Learn more about Search Results NGC - Page 48

- You may be interested
- 「H3とPlotlyを使用してヘキサゴンマップ...
- XGBoost 最終ガイド(パート2)
- CDCデータレプリケーション:技術、トレー...
- Google Cloudを使用してレコメンドシステ...
- Mistral-7B-v0.1をご紹介します:新しい大...
- 機能データの異常検出のための密度カーネ...
- 「ジャスティン・マクギル、Content at Sc...
- トランスフォーマーのA-Z:知っておくべき...
- 強化学習:動的プログラミングとモンテカ...
- このAIの論文は、純粋なゼロショットの設...
- プロンプトの旅:プロンプトエンジニアリ...
- スタンフォードの研究者たちは、DSPyを紹...
- 「PythonとMatplotlibを使用して目を引く...
- 『AIの未来、心の索引化、より良いAIの構築』
- Acme 分散強化学習のための新しいフレーム...
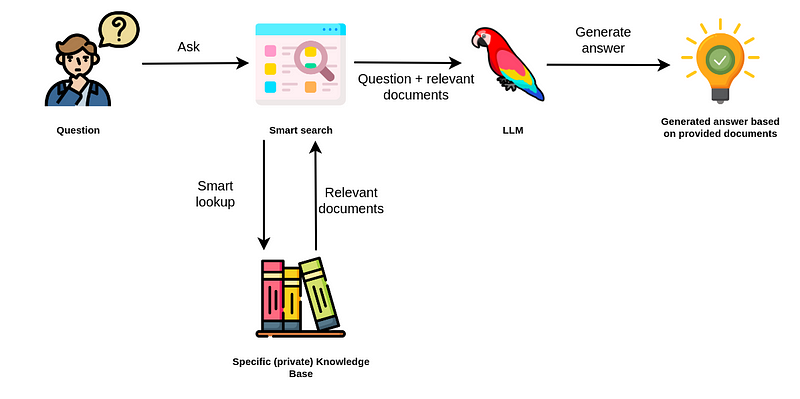
「Neo4jにおける非構造化テキストに対する効率的な意味検索」
ChatGPTが6か月前に登場して以来、技術の風景は変革的な転換を遂げましたChatGPTの優れた一般化能力により、...

Databricks ❤️ Hugging Face 大規模言語モデルのトレーニングとチューニングが最大40%高速化されました
生成AIは世界中で大きな注目を集めています。データとAIの会社として、私たちはオープンソースの大規模言語モデルDollyのリリース、およびそれを微調整するために使用した研究および商用利用のための内部クラウドソーシングデータセットであるdatabricks-dolly-15kのリリースと共にこの旅に参加してきました。モデルとデータセットはHugging Faceで利用可能です。このプロセスを通じて多くのことを学びましたが、今日はApache Spark™のデータフレームから簡単にHugging Faceデータセットを作成できるようにするHugging Faceコードベースへの初めての公式コミットの1つを発表することを喜んでお知らせします。 「Databricksがモデルとデータセットをコミュニティにリリースしてくれたのを見るのは素晴らしいことでしたが、それをHugging Faceへの直接のオープンソースコミットメントにまで拡張しているのを見るのはさらに素晴らしいことです。Sparkは、大規模なデータでの作業に最も効率的なエンジンの1つであり、その技術を使用してHugging Faceのモデルをより効果的に微調整できるようになったユーザーを見るのは素晴らしいことです。」 — Clem Delange、Hugging Face CEO Hugging Faceが一流のSparkサポートを受ける 過去数週間、ユーザーから、SparkのデータフレームをHugging Faceデータセットに簡単にロードする方法を求める多くのリクエストを受け取りました。今日のリリースよりも前は、SparkのデータフレームからHugging Faceデータセットにデータを取得するために、データをParquetファイルに書き込み、それからHugging Faceデータセットをこれらのファイルに指定して再ロードする必要がありました。たとえば: from datasets import load_dataset train_df…

あなたのGen AIプロジェクトで活用するための10のヒントとトリック
現在、実際に利用されている生成型AIアプリケーションはあまり多くはありませんここで言っているのは、それらがエンドユーザーによって展開され、活発に使用されていることを意味します(デモ、POC、および抽出型AIは含まれません)生成型AIは…

「Amazon SageMakerを使用したフェデレーテッドラーニングによる分散トレーニングデータを用いた機械学習」
この投稿では、分散トレーニングデータを使用してAmazon SageMakerでフェデレーテッドラーニングを実装する方法について説明します

「2023年にPrompt Engineeringを使用するであろう5つの仕事」
「OpenAIのChatGPTが登場し、大規模な言語モデルを一般のイメージに広めた以来、これらのAIモデルを十分に活用する能力は、すぐに非常に求められるスキルとなりましたそのような中、企業はAIの全ての潜在能力を引き出すために、迅速なエンジニアリングが必要であることに気付き始めています...」
このAIニュースレターは、あなたが必要とするすべてです#61
「最近の数ヶ月間、私たちは大規模な言語モデル(LLM)の進歩と新しい技術の徐々の導入を続けてきましたが、まだGPT-4を直接的に置き換えることを目指した競争は見られていません…」

