Learn more about Search Results プルリクエスト - Page 4

- You may be interested
- (Samsung no AI to chippu gijutsu no mir...
- Typescriptによる空間データエンジニアリング
- 「時系列データセットで欠損データを特定...
- マイクロソフトAI研究は、分子システムの...
- 「オンラインプログラムで第3位のデータサ...
- 「音声のデコード」
- ケンブリッジ大学の研究者が50,000枚の合...
- 「Sierra DivisionがNVIDIA Omniverseを使...
- 『ChatGPTや他のチャットボットの安全コン...
- 「マイクロソフトのこのAI論文では、生物...
- 検索における生成AIが120以上の新しい国と...
- Deep Learningのマスタリング:Piecewise...
- 「Google BigQuery / SQLでの5つの一般的...
- 「データサイエンスの仕事を得る方法?[8...
- 2023年のトップ10 AI QRコードジェネレーター

データサイエンス入門:初心者向けガイド
この記事は新しいデータサイエンティストのためのガイドであり、迅速に始めるのを助けるために設計されていますこれは出発点となるものですが、既に新しい仕事を探している場合は、この記事をもっと読むことをお勧めします

マイクロソフトが「TypeChat」をリリース:型を使用して自然言語インターフェースを簡単に構築できるAIライブラリ
MicrosoftのTypeChatライブラリは、大規模な言語モデル(LLM)に基づいたタイプベースの自然言語インターフェースの作成を容易にする試みです。TypeChatは、TypeScriptと生成AIを通じてAPI、アプリケーションスキーマ、自然言語のギャップを埋めることを目指すGitHubプロジェクトです。TypeChatは、アプリケーションの型定義を使用して型安全な構造化AI応答を取得します。Microsoftの技術フェローであり、C#とTypeScriptのリードデベロッパーであるAnders Hejlsbergは、7月20日にTypeChatを紹介しました。これは、複雑な決定木を用いてユーザーの意図を推測し、必要なデータを収集してアクションを起こすアプリに対して自然言語インターフェースを作成するという課題に取り組むためのものです。 TypeChatは、型を使用してNLUの作成プロセスを簡略化するライブラリです。最近まで、自然言語とのインターフェースを持つアプリを開発することは困難でした。これらのアプリは、ユーザーの意図を推測し、さらなる処理のために関連するデータを収集するために、詳細な決定木を頻繁に使用していました。大規模な言語モデル(LLM)のおかげで、ユーザーの自然言語の入力を受け取り、その意図に一致させることははるかに簡単になりました。これにより、モデルの応答の妥当性を保証し、モデルの出力に必要な安全性制約を課すという新たな困難が生じました。ただし、プロンプトエンジニアリングの学習曲線は厳しく、目標はこれらの問題を修正することであっても、その成長とともにプロンプトの脆弱性も増していきます。 TypeChatの開発者は、この製品がスキーマエンジニアリングによってプロンプトエンジニアリングを効果的に代替できる可能性があると主張しています。自然言語アプリで使用できる意図は、開発者によって型として定義できます。これは、感情をラベル付けするシステムからデジタル音楽ストアのカテゴリセットまで、非常に基本的なものから洗練されたものまでです。 TypeChatは、開発者が定義した型を使用してLLMのプロンプトを構築し、そのプロンプトがスキーマに従っているかどうかを確認します。検証に失敗した場合は、言語モデルを再び対話して出力を修正し、それに従うようにします。TypeChatはまた、状況を要約し、それがユーザーの期待に一致しているかを確認します。 TypeChatの開発者は、最近のLLMに関する「興奮のラッシュ」について、多くの質問が出されていると述べています。これらのモデルの最も明らかなユースケースはチャットボットでした。ただし、従来のUIを自然言語インターフェースで補完したり、ユーザーのリクエストをアプリが処理できる形式に変換するためにAIを使用したりするなど、これらのモデルを既存のアプリインターフェースに組み込む方法についての質問が提起されています。TypeChatの目的は、これらの問題に対処することです。 この取り組みにおいて、あなたの意見とアイデアは非常に貴重です。寄付のほとんどにはContributor License Agreement(CLA)にサインする必要があり、貢献者が貢献を利用する権限を持っていることを明示します。詳細については、https://cla.opensource.microsoft.com/をご覧ください。 CLAが必要な場合、CLAボットは自動的にプルリクエストのスタイリング(ステータス、備考など)を更新してこれを反映します。ロボットが指示する通りに行ってください。CLAを使用する場合は、すべてのリポジトリに対して一度だけ行う必要があります。

「今日から使える5つの簡単なPythonの機能で、より良いコードを書き始めることができます」
「これは超きれいです 😎」や「こんな方法でできるとは知らなかった」というコメントを自分のコードやプルリクエストで見ると、素晴らしい感覚になることを認めなければなりません個人的な経験から言えば...

