Learn more about Search Results link - Page 46

- You may be interested
- マイクロソフトの研究者たちは「エモーシ...
- 「企業がGoogle Cloud AIを利用する7つの...
- 「OceanBaseを使用して、ゼロからLangchai...
- 生成AI 最初のドラフト、最終的なものでは...
- 言語モデルの構築:ステップバイステップ...
- LLaMA 皆のためのLLM!
- PDFとのチャット | PythonとOpenAIによる...
- 説明可能AI(XAI)
- Nyström形式:ニュストローム法による線形...
- シリコンバレー、『シンギュラリティ』が...
- 「人間と機械の間のギャップを埋めるAI時...
- オムニヴォアに会ってください:産業デザ...
- 「WebAgentに会いましょう:DeepMindの新...
- 「3年間の経験から厳選された130の機械学...
- 「最新のゲームをクラウド上で初日からプ...

データストレージの最適化:SQLにおけるデータ型と正規化の探索
SQLにおけるデータ型と正規化の技術について学び、データストレージの最適化に非常に役立ちます
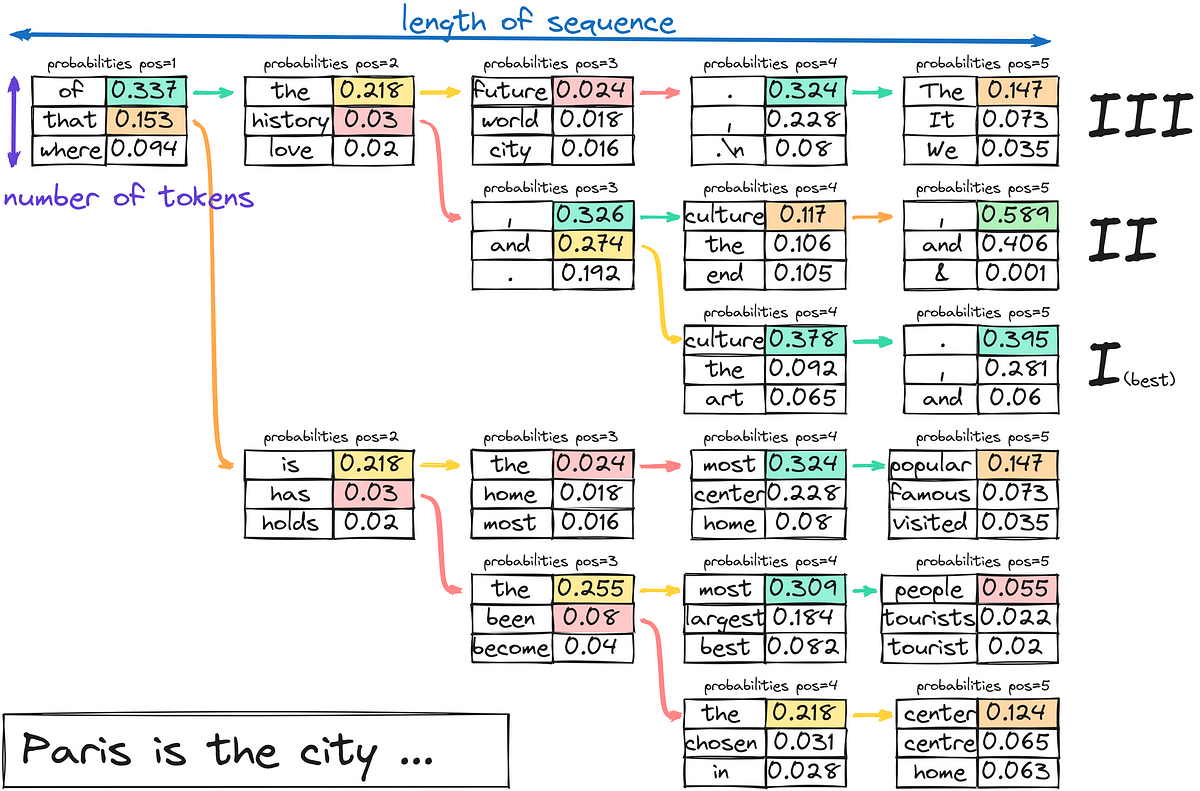
「LLMはどのようにテキストを生成するのか?」
今日は、3つ目のステップに集中します-テキストのデコードと生成最初の2つのステップに興味がある場合は、以下にコメントしてくださいそれらのトピックもカバーすることを検討しますさあ、少し潜りましょう...

