Learn more about Search Results マーフ - Page 4

- You may be interested
- Concrete MLと出会ってください:プライバ...
- 「密度プロンプトのチェーンを通じたGPT-4...
- 「データウェアハウジング入門ガイド」
- 科学者が本当のスーパーヒーローであるこ...
- スタンフォード大学の研究者たちは、安定...
- 「ビジョン・トランスフォーマーの内部機能」
- 最初のLLMアプリを構築するために知ってお...
- 驚くべき発見:AIが未解決の数学問題を解...
- 「ウェブマップを使用した空間データの表示」
- Zipperを使用してサーバーレスアプリを高...
- このAI論文は、「MATLABER:マテリアルを...
- 「OpenAIが大企業向けのChatGPTバージョン...
- 「Hugging Face Transformersを使用したBE...
- 新車販売が加速し、チップ不足が緩和される
- 「NVIDIAは3DワールドのためのOpenUSD標準...

data2vec 自己教師あり学習における画期的な進歩
「機械学習モデルは、訓練にラベル付きデータを大いに依存してきました従来の考え方では、ラベル付きデータでモデルを訓練することで正確な結果が得られますしかし、ラベル付きデータを使用する主なデメリットは、訓練データのサイズが増えるにつれて上昇する高い注釈コストです高い注釈コストは、[…]にとって大きなハードルとなります」
リアルタイムでデータを理解する
このブログ投稿では、オープンソースのストリーミングソリューションであるbytewaxと、ydata-profilingを組み合わせて活用する方法について説明しますこれにより、ストリーミングフローの品質を向上させることができます

「機械が収穫するためではない」 AIに対するデータの反乱勃発
「A.I.企業が許可なくオンラインコンテンツを消費することにうんざりしたため、ファンフィクション作家、俳優、ソーシャルメディア企業、ニュース機関などが反乱を起こしています」
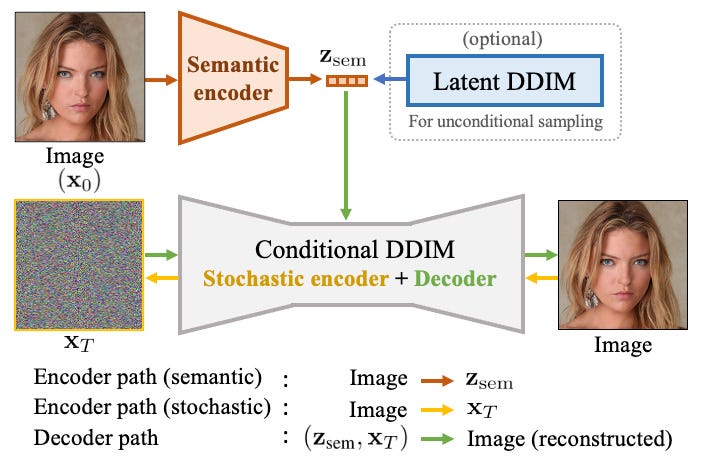
「DAE Talking 高忠実度音声駆動の話し相手生成における拡散オートエンコーダー」
今日は、新しい論文と、私が出会った中で最高品質の音声駆動ディープフェイクモデルについて話し合いますマイクロソフトリサーチから来たDAE-talkerは、個別の人物に特化したフルヘッドモデルです...