LAION AIは、Video2Datasetを紹介しますこれは、効率的かつスケールでビデオとオーディオのデータセットをキュレーションするために設計されたオープンソースツールです
CLIP、Stable Diffusion、Flamingoなどの大規模な基盤モデルは、過去数年間にわたり、マルチモーダルな深層学習を劇的に向上させました。テキストと画像の共同モデリングは、ニッチなアプリケーションから、今日の人工知能の領域で最も関連性の高い問題の1つ(もしくは最も関連性の高い問題)にまで進化しました。これらのモデルは、壮観で高解像度のイメージを生成したり、難しい下流の問題を解決するといった、卓越した能力を持っています。驚くべきことに、これらのモデルは、非常に異なるタスクに取り組み、非常に異なる設計を持っているにもかかわらず、強力なパフォーマンスに貢献する共通の3つの基本的な特性を持っています。それは、(事前)トレーニング中のシンプルで安定した目的関数、よく調査されたスケーラブルなモデルアーキテクチャ、そしておそらく最も重要なこととして、大規模で多様なデータセットです。 2023年現在、マルチモーダルな深層学習は、テキストと画像のモデリングに主に関心があり、ビデオ(および音声)などの追加のモダリティにはほとんど注意が払われていません。モデルをトレーニングするために使用される技術は通常モダリティに依存しないため、なぜ他のモダリティ用の堅牢な基盤モデルが存在しないのか疑問に思うかもしれません。その簡単な説明は、高品質で大規模なアノテーション付きデータセットの希少性です。クリーンなデータの不足は、特にビデオの領域において、大規模なマルチモーダルモデルの研究開発を妨げています。これに対し、画像モデリングでは、LAION-5B、DataComp、COYO-700Mなどのスケーリング用の確立されたデータセットやimg2datasetなどのスケーラブルなツールが存在します。 革新的なイニシアチブ、例えば高品質なビデオや音声の作成、改良された事前学習済みモデルのロボット工学への応用、盲人コミュニティ向けの映画ADなどを可能にするため、研究者はこのデータの問題解決を(オープンソースの)マルチモーダル研究の中心的目標として提案しています。 研究者は、高速で包括的なビデオおよび音声データセットのキュレーションを行うためのオープンソースプログラムであるvideo2datasetを提案しています。video2datasetは、いくつかの大規模なビデオデータセットで正常にテストされており、適応性があり、拡張性があり、多数の変換を提供しています。このメソッドを複製するための詳細な手順と、これらのケーススタディをリポジトリで見つけることができます。 研究者は、個々のビデオデータセットをダウンロードし、それらを結合し、新しい特徴と大量のサンプルを持つより管理しやすい形状に整形することで、既存のビデオデータセットをベースにvideo2datasetを活用してきました。より詳細な説明については、例セクションを参照してください。video2datasetが提供するデータセットで異なるモデルをトレーニングした結果は、このツールの効果を示しています。今後の研究では、新しいデータセットと関連する調査結果について詳しく議論します。 まずは、video2datasetを定義しましょう。 Webdatasetが受け入れ可能なinput_formatであるため、video2datasetは以前にダウンロードしたデータを再処理するためのチェーンで使用することができます。前の例でダウンロードしたWebVidデータを使用して、このスクリプトを実行すると、各ムービーの光流を計算し、それをメタデータシャードに保存します(光流メタデータのみを含むシャード)。 アーキテクチャ img2datasetをベースにしているvideo2datasetは、URLのリストと関連するメタデータを受け取り、単一のコマンドでロード可能なWebDatasetに変換します。