Learn more about Search Results Yi - Page 49

- You may be interested
- 人間のフィードバックからの強化学習(RLHF)
- 「LLMの評価にLLMを使用する」
- 「PolyLM(Polyglot Large Language Model...
- Snowflakeにおけるクエリ性能の向上と関連...
- メイヨークリニックのAI研究者たちは、拡...
- 「不確定性原理は時間系列解析をどのよう...
- 「2024年のデータサイエンティストにとっ...
- 「ニューラルネットワークの多様性の力を...
- ウェイブは、LINGO-1という新しいAIモデル...
- 自然言語処理ツールキット(NLTK)感情分...
- 最適なテクノロジー/ベンダーを選ぶための...
- 「金融ソフトウェア開発の世界:財務ソリ...
- JavaScriptを使用してOracleデータベース...
- 「研究データ管理の変革:AIの役割による...
- 「Matplotlibのマスタリング:データ可視...

「AIのプロセス」
AIはまだ比較的新しい分野と見なされているため、SWEBOKのようなガイドや標準は実際には存在しません実際に、AI/MLの修士課程の教科書にはAIの明確かつ一貫した説明が提供されていません...

「ウェブマップを使用した空間データの表示」
地図を作る方法はたくさんありますQGISやArcGISなどのデスクトップGISソフトウェア、LeafletやMapbox GL JSなどのウェブフレームワーク、またはインクと紙を使って昔ながらの方法で作ることもできますウェブ...

Google DeepMindの研究者がSynJaxを紹介:JAX構造化確率分布のためのディープラーニングライブラリ
データは、その構成要素がどのように組み合わさって全体を形成するかを説明するさまざまな領域で構造を持っていると見なすことができます。活動によっては、この構造は通常潜在的であり、変化します。自然言語の異なる構造の例を図1に示します。単語は一連の単語で構成され、それぞれの単語には品詞タグが適用されます。これらのタグは相互に関連し、赤色の線状の連鎖を生成します。文の分割により、泡で示された文の単語は小さな不連続なクラスターに組み合わせることができます。言語のより詳細な調査では、グループを再帰的に作成し、構文木構造を作成することができます。構造は2つの言語を結びつけることもできます。 たとえば、同じ画像内のアライメントは、日本語の翻訳を英語のソースにリンクさせることができます。これらの文法的構造は普遍的です。生物学では、類似の構造が見つかることがあります。RNAのツリーベースのモデルは、タンパク質の折りたたみ過程の階層的な側面を捉えていますが、一方、単調なアライメントはRNA配列のヌクレオチドを一致させるために使用されます。ゲノムデータも連続したグループに分割されます。ほとんどの現在の深層学習モデルは、中間構造を明示的に表現しようとせず、入力から直接出力変数を予測しようとします。これらのモデルは、さまざまな方法で構造の明示的なモデリングから利益を得ることができます。適切な帰納バイアスを使用することで、改善された一般化が容易になります。これにより、サンプル効率性に加えて下流のパフォーマンスも向上します。 図1: 自然言語構造の例。 明示的な構造モデリングは、問題固有の制約や方法を組み込むことができます。離散的な構造のため、モデルが行った判断はより理解しやすくなります。最後に、構造が学習自体の結果である場合もあります。たとえば、データが特定の形状の隠れた構造によって説明されることを知っているが、それについてさらに詳しく知る必要がある場合があります。シーケンスのモデリングでは、自己回帰モデルが主流の技術です。一部の場合では、非順序の構造を線形化し、順序構造で近似することができます。これらのモデルは、独立した仮定に依存せず、多くのデータを使用してトレーニングすることができるため、強力です。最適な構造の特定や隠れた変数の周辺化は一般的な推論の問題ですが、自己回帰モデルからのサンプリングはしばしば扱いにくいです。 大規模モデルにおいて自己回帰モデルを使用することは、バイアスのあるまたは高分散の近似を要求するため、しばしば計算コストが高いです。対象構造と同じように因子グラフ上のモデルは、自己回帰モデルの代替手段です。これらのモデルは、専用の手法を使用することで興味深い推論問題を正確かつ効率的に計算することができます。各構造には固有の方法が必要ですが、各推論タスクには専用のアルゴリズム(argmax、サンプリング、周辺、エントロピーなど)は必要ありません。SynJaxでは、各構造タイプごとに1つの関数から複数の数値を抽出するために、自動微分を使用しています。 図2: ポリシーグラディエントによる自己反省ベースラインとエントロピー正則化を用いた生成木の実装例。 構造要素のアクセラレータに対応した実装を提供する実用的なライブラリが存在しないため、構造化分布の深い理解のための研究は遅れています。特に、これらのコンポーネントは、Transformerモデルとは異なり、利用可能な深層学習プリミティブに直接マッピングしないアルゴリズムに依存することが頻繁にあります。Google Deepmindの研究者は、JAX機械学習フレームワーク内で組み合わせるための簡単に使用できる構造プリミティブを提供し、SynJaxがこの課題を解決するのに役立っています。使用法を示すために、図2の例を考えてください。このコードでは、サンプリング、argmax、エントロピー、および対数確率を含むいくつかのパラメータを計算する必要があるポリシーグラディエント損失を実装しています。それぞれのパラメータを計算するには、別々のアプローチが必要です。 このコード行では、非射影的な有向全域木であり、単一のルートエッジ制約があります。その結果、SynJaxは単一ルートツリーに対してdist.sample() Wilsonのサンプリング手法、dist.entropy()、およびTarjanの最大全域木アルゴリズムを使用します。単一ルートエッジツリーでは、Matrix-Tree定理を使用することができます。SynJaxはそのようなアルゴリズムに関連するすべてのことを処理するため、ユーザーはそれらを実装することなく、またはそれらがどのように機能するかを理解することなく、自分の問題のモデリングに集中することができます。