「LlaMA 2の始め方 | メタの新しい生成AI」
イントロダクション OpenAIからGPTがリリースされて以来、多くの企業が独自の堅牢な生成型大規模言語モデルを作成するための競争に参入しました。ゼロから生成型AIを作成するには、生成型AIの分野での徹底的な研究と数多くの試行錯誤が必要な場合があります。また、大規模言語モデルの効果は、それらが訓練されるデータに大きく依存するため、高品質なデータセットを注意深く編集する必要があります。さらに、これらのモデルを訓練するためには膨大な計算能力が必要であり、多くの企業がアクセスできない状況です。そのため、現時点では、OpenAIやGoogleを含むわずかな企業しかこれらの大規模言語モデルを作成できません。そして、ついにMetaがLlaMAの導入でこの競争に参加しました。 学習目標 新しいバージョンのLlaMAについて知る モデルのバージョン、パラメータ、モデルのベンチマークを理解する Llama 2ファミリのモデルにアクセスする さまざまなプロンプトでLlaMA 2を試して出力を観察する この記事はData Science Blogathonの一環として公開されました。 Llamaとは何ですか? LlaMA(Large Language Model Meta AI)は、特にMeta AI(元Facebook)が所有する会社であるMeta AIによって開発された基礎となる大規模言語モデルのグループである生成型AIモデルです。Metaは2023年2月にLlamaを発表しました。Metaは、7、13、33、および65兆のパラメータを持つコンテキスト長2kトークンの異なるサイズのLlamaをリリースしました。このモデルは、研究者がAIの分野での知識を進めるのを支援することを目的としています。小型の7Bモデルは、計算能力が低い研究者がこれらのモデルを研究することを可能にします。 LlaMaの導入により、MetaはLLMの領域に参入し、OpenAIのGPTやGoogleのPaLMモデルと競合しています。Metaは、限られた計算リソースで小さなモデルを再トレーニングまたは微調整することで、それぞれの分野で最先端のモデルと同等の結果を達成できると考えています。Meta AIのLlaMaは、LlaMAモデルファミリが完全にオープンソースであり、誰でも無料で使用できるだけでなく、研究者のためにLlaMAの重みを非営利目的で公開しているため、OpenAIやGoogleのLLMとは異なります。 前進 LlaMA…

Together AIがLlama-2-7B-32K-Instructを発表:拡張コンテキスト言語処理の大きな進歩
自然言語処理の広大な領域において、多面的な課題が生じています。それは、複雑で長大な指示を適切に理解し、応答する能力です。コミュニケーションの微妙なニュアンスがより複雑になるにつれて、既存のモデルが広範な文脈の複雑さに対処する際の不足点が露呈してきました。本書では、Together AIの献身的なチームが生み出した非凡な解決策が明らかになります。これは、言語処理の基盤そのものを再構築するという約束を持つソリューションです。このイノベーションは、特に広範な文脈の微妙な把握を必要とするタスクにおいて、重要な意味を持ちます。 現代の自然言語処理技術は、長大な指示の複雑さに取り組むためのツールや手法に頼っています。しかし、研究チームが開発したLlama-2-7B-32K-Instructは、有望な新たな領域に進出しています。Together Inference APIの能力を巧みに活用することで、チームは短い文脈のシナリオでのパフォーマンスを損なうことなく、長い指示の領域で優れたモデルを構築しました。この戦略は、Alpaca、Vicuna、WizardLM、Orcaなどのモデルが取り入れている成功したアプローチと共通しており、強力な言語モデルを活用することで貴重な洞察が得られます。 Llama-2-7B-32K-Instructの成功は、研究チームによって厳格に指示された4つのステップの過程に基づいています。この旅は、モデルの厳密な蒸留から始まります。これは、会話、人間の指示、およびLlama-2-70B-Chatから派生した出力を包括する多様なデータセットの統合です。この幅広いミックスにより、モデルは繊細な指示を理解することができます。研究チームは、Together Inference APIを駆使してLlama-2-70B-Chatとクエリを行い、Llama-2-7B-32K-Instructを微調整しています。 ダイナミックな微調整プロセスの後、モデルは厳格な評価を受けます。要約から複数のドキュメントにわたる質問応答まで、さまざまなタスクのベンチマークとしてのパフォーマンスが測定されます。Llama-2-7B-32K-Instructは、GPT-3.5-Turbo-16K、Llama-2-7b-chat、Longchat-7b-16k、Longchat-7b-v1.5-32kを含む既存のベースラインモデルを常に上回っています。この堅固なパフォーマンスは、モデルが長大な指示を処理し、さまざまなベンチマークで優れた結果を残す能力を裏付けています。 https://together.ai/blog/llama-2-7b-32k-instruct https://together.ai/blog/llama-2-7b-32k-instruct 結論として、Llama-2-7B-32K-Instructの登場は、長大な文脈の言語処理によって引き起こされる複雑さに取り組むための注目すべき進展を示しています。研究チームの正当な手法と革新的なTogether Inference APIの利用は、複雑な指示に対応し、新たなパフォーマンスの基準を確立するモデルに結実しました。Llama-2-7B-32K-Instructは、複雑な文脈を理解し、関連する応答を生成する能力の間隔を埋めることで、自然言語処理の将来の進歩を示す説得力のあるプレビューを提供します。この進歩は、複雑な指示から徹底的な理解と巧妙な応答の生成を要求するアプリケーションに力を与え、未知の領域に向けて分野を推進することができるでしょう。

「LlamaIndex 最新バージョン:Python における基礎から高度なテクニックまで -(パート3)」
このシリーズの第二部では、ドキュメントストア、サービスコンテキスト、LLMプレディクタなどについて話しましたまだ読んでいない場合は、ぜひチェックしてくださいLlamaIndexのLLMクラスは、...を提供します

「ChatGPT APIのカスタムメモリ」
この記事では、OpenAI APIを使用してChatGPTにメモリを与える方法について調査しますこれにより、一般的なLangChainフレームワークを使用して、以前のやり取りを記憶することが可能になります
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.