Learn more about Search Results モード - Page 48

- You may be interested
- 「OpenAIのChatGPT Enterpriseは、セキュ...
- ギガGPTに会ってください:Cerebrasのnano...
- 「EUの新しいAI法案の主なポイント、初の...
- 新興の脅威:言語モデルの時代におけるア...
- パンダのGroupByを最大限に活用する
- 海洋ナビゲーションのためのロボットプラ...
- 「AIガバナンスにおけるステークホルダー...
- 「データ統合とAIによる洞察力」
- ユリーカに会ってください:大規模な言語...
- NLPの探索 – NLPのキックスタート(...
- 「ReactとChatGPT APIを使用して独自のAI...
- 「2030年までに注目すべき7つの先駆的なAI...
- 「効率的な変数選択のための新しいアルゴ...
- ティーンエイジャーのころ、彼女はビデオ...
- 「ChatGPTを再び視覚させる:このAIアプロ...
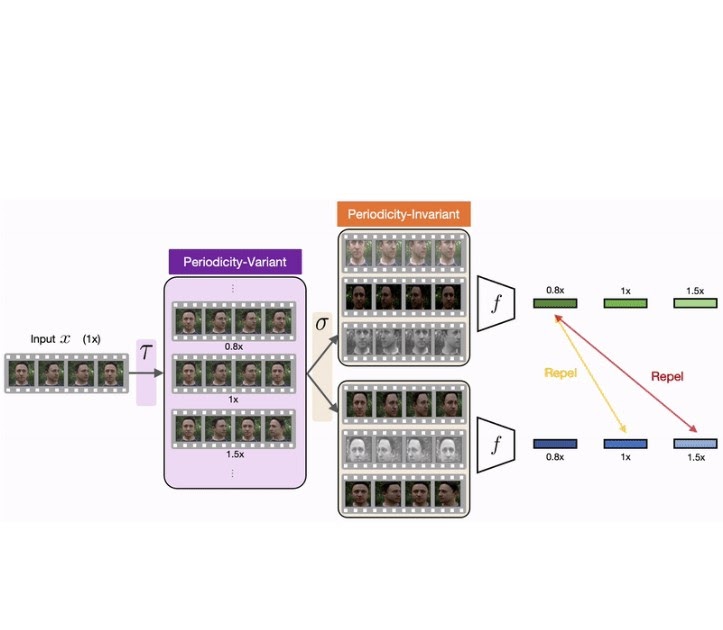
SimPer:周期的なターゲットの簡単な自己教示学習
Googleのスタッフ研究者であるDaniel McDuffと学生研究者のYuzhe Yangによって投稿されました。 周期的なデータ(心拍や地球表面の日々の気温変化など、繰り返される信号)から学ぶことは、天候システムの監視から生体徴候の検出まで、多くの実世界のアプリケーションにとって重要です。例えば、環境遠隔検出の領域では、降水パターンや地表温度などの環境変化のナウキャスティングを可能にするために周期的な学習がしばしば必要です。健康領域では、ビデオ測定から学んだ結果、心房細動や睡眠時無呼吸などの(準)周期的な生体徴候を抽出することが示されています。 RepNetなどのアプローチは、これらのタスクの重要性を強調し、単一のビデオ内で繰り返されるアクティビティを認識する解決策を提供しています。ただし、これらは教師ありのアプローチであり、繰り返されるアクティビティを捉えるために大量のデータと、アクションが繰り返された回数を示すラベルが必要です。このようなデータのラベリングは、しばしば難しくリソースを消費するため、研究者は興味の対象のモダリティ(ビデオや衛星画像など)と同期したゴールドスタンダードの時間的計測を手動でキャプチャする必要があります。 代わりに、自己教師あり学習(SSL)の手法(SimCLRやMoCo v2など)は、周期的または準周期的な時間的ダイナミクスを捉える表現を学習するためにラベルの付いていない大量のデータを活用することで、分類タスクの解決に成功しています。しかし、これらの手法は、データの固有の周期性(つまり、フレームが周期的なプロセスの一部であるかどうかを識別する能力)を見落とし、周期的な属性や周波数属性を捉える堅牢な表現を学習することができません。これは、周期的な学習が一般的な学習タスクとは異なる特性を持つためです。 周期的表現の文脈での特徴の類似性は、静的な特徴(例えば画像)とは異なります。例えば、短い時間遅れでオフセットされたビデオや反転されたビデオは、元のサンプルと類似しているべきです。一方、ビデオのアップサンプリングやダウンサンプリングは、元のサンプルから因子xで異なるはずです。 これらの課題に対処するために、私たちは「SimPer: Simple Self-Supervised Learning of Periodic Targets」という論文で、データ内の周期的な情報を学習するための自己教師ありの対照的なフレームワークを紹介しました。具体的には、SimPerは周期性不変および周期性変動の拡張によって、同じ入力インスタンスから正例と負例のサンプルを取得することで、周期性のあるターゲットの時間的特性を活用します。