Learn more about Search Results このリンク - Page 4

- You may be interested
- 「ヒープデータ構造の紹介」
- このAI研究では、詳細な全身のジオメトリ...
- 「ファストテキストを使用したシンプルな...
- 私たちが知っていることを蒸留する
- 「HuggingFace Transformers ツールとエー...
- テックとマインドのバランス:メンタルヘ...
- IBMとMETAが責任あるイノベーションのため...
- 「Seaborn KDE プロット上のデータポイン...
- 「ファウンデーションモデルの安全で準拠...
- オープンAIのファンクションコーリング入門
- MuZeroの研究から現実世界への第一歩
- ChatGPT 4 API、Google Meet、Google Driv...
- Office 365の移行と管理を外部委託する主...
- 「AmazonショッピングがAmazon Rekognitio...
- 「ChatGPTをより優れたソフトウェア開発者...

LangChainとLLMsのための非同期処理
「この記事では、LangChainを使用してLLMに非同期呼び出しを行い、長いワークフローを処理する方法について説明します実際のコードを使用した例を通じて、順次実行と比較しながら進めます...」

🤗 Transformersを使用して、Wav2Vec2を使用して大規模なファイルで自動音声認識を行う方法
Tl;dr: この投稿では、Connectionist Temporal Classification(CTC)アーキテクチャの特性を活用して、任意の長さのファイルやライブ推論中でも非常に良い品質の自動音声認識(ASR)を実現する方法を説明します。 Wav2Vec2は、音声認識のための人気のある事前学習モデルです。Meta AI Researchによって2020年9月にリリースされ、この新しいアーキテクチャは、自己教師あり事前学習における音声認識の進歩を促進しました(例:G. Ng et al.、2021年、Chen et al.、2021年、Hsu et al.、2021年、Babu et al.、2021年)。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは、現在月間25万回以上ダウンロードされています。 Wav2Vec2は、その核としてtransformersモデルを使用しており、transformersの注意点の1つは、通常、扱えるシーケンスの長さに限界があることです。