さらに、同じシャードの内容を保持したまま、WebDatasetを追加の変更のために再処理することもできます。video2datasetはどのように機能するのでしょうか。説明します。 アイデアの交換 最初のステップは、入力データを均等にワーカー間で分割することです。これらの入力シャードは一時的にキャッシュされ、それらとそれらに対応する出力シャードとの一対一のマッピングにより、障害のない回復が保証されます。データセットの処理が予期せず終了した場合、既に対応する出力シャードを持つ入力シャードをスキップすることで時間を節約することができます。 コミュニケーションと研究 ワーカーは、シャードに含まれるサンプルを読み取り、処理するために交互に行動します。研究者は、マルチプロセス、pyspark、slurmの3つの異なる分散モードを提供しています。前者は単一マシンのアプリケーションに最適であり、後者は複数のマシンにスケーリングするために有用です。着信データセットの形式は、読み取り戦略を決定します。データがURLのテーブルである場合、video2datasetはインターネットからビデオを取得し、データセットに追加します。video2datasetは、見つからないビデオを要求するためにyt-dlpを使用するため、さまざまなビデオプラットフォームで動作します。ただし、ビデオサンプルが既存のWebデータセットから来る場合、そのデータセットのデータローダーはバイトまたはフレームのテンソル形式を読み取ることができます。 サブサンプリング ビデオが読み込まれ、ワーカーがビデオのバイトを取得した後、バイトはジョブの設定に従ってサブサンプラーのパイプラインを通過します。この段階では、ビデオはフレームレートと解像度の両方でオプションでダウンサンプリングされる場合があります。また、クリップされたり、シーンが識別されたりする場合もあります。一方、入力モダリティから解像度/圧縮情報、合成キャプション、オプティカルフローなどのメタデータを抽出および追加することを目的としたサブサンプラーもあります。video2datasetに新しい変換を追加するには、新しいサブサンプラーを定義するか、既存のサブサンプラーを変更するだけで十分です。これは大いに助けになり、リポジトリの他の場所で数か所の変更を行うだけで実装できます。 ログ記録 Video2datasetは、プロセスの複数のポイントで詳細なログを保持しています。各シャードの完了は、関連する「ID」_stats.jsonファイルに結果を記録します。ここには、処理されたサンプルの総数、正常に処理されたサンプルの割合、および発生したエラーの内容と性質などの情報が記録されます。Weights & Biases(wand)は、video2datasetと組み合わせて使用できる追加のツールです。この統合をオンにするだけで、成功と失敗の詳細なパフォーマンスレポートやメトリクスにアクセスできます。これらの機能は、ジョブ全体に関連するベンチマーキングやコスト見積りのタスクに役立ちます。 書き込み 最後に、video2datasetは変更された情報を出力シャードにユーザー指定の場所に保存し、次のトレーニングまたは再処理操作で使用します。データセットは、各サンプルが含まれるシャードで構成されたいくつかの形式でダウンロードできます。これらの形式には、フォルダ、tarファイル、レコード、およびparquetファイルが含まれます。デバッグ用の小規模データセットにはディレクトリ形式、ローディングにはWebDataset形式でtarファイルが使用されます。 再処理 video2datasetは、出力シャードを読み込んでサンプルを新しい変換に通過させることで、以前の出力データセットを再処理することができます。この機能は、しばしば重いサイズと扱いにくい性質が特徴のビデオデータセットに対して特に有利です。これにより、大量の大きなデータセットのダウンロードを回避するためにデータを慎重にダウンサンプリングすることができます。次のセクションでは、研究者がこれに関する実践的な例を探求します。…

