Learn more about Search Results 6. 結論 - Page 49

- You may be interested
- 「9歳の子に機械学習を説明するとしたら、...
- データ再構築の革命:広範な情報検索にお...
- オープンAIは、人工汎用知能への追加資金...
- 光ニューラルネットワークとトランスフォ...
- Google AIは、ドキュメント理解タスクの進...
- 「OpenAI、3ヶ月で約20%のトラフィック減...
- データ分析におけるサンプリング技術
- 土木技術者からデータサイエンティストへ...
- 「AIが大気衝撃波から津波の初期兆候を見...
- Google at ACL 2023′ ACL 2023にお...
- 「PythonとMatplotlibを使用して米国のデ...
- このAI研究は、大規模言語モデル(LLM)に...
- AIが置き換えることができない仕事
- 「APIガバナンスによるAIインフラストラク...
- NVIDIAは、AIプロセッサの供給において日...
CPU上でBERT推論をスケーリングアップする(パート1)
.centered { display: block; margin: 0 auto; } figure { text-align: center; display: table; max-width: 85%; /* デモです; 必要に応じていくつかの量 (px や %) を設定してください */…
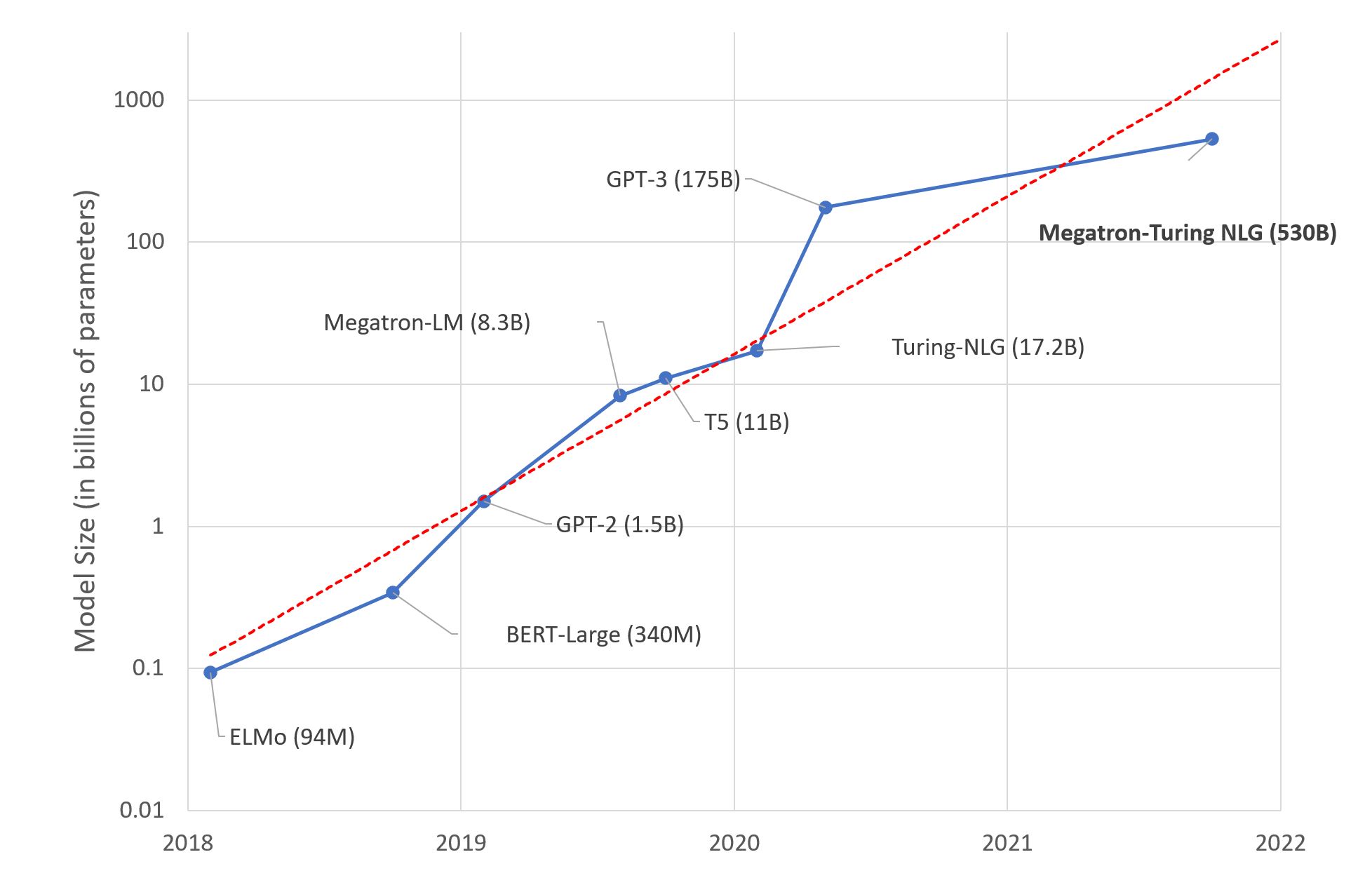
大規模言語モデル:新たなモーアの法則?
