Learn more about Search Results モード - Page 47

- You may be interested
- AIが白人を好むとき
- ChatGPTは自己を規制するための法律を作成...
- 学生アンバサダープログラムの応募受付が...
- 「Gen-AI:楽しさ、恐怖、そして未来!」
- このUCLAのAI研究によると、大規模な言語...
- 新しい – Code-OSS VS Codeオープン...
- 1. データサイエンティストになるべきでな...
- バイナリおよびマルチクラスのターゲット...
- イノベーションを推進するための重要なツ...
- ビジネスにおけるオープンソースと専有モ...
- 「マイクロソフトに韻を踏む事件」
- 言語の愛好家であるなら、ChatGPTの多言語...
- 「Nous-Hermes-Llama2-70bを紹介します:3...
- 「生成的なAIアプリケーションと3D仮想世...
- OpenAIのLLMの支配を覆すことを目指す挑戦...

2023年の機械学習研究におけるトップのデータバージョン管理ツール
生産に使用されるすべてのシステムはバージョン管理する必要があります。ユーザーが最新のデータにアクセスできる単一の場所です。特に多くのユーザーが同時に変更を加えるリソースには監査トレイルを作成する必要があります。 チーム全員が同じページにいることを確保するために、バージョン管理システムが担当しています。それにより、チーム全員が同時に同じプロジェクトで協力し、ファイルの最新バージョンで作業していることが保証されます。適切なツールがあれば、このタスクを迅速に完了することができます! 信頼性のあるデータバージョン管理方法を採用すると、一貫性のあるデータセットとすべての研究の完全なアーカイブを持つことができます。データバージョニングソリューションは、再現性、トレーサビリティ、およびMLモデルの履歴に関心がある場合、ワークフローに必須です。 データセットやモデルのハッシュなどのオブジェクトのコピーを取得し、区別して比較するために使用できるデータバージョンが頻繁にメタデータ管理ソリューションに記録されるようにすると、モデルのトレーニングがバージョン管理され、繰り返し可能になります。 さあ、コードの各コンポーネントを追跡できる最高のデータバージョン管理ツールを調べてみましょう。 Git LFS Git LFSプロジェクトの使用は制限されていません。Gitは、GitHub.comやGitHub Enterpriseなどのリモートサーバーに大きなファイルの内容を保存し、大きなファイルをテキストポインターで置き換えます。音声サンプル、映画、データベース、写真など、置き換えられるファイルの種類には大きなファイルが含まれます。 Gitを使用して大規模なファイルリポジトリを迅速にクローンして取得したり、外部ストレージを使用してGitリポジトリでより多くのファイルをホストしたり、数GBの大きさの大きなファイルをバージョン管理することができます。データの取り扱いにおいては比較的シンプルな解決策です。他のツールキット、ストレージシステム、スクリプトは必要ありません。ダウンロードするデータ量を制限します。これにより、大きなファイルのコピーがリポジトリから取得するよりも速くなります。ポイントはLFSを指し、より軽い素材で作られています。 LakeFS LakeFSは、S3またはGCSにデータを格納するオープンソースのデータバージョニングソリューションであり、Gitに似たブランチングおよびコミット方法をスケーラブルに実装しています。このブランチング方法により、別々のブランチで変更を可能にし、アトミックかつ即座に作成、マージ、およびロールバックできるようにすることで、データレイクをACID準拠にします。 LakeFSを使用すると、繰り返し可能でアトミックなデータレイクの活動を開発することができます。これは新しいものですが、真剣に取り組む必要があります。Gitのようなブランチングとバージョン管理の方法を使用してデータレイクとやり取りし、ペタバイト単位のデータをスケーラブルにチェックできます。 DVC Data Version Controlは、データサイエンスや機械学習のアプリケーションに適したアクセス可能なデータバージョニングソリューションです。