Learn more about Search Results Yi - Page 44

- You may be interested
- 「5つの手順でGoogle Cloud Platformを始...
- 「ジンディのCEO兼共同創設者、セリーナ・...
- ヘッドショットプロのレビュー:2時間で12...
- 3Dプリンターは郵便局の迅速かつ手頃な配...
- 「私たちの独占的なDockerチートシートを...
- 「クラスの不均衡とオーバーサンプリング...
- 拡散生成モデルによる医薬品発見の加速化
- このAIの論文は、インコンテキスト学習の...
- 「LLMのパラメータ効率的なファインチュー...
- チャタヌーガプラントは、量子種子を育て...
- Googleは独占禁止法訴訟で敗訴:ビッグテ...
- テンセントAIラボの研究者たちは、テキス...
- 分析プロジェクトにおけるデータ品質の課...
- プロンプトエンジニアリングへの紹介
- 「30日間のマップチャレンジの私の3週目」
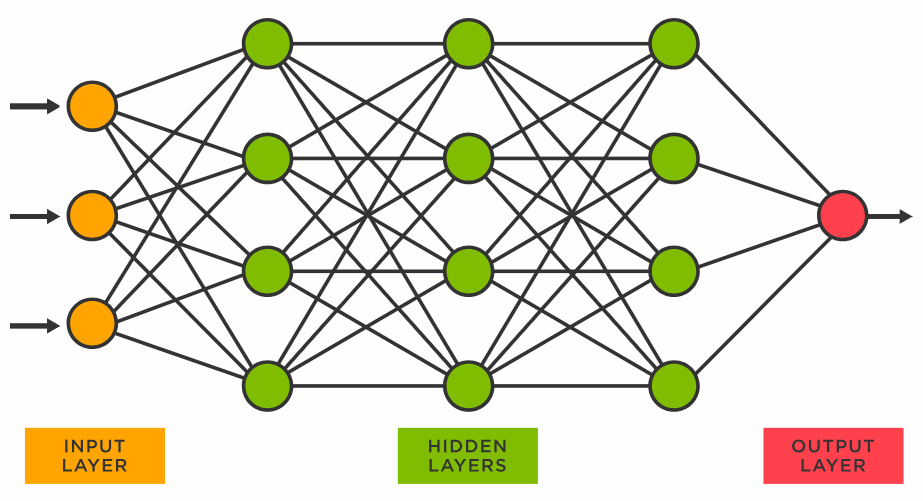
「ChatGPTのようなLLMの背後にある概念についての直感を構築する-パート1-ニューラルネットワーク、トランスフォーマ、事前学習、およびファインチューニング」
「たぶん私だけじゃないと思いますが、1月のツイートで明らかになっていなかったとしても、私は最初にChatGPTに出会ったときに完全に驚きましたその体験は他のどんなものとも違いました…」

「Hugging Face Transformersを使用したBERT埋め込みの作成」
はじめに Transformersはもともと、テキストを一つの言語から別の言語に変換するために作られました。BERTは、人間の言語を学習し作業する方法に大きな影響を与えました。それはテキストを理解する元々のトランスフォーマーモデルの部分を改良しました。BERTの埋め込みを作成することは、特に複雑な意味を持つ文章を把握するのに適しています。これは、文章全体を調べ、単語のつながり方を理解することで行います。Hugging Faceのtransformersライブラリは、ユニークな文章コードを作成し、BERTを導入するための鍵です。 学習目標 BERTと事前学習モデルの理解を深める。これらが人間の言語との作業にどれだけ重要かを理解する。 Hugging FaceのTransformersライブラリを効果的に使用する方法を学ぶ。これを使用してテキストの特殊な表現を作成する。 事前学習されたBERTモデルからこれらの表現を正しく削除する様々な方法を見つける。これは、異なる言語タスクには異なるアプローチが必要なため重要です。 実際にこれらの表現を作成するために必要な手順を実際に行い、実践的な経験を積む。自分自身でできることを確認する。 作成したこれらの表現を使用して、テキストのソートやテキスト内の感情の把握など、他の言語タスクを改善する方法を学ぶ。 特定の言語タスクにさらに適したように事前学習モデルを調整する方法を探索する。これにより、より良い結果が得られる可能性があります。 これらの表現が言語タスクの改善にどのように使用され、言語モデルの正確性とパフォーマンスを向上させるかを調べる。 この記事はデータサイエンスブログマラソンの一部として公開されました。 パイプラインはトランスフォーマーのコンテキスト内で何を含むのか? パイプラインは、トランスフォーマーライブラリに含まれる複雑なコードを簡素化するユーザーフレンドリーなツールと考えてください。言語の理解、感情分析、特徴の抽出、質問に対する回答などのタスクにモデルを使用することを簡単にします。これらの強力なモデルとの対話を簡潔な方法で提供します。 