「ニューラルネットワークの探索」
AIの力を解き放つ:ニューラルネットワークとその応用のガイド

「チャットモデル対決:GPT-4 vs. GPT-3.5 vs. LLaMA-2によるシミュレートされた討論会-パート1」
最近、MetaがGPT-4と競合するチャットモデルを開発する計画を発表し、AnthropicがClaude2を発売したことにより、どのモデルが最も優れているかについての議論がますます激化しています...
「ゼロからLLMを構築する方法」
「これは、大規模言語モデル(LLM)を実践的に使用するシリーズの6番目の記事です以前の記事では、プロンプトエンジニアリングとファインチューニングを通じて事前学習済みのLLMを活用する方法について詳しく調査しましたこれらに対して…」

「DreamBooth:カスタム画像の安定拡散」
イントロダクション クリエイティビティには限界がない、カスタムイメージのための安定拡散技術の世界へようこそ。AIによる画像生成の領域で、DreamBoothはゲームチェンジャーとして登場し、個々の人々に独自のアイデアに合わせて特別なビジュアルを作り上げる驚異的な能力を与えます。安定拡散は創造的なプロセスに命を吹き込み、普通の画像を非凡な高みに引き上げます。 この探求の中で、私たちはDreamBoothを紹介します。DreamBoothは、安定拡散を通じて普通の画像を非凡な芸術作品に変えるという画期的なプラットフォームです。一緒に、安定拡散の魔法を解き明かし、魅力的な方法で画像を操作・向上させることができるかを発見しましょう。 学習目標: テキストから画像を生成するための安定拡散を学ぶ。 最小限の画像、名前トークンの選択、キャプション付けによるDreamBoothのカスタマイズをマスターする。 実践的な調整、画像の選択、アスペクト比のマッチング、効果的な命名にDreamBoothを応用する。 画像生成における安定拡散の力を理解する 安定拡散は単なる画像生成技術ではありません。それはテキストから画像への変換を実現する画期的な手法です。テキストの記述を入力することで、そのシーンのエッセンスを捉えたリアルなイメージに変換することができます。例えば、「朝の静かな山の湖」というような説明を入力して、その場面を表現したようなイメージが生成されると考えてみてください。 安定拡散は、優れたエッジ保存性を提供することで、信じられないほどの詳細性とリアリズムを持つ画像を作り出すことで、生成型AIの領域で重要な役割を果たしています。これは流体力学に着想を得た手法であり、気体の拡散のような挙動をシミュレートするものです。安定拡散は画像品質においてゲームを変えました。 DreamBoothの微調整プロセスの複雑さ DreamBoothは、安定拡散の力をユーザーの手に握らせ、ユーザーが独自のコンセプトに基づいてカスタム画像を作成できるようにします。DreamBoothの特徴は、通常10から20枚の画像だけでこのカスタマイズを実現できる点です。これによりアクセスしやすく効率的になります。 DreamBoothの核心は、モデルに新しいコンセプトを教えることであり、これは微調整と呼ばれるプロセスを通じて行われます。あなたはあらかじめ存在する安定拡散モデル(赤い図)から始め、あなたのコンセプトを表す一連の画像を提供します。これは、ペットの犬の画像から特定の芸術的スタイルまで何でも構いません。DreamBoothは、指定されたトークン(通常は角括弧内の ‘V’ と表記される)を使用して、モデルにあなたのコンセプトに合った画像を生成するように誘導します。 名前トークンの選択とカスタムコンセプトの生成 微調整の成功には、コンセプトに適した名前トークンの選択が重要です。名前トークンはモデル内でコンセプトを一意に識別するための固有の識別子となります。既存のコンセプトとの衝突を避けるために、モデルが既に知っているコンセプトと関連付けられない名前を選ぶことが重要です。以下はいくつかのガイドラインです: ユニーク性:名前トークンがモデルの知識ベース内の既存のコンセプトと関連付けられる可能性が低いことを確認してください。 長さ:できるだけ長いトークン(5文字以上)を選ぶことが望ましいです。短く一般的なトークンは混乱を招く可能性があります。 テスト:微調整の前に、選んだトークンをベースモデルでテストし、どのような画像が生成されるかを確認します。これにより、モデルがトークンをどのように解釈しているかを理解することができます。 母音の除去:トークン名から母音を除去することを検討してください。これにより、既存のコンセプトとの衝突の可能性が低くなります。 DreamBoothの実践的な体験:カスタム画像の微調整 基礎の理解ができたところで、DreamBoothの動作の実践的なデモに入りましょう。カスタム画像のセットを使用して安定拡散モデルを微調整し、見事な個人向けビジュアルコンテンツを作成します。あなたが自分の作品にスタイルを注入したいアーティストであるか、安定拡散の潜在能力を探求したい趣味のある人であるかに関わらず、この実践的な体験はあなたにDreamBoothの真の可能性を開放します。 画像の選択と準備…