このアプリケーションを使用してパイプラインを任意の言語で定義することができます。 DVCは、その名前が示すように、データバージョニングに特化しているわけではありません。このツールは、大きなファイル、データセット、機械学習モデル、コードなどを管理することで、機械学習モデルを共有可能かつ再現可能にします。さらに、チームがパイプラインと機械学習モデルを管理しやすくします。このアプリケーションは、迅速に設定できる簡単なコマンドラインを提供することで、Gitの例にならっています。 最後に、DVCはチームのモデルの再現性と一貫性を向上させるのに役立ちます。コードの複雑なファイルの接尾辞やコメントではなく、Gitのブランチを使用して新しいアイデアをテストします。旅行中にペーパーや鉛筆ではなく、自動的なメトリックトラッキングを使用します。 プッシュ/プルコマンドを使用して機械学習モデル、データ、およびコードの一貫したバンドルを製品環境、リモートマシン、または同僚のデスクトップに転送するためのアドホックなスクリプトではなく使用します。 DeltaLake DeltaLakeというオープンソースのストレージレイヤーにより、データレイクの信頼性が向上します。Delta Lakeは、バッチおよびストリーミングデータ処理をサポートするだけでなく、スケーラブルなメタデータ管理も提供します。現在のデータレイクに基づいており、Apache…

「FathomNetをご紹介します:人工知能と機械学習アルゴリズムを使用して、私たちの海洋とその生物の理解のために視覚データの遅れを処理するためのオープンソースの画像データベース」
海洋は前例のない速さで変化しており、膨大な海洋データを視覚的に監視しながら責任ある管理を維持することは困難です。必要なデータ収集の量と速さは、基準を求める研究コミュニティの能力を超えています。データの一貫性の欠如、不適切なフォーマット、大規模かつラベル付けされたデータセットへの要望は、機械学習の最近の進歩の限定的な成功に寄与しています。これらの進歩により、迅速かつより複雑な視覚データ分析が可能となりました。 この要件を満たすため、いくつかの研究機関がMBARIと協力して、人工知能と機械学習の能力を活用して海洋研究を加速させる取り組みを行いました。このパートナーシップの一つの成果がFathomNetです。FathomNetはオープンソースの画像データベースであり、先進的なデータ処理アルゴリズムを使用して、注意深くキュレーションされたラベル付きデータを標準化および集約します。チームは、人工知能と機械学習の利用こそが海洋の健康に関する重要な研究を加速し、水中映像の処理のボトルネックを解消する唯一の方法だと考えています。この新しい画像データベースの開発プロセスに関する詳細は、Scientific Reports誌の最新の研究論文に記載されています。 機械学習は、過去において視覚解析の分野を変革してきました。その一部には、膨大な数の注釈付きデータがあることが挙げられます。陸地の応用において、機械学習とコンピュータビジョンの研究者が注目するベンチマークデータセットはImageNetとMicrosoft COCOです。研究者に対して豊かで魅力的な基準を提供するために、チームはFathomNetを作成しました。フリーでアクセス可能な、高品質な水中画像トレーニングリソースを確立するために、FathomNetはさまざまなソースからの画像と記録を組み合わせています。 MBARIのビデオラボの研究員は、35年間にわたってMBARIが収集した約28,000時間の深海ビデオと100万枚以上の深海写真を代表するデータを注意深く注釈付けしました。MBARIのビデオライブラリには、動物、生態系、および物体の観察を記録した8,200万以上の注釈があります。国立地理学協会の探検技術ラボは、さまざまな海洋生息地や全ての海洋盆地にまたがる場所から、1,000時間以上のビデオデータを収集しました。これらの記録は、CVision AIが開発したクラウドベースの共同分析プラットフォームで使用され、ハワイ大学とOceansTurnの専門家によって注釈が付けられました。 さらに、2010年に、アメリカ国立海洋大気庁(NOAA)の海洋探査チームは、NOAA船オケアノスエクスプローラー号を使用してデュアルリモート操作機器システムを使ってビデオデータを収集しました。ビデオデータの注釈付けをより詳細に行うために、2015年から専門の分類学者に資金提供しています。