Learn more about Search Results Yi - Page 45

- You may be interested
- データサイエンティストのためのGitの深い...
- 「環境持続可能性のために生成型AIのワー...
- 「ジェネラティブAI:2024年の人事におけ...
- 「RAVENに会ってください:ATLASの制限に...
- 「Amazon SageMakerを使用してビジョント...
- HuggingFaceはTextEnvironmentsを紹介しま...
- 新しいAIチューターに会ってください!
- アップル M2 Max GPU vs Nvidia V100、P10...
- 機能データの異常検出のための密度カーネ...
- 高度なチュートリアル:Matplotlibを絶対...
- 「SQLで移動平均と累積合計をマスターする...
- 「AWS Inferentia2を使って、あなたのラマ...
- より小さい相手による言語モデルからの知...
- 「PythonのPandasライブラリを使用した非...
- AIを使って若返る方法:新しい抗加齢薬が...

このAI論文は、「MATLABER:マテリアルを意識したテキストから3D生成のための新しい潜在的BRDFオートエンコーダ」を提案しています
3Dアセットの開発は、ゲーム、映画、AR/VRなど、多くの商業応用において不可欠です。従来の3Dアセット開発プロセスでは、多くの労力と時間を要する作業が必要であり、それらはすべて専門的な知識と形式美的なトレーニングに依存しています。最近の生成品質と効率の向上、および従来の3Dアセット作成に必要な時間とスキル要件を大幅に削減する潜在能力により、純粋なテキスト記述から自動的に3Dアセットを生成するテキストから3Dへのパイプラインへの注目が高まっています。 これらのテキストから3Dへのパイプラインは、NeRFまたはDMTETで表現されたターゲット3DアセットをSDS損失を介して逐次最適化することにより、魅力的なジオメトリと外観を提供することができます。図1は、彼らが高忠実度のオブジェクト素材を復元するのがいかに困難であるかを示しており、これがリライティングなどの現実世界のアプリケーションでの使用を制限しています。彼らのデザインには双方向反射率分布関数(BRDF)とランベルト反射率をモデル化しようとする試みがなされていますが、素材を予測するニューラルネットワークは、自然な分布に準拠する適切な素材を識別するために必要なモチベーションと手がかりを欠いています。特に、環境ライトと頻繁に絡み合うことが多い固定ライト条件下で、彼らの示した素材が環境ライトと混同してしまうことがあります。 本研究では、上海AI研究所とS-Lab、南洋理工大学の研究者が、既に利用可能な豊富な素材データを使用して、素材を環境ライティングから正確に分離する独自のテキストから3Dへのパイプラインを学習することに成功しました。MERL BRDF、Adobe Substance3D素材、実世界のBRDFコレクションTwoShotBRDFなど、大規模なBRDF素材データセットがありますが、素材とテキストの記述の結合データセットへのアクセスのなさにもかかわらず、彼らはテキストプロンプトに正確に対応するリアルで自然な見た目の素材を作成するために、全く新しい潜在的BRDFオートエンコーダを使用したマテリアルアウェアテキストから3Dへのエンコーダ(MATLABER)を提案しています。 BRDFの値ではなくBRDFの潜在コードを予測するために、潜在的BRDFオートエンコーダは、そのスムーズな潜在空間にTwoShotBRDFの実世界のBRDF事前知識を組み込むように訓練されます。これにより、MATLABERは最も適切な素材の選択に集中し、予測されたBRDFの妥当性にあまり心配する必要がありません。彼らの手法は、BRDFオートエンコーダのスムーズな潜在空間により、オブジェクトのジオメトリと外観の最適な分離を実現し、高忠実度のコンテンツを持つ3Dアセットを生成することができます。図1に示すように、これは従来の最先端のテキストから3Dへのパイプラインを超えるものです。 図1: テキストから3Dへの生成の目標は、提供されたテキストの記述に対応する高品質な3Dオブジェクトを作成することです。DreamFusionやFantasia3Dなどの代表的な技術は、見栄えはするものの、高忠実度のオブジェクト素材を復元するのには依然として十分ではありません。具体的には、Fantasia3Dは環境ライティングと絡み合ったBRDF素材を予測し、DreamFusionは拡散反射素材のみを考慮しています。潜在的BRDFオートエンコーダに基づくこの手法は、3Dオブジェクト用の有機的な素材を生成し、さまざまな照明条件でのリアルなレンダリングを可能にします。 さらに重要なことに、オブジェクト素材の正確な推定により、以前は困難だったシーンの修正、素材の編集、リライティングなどの活動が可能になります。これらのダウンストリームのタスクが重要であると認識するいくつかの現実世界のアプリケーションによって、より実用的な3Dコンテンツ生成のパラダイムに道が開かれています。さらに、彼らのアルゴリズムは、ObjectFolderなどのマルチモーダルデータセットを使用して、取得した素材から触覚情報や音響情報を推測することができます。これらの情報は、仮想物体の素材の三位一体を構成します。