学習トランスフォーマーコード第2部 – GPTを間近で観察
私のプロジェクトの第2部へようこそここでは、TinyStoriesデータセットとnanoGPTを使用して、トランスフォーマーとGPTベースのモデルの複雑さについて探求しますこれらはすべて、古いゲーミングラップトップで訓練されました

「The Reformer – 言語モデリングの限界を押し上げる」
Reformerが半ミリオントークンのシーケンスを訓練するために8GB未満のRAMを使用する方法 Reformerモデルは、Kitaev、Kaiserらによって2020年に紹介されたもので、現在のところ最もメモリ効率の良いトランスフォーマーモデルの1つです。 最近、長いシーケンスモデリングは大きな関心を集めており、今年だけでも多くの論文が提出されています(Beltagyら(2020年)、Royら(2020年)、Tayら、Wangらなど)。長いシーケンスモデリングの背後にある動機は、要約、質問応答などの多くのNLPタスクが、BERTなどのモデルよりも長い入力シーケンスを処理する必要があるということです。大きな入力シーケンスを処理する必要があるタスクでは、長いシーケンスモデルはメモリオーバーフローを避けるために入力シーケンスを切り詰める必要がなく、従って標準の「BERT」のようなモデルを上回る性能を示すことが示されています(Beltagyら(2020年)による)。 Reformerは、このデモに示されているように、一度に最大で半ミリオンのトークンを処理する能力により、長いシーケンスモデリングの限界を em em ます。比較のために、従来の bert-base-uncased モデルでは、入力の長さを512トークンに制限しています。Reformerでは、標準のトランスフォーマーアーキテクチャの各部分が最小限のメモリ要件を最適化するために再設計されており、性能の大幅な低下を伴わずにメモリの改善がなされています。 メモリの改善は、Reformerの作者がトランスフォーマーワールドに導入した4つの特徴に帰属できます: Reformer Self-Attention Layer – ローカルコンテキストに制限されることなく自己注意を効率的に実装する方法は? Chunked Feed Forward Layers – 大規模なフォワードレイヤーの時間とメモリのトレードオフを改善する方法は? Reversible Residual Layers…
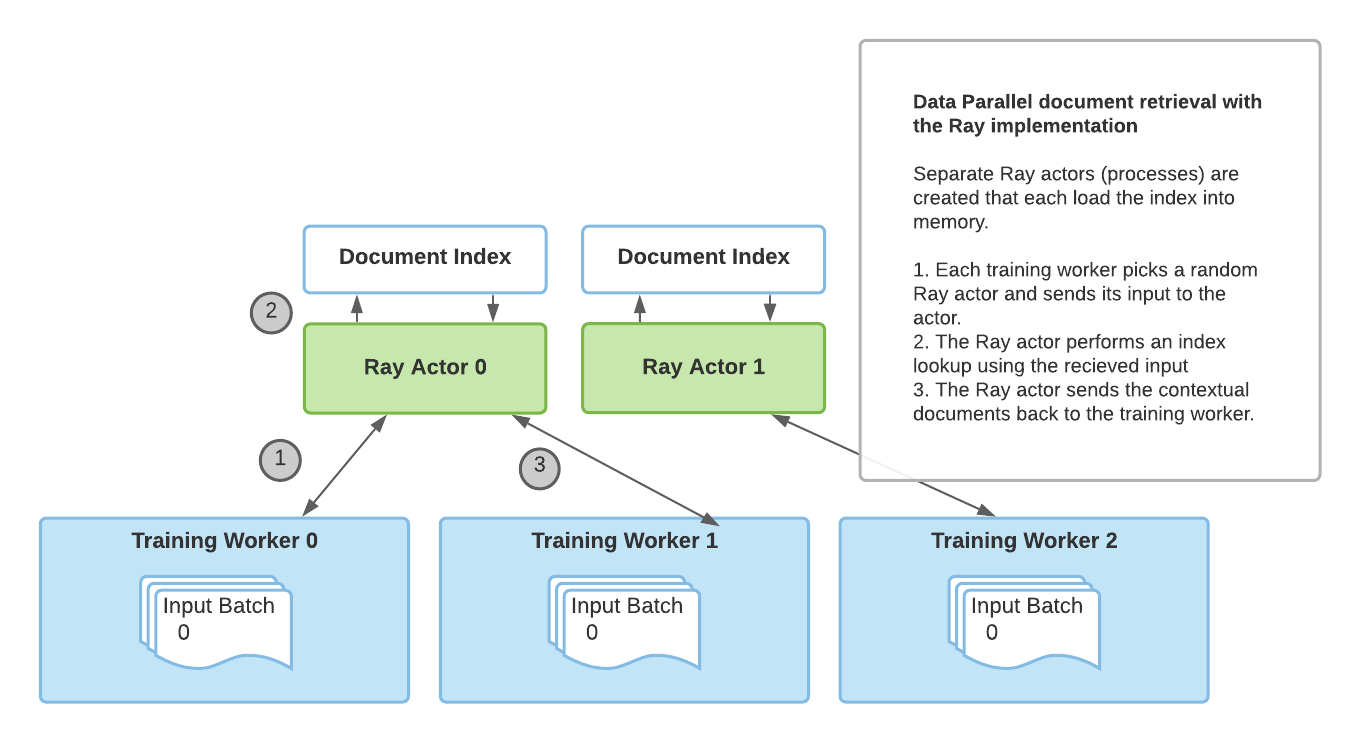
Huggingface TransformersとRayを使用した検索増強生成
アノスケールのチームからのゲストブログ投稿:Amog Kamsetty氏 Huggingface Transformersは最近、Retrieval Augmented Generation(RAG)モデルを追加しました。これは、外部のドキュメント(ウィキペディアなど)を活用して知識を拡充し、知識集約的なタスクで最先端の結果を実現する新しいNLPアーキテクチャです。このブログ投稿では、スケーラブルなアプリケーションを構築するためのライブラリであるRayをRAGの文脈におけるドキュメント検索メカニズムに統合する方法を紹介します。これにより、検索呼び出しの速度が2倍に向上し、RAGの分散ファインチューニングのスケーラビリティが向上します。 Retrieval Augmented Generation(RAG)とは何ですか? RAGの概要です。