最初は、ボランティアの科学者たちを通じて注釈付けをクラウドソーシングしていました。MBARIのデータセットの一部、および国立地理学協会とNOAAの資料がすべてFathomNetに含まれています。 FathomNetはオープンソースであるため、他の機関も容易に貢献し、視覚データの処理と分析において従来の方法よりも時間とリソースを節約することができます。さらに、MBARIはFathomNetのデータを学習した機械学習モデルを使用して、遠隔操作型の水中無人機(ROV)によって撮影されたビデオを分析するためのパイロットイニシアチブを開始しました。AIアルゴリズムの使用により、ラベリングの速度が10倍に向上し、人間の作業量が81%削減されました。FathomNetデータに基づく機械学習アルゴリズムは、海洋の探査と監視を革新する可能性があります。例えば、カメラと高度な機械学習アルゴリズムを搭載したロボット搭載車両を使用して、海洋生物やその他の水中のものを自動的に検索して監視することが挙げられます。 FathomNetには現在84,454枚の画像があり、81の異なるコレクションから175,875箇所のローカリゼーションを反映しています。このデータセットは、さまざまな位置やイメージング設定で200,000以上の動物種に対して1,000以上の独立した観察を取得した後、2億以上の観測を持つ予定です。4年前までは、注釈付きの写真の不足が何千時間もの海洋映像を機械学習で調査することを阻んでいました。FathomNetは、発見を解き放ち、探検家、科学者、一般の人々が海洋研究のペースを加速させるために利用できるツールを可能にすることで、このビジョンを現実化します。 FathomNetは、協力と共同科学が海洋の理解の向上にどのように貢献するかを示す素晴らしい例です。研究者たちは、MBARIと他の共同研究者からのデータを基盤として、データセットが海洋研究の加速に貢献することを期待しています。研究者たちはまた、FathomNetが海洋愛好家や様々なバックグラウンドを持つ探検家が知識と技術を共有するコミュニティとして機能することを強調しています。これは、広範な参加なしに達成できなかった海洋視覚データの問題に取り組むための飛躍台となります。視覚データの処理を高速化し、持続可能で健全な海洋を作り上げるために、FathomNetはコミュニティからのラベル付きデータをさらに含めるために常に改善されています。 この記事はMarktechpostスタッフによる研究概要記事として書かれたものであり、研究論文『FathomNet: 海洋での人工知能を可能にするためのグローバル画像データベース』に基づいています。この研究に関するすべてのクレジットは、このプロジェクトの研究者に帰属します。論文、ツール、参考記事もチェックしてください。また、最新のAI研究ニュース、素敵なAIプロジェクトなどを共有している26k+ ML SubReddit、Discordチャンネル、メールニュースレターにぜひ参加してください。 この投稿は、FathomNetというオープンソースの画像データベースについてです。このデータベースは、人工知能と機械学習アルゴリズムを使用して、私たちの海洋とその生物を理解するために視覚データのバックログを処理するのに役立ちます。 この投稿はMarkTechPostで最初に公開されました。

機械学習の簡素化と標準化のためのトップツール
人工知能と機械学習は、技術の進歩によって世界中のさまざまな分野に恩恵をもたらす革新的なリーダーです。競争力を保つために、どのツールを選ぶかは難しい決断です。 機械学習ツールを選ぶことは、あなたの未来を選ぶことです。人工知能の分野では、すべてが非常に速く進化しているため、「昔の犬、昔の技」を守ることと、「昨日作ったばかり」のバランスを保つことが重要です。 機械学習ツールの数は増え続けており、それに伴い、それらを評価し、最適なものを選ぶ方法を理解する必要があります。 この記事では、いくつかのよく知られた機械学習ツールを紹介します。このレビューでは、MLライブラリ、フレームワーク、プラットフォームについて説明します。 Hermione 最新のオープンソースライブラリであるHermioneは、データサイエンティストがより整理されたスクリプトを簡単かつ迅速に設定できるようにします。