハギングフェイスにおけるコンピュータビジョンの状況 🤗
弊社の自慢は、コミュニティとともに人工知能の分野を民主化することです。その使命の一環として、私たちは過去1年間でコンピュータビジョンに注力し始めました。🤗 Transformersにビジョントランスフォーマー(ViT)を含めるというPRから始まったこの取り組みは、現在では8つの主要なビジョンタスク、3000以上のモデル、およびHugging Face Hub上の100以上のデータセットに成長しました。 ViTがHubに参加して以来、多くのエキサイティングな出来事がありました。このブログ記事では、コンピュータビジョンの持続的な進歩をサポートするために何が起こったのか、そして今後何がやってくるのかをまとめます。 以下は、カバーする内容のリストです: サポートされているビジョンタスクとパイプライン 独自のビジョンモデルのトレーニング timmとの統合 Diffusers サードパーティーライブラリのサポート デプロイメント その他多数! コミュニティの支援:一つずつのタスクを可能にする 👁 Hugging Face Hubは、次の単語予測、マスクの埋め込み、トークン分類、シーケンス分類など、さまざまなタスクのために10万以上のパブリックモデルを収容しています。現在、我々は8つの主要なビジョンタスクをサポートし、多くのモデルチェックポイントを提供しています: 画像分類 画像セグメンテーション (ゼロショット)オブジェクト検出 ビデオ分類 奥行き推定 画像から画像への合成…

制御ネット(ControlNet)は、🧨ディフューザー内での使用です
Stable Diffusionが世界中で大流行した以来、人々は生成プロセスの結果に対してより多くの制御を持つ方法を探してきました。ControlNetは、ユーザーが生成プロセスを非常に大きな範囲でカスタマイズできる最小限のインターフェースを提供します。ControlNetを使用すると、ユーザーは深度マップ、セグメンテーションマップ、スクリブル、キーポイントなど、さまざまな空間的なコンテキストを使用して簡単に生成を条件付けることができます! 私たちは、驚くほどの一貫性を持つ写実的な写真に漫画の絵を変えることができます。 写実的なLofiガール また、それをあなたのインテリアデザイナーとして使用することもできます。 Before After あなたはスケッチのスクリブルを芸術的な絵に変えることができます。 Before After さらに、有名なロゴを生き生きとさせることもできます。 Before After ControlNetを使用すると、可能性は無限大です🌠 このブログ記事では、まずStableDiffusionControlNetPipelineを紹介し、さまざまな制御条件にどのように適用できるかを示します。さあ、制御しましょう! ControlNet: TL;DR ControlNetは、Lvmin ZhangとManeesh AgrawalaによってText-to-Image Diffusion Modelsに条件付き制御を追加することで導入されました。これにより、Stable DiffusionなどのDiffusionモデルに追加の条件として使用できるさまざまな空間的コンテキストをサポートするフレームワークが導入されます。ディフュージョンモデルの実装は、元のソースコードから適応されています。 ControlNetのトレーニングは次の手順で行われます:…
BERTopicとHugging Face Hubの統合をご紹介します
私たちは、BERTopic Pythonライブラリの重要なアップデートを発表して大変喜んでいます。これにより、トピックモデリングの愛好家や実践者のためのワークフローがさらに効率化され、機能が拡張されました。BERTopicは、Hugging Face Hubへのトレーニング済みトピックモデルの直接プッシュとプルをサポートするようになりました。この新しい統合により、BERTopicのパワーを生かして製品の使用例でのトピックモデリングが簡単に行えるようになりました。 トピックモデリングとは何ですか? トピックモデリングは、ドキュメントのグループ内に隠れたテーマや「トピック」を明らかにするのに役立つメソッドです。ドキュメント内の単語を分析することで、これらの潜在的なトピックを明らかにするパターンや関連性を見つけることができます。たとえば、機械学習に関するドキュメントは、「勾配」や「埋め込み」といった単語を使用する可能性が高く、パンの焼き方に関するドキュメントとは異なります。 各ドキュメントは通常、異なる比率で複数のトピックをカバーしています。単語の統計を調べることで、これらのトピックを表す関連する単語のクラスタを特定することができます。これにより、ドキュメントの分析と、それぞれのドキュメント内のトピックのバランスを決定することができます。より最近では、トピックモデリングの新しいアプローチでは、単語の使用ではなく、Transformerベースのモデルなど、より豊かな表現を使用するようになりました。 BERTopicとは何ですか? BERTopicは、さまざまな埋め込み技術とc-TF-IDFを使用して、トピックモデリングのプロセスを簡素化し、重要な単語をトピックの説明に保持しながら、密なクラスタを作成する最新のPythonライブラリです。 BERTopicライブラリの概要 BERTopicは初心者でも簡単に始めることができますが、ガイド付き、教師付き、半教師付き、およびマニュアルトピックモデリングなど、トピックモデリングのさまざまな高度なアプローチをサポートしています。最近では、BERTopicはマルチモーダルトピックモデルもサポートしています。BERTopicには、視覚化ツールの豊富なセットもあります。 BERTopicは、テキストコレクション内の重要なトピックを明らかにするための強力なツールを提供し、貴重な洞察を得ることができます。BERTopicを使用すると、顧客のレビューを分析したり、研究論文を探索したり、ニュース記事をカテゴリ分けしたりすることが容易になります。テキストデータから意味のある情報を抽出したいと考えている人にとって、これは必須のツールです。 Hugging Face Hubを使用したBERTopicモデルの管理 最新の統合により、BERTopicのユーザーはトレーニング済みのトピックモデルをHugging Face Hubにシームレスにプッシュおよびプルすることができます。この統合により、異なる環境でのBERTopicモデルの展開と管理が簡素化されるという重要なマイルストーンが達成されました。 BERTopicモデルのトレーニングとハブへのプッシュは、数行で行うことができます from bertopic import BERTopic topic_model…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.