「ノイズのある量子プロセッサをクラシカルコンピュータと比較する方法」
Google Quantum AIチームの主任研究員であるセルヒオ・ボイショとヴァディム・スメリャンスキーによる投稿 完全なスケールのエラー訂正量子コンピュータは、古典コンピュータでは不可能な問題を解決することができますが、そのようなデバイスを構築することは非常に困難です。私たちは完全にエラー訂正された量子コンピュータに向けて達成したマイルストーンに誇りを持っていますが、大規模なコンピュータはまだ数年先です。一方、私たちは現在のノイズのある量子プロセッサを柔軟なプラットフォームとして量子実験に活用しています。 エラー訂正された量子コンピュータとは異なり、ノイズのある量子プロセッサでの実験は、ノイズが量子状態を劣化させる前に数千回の量子操作またはゲートに制限されています。2019年に、私たちはランダム回路サンプリングという特定の計算タスクを量子プロセッサで実装し、それが最先端の古典超並列計算を上回ることを初めて示しました。 彼らはまだ古典的な能力を超えていませんが、私たちはまた、時間結晶やマヨラナエッジモードなどの新しい物理現象を観察するためにプロセッサを使用し、相互作用する光子の堅牢な束縛状態やフロケ進化のマヨラナエッジモードのノイズ耐性などの新しい実験的な発見をしました。 私たちは、この中間のノイズ領域でも、量子プロセッサを使って有用な量子実験を古典的な超並列計算よりもはるかに高速に実行できるアプリケーションを見つけると予想しています。これを「計算アプリケーション」と呼んでいます。まだ誰もこのような超古典的な計算アプリケーションを実証していません。したがって、このマイルストーンを達成するための問題は、量子プロセッサで実行された量子実験を古典的なアプリケーションの計算コストと比較する最良の方法は何かということです。 エラー訂正された量子アルゴリズムと古典的なアルゴリズムを比較する方法はすでにわかっています。その場合、計算複雑性の分野から、それらの相互の計算コスト(つまり、タスクを達成するために必要な操作の回数)を比較できることがわかります。しかし、現在の実験的な量子プロセッサでは、状況はそれほど明確ではありません。 「ノイズのある量子処理実験の計算コストの効果的な量子ボリューム、信頼性、および計算コスト」では、量子実験の計算コストを測定するためのフレームワークを提供し、実験の「効果的な量子ボリューム」を導入します。これは、測定結果に寄与する量子操作またはゲートの数です。私たちはこのフレームワークを適用して、最近の3つの実験の計算コストを評価します:ランダム回路サンプリング実験、アウトオブタイムオーダーコレレータ(OTOC)と呼ばれる量を測定する実験、およびイジングモデルに関連するフロケ進化の最新の実験。私たちは特にOTOCに興奮しています。なぜなら、OTOCは回路(量子ゲートまたは操作のシーケンス)の効果的な量子ボリュームを実験的に測定する直接的な方法を提供し、これは古典的なコンピュータにとって正確に推定するのが難しい計算的なタスクです。OTOCはまた、核磁気共鳴や電子スピン共鳴分光学においても重要です。したがって、私たちはOTOC実験が量子プロセッサの初の計算アプリケーションの有望な候補であると考えています。 計算コストといくつかの最近の量子実験の影響のプロット。一部(例:QC-QMC 2022)は高い影響力を持ち、他の一部(例:RCS 2023)は高い計算コストを持っていますが、まだ有用で十分に困難なものはありません。私たちの将来のOTOC実験がこの閾値を初めて超える可能性があると推測しています。プロットされた他の実験は、テキストで参照されています。 ランダム回路サンプリング:ノイズのある回路の計算コストの評価 ノイズのある量子プロセッサで量子回路を実行する場合、2つの競合する考慮事項があります。一方では、古典的に達成するのが困難なことを行いたいと考えています。計算コスト(古典的なコンピュータでタスクを達成するために必要な操作の数)は、量子回路の効果的な量子ボリュームに依存します。ボリュームが大きいほど、計算コストが高くなり、量子プロセッサが古典的なものを上回ることができます。 しかし、一方で、ノイズの多いプロセッサでは、各量子ゲートが計算に誤りを導入することがあります。操作が多いほど誤りが増え、興味のある量を測定する量子回路の信頼性が低下します。この考慮に基づいて、効果的な体積が小さく、クラシックコンピュータで簡単にシミュレートできるような単純な回路を選ぶことがあります。最大化したいこれら競合する要素のバランスを、「計算リソース」と呼びます。以下に示します。 量子回路の量子体積とノイズのトレードオフを示したグラフであり、これは「計算リソース」と呼ばれる量で捉えられます。ノイズの多い量子回路では、計算コストとともにこれは初めは増加しますが、やがてノイズが回路を制御し、減少させます。 これら競合する要素がどのように影響するかは、量子プロセッサの単純な「ハローワールド」プログラムであるランダム回路サンプリング(RCS)によって明らかになります。このプログラムは、量子プロセッサがクラシックコンピュータを上回る最初のデモンストレーションでした。ゲートのいかなるエラーもこの実験を失敗させる可能性があります。必然的に、これは高い信頼性で達成することの難しい実験であり、システムの信頼性の基準ともなります。しかし、これはまた、量子プロセッサによって達成可能な既知の最も高い計算コストに対応しています。私たちは最近、これまでで最も強力なRCS実験を報告しました。その実験では、低い測定実験的信頼性が1.7×10-3であり、高い理論的計算コストが約1023です。これらの量子回路には700の2量子ビットゲートがあります。この実験を世界最大のスーパーコンピュータでシミュレートするには約47年かかると推定されています。これは、計算アプリケーションに必要な2つの要件のうちの1つを満たしていますが、それ自体は特に有用なアプリケーションではありません。 OTOCとフロケエボリューション:局所観測量の効果的な量子体積 量子多体物理学にはクラシカルに解けない問題が多く存在し、これらの実験のいくつかを量子プロセッサ上で実行することには大きな潜在能力があります。通常、RCS実験とは異なる視点でこれらの実験を考えます。実験の終わりにすべてのキュビットの量子状態を測定するのではなく、通常は特定の局所物理観測量に関心があります。回路内のすべての操作が観測量に影響を与えるわけではないため、局所観測量の効果的な量子体積は、実験を実行するために必要なフル回路の体積よりも小さくなる場合があります。 これは、相対性理論からの光錐の概念を適用することで理解することができます。光錐は、時空内のどのイベントが因果関係を持つ可能性があるかを決定するものであり、情報がそれらの間を伝播するのに時間がかかるため、一部のイベントはお互いに影響を与えることはできません。このような2つのイベントはそれぞれの光錐の外にあります。量子実験では、光錐を「バタフライコーン」というものに置き換えます。その成長はバタフライ速度によって決まります。バタフライ速度はシステム全体に情報が広がる速度を表します(これは後述のOTOCによって特徴付けられます)。局所観測量の効果的な量子体積は、本質的にはバタフライコーンの体積であり、観測量に因果関係を持つ量子操作のみを含みます。したがって、情報がシステム内で広がる速度が速いほど、効果的な体積は大きくなり、クラシック的にシミュレートするのはより困難になります。 局所観測量Bに寄与するゲートの効果的な体積Veffの描写です。関連する量である効果的な面積Aeffは、平面とコーンの断面で表されています。底辺の周囲はバタフライ速度vBで移動する情報の前面に対応しています。 このフレームワークを最近の実験に適用し、いわゆるFloquet Isingモデル、時間結晶およびMajorana実験に関連する物理モデルを実装しました。この実験のデータから、最大回路に対して有効な信頼性を0.37と直接推定することができます。測定されたゲートエラーレートは約1%であり、これにより推定される有効なボリュームは約100となります。これは、127量子ビットに2,000のゲートが含まれるライトコーンよりもはるかに小さくなります。したがって、この実験のバタフライ速度は非常に小さいです。実験よりも大きな精度を得る数値シミュレーションを使用して、この小さな有効なボリュームが127ではなく約28の量子ビットのみをカバーしていることも確認されました。この小さな有効ボリュームはOTOC技術によっても裏付けられています。これは深い回路であったにもかかわらず、推定される計算コストは5×10^11であり、最近のRCS実験のおよそ1兆分の1です。それに対応して、この実験は単一のA100 GPU上のデータポイントごとに1秒未満でシミュレートすることができます。したがって、これは確かに有用なアプリケーションであるものの、計算アプリケーションの2番目の要件を満たしていません:古典的なシミュレーションを大幅に上回ること。…

