Learn more about Search Results リポジトリ - Page 49

- You may be interested
- ChatGPTと仮想アシスタントの未来 💻
- 「Anthropic Releases Claude 2.1:拡張さ...
- 「ChatGPTのような言語モデルに関するプラ...
- スタビリティAIがアドバーサリアルディフ...
- 「Scikit-Learnによるアンサンブル学習:...
- 「目指すべき人工知能の高収入の仕事6選」
- 「非構造化データ内のデータスライスの検...
- 「Pythonを使用したアンダーサンプリング...
- 高性能意思決定のためのRLHF:戦略と最適化
- 「LoRAを使用してAmazon SageMakerでWhisp...
- 倫理的なAIと責任あるデータサイエンス:...
- 「AIの風景でのデジタル実験とA / Bテスト...
- 記述的な質問に対する戦略的なデータ分析&...
- 言語ドメインにおける画期的かつオープン...
- 清华大学和微软研究人员推出ToRA:用于数...

「開発者向けの15以上のAIツール(2023年9月)」
GitHub Copilot GitHub Copilotは、市場をリードするAIパワードのコーディングアシスタントです。開発者がより効率的に優れたコードを作成するために設計されており、CopilotはOpenAIのCodex言語モデルを基盤に動作しています。このモデルは、自然言語と広範な公開コードデータベースでトレーニングされており、洞察に富んだ提案を行うことができます。コードや関数の完全な行を補完し、コメントの作成やデバッグ、セキュリティチェックの支援など、開発者にとって貴重なツールとなっています。 Amazon CodeWhisperer AmazonのCodeWhispererは、Visual StudioやAWS Cloud9などのさまざまなIDEでリアルタイムのコーディングの推奨を提供する機械学習駆動のコードジェネレータです。大規模なオープンソースのコードデータセットでトレーニングされており、スニペットから完全な関数まで提案し、繰り返しのタスクを自動化し、コードの品質を向上させます。効率とセキュリティを求める開発者にとっての利点です。 Notion AI Notionのワークスペース内で、AIアシスタントのNotionがさまざまな文書作成に関連するタスクをサポートします。創造性、修正、要約など、さまざまなタスクで執筆の速度と品質を向上させます。Notion AIは、ブログやリストからブレストセッションやクリエイティブライティングまで、幅広い執筆タスクを自動化するために使用できるAIシステムです。NotionのAI生成コンテンツは、ドラッグアンドドロップのテキストエディタを使用して簡単に再編成や変換ができます。 Stepsize AI Stepsize AIは、チームの生産性を最適化するために設計されたコラボレーションツールです。プロジェクトの履歴やタスク管理者として機能し、Slack、Jira、GitHubなどのプラットフォームと統合して、更新を効率化し、意思疎通のミスを防ぎます。主な機能には、活動の統一された要約、クエリへの即時回答、堅牢なデータプライバシーコントロールがあります。 Mintlify Mintlifyは、お気に入りのコードエディタで直接コードドキュメントを自動生成する時間を節約するツールです。Mintlify Writerをクリックするだけで、関数のためのよく構造化されたコンテキストに即した説明を作成します。開発者やチームに最適で、複雑な関数のための正確なドキュメントを生成することで、効率と正確さが評価されています。 Pieces for Developers Pieces…
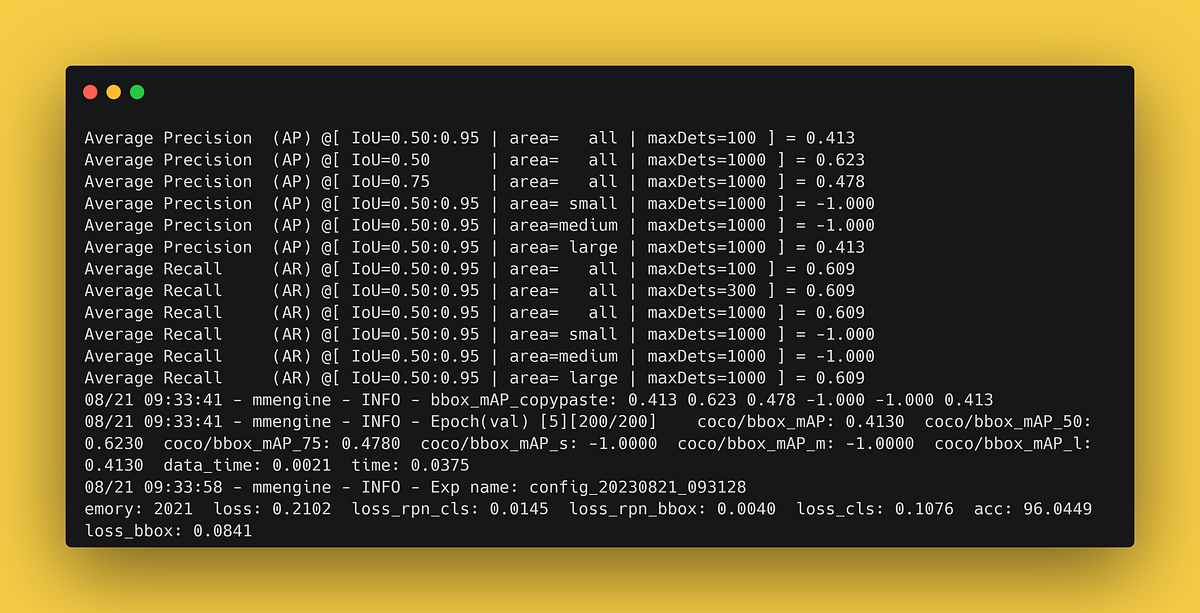
「MMDetectionを使用して物体検出モデルのトレーニング方法を学びましょう」
MMDetection 3を使用してディープラーニングモデルをトレーニングし、CVATで画像にラベルを付け、TensorBoardでトレーニングを監視する方法についてのステップバイステップチュートリアル