また、Hermioneはデータビュー、テキストベクトル化、列の正規化と非正規化など、日常の活動を支援するためのトピックに関するクラスを提供しています。Hermioneを使用する場合、手順に従う必要があります。あとは彼女が魔法のように処理してくれます。 Hydra HydraというオープンソースのPythonフレームワークは、研究やその他の目的のために複雑なアプリを作成することを容易にします。Hydraは、多くの頭を持つヒドラのように多くの関連タスクを管理する能力を指します。主な機能は、階層的な構成を動的に作成し、構成ファイルとコマンドラインを介してそれをオーバーライドする能力です。 もう一つの機能は、動的なコマンドラインのタブ補完です。さまざまなソースから階層的に構成でき、構成はコマンドラインから指定または変更できます。また、単一のコマンドでリモートまたはローカルでプログラムを起動し、さまざまな引数で複数のタスクを実行することもできます。 Koalas Koalasプロジェクトは、巨大なデータ量で作業するデータサイエンティストの生産性を向上させるために、Apache Sparkの上にpandas DataFrame APIを統合しています。 pandasは(シングルノードの)Python DataFrameの事実上の標準実装であり、Sparkは大規模なデータ処理の事実上の標準です。pandasに慣れている場合、このパッケージを使用してすぐにSparkを使用し始め、学習曲線を回避することができます。単一のコードベースはSparkとPandasに互換性があります(テスト、より小さいデータセット)(分散データセット)。 Ludwig Ludwigは、機械学習パイプラインを定義するための明確で柔軟なデータ駆動型の設定アプローチを提供する宣言的な機械学習フレームワークです。Linux Foundation AI & DataがホストするLudwigは、さまざまなAI活動に使用することができます。 入力と出力の特徴と適切なデータ型は設定で宣言されます。ユーザーは、前処理、エンコード、デコードの追加のパラメータを指定したり、事前学習モデルからデータをロードしたり、内部モデルアーキテクチャを構築したり、トレーニングパラメータを調整したり、ハイパーパラメータ最適化を実行したりするための追加のパラメータを指定できます。 Ludwigは、設定の明示的なパラメータを使用してエンドツーエンドの機械学習パイプラインを自動的に作成し、設定されていない設定にはスマートなデフォルト値を使用します。…

「2023年のトップデータウェアハウジングツール」
データウェアハウスは、データの報告、分析、および保存のためのデータ管理システムです。それはエンタープライズデータウェアハウスであり、ビジネスインテリジェンスの一部です。データウェアハウスには、1つ以上の異なるソースからのデータが保存されます。データウェアハウスは中央のリポジトリであり、複数の部門にわたる報告ユーザーが意思決定を支援するために設計された分析ツールです。データウェアハウスは、ビジネスや組織の歴史的なデータを収集し、それを評価して洞察を得ることができます。これにより、組織全体の統一された真実のシステムを構築するのに役立ちます。 クラウドコンピューティング技術のおかげで、ビジネスのためのデータウェアハウジングのコストと難しさは劇的に低下しました。以前は、企業はインフラに多額の投資をしなければなりませんでした。物理的なデータセンターは、クラウドベースのデータウェアハウスとそのツールに取って代わられています。多くの大企業はまだ古いデータウェアハウジングの方法を使用していますが、データウェアハウスが将来機能するのはクラウドであることは明らかです。使用料金ベースのクラウドベースのデータウェアハウジング技術は、迅速で効果的で非常にスケーラブルです。 データウェアハウスの重要性 現代のデータウェアハウジングソリューションは、データウェアハウスアーキテクチャの設計、開発、および導入の繰り返しのタスクを自動化することで、ビジネスの絶えず変化するニーズに対応しています。そのため、多くの企業がデータウェアハウスツールを使用して徹底的な洞察を獲得しています。 以上から、データウェアハウジングが大規模でボイジーサイズの企業にとって重要であることがわかります。データウェアハウスは、チームがデータにアクセスし、情報から結論を導き、さまざまなソースからデータを統合するのを支援します。