Learn more about Search Results Yi - Page 46

- You may be interested
- 機械学習によるストレス検出の洞察を開示
- Apple SiliconでのCore MLを使用した安定...
- 生成AIにおけるタスクの概念:知能システ...
- AIモデルの知覚を測定する
- 時間シリーズのフーリエ変換:画像畳み込...
- 『プロンプトブリーダーの内部:Google De...
- 「複雑なエンジニアリング図面のためのOCR...
- Google Pub/SubからBigQueryへの簡単な方法
- 「勝つための機械学習の履歴書の作り方」
- 「IntelのOpenVINOツールキットを使用した...
- 「Text2Cinemagraphによるダイナミックな...
- バーチワークス2023データサイエンス&AI...
- 「IID 初心者のための意味と解釈」
- 「強化学習の実践者ガイド」
- 「大規模言語モデルを改善するための簡単...

「UCサンディエゴのコンピュータサイエンティストが、毎年15億台の廃棄されたスマートフォンの問題に取り組む」
カリフォルニア大学サンディエゴ校のコンピュータ科学者は、無効化されたスマートフォンを再利用する方法を提案しました
SQLにおける共通テーブル式の包括的なガイド
プログラミングでは、指示や文を小さな、より管理しやすいコードブロックにグループ化することが一般的な手法ですこの手法は通常、コードブロックの組織化と呼ばれています基本的には...
データサイエンスプロジェクトを効果的に構造化する方法
「以前は、顧客がさまざまな回帰および分類タスクに取り組むために、類似モデルや推薦システム、NLP問題、予測など様々なデータサイエンスプロジェクトに従事していました」
「クラスターに SLURM ジョブを送信する方法」
「データサイエンスのスキルを向上させ、強力なGPUクラスターを使用する準備はできていますか?この記事はその完璧な導入です🚀」

「Amazon SageMaker Data WranglerでAWS Lake Formationを使用して細粒度のデータアクセス制御を適用する」
「SageMaker Data Wranglerは、Amazon EMRと組み合わせてLake Formationを利用できるようになり、この細かいデータアクセス制限を提供することをお知らせできることを嬉しく思います」
「データエンジニアリングの役割に疲れましたか?」
数年前、私は自分のキャリアに満足していないと感じる時期にいました私はデータエンジニアリングの仕事を3年間しており、テクノロジーの世界でのスタートの興奮も初めの頃には…