パイプラインにはいくつかの重要なコンポーネントが含まれます:トークナイザ(通常のテキストをモデルが処理するための小さな単位に変換するもの)、モデル自体(入力に基づいて予測を行うもの)、そしてモデルがうまく動作するようにするためのいくつかの追加の準備ステップ。 Hugging Face Transformersの使用の必要性は何ですか? トランスフォーマーモデルは通常非常に巨大であり、トレーニングや実際のアプリケーションで使用するために取り扱うことは非常に複雑です。Hugging Face transformersは、このプロセス全体を簡単にすることを目指しています。どれほど巨大であっても、どんなTransformerモデルでも、ロード、トレーニング、保存するための単一の方法を提供します。モデルのライフサイクルの異なる部分に異なるソフトウェアツールを使用することはさらに便利です。一連のツールでトレーニングを行い、その後、手間をかけずに実世界のタスクに使用することができます。 高度な機能 これらの最新のモデルは使いやすく、人間の言語の理解と生成、コンピュータビジョンや音声に関連するタスクにおいて優れた結果を提供します。…

「NTU SingaporeのこのAI論文は、モーション表現を用いたビデオセグメンテーションのための大規模ベンチマーク、MeVISを紹介しています」
言語にガイドされたビデオセグメンテーションは、自然言語の記述を使用してビデオ内の特定のオブジェクトをセグメント化およびトラッキングすることに焦点を当てた発展途上の領域です。ビデオオブジェクトを参照するための現行のデータセットは通常、目立つオブジェクトに重点を置き、多くの静的属性を持つ言語表現に依存しています。これらの属性により、対象のオブジェクトを単一のフレームで特定することができます。しかし、これらのデータセットは、言語にガイドされたビデオオブジェクトセグメンテーションにおける動きの重要性を見落としています。 https://arxiv.org/abs/2308.08544 研究者は、私たちの調査を支援するために、Motion Expression Video Segmentation(MeViS)と呼ばれる新しい大規模データセットであるMeVISを紹介しました。 MeViSデータセットは2,006のビデオ、8,171のオブジェクト、および28,570のモーション表現で構成されています。上記の画像は、MeViSの表現を表示しており、これらの表現は主にモーションの属性に焦点を当てており、単一のフレームだけで対象のオブジェクトを特定することはできません。たとえば、最初の例では似たような外観を持つ3羽のオウムが特徴であり、対象のオブジェクトは「飛び去る鳥」と特定されます。このオブジェクトは、ビデオ全体のモーションをキャプチャすることでのみ認識できます。 MeVISデータセットがビデオの時間的なモーションに重点を置くようにするために、いくつかの手順があります。 まず、静的属性だけで説明できる孤立したオブジェクトを持つビデオを除外し、モーションと共存する複数のオブジェクトを含むビデオコンテンツを注意深く選択します。 次に、ターゲットオブジェクトをモーションの単語のみで曖昧さなく説明できる場合、カテゴリ名やオブジェクトの色などの静的な手がかりを含まない言語表現を優先します。 MeViSデータセットの提案に加えて、研究者はこのデータセットがもたらす課題に対処するためのベースラインアプローチであるLanguage-guided Motion Perception and Matching(LMPM)を提案しています。彼らのアプローチでは、言語によるクエリの生成を行い、ビデオ内の潜在的な対象オブジェクトを識別します。これらのオブジェクトはオブジェクト埋め込みを使用して表現され、オブジェクトの特徴マップと比較してより堅牢で計算効率の良いものです。