「文書理解の進展」
Google Research、Athenaチームのソフトウェアエンジニア、サンディープ・タタ氏による投稿 過去数年間で、複雑なビジネスドキュメントを自動的に処理し、それらを構造化されたオブジェクトに変換するシステムの進歩が急速に進んでいます。領収書、保険見積もり、財務報告書などのドキュメントからデータを自動的に抽出するシステムは、エラーが多く手作業が必要な作業を回避することで、ビジネスワークフローの効率を劇的に向上させる潜在能力を持っています。Transformerアーキテクチャに基づいた最近のモデルは、驚異的な精度の向上を示しています。PaLM 2などのより大規模なモデルは、これらのビジネスワークフローをさらに効率化するために活用されています。しかし、学術文献で使用されるデータセットは、現実のユースケースで見られる課題を捉えることができていません。その結果、学術ベンチマークはモデルの精度を高く報告していますが、同じモデルを複雑な現実世界のアプリケーションに使用すると、精度が低下します。 KDD 2023で発表された「VRDU: A Benchmark for Visually-rich Document Understanding」では、このギャップを埋め、研究者がドキュメント理解タスクの進捗状況をより正確に追跡できるようにするため、新しいVisually Rich Document Understanding(VRDU)データセットの公開を発表しています。私たちは、ドキュメント理解モデルが頻繁に使用される実世界のドキュメントの種類に基づいて、良いドキュメント理解ベンチマークのための5つの要件をリストアップしています。そして、現在研究コミュニティで使用されているほとんどのデータセットがこれらの要件のいずれかを満たしていないことを説明し、一方でVRDUはこれらの要件をすべて満たしていることを説明しています。私たちは、VRDUデータセットと評価コードをクリエイティブ・コモンズ・ライセンスの下で公開することを発表できることを喜んでいます。 ベンチマークの要件 まず、実世界のユースケースでの最先端のモデルの精度(例:FormNetやLayoutLMv2との比較)を学術ベンチマーク(例:FUNSD、CORD、SROIE)と比較しました。その結果、最先端のモデルは学術ベンチマークの結果とは一致せず、実世界でははるかに低い精度を提供しました。次に、ドキュメント理解モデルが頻繁に使用される典型的なデータセットを学術ベンチマークと比較し、実世界のアプリケーションの複雑さをより良く捉えるための5つのデータセットの要件を特定しました: リッチスキーマ:実際の実務では、構造化抽出のためのさまざまな豊富なスキーマが存在します。エンティティには異なるデータ型(数値、文字列、日付など)があり、単一のドキュメント内で必須、オプション、または繰り返しの場合もあり、さらにネストする場合もあります。ヘッダ、質問、回答などの単純なフラットなスキーマの抽出タスクでは、実務でよく遭遇する問題を反映していません。 レイアウト豊かなドキュメント:ドキュメントには複雑なレイアウト要素が含まれている必要があります。実践的な設定での課題は、ドキュメントにテーブル、キーと値のペア、単一列と二列のレイアウトの切り替え、異なるセクションのフォントサイズの変化、キャプション付きの画像や脚注などが含まれることです。これに対して、ほとんどのドキュメントが文、段落、セクションヘッダを持つ文章で構成されているデータセットとは対照的です。