周期的な特徴の類似性を提案し、周期的な学習の文脈で類似性を測定する方法を明示的に定義します。さらに、古典的なInfoNCE損失をソフト回帰バリアントに拡張した汎用の対照的な損失を設計し、連続したラベル(周波数)を対照することを可能にします。次に、SimPerが最新のSSL手法と比較して効果的に周期的な特徴表現を学習することを示し、データの効率性、誤った相関に対する堅牢性、分布のシフトに対する一般化能力など、その興味深い特性を強調します。最後に、私たちはSimPerのコードリポジトリを研究コミュニティと共有することを楽しみにしています。 SimPerフレームワーク SimPerは、時間的な自己対照的学習フレームワークを導入します。正例と負例のサンプルは、周期性不変および周期性変動の拡張によって同じ入力インスタンスから取得されます。時間的なビデオの例では、周期性不変の変更にはトリミング、回転、反転があり、周期性変動の変更にはビデオの速度の増減が含まれます。 周期的な学習の文脈で類似性を測定する方法を明示的に定義するために、SimPerは周期的な特徴の類似性を提案します。この構成により、トレーニングを対照的な学習タスクとして定式化することができます。モデルはラベルのないデータでトレーニングされ、必要に応じて学習された特徴を特定の周波数値にマッピングするために微調整されることができます。 入力シーケンスxが与えられた場合、関連する周期的な信号が存在することがわかります。そして、xを変換して速度や周波数が変化したサンプルのシリーズを作成し、基になる周期的なターゲットを変更し、異なる負のビューを作成します。元の周波数は不明ですが、ラベルのない入力xに対して擬似的な速度や周波数のラベルを効果的に考案します。 従来の類似性尺度(例:コサイン類似度)は、2つの特徴ベクトル間の厳密な近接性を強調し、インデックスがシフトした特徴(異なるタイムスタンプを表す)、逆転した特徴、および周波数が変化した特徴に対して敏感です。一方、周期的な特徴類似性は、時間的なシフトが小さく、または逆転したインデックスがあるサンプルに対して高くなるべきであり、特徴の周波数が変化する際に連続的な類似性の変化を捉えるべきです。これは、フーリエ変換間の距離など、周波数領域の類似度尺度によって実現できます。 周波数領域で増強されたサンプルの固有の連続性を活用するために、SimPerは一般化された対照的損失を設計します。この損失は、古典的なInfoNCE損失をソフト回帰のバリアントに拡張し、連続的なラベル(周波数)に対して対比を可能にします。これにより、心拍などの連続信号を回復するという回帰タスクに適しています。 SimPerは、周波数領域でデータのネガティブビューを構築することによって、データの変換を行います。入力シーケンスxには、関連する周期的な信号があります。SimPerは、xを変換して速度や周波数が変化したサンプルのシリーズを作成します。これにより、基礎となる周期的なターゲットが変わり、異なるネガティブビューが作成されます。元の周波数は不明ですが、未ラベルの入力xに対して疑似的な速度や周波数ラベル(周期性変数の増強τ)を効果的に設計します。SimPerは、入力の識別を変更しない変換を取り、これらを周期性に関して不変な増強σと定義し、サンプルの異なるポジティブビューを作成します。そして、これらの増強ビューをエンコーダfに送り、対応する特徴を抽出します。 結果 SimPerの性能を評価するために、人間の行動分析、環境リモートセンシング、および医療の共通の実世界タスクに対して、SimPerを最新のSSLスキーム(例:SimCLR、MoCo…
未来への進化-新しいウェーブガイドがデータの転送および操作方法を変えています
物理学者たちは、メタサーフェス上で電磁スピンをエンジニアリングする方法を開拓し、ますますデジタル化する世界のデータストレージと転送のニーズに対応しています