研究者はこれらのオブジェクト埋め込みに対してMotion Perceptionを適用し、ビデオのモーションダイナミクスの時間的な文脈を捉え、ビデオ内の瞬間的なモーションと持続的なモーションの両方を把握することができます。 https://arxiv.org/abs/2308.08544 上記の画像はLMLPのアーキテクチャを表示しています。彼らはTransformerデコーダを使用して、モーションに影響を受けた組み合わせられたオブジェクト埋め込みから言語を解釈し、オブジェクトの移動を予測するのに役立ちます。それから、言語特徴を投影されたオブジェクトの動きと比較して、表現で言及されるターゲットオブジェクトを見つけます。この革新的な方法は、言語理解とモーション評価を統合して、複雑なデータセットの課題を効果的に処理します。 この研究は、より高度な言語にガイドされたビデオセグメンテーションアルゴリズムの開発の基盤を提供しました。さらに、以下のようなより困難な方向に向けた道を開拓しました。 視覚的および言語的モダリティにおけるより良いモーション理解とモデリングのための新しい技術の探索。 冗長な検出されたオブジェクトの数を減らすより効率的なモデルの作成。 言語と視覚信号の相補的な情報を活用するための効果的なクロスモーダル融合手法の設計。 複数のオブジェクトと表現がある複雑なシーンを処理できる高度なモデルの開発。 これらの課題に取り組むには、言語によるビデオセグメンテーションの現在の最先端を推進するための研究が必要です。

ロボットスキル合成のための言語から報酬への変換
Googleの研究科学者、Wenhao YuとFei Xiaによる投稿 エンドユーザーがロボットに新しいタスクを教えるためのインタラクティブな機能を持つことは、実世界の応用において重要な能力です。例えば、ユーザーはロボット犬に新しいトリックを教えたり、マニピュレータロボットにユーザーの好みに基づいてランチボックスの整理方法を教えたりすることがあります。大量の言語モデルが、インターネット上の広範なデータで事前学習された最近の進歩は、この目標を達成するための有望な道を示しています。実際、研究者たちは、LLMをロボットに活用するためのさまざまな方法を探索しています。それは、ステップバイステップの計画や目標指向の対話からロボットコードの生成までです。 これらの方法は、新しい行動の構成的一般化の新しい方法を提供しますが、既存の制御原理のライブラリーから新しい行動をリンクするために言語を使用することに焦点を当てています。これらの制御原理は、手動で設計されるか、あらかじめ学習されるものです。ロボットの動きに関する内部知識を持っているにもかかわらず、LLMは関連するトレーニングデータが限られているため、低レベルのロボットコマンドを直接出力することが困難です。その結果、これらの方法の表現は、使用可能な基本要素の幅によって制約されます。これらの基本要素の設計は、広範な専門知識や大量のデータ収集を必要とすることがしばしばあります。 「Language to Rewards for Robotic Skill Synthesis」では、自然言語入力を介してユーザーがロボットに新しいアクションを教える手法を提案しています。これを行うために、言語と低レベルのロボットアクションの間のギャップを埋めるインターフェースとして報酬関数を活用しています。報酬関数は、その意味、モジュール性、解釈性の豊かさから、このようなタスクにとって理想的なインターフェースを提供します。また、報酬関数は、ブラックボックス最適化や強化学習(RL)を介した低レベルポリシーへの直接的な接続を提供します。我々は、LLMsを活用して自然言語のユーザー指示を報酬指定コードに翻訳し、それからMuJoCo MPCを適用して生成された報酬関数を最大化する最適な低レベルのロボットアクションを見つける言語から報酬へのシステムを開発しました。