大規模言語モデルの応用の最先端テクニック
イントロダクション 大規模言語モデル(LLM)は、人工知能の絶えず進化する風景において、注目すべきイノベーションの柱です。GPT-3のようなこれらのモデルは、印象的な自然言語処理およびコンテンツ生成の能力を示しています。しかし、それらのフルポテンシャルを活かすには、その複雑な仕組みを理解し、ファインチューニングなどの効果的な技術を用いてパフォーマンスを最適化する必要があります。 私はLLMの研究の奥深さに踏み込むことが好きなデータサイエンティストとして、これらのモデルが輝くためのトリックや戦略を解明するための旅に出ました。この記事では、LLMのための高品質データの作成、効果的なモデルの構築、および現実世界のアプリケーションでの効果を最大化するためのいくつかの重要な側面を紹介します。 学習目標: 基礎モデルから専門エージェントまでのLLMの使用における段階的なアプローチを理解する。 安全性、強化学習、およびデータベースとのLLMの接続について学ぶ。 「LIMA」、「Distil」、および質問応答技術による一貫した応答の探求。 「phi-1」などのモデルを用いた高度なファインチューニングの理解とその利点。 スケーリング則、バイアス低減、およびモデルの傾向に対処する方法について学ぶ。 効果的なLLMの構築:アプローチと技術 LLMの領域に没入する際には、その適用の段階を認識することが重要です。これらの段階は、私にとって知識のピラミッドを形成し、各層が前の層に基づいて構築されています。基礎モデルは基盤です。それは次の単語を予測することに優れたモデルであり、スマートフォンの予測キーボードと同様です。 魔法は、その基礎モデルをタスクに関連するデータを用いてファインチューニングすることで起こります。ここでチャットモデルが登場します。チャットの会話や教示的な例でモデルをトレーニングすることで、チャットボットのような振る舞いを示すように誘導することができます。これは、さまざまなアプリケーションにおける強力なツールです。 インターネットはかなり乱暴な場所であるため、安全性は非常に重要です。次のステップは、人間のフィードバックからの強化学習(RLHF)です。この段階では、モデルの振る舞いを人間の価値観に合わせ、不適切な応答や不正確な応答を防止します。 ピラミッドをさらに上に進むと、アプリケーション層に達します。ここでは、LLMがデータベースと接続して、有益な情報を提供し、質問に答えたり、コード生成やテキスト要約などのタスクを実行したりすることができます。 最後に、ピラミッドの頂点は、独自にタスクを実行できるエージェントの作成に関わります。これらのエージェントは、ファイナンスや医学などの特定のドメインで優れた性能を発揮する特殊なLLMと考えることができます。 データ品質の向上とファインチューニング データ品質はLLMの効果において重要な役割を果たします。データを持つことだけでなく、正しいデータを持つことが重要です。たとえば、「LIMA」のアプローチでは、注意深く選ばれた小さなセットの例が大きなモデルよりも優れることが示されています。したがって、焦点は量から品質へと移ります。 「Distil」テクニックは、別の興味深いアプローチを提供しています。ファインチューニング中に回答に根拠を加えることで、モデルに「何」を教えるかと「なぜ」を教えることができます。これにより、より堅牢で一貫性のある応答が得られることがしばしばあります。 Metaの創造的なアプローチである回答から質問のペアを作成する手法も注目に値します。既存のソリューションに基づいて質問を形成するためにLLMを活用することで、より多様で効果的なトレーニングデータセットが作成できます。 LLMを使用したPDFからの質問ペアの作成 特に魅力的な手法の1つは、回答から質問を生成することです。これは一見矛盾する概念ですが、知識の逆破壊とも言える手法です。テキストがあり、それから質問を抽出したいと想像してみてください。これがLLMの得意分野です。 たとえば、LLM Data Studioのようなツールを使用すると、PDFをアップロードすると、ツールが内容に基づいて関連する質問を出力します。このような手法を用いることで、特定のタスクを実行するために必要な知識を持ったLLMを効率的に作成することができます。…