Siameseネットワークの導入と実装
イントロダクション シャムネットワークは、たった1つの例に基づいて正確な画像分類を可能にする興味深いアプローチを提供します。これらのネットワークは、データセット内の画像のペアの類似性を測定するためにコントラスティブロスと呼ばれる概念を使用します。画像の内容を解読する従来の方法とは異なり、シャムネットワークは画像間の変動と類似点に集中しています。この独特な学習方法は、限られたデータのシナリオにおいても強さを発揮し、ドメイン固有の知識なしでも性能を向上させます。 この記事では、シャムネットワークのレンズを通して署名の検証の魅力的な領域に深く入り込みます。PyTorchを使用して機能的なモデルを作成する方法について、洞察と実装手順を提供します。 学習目標 シャムネットワークの概念と双子のサブネットワークを含むユニークなアーキテクチャの理解 シャムネットワークで使用されるロス関数(バイナリクロスエントロピー、コントラスティブロス、トリプレットロス)の違いを理解する シャムネットワークが効果的に使用できる実世界のアプリケーション(顔認識、指紋認識、テキストの類似性評価など)を特定し説明する シャムネットワークの1ショット学習、汎用性、ドメインに依存しないパフォーマンスに関する利点と欠点をまとめる この記事はデータサイエンスブログマラソンの一部として公開されました。 シャムネットワークとは何ですか? シャムネットワークは、ワンショット分類のために2つの同じ構造のサブネットワークを使用するネットワークのカテゴリに属しています。これらのサブネットワークは、異なる入力を受け入れながら、同じセットアップ、パラメータ、重みを共有します。シャムネットワークは、複数のクラスを予測するために豊富なデータで訓練される従来のCNNとは異なり、類似性関数を学習します。この関数により、少ないデータを使用してクラスを識別することができるため、ワンショット分類に非常に効果的です。このユニークな能力により、これらのネットワークは多くの場合、1つの例で正確に画像を分類することができます。 シャムネットワークの実世界の応用例として、顔認識や署名の検証のタスクがあります。例えば、会社が自動顔認識に基づいた出席システムを導入するとします。従来のCNNでは、各従業員の1枚の画像しか利用できないため、正確に何千人もの従業員を分類するのは困難です。そこでシャムネットワークが登場し、このようなシナリオで優れた性能を発揮します。 フューショットラーニングの探求 フューショットラーニングでは、モデルは限られた数の例に基づいて予測を行うためのトレーニングを行います。これは、従来のアプローチとは対照的で、トレーニングには大量のラベル付きデータが必要です。フューショットモデルのアーキテクチャは、わずかな数のサンプル間の微妙な違いを活用し、わずかな数やたった1つの例に基づいて予測を行うことができます。シャムネットワーク、メタラーニングなどのさまざまな設計フレームワークが、この機能を可能にします。これらのフレームワークは、モデルが意味のあるデータ表現を抽出し、それを新しい、未知のサンプルに使用することができるようにします。 フューショットラーニングが活躍する実用例には、以下のものがあります: 監視カメラにおける物体検出: フューショットラーニングは、物体の検出において、それらの物体の例がわずかしかない場合でも効果的に識別することができます。わずかなラベル付きの例を使ってモデルをトレーニングした後、それらの物体を新しい映像で検出することができます。 2. 個別のヘルスケア: 個別のヘルスケアでは、医療専門家は患者の医療記録の限られたセットを持っている場合があります。これにはCTスキャンや血液検査の少数の例が含まれます。フューショットラーニングモデルを使用すると、トレーニング用のわずかな例から、患者の将来の健康状態を予測することができます。これには、特定の疾患の発症の予測や特定の治療法への反応の予測などが含まれます。 シャムネットワークのアーキテクチャ Siameseネットワークの設計には、2つの同一のサブネットワークが含まれており、それぞれが入力の1つを処理します。最初に、入力は畳み込みニューラルネットワーク(CNN)を介して処理されます。このCNNは、提供された画像から有意な特徴を抽出します。その後、これらのサブネットワークはエンコードされた出力を生成し、通常は完全に接続された層を介して、入力データの縮約表現を生成します。 CNNは、2つのブランチと共有の特徴抽出コンポーネントで構成される、畳み込み、バッチ正規化、ReLU活性化、最大プーリング、およびドロップアウト層のレイヤーからなります。最後のセグメントでは、抽出された特徴を最終的な分類結果にマッピングするFC層が含まれています。関数は、線形層の後にReLU活性化のシーケンスと連続的な操作(畳み込み、バッチ正規化、ReLU活性化、最大プーリング、およびドロップアウト)の系列が続きます。フォワード関数は、入力をネットワークの両方のブランチに案内します。 差分層は、入力の類似性を特定し、異なるペア間の差を増幅するためにユークリッド距離関数を使用します:…