我々は、四足歩行ロボットと器用なマニピュレータロボットを使用して、シミュレーション上のさまざまなロボット制御タスクで我々の言語から報酬へのシステムを実証しました。さらに、物理的なロボットマニピュレータでも我々の手法を検証しました。 言語から報酬へのシステムは、2つの主要なコンポーネントで構成されています:(1)報酬トランスレータ、および(2)モーションコントローラ。報酬トランスレータは、ユーザーの自然言語の指示をPythonコードとして表される報酬関数にマッピングする役割を担っています。モーションコントローラは、与えられた報酬関数を最適化するために、リシーディングホライズン最適化を使用して、ロボットモーターごとに適用されるトルクの量などの最適な低レベルのロボットアクションを見つけます。 LLMsは、事前学習データセット内のデータが不足しているため、直接的に低レベルのロボットアクションを生成することができません。我々は報酬関数を使用して、言語と低レベルのロボットアクションのギャップを埋め、自然言語の指示から新しい複雑なロボットモーションを実現することを提案しています。 報酬トランスレータ:ユーザーの指示を報酬関数に翻訳する 報酬トランスレータモジュールは、自然言語のユーザー指示を報酬関数にマッピングすることを目指して構築されました。報酬の調整は、特定のハードウェアに対して専門知識が必要なため、一般的な言語データセットで訓練されたLLMsが特定の報酬関数を直接生成できないことは驚くべきことではありませんでした。これを解決するために、LLMsのインコンテキスト学習能力を適用しました。さらに、報酬トランスレータをモーションディスクリプタと報酬コーダーの2つのサブモジュールに分割しました。 モーションディスクリプタ まず、モーションディスクリプタを設計し、ユーザーからの入力を解釈して、あらかじめ定義されたテンプレートに従ったロボットの動きの自然言語の説明に展開します。このモーションディスクリプタは、曖昧またはあいまいなユーザーの指示をより具体的で具体的なロボットの動きに変換し、報酬コーディングのタスクをより安定させます。さらに、ユーザーはモーションの説明フィールドを介してシステムと対話するため、これは報酬関数を直接表示するよりもユーザーにとってより解釈可能なインターフェースも提供します。 モーションディスクリプタを作成するために、ユーザーの入力をLLMで翻訳し、希望するロボットの動作の詳細な説明に変換します。 LLMが適切な詳細度と形式でモーションの説明を出力するようにガイドするプロンプトを設計します。 あいまいなユーザーの指示をより詳細な説明に翻訳することで、システムで報酬関数をより信頼性の高い方法で生成することができます。 このアイデアは、ロボットのタスクを超えて一般的に応用することも可能であり、Inner-Monologueとchain-of-thoughtのプロンプトに関連しています。 Reward…
「エンティティ解決とグラフニューラルネットワークを用いた詐欺検知」
オンライン詐欺は、金融、電子商取引、およびその他の関連産業にとってますます深刻な問題ですこの脅威に対応するため、組織は機械学習と…に基づく詐欺検知メカニズムを使用します

ランダムウォークタスクにおける時差0(Temporal-Difference(0))と定数αモンテカルロ法の比較
モンテカルロ(MC)法と時間差分(TD)法は、強化学習の分野での基本的な手法です経験に基づいて予測問題を解決します
「AIの学び方」 AIを学ぶ方法
初心者の一般的な誤解は、最新のアルゴリズムを実装したいくつかのチュートリアルからAI/MLを学べるということですそのため、AIの学習に関するいくつかのノートとアドバイスを共有したいと思いますまた、私も...