それは位置符号化を使用するためではなく(この場合は違います)、単純にtransformersの注意コストが実際にはO(n²)となり、非常に大きなシーケンス長を使用すると複雑さやメモリの使用量が爆発します。したがって、非常に長いファイルでさえWav2Vec2を実行することはできません(たとえA100のような非常に大きなGPUを使用しても)。プログラムはクラッシュします。試してみましょう! pip install transformers from transformers…
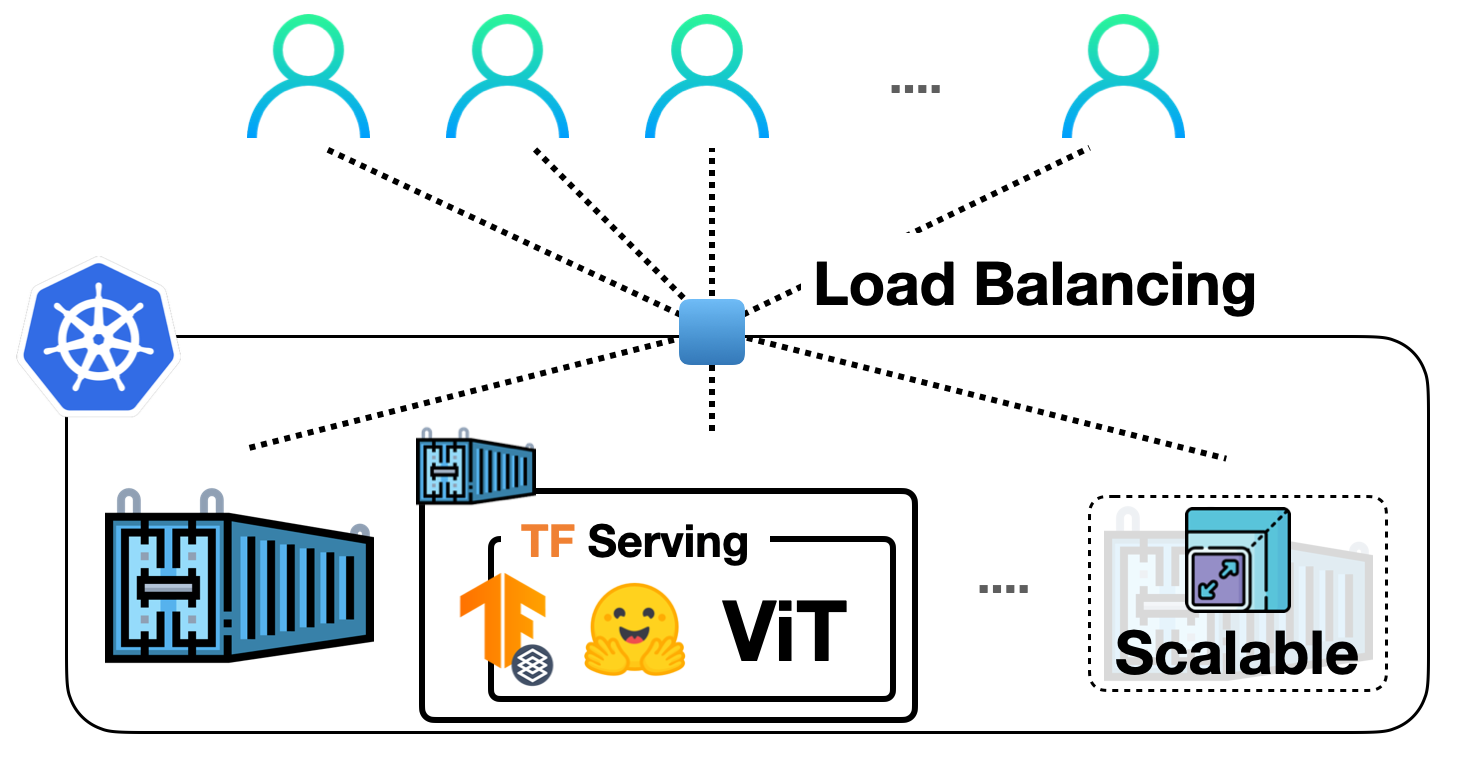
TF Servingを使用してKubernetes上に🤗 ViTをデプロイする
前の投稿では、TensorFlow Servingを使用して🤗 TransformersからVision Transformer(ViT)モデルをローカルに展開する方法を示しました。ビジョントランスフォーマーモデル内での埋め込み前処理および後処理操作、gRPCリクエストの処理など、さまざまなトピックをカバーしました! ローカル展開は、有用なものを構築するための優れたスタート地点ですが、実際のプロジェクトで多くのユーザーに対応できる展開を実行する必要があります。この投稿では、前の投稿のローカル展開をDockerとKubernetesでスケーリングする方法を学びます。したがって、DockerとKubernetesに関する基本的な知識が必要です。 この投稿は前の投稿に基づいていますので、まずそれをお読みいただくことを強くお勧めします。この投稿で説明されているコードは、このリポジトリで確認することができます。 私たちの展開をスケールアップする基本的なワークフローは、次のステップを含みます: アプリケーションロジックのコンテナ化:アプリケーションロジックには、リクエストを処理して予測を返すサービスモデルが含まれます。コンテナ化するために、Dockerが業界標準です。 Dockerコンテナの展開:ここにはさまざまなオプションがあります。最も一般的に使用されるオプションは、DockerコンテナをKubernetesクラスターに展開することです。Kubernetesは、展開に便利な機能(例:自動スケーリングとセキュリティ)を提供します。ローカルでKubernetesクラスターを管理するためのMinikubeのようなソリューションや、Elastic Kubernetes Service(EKS)のようなサーバーレスソリューションを使用することもできます。 SagemakerやVertex AIのような、MLデプロイメント固有の機能をすぐに利用できる時代に、なぜこのような明示的なセットアップを使用するのか疑問に思うかもしれません。それは考えるのは当然です。 