数日前、MicrosoftとNVIDIAは「世界最大かつ最もパワフルな生成言語モデル」と称される、Megatron-Turing NLG 530BというTransformerベースのモデルを発表しました。 これは、間違いなく機械学習エンジニアリングの印象的なデモンストレーションです。しかし、このメガモデルのトレンドに興奮すべきでしょうか?私自身はそう思いません。以下にその理由を説明します。 これがディープラーニングの脳です 研究者は、人間の脳が平均して860億個のニューロンと100兆個のシナプスを持つと推定しています。言語に特化しているわけではないことは明らかです。興味深いことに、GPT-4は約100兆個のパラメータを持つ予定です…この例えがどれほど不正確かもしれませんが、人間の脳と同じくらいの大きさの言語モデルを構築することが最善の長期的なアプローチなのか疑問に思わないでしょうか? もちろん、私たちの脳は進化の結果として何百万年もの間に生まれた驚異的なデバイスですが、ディープラーニングモデルは数十年しか存在していません。それでも、私たちの直感が何かが計算できないと感じるはずです。 ディープラーニング、深いポケット? 予想通り、巨大なテキストデータセットで5300億のパラメータを持つモデルをトレーニングするためには、相当なインフラストラクチャが必要です。実際に、MicrosoftとNVIDIAは数百台のDGX A100マルチGPUサーバーを使用しました。1台あたり199,000ドルで、ネットワーク機器やホスティングコストなども考慮すると、この実験を複製しようとする場合、1億ドル近く費やさなければなりません。それにつけてもフライドポテトはいかがでしょうか? 真剣に考えてみてください。どのようなビジネスケースを持つ組織が、ディープラーニングのインフラストラクチャに1億ドル、さらには1,000万ドルも費やす価値があるのでしょうか?ほとんどありません。では、これらのモデルは実際に誰のために存在するのでしょうか? その暖かい感覚はGPUクラスターです エンジニアリングの素晴らしさにもかかわらず、GPU上でのディープラーニングモデルのトレーニングは力技です。仕様書によると、各DGXサーバーは最大で6.5キロワット消費します。もちろん、データセンター(またはサーバールーム)には少なくとも同じくらいの冷却能力が必要です。あなたがスターク家であり、ウィンターフェルを冬の寒さから守る必要がある場合を除いて、これは別の問題です。 さらに、公衆の意識が気候変動や社会的責任の問題について高まるにつれ、組織は自らの炭素排出量を考慮する必要があります。2019年のマサチューセッツ大学の研究によれば、「GPU上でBERTをトレーニングすることは、アメリカ横断飛行とほぼ同等である」とされています。 BERT-Largeは3億4000万個のパラメータを持っています。Megatron-Turingの環境影響は計り知れません…私を知っている人たちは私を環境保護主義者とは呼ばないでしょうが、いくつかの数字は無視できません。 では? Megatron-Turing NLG 530Bや次に登場するどんなビーストに興奮していますか?いいえ。追加のコスト、複雑さ、環境への影響を考えると、(比較的小さい)ベンチマークの改善がその価値に見合っているとは思いません。これらの巨大モデルの構築と宣伝が組織の機械学習の理解と採用に役立っていると思いますか?いいえ。 私は何のためにこれらを行っているのか疑問に思っています。科学のための科学?昔ながらのマーケティング?技術的な優位性?おそらくそれぞれの要素が少しずつ関与しているでしょう。それらに任せておきましょう。 代わりに、高品質な機械学習ソリューションを構築するために皆さんが利用できる実用的で実行可能な技術に焦点を当てましょう。 事前学習済みモデルを使用する ほとんどの場合、カスタムのモデルアーキテクチャは必要ありません。カスタムのモデル(別のものですが)が必要な場合もありますが、それは専門家向けです。 始める良いポイントは、解決しようとしているタスクに対して事前学習されたモデルを探すことです(例えば、英語のテキストを要約するためのモデルなど)。…

モダンなCPU上でのBERTライクモデルの推論のスケーリングアップ – パート2