モデルは外部のデータセットから文脈ドキュメントを取得し、実行の一環として使用します。これらの文脈ドキュメントは元の入力と組み合わせて出力を生成するために使用されます。このGIFはFacebookのオリジナルのブログ投稿から取得されました。 最近、HuggingfaceはFacebook AIと提携して、RAGモデルをTransformersライブラリの一部として導入しました。 RAGは他のseq2seqモデルと同様に機能しますが、外部の知識ベース(ウィキペディアのテキストコーパスなど)から文脈ドキュメントを取得する中間コンポーネントを持っています。これらのドキュメントは入力シーケンスと組み合わせて基礎となるseq2seqジェネレータに渡されます。 この情報検索ステップにより、RAGはモデルパラメータに埋め込まれた知識と文脈のパッセージに含まれる情報という複数の知識源を活用することができます。これにより、質問応答などのタスクで他の最先端モデルを上回るパフォーマンスを発揮します。Huggingfaceが提供するデモを使用して、自分自身で試すこともできます。 ファインチューニングのスケーリング これらの文脈ドキュメントの取得は、RAGの最先端の結果にとって重要ですが、追加の複雑さをもたらします。データ並列トレーニングルーチンを介してトレーニングプロセスをスケーリングアップする際、ドキュメントの検索の単純な実装はトレーニングのボトルネックになることがあります。さらに、検索コンポーネントで使用されるドキュメントインデックスは非常に大きいため、各トレーニングワーカーが自分自身の複製されたインデックスを読み込むことは不可能です。 以前のRAGファインチューニングの実装では、torch.distributed通信パッケージを使用してドキュメント検索部分を活用していました。しかし、この実装は柔軟性に欠け、スケーラビリティに制約がありました。 その代わりに、フレームワークに依存しないアドホックな並行プログラミングのためのより柔軟な実装が必要です。それには、Rayが完璧に適しています。Rayは一般的な分散および並列プログラミングのためのシンプルで強力なPythonライブラリです。Rayを使用して分散ドキュメント検索を行うことで、torch.distributedに比べて検索呼び出しごとに2倍の高速化と、ファインチューニングのスケーラビリティの向上を実現しました。 ドキュメント検索のためのRay torch.distributedの実装によるドキュメント検索 torch.distributedを使用したドキュメント検索の主な欠点は、トレーニングに使用されるプロセスグループに依存していて、ランク0のトレーニングワーカーのみがインデックスをメモリに読み込んでいたことです。 その結果、この実装にはいくつかの制限がありました: 同期のボトルネック:ランク0のワーカーはすべてのワーカーから入力を受け取り、インデックスクエリを実行し、その結果を他のワーカーに送信する必要がありました。これにより、複数のトレーニングワーカーでのパフォーマンスが制限されました。 PyTorch固有の:ドキュメント検索プロセスグループはトレーニングに使用される既存のプロセスグループに依存する必要があり、トレーニングにはPyTorchを使用する必要がありました。…
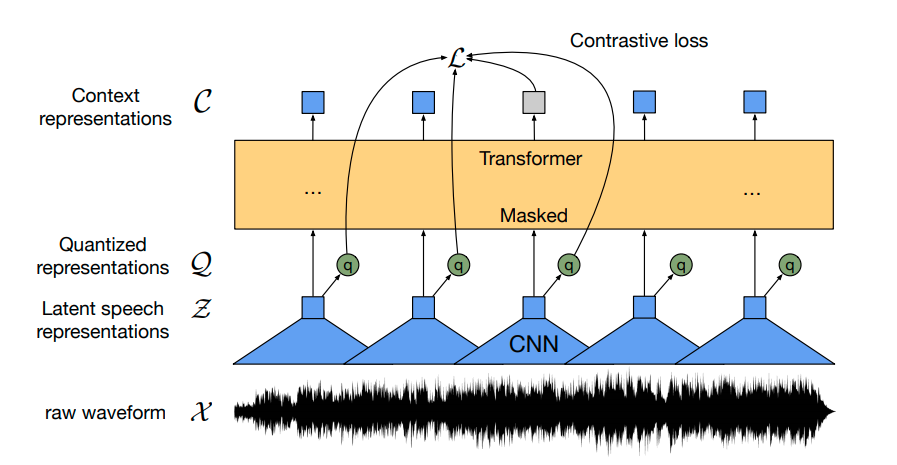
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…