上記のワークフローは、業界で広く採用され、多くの組織がその恩恵を受けています。長年にわたってすでに実戦投入されています。また、複雑な部分を抽象化しながら、展開に対してより細かな制御を持つことができます。 この投稿では、Google Kubernetes Engine(GKE)を使用してKubernetesクラスターをプロビジョニングおよび管理することを前提としています。GKEを使用する場合、請求を有効にしたGCPプロジェクトが既にあることを想定しています。また、GKEで展開を行うためにgcloudユーティリティを構成する必要があります。ただし、Minikubeを使用する場合でも、この投稿で説明されているコンセプトは同様に適用されます。 注意:この投稿で表示されるコードスニペットは、gcloudユーティリティとDocker、kubectlが構成されている限り、Unixターミナルで実行できます。詳しい手順は、付属のリポジトリで入手できます。 サービングモデルは、生のイメージ入力をバイトとして処理し、前処理および後処理を行うことができます。 このセクションでは、ベースのTensorFlow Servingイメージを使用してそのモデルをコンテナ化する方法を示します。TensorFlow Servingは、モデルをSavedModel形式で消費します。前の投稿でSavedModelを取得した方法を思い出してください。ここでは、SavedModelがtar.gz形式で圧縮されていることを前提としています。万が一必要な場合は、ここから入手できます。その後、SavedModelは<MODEL_NAME>/<VERSION>/<SavedModel>という特別なディレクトリ構造に配置する必要があります。これにより、TensorFlow Servingは異なるバージョンのモデルの複数の展開を同時に管理できます。 Dockerイメージの準備…
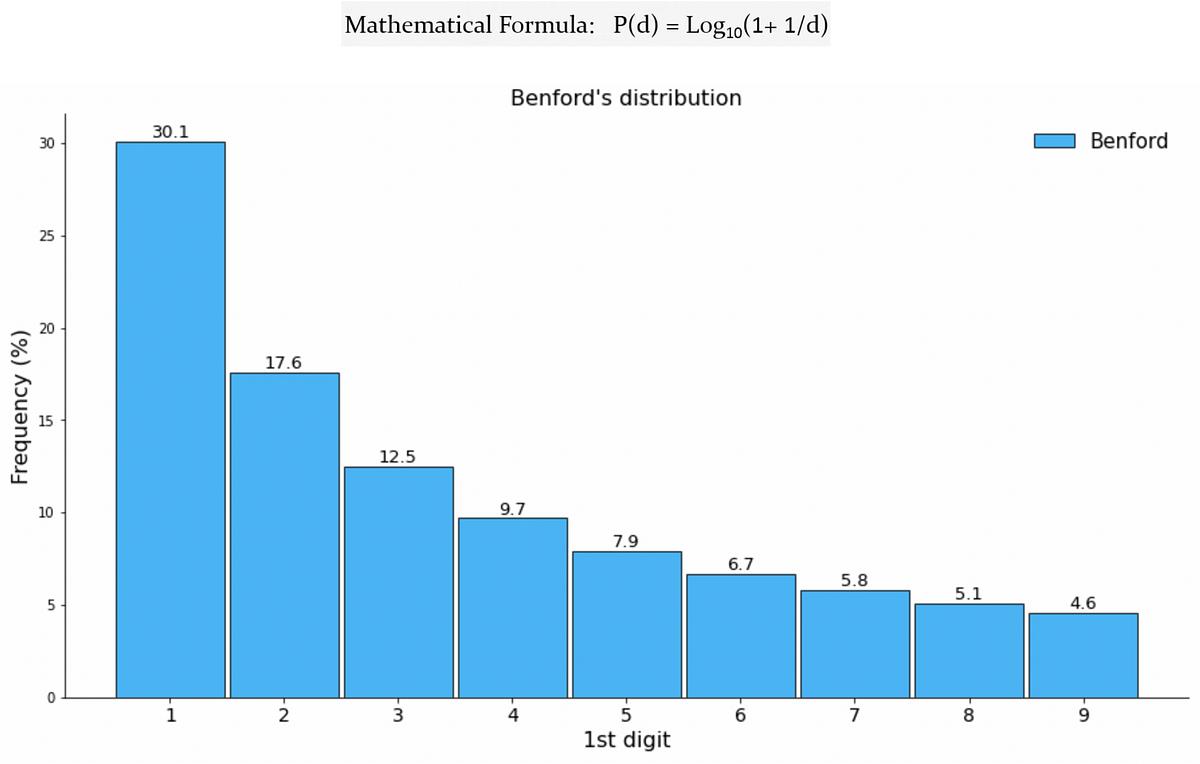
Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
ソーシャルメディアの広大なデジタル領域において、ユーザーの真正性は最も重要な懸念事項ですTwitterなどのプラットフォームが成長するにつれ、フェイクアカウントの増加も増えていますこれらのアカウントは本物のアカウントを模倣します
Pythonを使った感情分析(Sentiment Analysis)のFlair
シリーズ記事の次のブログへようこそ!今日は、感情分析のためのPythonライブラリで使用される方法の1つであるFlairを探求しますFlairは、NLP(自然言語処理)ライブラリです...