イントロダクション:CPU上でのAI効率を最適化するためのIntelソフトウェアの使用 前のブログ記事で詳細に説明したように、Intel Xeon CPUは、AVX512やVNNI(Vector Neural Network Instructions)などのAIワークロードに特に設計された機能を提供しており、整数量子化されたニューラルネットワークを使用した効率的な推論をサポートするための追加のシステムツールも提供しています。このブログ記事では、ソフトウェアの最適化に焦点を当て、Intelの新しいIce Lake世代のXeon CPUのパフォーマンスについて紹介します。私たちの目標は、Intelのハードウェアを最大限に活用するためにソフトウェア側で利用可能なものをすべて紹介することです。前のブログ記事と同様に、ベンチマークの結果とグラフとともに、これらのツールと機能を簡単に使用できるようにします。 4月にIntelは最新のIntel Xeonプロセッサ、コードネームIce Lakeを発売しました。これはより効率的で高性能なAIワークロードをターゲットにしています。具体的には、Ice Lake Xeon CPUは、以前のCascade Lake Xeonプロセッサと比較して、さまざまなNLPタスクで最大75%高速な推論が可能です。これは、新しいSunny Coveアーキテクチャ上での新しい命令やPCIe 4.0のようなハードウェアおよびソフトウェアの改善の組み合わせによって実現されています。最後になりますが、Intelは、IntelのExtension for Scikit Learn、Intel TensorFlow、Intel PyTorch…

KiliとHuggingFace AutoTrainを使用した意見分類
イントロダクション ユーザーのニーズを理解することは、ユーザーに関連するビジネスにおいて重要です。しかし、それには多くの労力と分析が必要であり、非常に高価です。ならば、Machine Learningを活用しませんか?Auto MLを使用することでコーディングを大幅に削減できます。 この記事では、HuggingFace AutoTrainとKiliを活用して、テキスト分類のためのアクティブラーニングパイプラインを構築します。Kiliは、品質の高いトレーニングデータ作成を通じて、データ中心のアプローチを強力にサポートするプラットフォームです。協力的なデータ注釈ツールとAPIを提供し、信頼性のあるデータセット構築とモデルトレーニングの素早い反復を可能にします。アクティブラーニングとは、データセットにラベル付けされたデータを追加し、モデルを反復的に再トレーニングするプロセスです。そのため、終わりのない作業であり、人間がデータにラベルを付ける必要があります。 この記事の具体的なユースケースとして、Google PlayストアのVoAGIのユーザーレビューを使用してパイプラインを構築します。その後、構築したパイプラインでレビューをカテゴリ分類します。最後に、分類されたレビューに感情分析を適用します。その結果を分析することで、ユーザーのニーズと満足度を理解することが容易になります。 HuggingFaceを使用したAutoTrain 自動化されたMachine Learningは、Machine Learningパイプラインの自動化を指す用語です。データクリーニング、モデル選択、ハイパーパラメータの最適化も含まれます。🤗 transformersを使用して自動的にハイパーパラメータの検索を行うことができます。ハイパーパラメータの最適化は困難で時間のかかるプロセスです。 transformersや他の強力なAPIを使用してパイプラインを自分自身で構築することもできますが、AutoTrainを完全に自動化することも可能です。AutoTrainは、transformers、datasets、inference-apiなどの多くの強力なAPIを基に構築されています。 データのクリーニング、モデルの選択、ハイパーパラメータの最適化のステップは、すべてAutoTrainで完全に自動化されています。このフレームワークをフルに活用することで、特定のタスクに対してプロダクションレディのSOTAトランスフォーマーモデルを構築することができます。現在、AutoTrainはバイナリとマルチラベルのテキスト分類、トークン分類、抽出型質問応答、テキスト要約、テキストスコアリングをサポートしています。また、英語、ドイツ語、フランス語、スペイン語、フィンランド語、スウェーデン語、ヒンディー語、オランダ語など、多くの言語もサポートしています。AutoTrainでサポートされていない言語の場合、カスタムモデルとカスタムトークナイザを使用することも可能です。 Kili Kiliは、データ中心のビジネス向けのエンドツーエンドのAIトレーニングプラットフォームです。Kiliは、最適化されたラベリング機能と品質管理ツールを提供し、データを管理するための便利な手段を提供します。画像、ビデオ、テキスト、PDF、音声データを素早く注釈付けできます。GraphQLとPythonの強力なAPIも備えており、データ管理を容易にします。 オンラインまたはオンプレミスで利用可能であり、コンピュータビジョンやNLP、OCRにおいてモダンなMachine Learning技術を実現することができます。テキスト分類、固有表現認識(NER)、関係抽出などのNLP / OCRタスクをサポートしています。また、オブジェクト検出、画像転写、ビデオ分類、セマンティックセグメンテーションなどのコンピュータビジョンタスクもサポートしています。 Kiliは商用ツールですが、Kiliのツールを試すために無料のデベロッパーアカウントを作成することもできます。料金については、価格ページから詳細を確認できます。 プロジェクト モバイルアプリケーションについての洞察を得るために、レビューの分類と感情分析の例を取り上げます。…