「勾配降下法アルゴリズムとその直感的な考え方」
最適化手法の中で、そして一次のアルゴリズムタイプにおいて、確かにGradient Descentとして知られるものを聞いたことがあるでしょうこれは一次の最適化タイプであり、…を必要とします
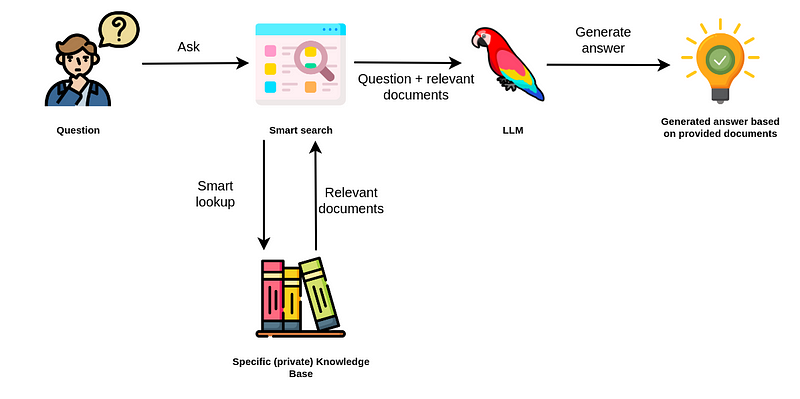
「Neo4jにおける非構造化テキストに対する効率的な意味検索」
ChatGPTが6か月前に登場して以来、技術の風景は変革的な転換を遂げましたChatGPTの優れた一般化能力により、...