RAPIDS:簡単にMLモデルを加速するためにGPUを使用する
はじめに 人工知能(AI)がますます成長するにつれて、より高速かつ効率的な計算能力の需要が高まっています。機械学習(ML)モデルは計算量が多く、モデルのトレーニングには時間がかかることがあります。しかし、GPUの並列処理能力を使用することで、トレーニングプロセスを大幅に加速することができます。データサイエンティストはより速く反復し、より多くのモデルで実験し、より短い時間でより良い性能のモデルを構築することができます。 使用できるライブラリはいくつかあります。今日は、GPUの知識がなくてもMLモデルの加速化にGPUを使用する簡単な解決策であるRAPIDSについて学びます。 学習目標 この記事では、以下のことについて学びます: RAPIDS.aiの概要 RAPIDS.aiに含まれるライブラリ これらのライブラリの使用方法 インストールとシステム要件 この記事は、Data Science Blogathonの一部として公開されました。 RAPIDS.AI RAPIDSは、GPU上で完全にデータサイエンスパイプラインを実行するためのオープンソースのソフトウェアライブラリとAPIのスイートです。RAPIDSは、最も人気のあるPyDataライブラリと一致する使い慣れたAPIを持ちながら、優れたパフォーマンスと速度を提供します。これは、NVIDIA CUDAとApache Arrowで開発されており、その非凡なパフォーマンスの理由です。 RAPIDS.AIはどのように動作するのですか? RAPIDSは、GPUを使用した機械学習を利用してデータサイエンスおよび分析ワークフローのスピードを向上させます。GPU最適化されたコアデータフレームを持っており、データベースと機械学習アプリケーションの構築を支援し、Pythonに似た設計となっています。RAPIDSは、データサイエンスパイプラインを完全にGPU上で実行するためのライブラリのコレクションを提供します。これは、2017年にGPU Open Analytics Initiative(GoAI)と機械学習コミュニティのパートナーによって作成され、Apache Arrowのカラムメモリプラットフォームに基づいたGPUデータフレームを使用して、エンドツーエンドのデータサイエンスおよび分析ワークフローをGPU上で加速するためのものです。RAPIDSには、機械学習アルゴリズムと統合されるDataframe APIも含まれています。 データの移動量を減らした高速データアクセス…
データモデリングの成功を解き放つ:3つの必須のコンテキストテーブル
データモデリングは、分析チームにとって課題となることがあります各組織には独自のビジネスエンティティが存在するため、それぞれのテーブルに適切な構造と詳細度を見つけることは限りなく難しいものですしかし、

マーケティング予算の最適化方法
マーケティングミックスモデルは、異なるマーケティングチャネルが売上に与える影響を理解するための強力なツールですマーケターはマーケティングミックスモデルを構築することにより、各要素の貢献度を定量化することができます
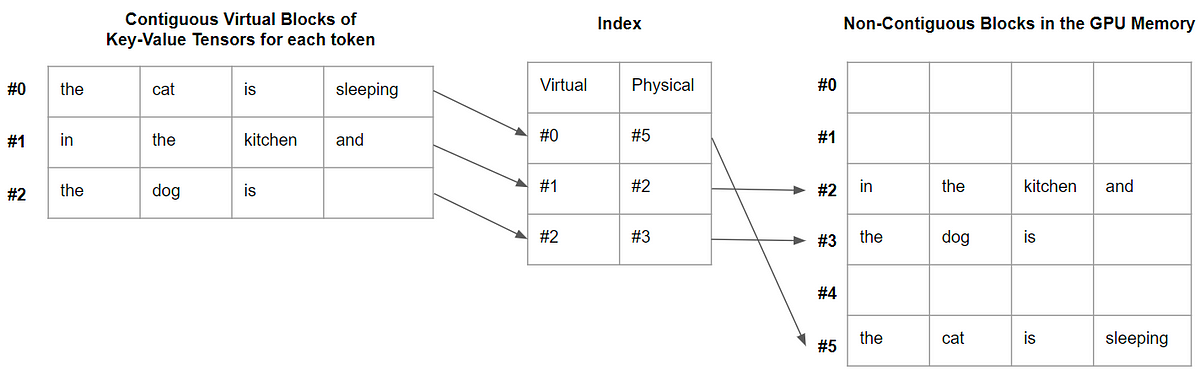
vLLM:24倍速のLLM推論のためのPagedAttention
この記事では、PagedAttentionとは何か、そしてなぜデコードを大幅に高速化するのかを説明します
線形回帰の理論的な深堀り
多くのデータサイエンス志望のブロガーが行うことがあります 線形回帰に関する入門的な記事を書くことですこれは、この分野に入る際に最初に学ぶモデルの1つであるため、自然な選択肢です...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.