ホモモーフィック暗号化による暗号化データの感情分析
感情分析モデルは、テキストがポジティブ、ネガティブ、または中立であるかを判断することが広く知られています。しかし、このプロセスには通常、暗号化されていないテキストへのアクセスが必要であり、プライバシー上の懸念が生じる可能性があります。 ホモモーフィック暗号化は、復号化することなく暗号化されたデータ上で計算を行うことができる暗号化の一種です。これにより、ユーザーの個人情報や潜在的に機密性の高いデータがリスクにさらされるアプリケーションに適しています(例:プライベートメッセージの感情分析)。 このブログ投稿では、Concrete-MLライブラリを使用して、データサイエンティストが暗号化されたデータ上で機械学習モデルを使用することができるようにしています。事前の暗号学の知識は必要ありません。暗号化されたデータ上で感情分析モデルを構築するための実践的なチュートリアルを提供しています。 この投稿では以下の内容をカバーしています: トランスフォーマー トランスフォーマーをXGBoostと組み合わせて感情分析を実行する方法 トレーニング方法 Concrete-MLを使用して予測を暗号化されたデータ上の予測に変換する方法 クライアント/サーバープロトコルを使用してクラウドにデプロイする方法 最後に、この機能を実際に使用するためのHugging Face Spaces上の完全なデモで締めくくります。 環境のセットアップ まず、次のコマンドを実行してpipとsetuptoolsが最新であることを確認します: pip install -U pip setuptools 次に、次のコマンドでこのブログに必要なすべてのライブラリをインストールします。 pip install concrete-ml transformers…

機械学習におけるバイアスについて話しましょう!倫理と社会に関するニュースレター #2
機械学習におけるバイアスは普遍的であり、また複雑です。実際には、単一の技術的介入では問題を意味のある形で解決することはできないほど複雑です。機械学習モデルは社会技術システムであり、その展開コンテキストに依存し、常に進化しながら、不平等や有害なバイアスを悪化させる社会的な傾向を増幅させます。 これは、慎重に機械学習システムを開発するためには警戒心が必要であり、展開コンテキストからのフィードバックに対応することが求められます。これには、コンテキスト間での教訓の共有や、機械学習開発のあらゆるレベルでバイアスの兆候を分析するためのツールの開発などが必要です。 このブログポストでは、Ethics and Societyのメンバーが学んだ教訓と、機械学習におけるバイアスに対処するために開発したツールを共有しています。最初の部分では、バイアスとそのコンテキストについて幅広く考察しています。既に読んでいて、具体的にツールについて戻ってきた場合は、データセットやモデルのセクションに移動してください! 機械学習におけるバイアスに対処するために🤗のチームメンバーが開発したツールの一部を選択 目次: 機械バイアスについて 機械バイアス:機械学習システムからリスクへ バイアスをコンテキストに置く ツールと推奨事項 機械学習開発全体でのバイアスの対処 タスクの定義 データセットのキュレーション モデルのトレーニング 🤗のバイアスツールの概要 機械バイアス:機械学習システムから個人および社会的なリスクへ 機械学習システムは、さまざまなセクターやユースケースで展開されるため、以前に見たことのないスケールで複雑なタスクを自動化することができます。技術が最も効果的に機能する場合、人々と技術システムの間の相互作用をスムーズにし、高度に繰り返しの多い作業の必要性をなくしたり、研究をサポートするための情報処理の新しい方法を開放することができます。 しかし、同じシステムは、特にデータが人間の行動をエンコードする場合、差別的で虐待的な行動を再現する可能性があります。その結果、これらの問題は大幅に悪化する可能性があります。自動化とスケール展開は、次のようなことができます: 時間の経過とともに行動を固定化し、社会的な進歩が技術に反映されるのを妨げる オリジナルのトレーニングデータのコンテキストを超えて有害な行動を広める 予測を行う際にステレオタイプな関連性に過度に焦点を当てて不公平を増幅させる バイアスを「ブラックボックス」システム内に隠すことで救済の可能性を排除する これらのリスクをよりよく理解し対処するために、機械学習の研究者や開発者は、機械バイアスやアルゴリズムのバイアスなど、システムが展開コンテキストでさまざまな人口集団に対して負のステレオタイプや関連性をエンコードする可能性のあるメカニズムを研究し始めています。…