Amazon SageMakerを使用して、Hugging Faceモデルを簡単にデプロイできます
今年早くも、Hugging FaceをAmazon SageMakerで利用しやすくするためにAmazonとの戦略的な協力を発表し、最先端の機械学習機能をより速く提供することを目指しています。新しいHugging Face Deep Learning Containers (DLCs)を導入し、Amazon SageMakerでHugging Face Transformerモデルをトレーニングすることができます。 今日は、Amazon SageMakerでHugging Face Transformersを展開するための新しい推論ソリューションを紹介します!新しいHugging Face Inference DLCsを使用すると、トレーニング済みモデルをわずか1行のコードで展開できます。また、Model Hubから10,000以上の公開モデルを選択し、Amazon SageMakerで展開することもできます。 SageMakerでモデルを展開することで、AWS環境内で簡単にスケーリング可能な本番用エンドポイントが提供されます。モニタリング機能やエンタープライズ向けの機能も組み込まれています。この素晴らしい協力を活用していただければ幸いです! 以下は、新しいSageMaker Hugging Face…
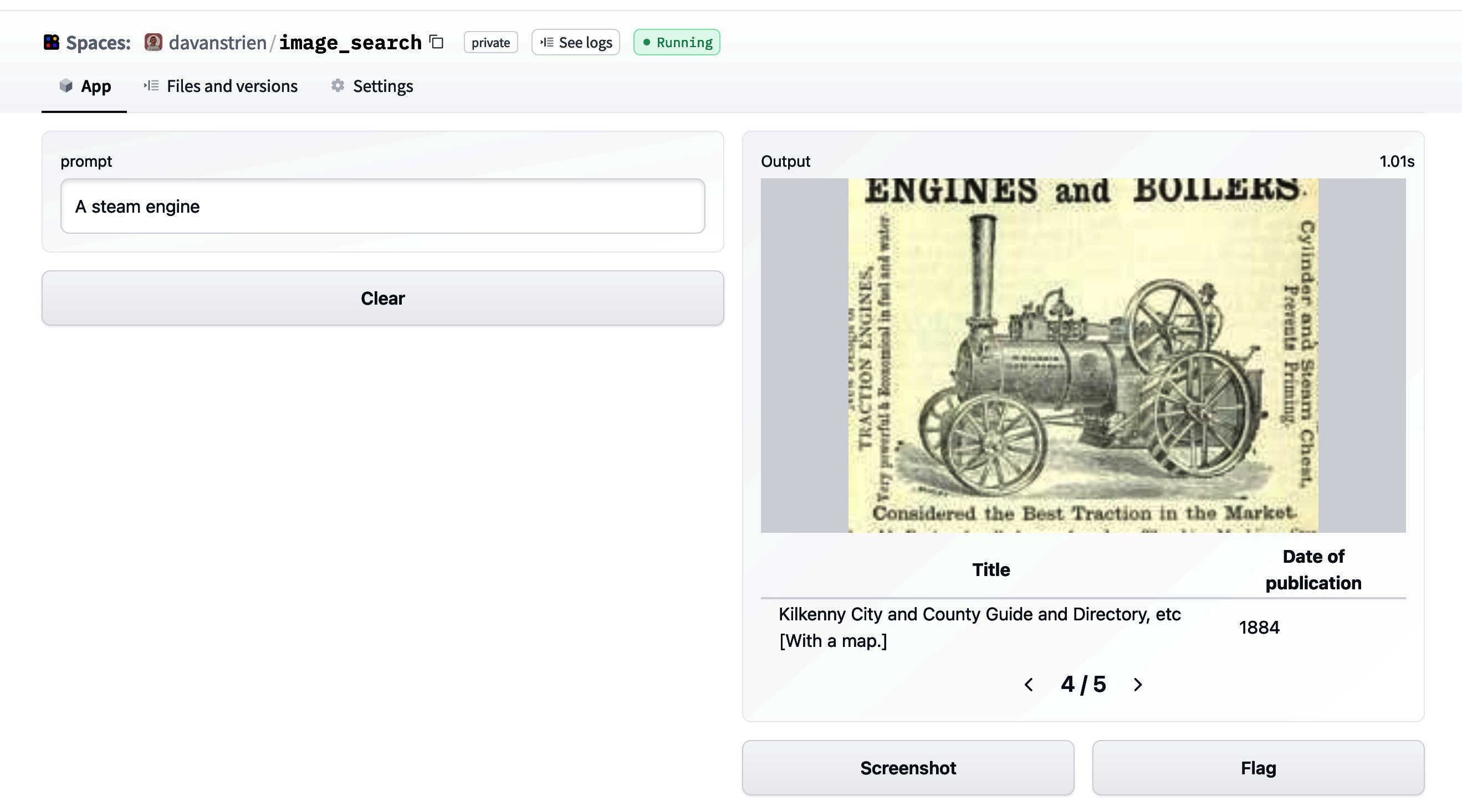
🤗データセットを使った画像検索
🤗 datasetsは、データセットに簡単にアクセスして共有することができるライブラリです。また、メモリに収まらないデータを効率的に処理することも容易にします。 datasetsが最初にリリースされた当初は、主にテキストデータと関連していました。しかし、最近では、datasetsは音声や画像に対するサポートを増やしています。特に、画像のためのdatasetsの機能タイプが追加されました。以前のブログ投稿では、datasetsと🤗 transformersを組み合わせて画像分類モデルのトレーニング方法を紹介しました。このブログ投稿では、datasetsと他のいくつかのライブラリを組み合わせて画像検索アプリケーションを作成する方法を見ていきます。 まず、datasetsをインストールします。画像を扱うために、pillowもインストールします。さらに、sentence_transformersとfaissも必要です。これらについては後ほど詳しく説明します。また、richもインストールします。ここでは簡単に使用するだけですが、非常に便利なパッケージなので、ぜひ詳しく探索してみてください! !pip install datasets pillow rich faiss-gpu sentence_transformers まずは、画像の特徴を見てみましょう。素晴らしいライブラリであるrichを使用して、Pythonオブジェクト(関数、クラスなど)を調べることができます。 from rich import inspect import datasets inspect(datasets.Image, help=True) ╭───────────────────────── <class 'datasets.features.image.Image'>…

ハギングフェイスフェローシッププログラムの発表