データ、効率化された:より良い製品、ワークフロー、チームの構築方法
「利用可能なデータと有用なデータの間のギャップは、データプラクティショナーが実現するための唯一の目的である企業やツールの増加にもかかわらず、非常に困難であることが証明されています」

「LoRAアダプターにダイブ」
「大規模言語モデル(LLM)は世界中で大流行しています過去の1年間では、彼らができることにおいて莫大な進歩を目撃してきましたそれまではかなり限定的な用途にとどまっていましたが、今では…」

テンセントAIラボの研究者たちは、テキスト対応の画像プロンプトアダプタ「IP-Adapter」を開発しました:テキストから画像への拡散モデルのためのアダプタです
「リンゴ」と言えば、あなたの頭にすぐにリンゴのイメージが浮かびます。私たちの脳の働き方が魅力的であるように、生成AIも同じレベルの創造性とパワーをもたらし、機械が私たちがオリジナルコンテンツと呼ぶものを作り出すことができるようになりました。最近では、非常にリアルな画像を作成するテキストから画像へのモデルが登場しています。モデルに「リンゴ」とフィードすると、さまざまな種類のリンゴの画像を得ることができます。 しかし、これらのモデルがテキストのプロンプトだけで正確に私たちが望むものを生成することは非常に困難です。通常、適切なプロンプトの慎重な作成を必要とします。これを行う別の方法は、画像のプロンプトを利用することです。現在の既存のモデルから直接的にモデルを洗練するための技術は成功していますが、大量の計算能力を必要とし、異なる基礎モデル、テキストプロンプト、構造の調整との互換性が欠けています。 制御可能な画像生成の最近の進歩は、テキストから画像への拡散モデルのクロスアテンションモジュールに関する懸念を浮き彫りにしています。これらのモジュールは、事前学習済みの拡散モデルのクロスアテンションレイヤーでキーと値のデータを射影するために調整されたウェイトを使用し、主にテキストの特徴に最適化されています。そのため、このレイヤーで画像とテキストの特徴を統合すると、画像の特異な詳細が無視される可能性があり、参照画像を利用する際に生成中の広範な制御(たとえば、画像のスタイルの管理)につながることがあります。 上記の画像では、右側の例は画像のバリエーション、マルチモーダル生成、および画像プロンプトによる埋め込みの結果を示しており、左側の例は画像プロンプトと追加の構造条件による制御可能な生成の結果を示しています。 研究者たちは、現在の方法によって引き起こされる課題に対処するために、効果的な画像プロンプトアダプターであるIP-Adapterを導入しました。IP-Adapterは、テキストと画像の特徴を処理するための別個のアプローチを使用します。拡散モデルのUNetに、画像の特徴に特化した追加のクロスアテンションレイヤーを追加しました。トレーニング中、新しいクロスアテンションレイヤーの設定を調整し、元のUNetモデルを変更せずに残します。このアダプターは効率的でありながら強力です。たった2200万のパラメーターでも、IPアダプターはテキストから画像への拡散モデルから派生した完全に微調整された画像プロンプトモデルと同じくらい良い画像を生成することができます。 その研究結果は、IP-Adapterが再利用可能かつ柔軟であることを証明しています。ベースの拡散モデルでトレーニングされたIP-Adapterは、同じベースの拡散モデルから微調整された他のカスタムモデルに一般化することができます。さらに、IP-AdapterはControlNetなどの他の制御アダプターとも互換性があり、画像プロンプトと構造制御の容易な組み合わせが可能です。別個のクロスアテンション戦略のおかげで、画像プロンプトはテキストプロンプトと並行して動作し、マルチモーダルな画像を作成します。 上記の画像は、IP-Adapterを他の方法と比較した場合の異なる構造条件を示しています。IP-Adapterの効果的な性能にもかかわらず、それはコンテンツとスタイルで参照画像に似た画像しか生成できません。言い換えれば、テキスト逆転やドリームブースなどの既存の方法のように、与えられた画像の主題と非常に一致した画像を合成することはできません。将来的には、研究者は一貫性を高めるために、より強力な画像プロンプトアダプターを開発することを目指しています。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.