インテルのサファイアラピッズを使用してPyTorch Transformersを高速化する – パート1
約1年前、私たちはHugging Faceのtransformersをクラスターまたは第3世代のIntel Xeon Scalable CPU(別名:Ice Lake)でトレーニングする方法を紹介しました。最近、Intelは第4世代のXeon CPUであるSapphire Rapidsというコードネームの新しいCPUを発売しました。このCPUには、深層学習モデルでよく見られる操作を高速化するエキサイティングな新しい命令があります。 この投稿では、AWS上で実行するSapphire Rapidsサーバーのクラスターを使用して、PyTorchトレーニングジョブの処理を高速化する方法を学びます。ジョブの分散にはIntelのoneAPI Collective Communications Library(CCL)を使用し、新しいCPU命令を自動的に活用するためにIntel Extension for PyTorch(IPEX)ライブラリを使用します。両方のライブラリはすでにHugging Face transformersライブラリと統合されているため、コードの1行も変更せずにサンプルスクリプトをそのまま実行できます。 次の投稿では、Sapphire Rapids CPU上での推論とそれによるパフォーマンス向上について説明します。 CPUでのトレーニングを検討すべき理由 Intel Xeon…

ハギングフェイスにおけるコンピュータビジョンの状況 🤗
弊社の自慢は、コミュニティとともに人工知能の分野を民主化することです。その使命の一環として、私たちは過去1年間でコンピュータビジョンに注力し始めました。🤗 Transformersにビジョントランスフォーマー(ViT)を含めるというPRから始まったこの取り組みは、現在では8つの主要なビジョンタスク、3000以上のモデル、およびHugging Face Hub上の100以上のデータセットに成長しました。 ViTがHubに参加して以来、多くのエキサイティングな出来事がありました。このブログ記事では、コンピュータビジョンの持続的な進歩をサポートするために何が起こったのか、そして今後何がやってくるのかをまとめます。 以下は、カバーする内容のリストです: サポートされているビジョンタスクとパイプライン 独自のビジョンモデルのトレーニング timmとの統合 Diffusers サードパーティーライブラリのサポート デプロイメント その他多数! コミュニティの支援:一つずつのタスクを可能にする 👁 Hugging Face Hubは、次の単語予測、マスクの埋め込み、トークン分類、シーケンス分類など、さまざまなタスクのために10万以上のパブリックモデルを収容しています。現在、我々は8つの主要なビジョンタスクをサポートし、多くのモデルチェックポイントを提供しています: 画像分類 画像セグメンテーション (ゼロショット)オブジェクト検出 ビデオ分類 奥行き推定 画像から画像への合成…

Intel Sapphire Rapidsを使用してPyTorch Transformersを高速化する – パート2
最近の投稿では、第4世代のIntel Xeon CPU(コードネーム:Sapphire Rapids)とその新しいAdvanced Matrix Extensions(AMX)命令セットについて紹介しました。Amazon EC2上で動作するSapphire Rapidsサーバーのクラスタと、Intel Extension for PyTorchなどのIntelライブラリを組み合わせることで、スケールでの効率的な分散トレーニングを実現し、前世代のXeon(Ice Lake)に比べて8倍の高速化とほぼ線形スケーリングを達成する方法を紹介しました。 この投稿では、推論に焦点を当てます。PyTorchで実装された人気のあるHuggingFaceトランスフォーマーと共に、Ice Lakeサーバーでの短いおよび長いNLPトークンシーケンスのパフォーマンスを測定します。そして、Sapphire RapidsサーバーとHugging Face Optimum Intelの最新バージョンを使用して同じことを行います。Hugging Face Optimum Intelは、Intelプラットフォームのハードウェアアクセラレーションに特化したオープンソースのライブラリです。 さあ、始めましょう! CPUベースの推論を検討すべき理由 CPUまたはGPUで深層学習の推論を実行するかどうかを決定する際には、いくつかの要素を考慮する必要があります。最も重要な要素は、モデルのサイズです。一般に、より大きなモデルはGPUによって提供される追加の計算能力からより多くの利益を得ることができますが、より小さいモデルはCPU上で効率的に実行することができます。…

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.