「従業員は職場でChatGPTを望む上司は秘密を漏らすことを心配している」
一部の企業リーダーは、会社や顧客の機密情報が公開されることへの懸念から、生成型人工知能ツールの使用を禁止しています
リアルタイムでデータを理解する
このブログ投稿では、オープンソースのストリーミングソリューションであるbytewaxと、ydata-profilingを組み合わせて活用する方法について説明しますこれにより、ストリーミングフローの品質を向上させることができます

MLCommonsは、臨床効果を提供するためのAIモデルのベンチマークを行うためのオープンソースプラットフォームであるMedPerfを紹介します
AIモデルの有効性を大規模かつ多様な実世界データセットで評価することは、医療AIの臨床翻訳において重要です。MLCommonsというオープンな国際エンジニアリングコミュニティが発表したオープンベンチマーキングプラットフォーム「MedPerf」は、患者のプライバシーを保護し、法的および規制上の懸念を最小限に抑えながら、幅広い実世界医療データでAIモデルを効果的に評価し、臨床的な有効性を提供するために開発されました。 医療AIモデルは、可能な臨床設定の小さなサブセットのデータで訓練された場合、特定の患者集団に対して意図しないバイアスを持つことがあります。一般化能力の欠如により、医療AIは実世界での効果が低いかもしれません。しかし、プライバシー、法的、規制上の考慮事項により、データ所有者はより大規模かつ多様なデータセットへのモデル訓練のアクセスをためらっています。MedPerfは、世界中のデータをAI研究者に便利かつ安全にアクセス可能にすることで、バイアスを排除し、一般化能力と臨床的な影響力を向上させることで、医療AIを強化します。 患者データへのアクセスがない状況下で、MedPerfは医療機関が簡素化された人間監視方式でAIモデルを評価および検証できるようにします。医療AIモデルは、データ供給業者によってリモートでインストールおよびレビューされ、プラットフォームの分散評価によって可能になります。患者情報のプライバシーに関する懸念が軽減され、信頼が強化され、これらすべてが医療関係者間のより良い連携に貢献します。 MedPerfは、同じ共同作業者とともに数多くのAIモデルの評価を時間ではなく数か月で行うことができます。この効果は、最大の連邦実験である脳腫瘍分割(FeTS)チャレンジで示されました。FeTSチャレンジでは、6つの大陸の32のサイトで41の異なるモデルをMedPerfで評価しました。 さらに、学術的な医療研究を反映した一連のパイロット試験によって、MedPerfの有効性が確認されました。これらの試験では、脳腫瘍、膵臓、手術ワークフローの段階などがカバーされました。その結果は、連邦評価ベンチマークが誰もが利用可能なAIを活用した医療ケアに向けた進展に役立つことを確認しています。 MedPerfは、利用性、適応性、パフォーマンスの観点で、fast.aiや他の広く利用されているMLライブラリの普及を促進するために、推奨しています。Microsoft Azure OpenAI Services、Epic Cognitive Computing、HF推論ポイントなどがサポートされるAPI専用およびプライベートAIモデルの一部です。 MedPerfは元々放射線学のために設計されましたが、バイオ医学の任意の分野に適用できる汎用プラットフォームです。MedPerfは、MLパイプラインの構築を簡素化するGaNDLFという姉妹プロジェクトにより、デジタル病理学やオミクスなど、さまざまな活動をサポートできます。データエンジニアリングのギャップを埋め、開発者に最先端の事前学習済みCVおよびNLPモデルへのアクセスを提供するために、MedPerfはPathMLやSlideFlow、Spark NLP、MONAIなどの特殊なローコードライブラリの例を作成しています。 チームは、自分たちの作業が医療AIへの信頼を高め、臨床設定でのMLの普及を加速し、最終的には医療AIが各患者に合わせたケアを提供し、医療費を削減し、医師と患者の生活の質を向上させることを願っています。

「最高のAIプレゼンテーション生成ツール10選」
デジタル時代において、AIによるプレゼンテーション生成ツールは、プレゼンテーションの作成や配信方法に革命をもたらしていますこれらのツールは人工知能を活用して、作成プロセスを効率化し、視覚的な魅力を高め、観客の関与を促進します以下では、次のプレゼンテーションを向上させるのに役立つトップ10のAIプレゼンテーション生成ツールについて詳しく説明します1. Beautiful.ai Beautiful.aiは[…]