「PythonとMatplotlibを使用して極座標ヒストグラムを作成する方法」
こんにちは、そしてこのPython + Matplotlibチュートリアルへようこそここでは、上記で見た美しい極座標ヒストグラムの作り方を紹介します極座標ヒストグラムは、値が多すぎる場合に便利です...

ランダムウォークタスクにおける時差0(Temporal-Difference(0))と定数αモンテカルロ法の比較
モンテカルロ(MC)法と時間差分(TD)法は、強化学習の分野での基本的な手法です経験に基づいて予測問題を解決します

RGBビデオから3Dビデオを作成する
「私は常に、私たちがデジタルな思い出を2Dの形式でアーカイブしていることに不満を感じてきました写真やビデオは鮮明さに欠けることはないものの、体験の深さや没入感が欠けているのです…」

「HuggingFace Diffusersにおける拡散モデルの比較と説明」
「画像生成を含む生成型AIへのますます高まる関心を受けて、多くの優れたリソースが利用可能となりつつあります以下でいくつかのハイライトを紹介しますが、私の経験に基づくと...」

「OceanBaseを使用して、ゼロからLangchainの代替を作成する」
「オーシャンベースとAIの統合からモデルのトレーニングやチャットボットの作成まで、興味深い旅を通じてこのトピックを探求します」

「データパイプラインにおけるデータ契約の役割」
データ契約とは何ですか? データ契約は、システム内でデータがどのように構造化され、処理されるべきかを定義する契約またはルールの集まりです。これは組織内の異なる部分やさまざまなソフトウェアコンポーネント間の重要なコミュニケーションツールとして機能します。異なる組織間または単一の会社内での管理や意図したデータの使用を指します。 データ契約の主な目的は、データがシステムの異なるバージョンやコンポーネント間で一貫性があり、互換性があることを保証することです。データ契約には次のものが含まれます – 利用規約: 開発、テスト、または展開などの目的でデータを使用する方法の説明。 サービスレベル契約(SLA): SLAはデータの配信品質を説明し、稼働時間、エラー率、可用性などを含む場合があります。 ビジネス契約が製品の供給業者と消費者間の責任を明示するように、データ契約はデータ製品の品質、利用可能性、信頼性を確立し、保証します。 データ契約に含めるべきメタデータは何ですか? スキーマ: スキーマはデータ処理と分析に関する有用な情報を提供します。データソースは進化し、製造業者はスキーマの変更を検出し、対応できるようにする必要があります。消費者は古いスキーマでデータを処理できる必要があります。 セマンティクス: セマンティクスは各ビジネスドメインのルールを捉えます。これには、ビジネスがライフサイクル内のさまざまなステージに移行する方法、お互いとの関係などが含まれます。スキーマと同様に、セマンティクスも時間の経過とともに進化する場合があります。 サービスレベル契約(SLA): SLAはデータ製品のデータの可用性と新鮮さを指定します。データプラクティショナーが効果的にデータ消費パイプラインを設計するのに役立ちます。SLAには、最大の予想遅延、新しいデータがデータ製品に期待される時期などのコミットメント、平均障害間隔、平均回復時間などのメトリックが含まれます。 データ契約の重要性は何ですか? データ契約の主な利点は、データスキーマの異なるバージョン間での互換性と一貫性を確保する役割です。具体的には、データ契約には以下の利点があります: 互換性の保証: データ契約がデータの構造とルールを定義するため、異なるコンポーネントやシステムバージョンによって生成および消費されるデータが互換性を保つことが保証されます。この予防的なアプローチにより、スキーマの進化中のデータ処理の複雑さが最小限に抑えられます。 一貫性の強制: データ契約はデータ表現の一貫性を強制します。すべての製造業者と消費者が同じスキーマに従うことを求め、データの正確性を促進し、システムの信頼性を高めます。 バージョン管理: データ契約はバージョン管理と追跡が可能です。この機能により、データスキーマへの変更を構造化して管理することができ、スキーマの進化を円滑に進めるために貴重なものとなります。…

「LoRAアダプターにダイブ」
「大規模言語モデル(LLM)は世界中で大流行しています過去の1年間では、彼らができることにおいて莫大な進歩を目撃してきましたそれまではかなり限定的な用途にとどまっていましたが、今では…」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.