その結果、企業はデータウェアハウスツールを以下の目標のために使用しています: 運用上および戦略上の問題について学ぶ。 意思決定とサポートのためのシステムを高速化する。 マーケティングイニシアチブの結果を分析し評価する。 従業員のパフォーマンスを分析する。 消費者のトレンドを把握し、次のビジネスサイクルを予測する。 市場で最も人気のあるデータウェアハウスツールは以下の通りです。 Amazon Redshift ビジネス向けのクラウドベースのデータウェアハウジングツールであるRedshiftです。完全に管理されたプラットフォームでペタバイト単位のデータを高速に処理できます。したがって、高速なデータ分析に適しています。さらに、自動の並列スケーリングがサポートされています。この自動化により、クエリ処理のリソースがワークロード要件に合わせて変更されます。オペレーションのオーバーヘッドがないため、同時に数百のクエリを実行できます。Redshiftはまた、クラスタをスケールアップしたりノードタイプを変更したりすることも可能です。その結果、データウェアハウスのパフォーマンスを向上させ、運用費用を節約することができます。 Microsoft Azure MicrosoftのAzure SQL Data Warehouseは、クラウドでホストされる関係データベースです。リアルタイムのレポート作成やペタバイト規模のデータの読み込みと処理に最適化されています。このプラットフォームは、大規模並列処理とノードベースのアーキテクチャ(MPP)を使用しています。このアーキテクチャは、並列処理のためのクエリの最適化に適しています。その結果、ビジネスインサイトの抽出と可視化が大幅に高速化されます。 データウェアハウスには数百のMS Azureリソースが互換性があります。たとえば、プラットフォームの機械学習技術を使用してスマートなアプリを作成することができます。さらに、IoTデバイスやオンプレミスのSQLデータベースなど、さまざまな種類の構造化および非構造化データをフォーラムに保存することができます。 Google BigQuery…
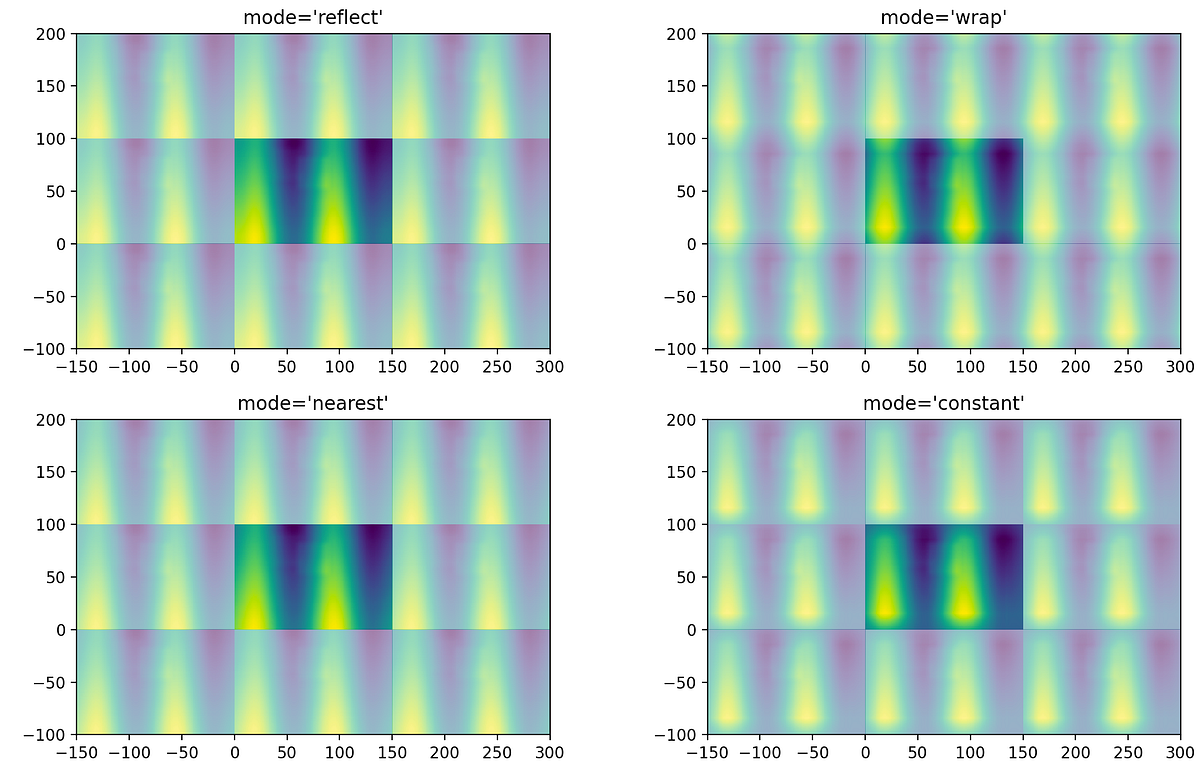
時間シリーズのフーリエ変換:画像畳み込みとSciPyについて
最初の投稿では、フーリエ変換が信号の畳み込みに非常に効率的に使用できる方法について説明しました私は、NumPyを使用したフーリエ変換を用いた畳み込みが桁違いに高速であることを示しました...
「OpenAI(Python)APIを解説する」
「これは、実践において大規模な言語モデル(LLM)を使用するシリーズの2番目の記事ですここでは、OpenAI APIの初心者向けの紹介を行いますこれにより、制約のあるチャットを超えることができます...」
LLMのトレーニングの異なる方法
大規模言語モデル(LLM)の領域では、さまざまなトレーニングメカニズムがあり、異なる手段、要件、目標がありますそれぞれが異なる目的を果たすため、混同しないようにすることが重要です...
「AIスタートアップのトレンド:Y Combinatorの最新バッチからの洞察」
シリコンバレーを拠点とする有名なスタートアップアクセラレータであるY Combinator(YC)は、最近、2023年冬のコホートを発表しました予想通り、269社のうち約31%のスタートアップ(80社)がAIを自己申告しています

「スケールナットのレビュー:最高のAI SEOライティングジェネレーター?(2023年7月)」
「コンテンツ作成を革新する最高のAI SEOライティングジェネレーターを見つけようとしていますか?Scalenutのレビューを読んで、詳細を学びましょう」

「Amazon SageMakerを使用して、効率的にカスタムアンサンブルをトレーニング、チューニング、デプロイする」
「人工知能(AI)は、テクノロジーコミュニティで重要かつ人気のあるトピックとなっていますAIが進化するにつれて、さまざまなタイプの機械学習(ML)モデルが登場してきましたアンサンブルモデリングとして知られるアプローチは、データサイエンティストや実践者の間で急速に注目を集めていますこの記事では、アンサンブルモデルとは何かについて議論します...」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.