フェローシップは、さまざまなバックグラウンドを持つ優れた人々のネットワークであり、機械学習のオープンソースエコシステムに貢献しています🚀。このプログラムの目標は、主要な貢献者に力を与え、彼らの影響力をスケールさせると同時に、他の人々にも貢献を促すことです。 フェローシップの仕組み 🙌🏻 これはHugging Faceが貢献者の素晴らしい仕事をサポートしています!フェローであることは、すべての人にとって異なる方法で機能します。重要な質問は次のとおりです: ❓ 貢献者がより大きな影響を持つためには何が必要ですか? Hugging Faceは彼らが常にやりたかったプロジェクトを実現できるようにどのようにサポートできますか? あらゆるバックグラウンドのフェローを歓迎します!機械学習の進歩は草の根の貢献に依存しています。それぞれの人には、さまざまな方法でこの分野を民主化するために使用できる独自のスキルと知識があります。それぞれのフェローは異なる方法で影響を与え、それは完璧です🌈。 Hugging Faceは彼らが最も必要とする方法で創造し、共有し続けることをサポートします。 フェローシップに参加することの利点は何ですか? 🤩 利点は個々の興味に基づきます。Hugging Faceがフェローをサポートする例をいくつか紹介します: 💾 コンピューティングとリソース 🎁 マーチャンダイズと資産。 ✨ Hugging Faceからの公式な認知。 フェローになるには…

ハブでの評価の発表
TL;DR : 今日はAutoTrainでパワードされた新しいツール、Evaluation on the Hubを紹介します。このツールを使用すると、コードを1行も書かずにHub上の任意のモデルを任意のデータセットで評価することができます! 全てのモデルを評価しましょう🔥🔥🔥! AIの進歩は驚くべきものであり、一部の人々はAIモデルが特定のタスクにおいて人間よりも優れているかもしれないと真剣に議論しています。しかし、この進歩は均等ではありませんでした。数十年前の機械学習者にとって、現代のハードウェアやアルゴリズムは驚くべきものに見えるかもしれませんし、利用可能なデータと計算能力の量も同様ですが、モデルの評価方法はほぼ同じままでした。 しかし、現代のAIは評価の危機に直面していると言っても過言ではありません。適切な評価には、多くのモデルを多くのデータセットで、複数の指標で測定する必要があります。しかし、これを行うことは不必要に手間がかかります。特に再現性に重点を置く場合、自己報告された結果は、偶発的なバグ、実装の微妙な違い、またはそれ以上の問題によって影響を受けている可能性があります。 私たちは、より良い評価が可能であると信じています。それには、私たちコミュニティがより良いベストプラクティスを確立し、障壁を取り除こうとすることが必要です。過去数か月間、私たちはEvaluation on the Hubに取り組んできました:ボタンをクリックするだけで、任意のモデルを任意のデータセットで任意のメトリックを使用して評価することができます。始めるには、いくつかの主要なデータセットで何百ものモデルを評価し、Hub上のモデルカードに新しい素敵なPull Request機能を使用して、検証済みのパフォーマンスを表示するための多くのPRを公開しました。評価結果は、モデルカードのメタデータに直接エンコードされ、Hub上のすべてのモデルに対してフォーマットが適用されます。DistilBERTのモデルカードをチェックしてみてください! On the Hub Hub上の評価は、非常に興味深いユースケースを提供します。データサイエンティストやエグゼクティブがどのモデルを展開するかを決定する必要がある場合や、新しいデータセットで論文の結果を再現しようとする学者、展開のリスクをよりよく理解したい倫理学者などにとって、これは非常に役立ちます。最初の3つの主要なユースケースシナリオを挙げると、次のようなものがあります: タスクに最適なモデルを見つける 自分のタスクが明確であり、その仕事に適したモデルを見つけたいとします。タスクを代表するデータセットのリーダーボードをチェックできます。