これは、長い入力に関する古典的な自然言語処理文献の焦点となるようなドキュメントの種類です。 異なるテンプレート:ベンチマークには異なる構造のレイアウトやテンプレートが含まれるべきです。特定のテンプレートから抽出することは、高容量モデルにとっては容易ですが、実際の実務では新しいテンプレート/レイアウトにも対応できる汎化能力が必要です。ベンチマークのトレーニングとテストの分割によって測定される能力です。 高品質なOCR:ドキュメントは高品質な光学文字認識(OCR)の結果を持っている必要があります。このベンチマークでは、VRDUタスク自体に焦点を当て、OCRエンジンの選択によってもたらされる変動性を除外することを目指しています。 トークンレベルの注釈:ドキュメントには、対応する入力テキストの一部としてマッピングできる正解の注釈が含まれている必要があります。これにより、各トークンを対応するエンティティの一部として注釈付けすることができます。これは、単にエンティティから抽出するための値のテキストを提供するだけではありません。これは、与えられた値に偶発的な一致があることを心配する必要がないクリーンなトレーニングデータの生成に重要です。たとえば、一部の領収書では、「税抜き合計」フィールドが「合計」フィールドと同じ値を持つ場合があります。トークンレベルの注釈があれば、両方の一致する値が「合計」フィールドの正解としてマークされたトレーニングデータを生成することを防ぐことができ、ノイズのない例を生成できます。 VRDUのデータセットとタスク VRDUデータセットは、登録フォームと広告購入フォームの2つの公開データセットを組み合わせたものです。これらのデータセットは、実世界の使用例を代表する例を提供し、上記の5つのベンチマーク要件を満たしています。…
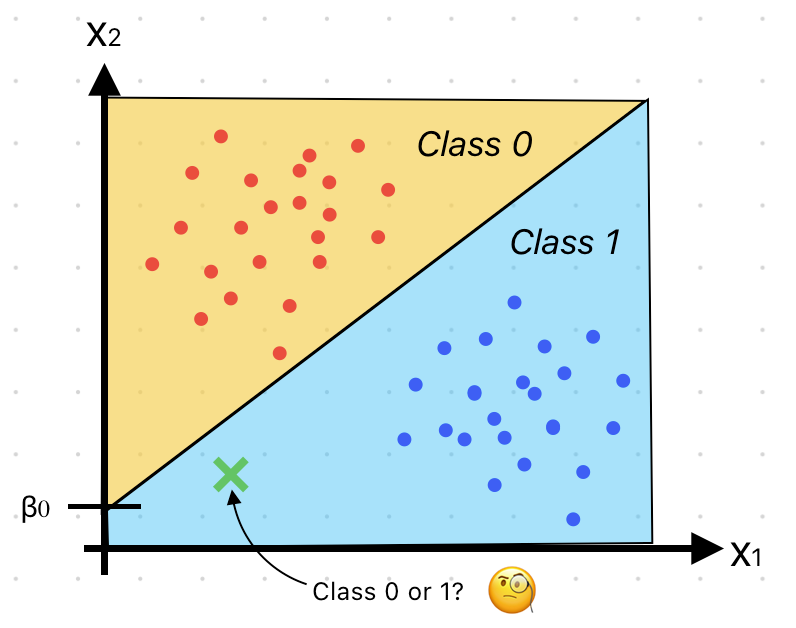
「ロジスティック回帰の謎解き:簡単なガイド」
データサイエンスと機械学習の世界において、ロジスティック回帰は強力で広く使われているアルゴリズムですその名前にもかかわらず、物流や商品の移動とは何の関係もありません...

「分析ストリーム処理への控えめな紹介」
「基礎は揺るぎない、壊れることのない構造物の土台です成功したデータアーキテクチャを構築する際には、データがシステム全体の中心的な要素です...」

「ゼロ冗長最適化(ZeRO):Pythonによる短い紹介」
ゼロ冗長最適化器がデータ並列処理を変換する方法を明らかにし、メモリと計算効率を向上させます

「S4 HANAとDomoでSQLを使用してデータ分析を超高速化する:機械学習の視点から」
「利用可能な多くのテクノロジーの中で、SQL、マシンラーニング、S4 HANA、そしてDomoの4つが際立っていますこれらは強力な洞察を解き放ち、企業に競争上の優位性を与えることができます」
シミュレーション105:数値積分によるダブルペンデュラムモデリング
振り子は、私たちがみなよく知っている古典的な物理学のシステムです祖父時計であろうと、ブランコで遊ぶ子供であろうと、振り子の規則的で周期的な運動を見たことがあります一つの振り子...
StackOverflowの転機:破壊から機会への転換
GPT4のような非常に効果的なモデルが登場し、生成型AIを強化していることで、データ専門家が所属する組織に長期的な価値を提供する方法が進化しています真の価値は...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.