CPU上でBERT推論をスケーリングアップする(パート1)
.centered { display: block; margin: 0 auto; } figure { text-align: center; display: table; max-width: 85%; /* デモです; 必要に応じていくつかの量 (px や %) を設定してください */…

BLOOMトレーニングの技術背後
近年、ますます大規模な言語モデルの訓練が一般的になってきました。これらのモデルがさらなる研究のために公開されていない問題は頻繁に議論されますが、そのようなモデルを訓練するための技術やエンジニアリングについての隠された知識は滅多に注目されません。本記事では、1760億パラメータの言語モデルBLOOMを例に、そのようなモデルの訓練の裏側にあるハードウェアとソフトウェアの技術とエンジニアリングについて、いくつかの光を当てることを目指しています。 しかし、まず、この素晴らしい1760億パラメータモデルの訓練を可能にするために貢献してくれた企業や主要な人物やグループに感謝したいと思います。 その後、ハードウェアのセットアップと主要な技術的な構成要素について説明します。 以下はプロジェクトの要約です: 人々 このプロジェクトは、Hugging Faceの共同創設者でありCSOのThomas Wolf氏が考案しました。彼は巨大な企業と競争し、単なる夢だったものを実現し、最終的な結果をすべての人にアクセス可能にすることで、最も多くの人々にとっては夢であったものを実現しました。 この記事では、モデルの訓練のエンジニアリング側に特化しています。BLOOMの背後にある技術の最も重要な部分は、私たちにコーディングと訓練の助けを提供してくれた専門家の人々と企業です。 感謝すべき6つの主要なグループがあります: HuggingFaceのBigScienceチームは、数人の専任の従業員を捧げ、訓練を始めから終わりまで行うための方法を見つけるために、Jean Zayの計算機を超えるすべてのインフラストラクチャを提供しました。 MicrosoftのDeepSpeedチームは、DeepSpeedを開発し、後にMegatron-LMと統合しました。彼らの開発者たちはプロジェクトのニーズに多くの時間を費やし、訓練前後に素晴らしい実践的なアドバイスを提供しました。 NVIDIAのMegatron-LMチームは、Megatron-LMを開発し、私たちの多くの質問に親切に答えてくれ、一流の実践的なアドバイスを提供しました。 ジャン・ゼイのスーパーコンピュータを管理しているIDRIS / GENCIチームは、計算リソースをプロジェクトに寄付し、優れたシステム管理のサポートを提供しました。 PyTorchチームは、このプロジェクトのために基礎となる非常に強力なフレームワークを作成し、訓練の準備中に私たちをサポートし、複数のバグを修正し、PyTorchコンポーネントの使いやすさを向上させました。 BigScience Engineeringワーキンググループのボランティア プロジェクトのエンジニアリング側に貢献してくれたすべての素晴らしい人々を全て挙げることは非常に困難なので、Hugging Face以外のいくつかの主要な人物を挙げます。彼らはこのプロジェクトのエンジニアリングの基盤となりました。 Olatunji Ruwase、Deepak…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.