「ジャムのマッピング:グラフ理論を用いた交通分析」
「グラフ理論は、社会ネットワーク、分子生物学、地理空間データなどの現実の問題に多くの応用があります今日は、最後のものとして、都市の道路配置を分析して予測することを紹介します...」
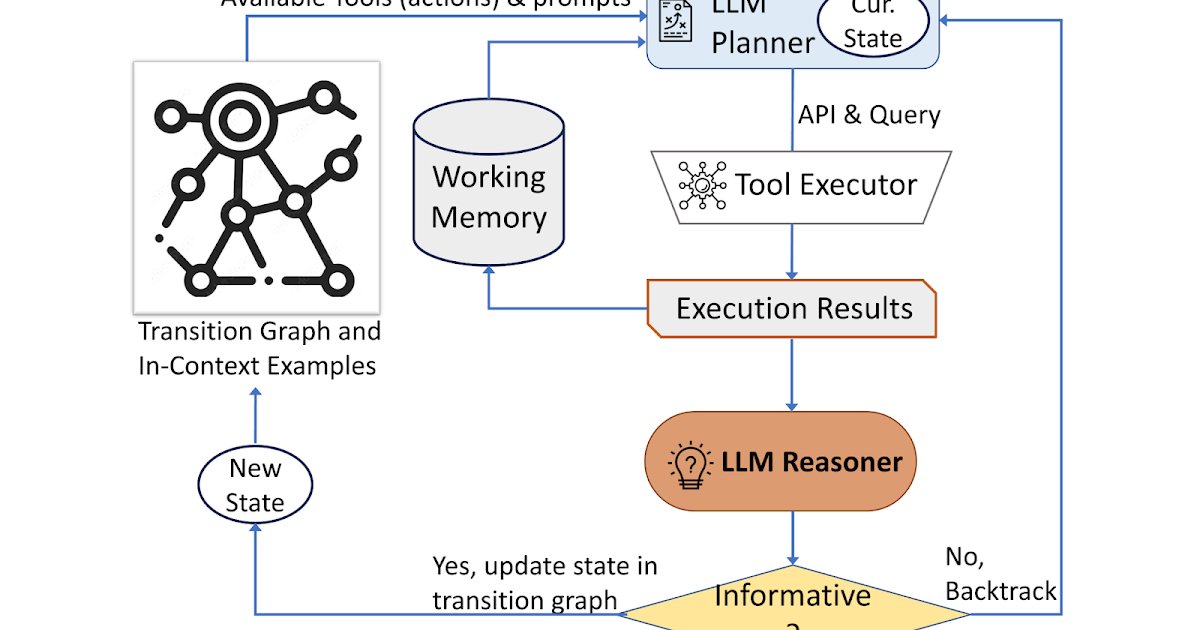
大規模な言語モデルを使用した自律型の視覚情報検索
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team 大規模言語モデル(LLM)を多様な入力に適応させるための進展があり、画像キャプショニング、ビジュアルな質問応答(VQA)、オープンボキャブラリ認識などのタスクにおいても進展が見られています。しかし、現在の最先端のビジュアル言語モデル(VLM)は、InfoseekやOK-VQAなどのビジュアル情報検索データセットにおいて、外部の知識が必要な質問に対して十分な性能を発揮できません。 外部の知識が必要なビジュアル情報検索のクエリの例。画像はOK-VQAデータセットから取得されています。 「AVIS:大規模言語モデルによる自律型ビジュアル情報検索」という論文では、ビジュアル情報検索タスクにおいて最先端の結果を達成する新しい手法を紹介しています。この手法は、LLMと3種類のツールを統合しています:(i)画像からビジュアル情報を抽出するためのコンピュータビジョンツール、(ii)オープンワールドの知識と事実を検索するためのWeb検索ツール、および(iii)視覚的に類似した画像に関連するメタデータから関連情報を得るための画像検索ツール。AVISは、LLMパワードのプランナーを使用して各ステップでツールとクエリを選択します。また、LLMパワードの推論エンジンを使用してツールの出力を分析し、重要な情報を抽出します。ワーキングメモリコンポーネントはプロセス全体で情報を保持します。 難しいビジュアル情報検索の質問に回答するためのAVISの生成されたワークフローの例。入力画像はInfoseekデータセットから取得されています。 以前の研究との比較 最近の研究(例:Chameleon、ViperGPT、MM-ReAct)では、LLMにツールを追加して多様な入力を扱うことを試みています。これらのシステムは2つのステージのプロセスに従います:プランニング(質問を構造化プログラムや命令に分解する)および実行(情報を収集するためにツールを使用する)。基本的なタスクでは成功していますが、このアプローチは複雑な実世界のシナリオではしばしば失敗します。 また、LLMを自律エージェントとして適用することに関心が高まっています(例:WebGPT、ReAct)。これらのエージェントは環境と対話し、リアルタイムのフィードバックに基づいて適応し、目標を達成します。ただし、これらの方法では各ステージで呼び出すことができるツールに制限がなく、膨大な検索空間が生じます。その結果、現在の最先端のLLMでも無限ループに陥ったり、エラーを伝播させることがあります。AVISは、ユーザースタディからの人間の意思決定に影響を受けたガイド付きLLMの使用によってこれを解決します。 ユーザースタディによるLLMの意思決定への情報提供 InfoseekやOK-VQAなどのデータセットに含まれる多くのビジュアルな質問は、人間にとっても難しい課題であり、さまざまなツールやAPIの支援が必要とされます。以下にOK-VQAデータセットの例の質問を示します。私たちは外部ツールの使用時の人間の意思決定を理解するためにユーザースタディを実施しました。…