「オムニバースへ:Blender 4.0 アルファリリースが新しいOpenUSDアートの時代の幕開けを切る」
編集者の注:この記事は「Into the Omniverse」というシリーズの一部であり、アーティスト、開発者、エンタープライズが最新のOpenUSDとNVIDIA Omniverseの進歩を活用してワークフローを変革する方法に焦点を当てています。 経験豊富な3Dアーティストやデジタルクリエーション愛好家にとって、人気のある3DソフトウェアBlenderのアルファ版がクリエイティブな旅を高めています。 アップデートの機能には、複雑なシェーダーネットワークの作成や強化されたアセットエクスポート機能が含まれており、BlenderとUniversal Scene Descriptionフレームワーク(OpenUSD)を使用する開発コミュニティは、3Dの風景を進化させるのに役立っています。 NVIDIAのエンジニアは、BlenderのOpenUSDの機能を向上させるために重要な役割を果たしており、これによりNVIDIA Omniverseとの使用向上ももたらされています。NVIDIA Omniverseは、OpenUSDベースのツールやアプリケーションを接続して構築するための開発プラットフォームです。 Blenderワークフローのためのユニバーサルアップグレード Blender 4.0アルファでは、さまざまなユースケースに最適化されたOpenUSDワークフローにアクセスできるようになります。 たとえば、ミュンヘンのBMWグループテクノロジーオフィスのデザインインターンであるエミリー・ボーマーは、Omniverse、Blender、Adobe Substance 3D Painterの組み合わせのパワーを活用して、コンピュータビジョンAIモデルのトレーニングに使用するリアルなOpenUSDベースのアセットを作成しています。 ボーマーは、BMWグループが公開したAIデータセットであるSORDI.aiで使用するアセットを作成するために、チームと協力しました。このデータセットには80万枚以上の写真写実的な画像が含まれています。 工業用の木箱が仮想的に「経年変化」しているクリップ。 USDはボーマーのワークフローを最適化しました。「BlenderとSubstance 3D Painterの両方でUSDサポートが見られるのは素晴らしいことです」と彼女は言います。「USDを使用して3Dアセットを作成する際、それらが配置されるシーンで予想どおりの見た目と挙動をすることを確信できます。なぜなら、物理的な特性を追加できるからです。」 オーストラリアのアニメーター、マルコ・マトセヴィッチも、Blender、Omniverse、USDの組み合わせたパワーを3Dのワークフローで活用しています。…
時系列のための生成AI
タイムシリーズデータ — 交通データ、株価、天気やエネルギーの測定値、医療信号 — は基本的には時間の経過とともに連続的に生成されるデータですこの時間の依存性は新たな要素をもたらします...

「初心者におすすめの副業5選(無料のコースとAIツールで始める)」
「ここには、$0から始められる5つの実証済みの副業アイデアがありますこれらの無料コースとAIツールを活用して、成功を加速させましょう」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.