素晴らしいですね!もし興味のある新しいモデルが、そのデータセットのリーダーボードにまだ掲載されていない場合は、Hubを離れずに評価を実行することができます。 新しいデータセットでモデルを評価する 新しく作成したデータセットでベースラインを実行したい場合はどうでしょう?Hubにアップロードして、それに対して評価したいモデルを何個でも評価することができます。コードは不要です。さらに、自分のデータセットでこれらのモデルを評価する方法が、他のデータセットで評価された方法とまったく同じであることを確信することができます。 自分のモデルを他の関連する多くのデータセットで評価する また、SQuADでトレーニングされた全く新しい質問応答モデルがあるとしましょう。評価するためのさまざまな質問応答データセットが何百もあります…

プライベートハブのご紹介:機械学習を活用した新しいビルド方法
機械学習は、企業が技術を構築する方法を変えつつあります。革新的な新製品のパワーを供給し、私たちが使い慣れて愛している既知のアプリケーションにスマートな機能を提供することから、MLは開発プロセスの中心にあります。 しかし、すべての技術の変化には新たな課題が伴います。 機械学習モデルの約90%が本番環境に到達しないとされています。馴染みのないツールや非標準的なワークフローがMLの開発を遅くしています。モデルやデータセットが内部で共有されないため、同じような成果物がチーム間で常にゼロから作成されます。データサイエンティストは、ビジネスステークホルダーに技術的な作業を示すのが難しく、正確でタイムリーなフィードバックを共有するのに苦労しています。そして、機械学習チームはDocker/Kubernetesや本番環境向けのモデル最適化に時間を浪費しています。 これらを考慮して、私たちはPrivate Hub(PH)を立ち上げました。機械学習の構築方法を革新する新しい方法です。研究から本番環境まで、セキュアかつコンプライアンスを確保しながら、機械学習ライフサイクルの各ステップを加速するための統合されたツールセットを提供します。PHはさまざまなMLツールを一つにまとめることで、機械学習の協力をよりシンプルで楽しく、生産的にします。 このブログ投稿では、Private Hubとは何か、なぜ役立つのか、そしてどのようにお客様がそれを使用してMLのロードマップを加速しているのかについて詳しく説明します。 一緒に読んでいただくか、興味を引くセクションにジャンプしてください 🌟: ハグフェースハブとは何ですか? プライベートハブとは何ですか? 企業はプライベートハブをどのように使用してMLのロードマップを加速しているのでしょうか? さあ、始めましょう! 🚀 1. ハグフェースハブとは何ですか? プライベートハブについて詳しく説明する前に、まずハグフェースハブについて見てみましょう。これはPHの中心的な要素です。 ハグフェースハブは、オープンソースで公開されているオンラインプラットフォームで、人々が簡単に協力してMLを構築できる場所です。ハブは、機械学習と一緒に技術を探求し、実験し、協力し、構築するための中心的な場所として機能します。 ハグフェースハブでは、次のようなMLアセットを作成または発見することができます: モデル:NLP、コンピュータビジョン、音声、時系列、生物学、強化学習、化学などの最新の最先端モデルをホスティング。 データセット:さまざまなドメイン、モダリティ、言語に対応したデータの幅広いバリエーション。 スペース:ブラウザ内で直接MLモデルをショーケースするインタラクティブなアプリ。 ハブにアップロードされた各モデル、データセット、またはスペースは、Gitベースのリポジトリです。これはすべてのファイルを含むバージョン管理された場所で、従来のgitコマンドを使用してファイルをプル、プッシュ、クローン、操作することができます。モデル、データセット、およびスペースのコミット履歴を表示し、誰がいつ何を行ったかを確認することができます。 モデルのコミット履歴…