AIが私たちのコーディング方法を変えていく方法
簡単に言うと、この記事では、AIと仕事に関する私の最新の研究の要約(AIが生産性に与える影響を探りながら、長期的な影響についての議論を展開する)を見つけることができます...
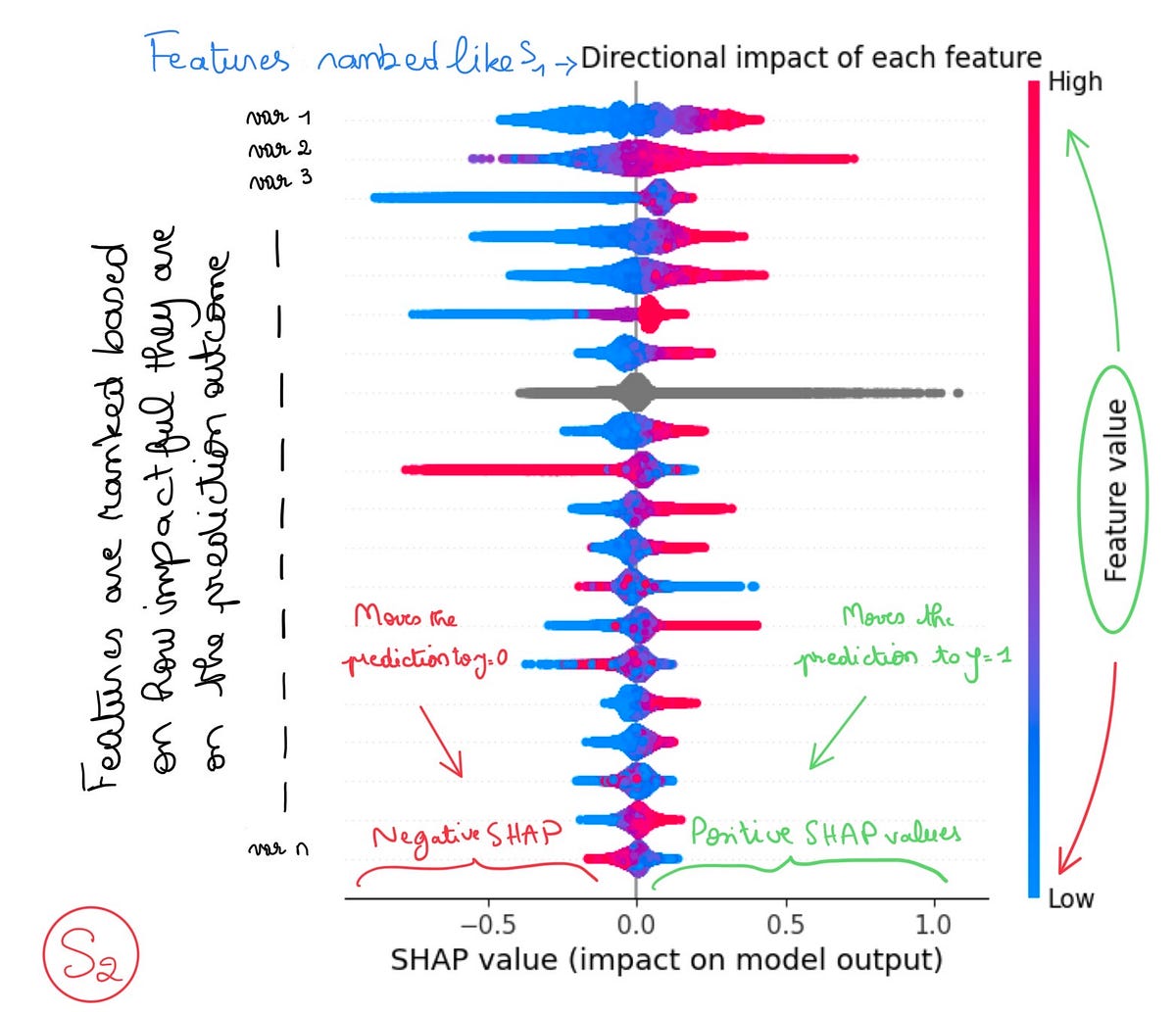
「Spotifyで学んだSHAPによる特徴重要度分析」
この記事は、Spotifyでの私の機械学習の卒業論文からの学びを文書化した2部構成の記事のうちの一つですぜひ第二の記事(まもなく到着予定!)もチェックしてください私が成功した方法について書かれています