「ビデオ編集はもはや難問ではありません:INVEはインタラクティブなニューラルビデオ編集を可能にするAI手法です」
イメージ編集なしのインターネットを想像することができますか? すべての面白いミーム、素敵なインスタグラムの写真、魅力的な風景などがなくなってしまうでしょう。それは楽しいインターネットではないですよね? デジタルカメラの初期から、イメージ編集は多くの人々の情熱でした。最初は簡単な編集ができるツールがありましたが、今ではほとんど努力をせずに画像の中の何でも何にでも変えることができます。特に最近の数年間で、強力なAIの手法のおかげで、イメージ編集ツールは驚くほど進化しました。 しかし、ビデオ編集に関しては、遅れています。ビデオ編集はしばしば専門知識と洗練されたソフトウェアが必要なものです。PremierやFinalCut Proなどの複雑なツールに入り込んで、細部を自分で調整しようとする必要があります。今ではビデオ編集は高給のスキルとなっていますから、それも無理はありません。一方、イメージ編集はモバイルアプリでも可能であり、結果は一般ユーザーに十分です。 インタラクティブなビデオ編集が、イメージ編集と同じくらい使いやすくなれば、どんな可能性があるでしょうか。技術的な複雑さとはおさらばし、全く新しい自由のレベルにこんにちはと言えるようになることを想像してみてください!それがINVEです。 INVE (インタラクティブニューラルビデオエディタ)は、その名前が示すとおり、ビデオ編集の問題に取り組むAIモデルです。非専門のユーザーが複雑なビデオ編集を簡単に行える方法を提案しています。 INVE の主な目標は、ユーザーがビデオに対して複雑な編集を簡単かつ直感的な方法で行えるようにすることです。このアプローチは、レイヤー化されたニューラルアトラス表現に基づいています。この表現には、ビデオ内の各オブジェクトと背景のための2Dアトラス(画像)が含まれています。これらのアトラスにより、局所的かつ一貫した編集が可能となります。 ビデオ編集はいくつかの固有の課題により手間がかかります。たとえば、ビデオ内の異なるオブジェクトは独立して移動するため、不自然なアーティファクトを避けるために正確なローカリゼーションと注意深い構成が必要です。さらに、個々のフレームの編集は不一致や目に見える欠陥を引き起こす可能性があります。これらの問題に対処するために、INVE はレイヤー化されたニューラルアトラス表現を使用した新しいアプローチを導入しています。 アイデアは、ビデオを動くオブジェクトごとに1つ、背景用にもう1つの2Dアトラスのセットとして表現することです。この表現により、ビデオ全体で一貫性を保ちながら局所的な編集が可能となります。ただし、以前の手法では双方向のマッピングに問題があり、特定の編集の結果を予測することが困難でした。さらに、計算量の複雑さがリアルタイムのインタラクティブな編集を妨げました。 INVEは1つのフレームで編集を一貫して伝播させることができます。 出典:https://arxiv.org/pdf/2307.07663.pdf INVE は、アトラスとビデオイメージの間の双方向のマッピングを学習します。これにより、ユーザーはアトラスまたはビデオ自体のどちらでも編集を行うことができ、より多くの編集オプションがあり、最終的なビデオでどのように編集が認識されるかをより良く理解することができます。 さらに、INVE はマルチ解像度ハッシュコーディングを採用しており、学習と推論の速度が大幅に向上しています。これにより、ユーザーは本当にインタラクティブな編集体験を楽しむことができます。 INVEの順方向マッピングパイプラインの概要。 出典:https://arxiv.org/pdf/2307.07663.pdf INVEは、剛体テクスチャトラッキングやベクトル化されたスケッチなど、豊富な編集操作を提供しています。これにより、ユーザーは自分の編集ビジョンを努力せずに実現することができます。初心者のユーザーでも、技術的な複雑さに苦しまずに、インタラクティブなビデオ編集の力を活用することができます。これにより、動く車に外部グラフィックスを追加したり、背景の森の色合いを調整したり、道路にスケッチしたりするなどのビデオ編集が容易になります。これらの編集は、ビデオ全体に簡単に伝播します。

情報とエントロピー
1948年、数学者のクロード・E・シャノンが「通信の数学的理論」という記事を発表し、機械学習における重要な概念であるエントロピーを紹介しましたエントロピーとは…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.