transformers、accelerate、bitsandbytesを使用した大規模トランスフォーマーの8ビット行列乗算へのやさしい入門
導入 言語モデルはますます大きくなっています。この執筆時点では、PaLMは540Bのパラメータを持ち、OPT、GPT-3、およびBLOOMは約176Bのパラメータを持ち、さらに大きなモデルに向かっています。以下は、いくつかの最近の言語モデルのサイズを示した図です。 したがって、これらのモデルは簡単にアクセス可能なデバイス上で実行するのが難しいです。例えば、BLOOM-176Bで推論を行うためには、8つの80GBのA100 GPU(各約15,000ドル)が必要です。BLOOM-176Bを微調整するには、これらのGPUが72台必要です!PaLMのようなさらに大きなモデルでは、さらに多くのリソースが必要です。 これらの巨大なモデルは多くのGPUで実行する必要があるため、モデルの性能を維持しながらこれらの要件を削減する方法を見つける必要があります。モデルサイズを縮小するためのさまざまな技術が開発されており、量子化や蒸留などの技術があります。 BLOOM-176Bのトレーニングを完了した後、HuggingFaceとBigScienceでは、この大きなモデルをより少ないGPUで簡単に実行できるようにする方法を探していました。BigScienceコミュニティを通じて、大規模モデルの予測パフォーマンスを低下させずに大規模モデルのメモリフットプリントを2倍に減らすInt8推論の研究について知らされました。すぐにこの研究に協力し始め、Hugging Faceのtransformersに完全に統合することで終了しました。このブログ記事では、Hugging FaceモデルのLLM.int8()統合を提供し、詳細を以下で説明します。研究についてもっと読みたい場合は、論文「LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale」を読んでください。 この記事では、この量子化技術の高レベルの概要を提供し、transformersライブラリへの統合の難しさを概説し、このパートナーシップの長期的な目標を立てます。 ここでは、なぜ大きなモデルが多くのメモリを使用するのか、BLOOMが350GBになる理由について、少しずつ基本的な前提を説明します。 機械学習で使用される一般的なデータ型 まず、機械学習の文脈では「精度」とも呼ばれる異なる浮動小数点データ型の基本的な理解から始めます。 モデルのサイズは、そのパラメータの数とその精度によって決まります。一般的には、float32、float16、またはbfloat16のいずれかのデータ型が使用されます(以下の画像は、https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/から引用されています)。 Float32(FP32)は、標準化されたIEEE 32ビット浮動小数点表現を表します。このデータ型では、幅広い浮動小数点数を表現することが可能です。FP32では、8ビットが「指数」に、23ビットが「仮数」に、1ビットが数値の符号に予約されています。さらに、ほとんどのハードウェアはFP32の操作と命令をサポートしています。 浮動小数点16ビット(FP16)のデータ型では、5ビットが指数に、10ビットが仮数に予約されています。これにより、FP16数の表現可能な範囲はFP32よりもはるかに低くなります。これにより、FP16数はオーバーフロー(非常に大きな数を表現しようとする)やアンダーフロー(非常に小さな数を表現する)のリスクにさらされます。 例えば、10k…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.