「ダークウェブを照らす」
「ダークウェブがどのように運営され続けているのか、そしてなぜ法執行機関がそれをすぐに閉鎖しないのか」

「ODSC West 2023 の最初の50セッションが発表されました」
ODSC Westは数ヶ月後に迫っており、最初の50セッションを発表できることを大変嬉しく思っています!このブログでは全てについて話すスペースがありませんが、以下にいくつかを紹介します最初の50セッションの完全なリストはこちらでご覧いただけます...

「Amazon SageMakerを使用したフェデレーテッドラーニングによる分散トレーニングデータを用いた機械学習」
この投稿では、分散トレーニングデータを使用してAmazon SageMakerでフェデレーテッドラーニングを実装する方法について説明します

セーフコーダーを紹介します
今日は、エンタープライズ向けのコードアシスタントソリューションであるSafeCoderの発表をお知らせいたします。 SafeCoderの目標は、エンタープライズ向けに完全に準拠し、自己ホスト型のペアプログラマーを提供することで、ソフトウェア開発の生産性を向上させることです。マーケティングの言葉で言えば、「独自のオンプレミスGitHub Copilot」です。 さらに詳しく見ていく前に、以下のことを知っておく必要があります: SafeCoderはモデルではなく、完全なエンドツーエンドの商用ソリューションです SafeCoderはセキュリティとプライバシーを中心に設計されており、トレーニングや推論中にコードがVPCから出ることはありません SafeCoderは、顧客が独自のインフラストラクチャ上で自己ホストすることを前提としています SafeCoderは、顧客が独自のCode Large Language Modelを所有することを目指して設計されています SafeCoderの利点は何ですか? GitHub CopilotなどのLLMを活用したコードアシスタントソリューションは、生産性の向上に大きく貢献しています。エンタープライズでは、企業のコードベースに合わせてCode LLMを調整し、独自のCode LLMを作成することで、補完の信頼性と関連性を向上させ、さらなる生産性の向上を実現できます。例えば、Googleの内部LLMコードアシスタントは、内部のコードベースをトレーニングデータとして学習することで、25-34%の補完受け入れ率を報告しています。 しかし、クローズドソースのCode LLMを利用して内部のコードアシスタントを作成することは、コンプライアンスとセキュリティの問題につながります。トレーニング中には、クローズドソースのCode LLMを内部のコードベースに微調整するために、このコードベースを第三者に公開する必要があります。そして、推論中には、微調整されたCode LLMがトレーニングデータセットからコードを「漏洩」させる可能性があります。コンプライアンス要件を満たすためには、企業は自社のインフラストラクチャ内で微調整されたCode LLMを展開する必要がありますが、クローズドソースのLLMではそれは不可能です。 Hugging Faceでは、SafeCoderによって顧客が独自のCode LLMを構築できるようになります。最新のオープンソースモデルとライブラリを使用して、独自のコードベースに微調整されたCode…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.