「回答付きのトップ50のAIインタビューの質問」
はじめに AIの面接の準備をしており、トップ50のAI面接質問の包括的なリストをお探しですか?それなら、探す必要はありません!このガイドでは、人工知能のさまざまな側面をカバーするさまざまな質問をまとめました。求職者、学生、または単にAIに興味がある方に、これらの質問のコレクションは知識を磨き、AIの面接で成功するのに役立ちます。これらの質問は、初級から上級のトピックまで、AIの理解をテストします。 トップ50のAI面接質問 面接で成功するためのトップ50のAI面接質問のリストです。AIのエキサイティングな世界に飛び込んで、面接の結果を成功させるために自分自身を装備しましょう。 人工知能基礎レベルの面接質問 Q1. 人工知能とは何ですか? 回答:人工知能(AI)は、人間の知能を機械にシミュレートし、問題解決、学習、意思決定など、通常人間の知能を必要とするタスクを実行できるようにすることを指します。 Q2. AIにおけるデータ前処理の重要性を説明してください。 回答:データの前処理はAIにおいて重要であり、生データをクリーニング、変換、整理して、AIアルゴリズムに適した品質の高いデータにすることを含みます。データの前処理により、ノイズを除去し、欠損値を処理し、データを標準化し、次元を削減することができます。これにより、AIモデルの精度と効率が向上します。 Q3. ニューラルネットワークにおける活性化関数の役割は何ですか? 回答:活性化関数は、ニューラルネットワークにおいて重要な役割を果たします。活性化関数は入力の重み付き和を変換し、ニューロンの出力を決定します。活性化関数により、ニューラルネットワークは複雑な関係をモデル化し、非線形性を導入し、学習と収束を促進することができます。 Q4. 教師あり学習、教師なし学習、強化学習を定義してください。 回答:教師あり学習は、入力データが対応する目的の出力やターゲットとペアになったラベル付きの例を使用してモデルを訓練することを指します。教師なし学習は、ラベルのないデータからパターンや構造を見つけることを目的とします。強化学習は、報酬と罰を使ってエージェントを訓練し、環境での行動から学習することを目的とします。 Q5. 機械学習における次元の呪いとは何ですか? 回答:次元の呪いとは、高次元のデータを扱う際の課題を指します。次元の数が増えると、データはますますまばらになり、データ点間の距離は意味をなさなくなります。これにより、分析や正確なモデルの構築が容易になります。 Q6. AIで使用される異なる探索アルゴリズムについて説明してください。 回答:AIで使用される異なる探索アルゴリズムには、深さ優先探索、幅優先探索、一様費用探索、A*探索、ヒューリスティック探索、遺伝的アルゴリズムなどがあります。これらのアルゴリズムは、探索空間を系統的に探索することで、最適または近似最適な解を見つけるのに役立ちます。 Q7.…

GPT-エンジニア:あなたの新しいAIコーディングアシスタント
GPT-Engineerは、プロジェクトの説明からコードベースを生成するAIパワードのアプリケーションビルダーですこれにより、キーバリューデータベースの例を含むアプリケーションの構築が簡素化され、GPT-4ともうまく連携します

「メタのLlama 2の力を明らかにする:創発型AIの飛躍?」
この記事では、Metaが新しくリリースしたLlama 2の技術的な詳細と意義について探求しますLlama 2は、生成型AIの分野を革新すると約束されている大規模言語モデルですその機能、性能、潜在的な応用について詳しく取り上げながら、オープンソースの性質や企業の安全性と透明性への取り組みについても議論します
「オムニスピーチは、次世代のAI音声アルゴリズムにより、自動車、モバイル、消費者、およびIoTの顧客により良いサービスを提供するために、ケイデンス・テンシリカ・オーディオ・ソフトウェア・パートナーとなりました」
「テクノロジーには、最高クラスのAIノイズ抑制とその他のAI音声技術が含まれていますカレッジパーク、MD - OmniSpeechは、任意のアプリ、デバイス、または環境でノイズを除去し、音声品質を向上させるというミッションを持つAI音声技術企業であり、本日、Cadenceの公式Tensilicaオーディオソフトウェアパートナーになったことを発表しました世界的に有名な電気技術者によって設立された... OmniSpeechは、次世代のAI音声アルゴリズムのためのCadence Tensilicaオーディオソフトウェアパートナーとなり、自動車、モバイル、消費者、およびIoTの顧客により良いサービスを提供することを目指しています詳細はこちらをご覧ください」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.