Learn more about Search Results Introduction to Python - Page 44

- You may be interested
- このAIニュースレターは、あなたが必要と...
- AIのインフレーション:常に多い方がいい...
- 「UCバークレーの研究者たちは、スターリ...
- フランスの新しいAIチャンピオンがシリコ...
- Webスケールトレーニング解放:DeepMindが...
- 「Reactを使用して、エキサイティングなデ...
- デット (物体検出用トランスフォーマー)
- 「コヒアーがコーラルを導入:最も戦略的...
- 「時間の最適化を送る」
- RedPajamaプロジェクト:LLMの民主化を目...
- 「Pythonによる水質EDAと水質の適性分析」
- ドメイン固有アプリケーションのためのLLM...
- 「ゼロトラストネットワークアクセス(ZTN...
- MITの研究者が新しいAIツール「PhotoGuard...
- 「誰が勝ち、誰が負けるのか? AIコーディ...

Googleの提供する無料のジェネレーティブAI学習パス
「ジェネレーティブAIについて最新情報を得たいですか?Google Cloudから提供される無料のコースやリソースをチェックしてみてください」
説明可能AI(XAI)
こんにちは、テクノフィルと好奇心旺盛な皆さん人工知能の本の次の章へようこそ人工知能の謎に更に深く入り込んでいきましょうAIが波を立てているような…
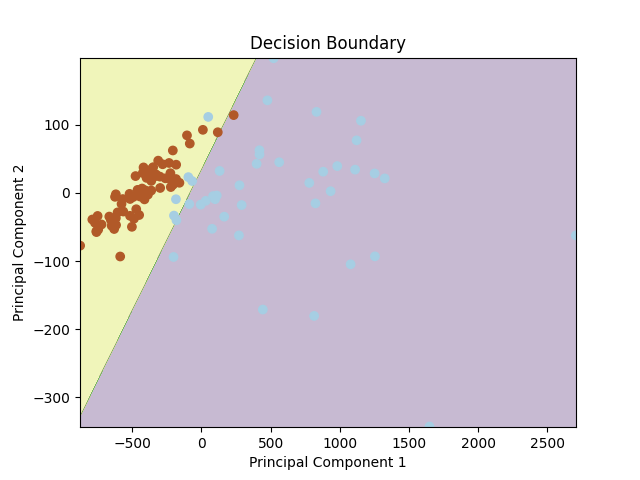
「ロジスティック回帰:直感と実装」
ロジスティック回帰は、2つの異なるデータ属性の間の決定境界を学習できる基本的な二値分類アルゴリズムですこの記事では、理論的な理解を深めるために、...
機械学習におけるクラスタリングの評価
「クラスタリングは常に私の関心を引きました特に、機械学習全体に初めて入り込んだ時には、教師なしクラスタリングは常に...」

「データサイエンティストが読むべきトップ7のNLP(自然言語処理)の本」
はじめに 自然言語処理(NLP)の最近の進歩は、データサイエンティストが最新の情報を把握するために不可欠です。NLPの書籍は、その分野における詳細な知識、実践的なガイダンス、最先端の技術を提供する貴重な情報源です。この記事では、データサイエンティストにとって必読の8冊のNLPの書籍を紹介します。これらの書籍には、NLPの基礎原理から最先端のディープラーニング技術までが網羅されています。これらの書籍は、初心者から経験豊富な実践者まで、NLPの理解と能力を向上させるでしょう。 NLPとは何ですか? 自然言語処理は、コンピュータと人間の言語との相互作用に焦点を当てた人工知能の分野です。コンピュータが言語の翻訳、感情分析、チャットボット、情報検索などのタスクを容易にするために、人間の言語を理解、解釈、生成するためのアルゴリズムや技術の開発を行います。 自然言語処理の入門コースもチェックしてください。 1. スピーチと言語処理 Daniel JurafskyとJames H. Martinによる著作 スピーチと言語処理は、NLPにおける最も包括的なマニュアルとされており、音声と言語処理の両方を含んでいます。この書籍は、基本的な概念、最先端の研究トピック、アルゴリズムを紹介しています。読者の能力レベルに応じた演習問題や実世界の例も提供されており、NLPの基礎を築くための有用なリソースとなっています。 書籍リンク:スピーチと言語処理 2. Pythonによる自然言語処理 Steven Bird、Ewan Klein、Edward Loperによる著作 Pythonによる自然言語処理は、実践的な学びを通じて新しいことを学びたい場合に適した選択肢です。この書籍では、NLTK(Natural Language Toolkit)などのよく知られたモジュールを使用して、Pythonを使ったNLPのアルゴリズムの開発方法を示しています。感情分析、固有表現認識、品詞タグ付け、トークン化、固有表現など、重要なNLPのプロセスが取り上げられています。このNLPの書籍は、役立つ例やコードの断片を提供することで、NLPのアイデアを実世界の状況で活用することができます。 書籍リンク:Pythonによる自然言語処理 3.…
類似検索、パート6:LSHフォレストによるランダム射影
「類似検索」とは、クエリが与えられた場合に、データベース内のすべてのドキュメントの中から、それに最も類似したドキュメントを見つけることを目指す問題ですデータサイエンスにおいては、類似検索はしばしばNLP(自然言語処理)で現れます...

「データサイエンスにおける頻度論者とベイズ統計学」
はじめに 統計分析は、急速に発展しているデータサイエンスの分野において重要な役割を果たしており、研究者に洞察に富んだ知識をもたらしています。しかし、ベイズ主義と頻度主義の方法論の相違は常に対立してきました。これらの2つの戦略は異なる心構えと手続きを具現化しており、それぞれが独自の利点と欠点を提供しています。この記事では頻度主義とベイズ主義の統計を比較し、それぞれの核心的なアイデア、主要なテスト、および選択する際に考慮すべき主要な変数について明らかにします。 頻度主義とベイズ主義:概要 側面 頻度主義アプローチ ベイズ主義アプローチ 確率の解釈 客観的:確率は長期的な頻度または繰り返される実験の限定的な振る舞いを表す。 主観的:確率は先行知識とデータに基づく信念や不確実性を表す。 パラメータの取り扱い 固定:パラメータは固定された未知の定数です。推定では、データに基づいて「最適な」推定値を見つけることが求められます。 ランダム:パラメータは独自の確率分布を持つランダム変数として扱われます。先行信念とデータに基づいて更新され、事後分布が得られます。 先行情報 該当なし:通常、先行情報は分析に明示的に組み込まれません。 重要:ベイズ分析では、データを観測する前のパラメータに関する先行信念を表す事前分布を指定する必要があります。 推論アプローチ 仮説検定:p値と棄却領域を使用します。 信用区間:指定された確率でパラメータ値を推定するための信用区間を使用します。 不確実性の取り扱い 点推定:点推定(例:標本平均)とそれに関連する不確実性(例:信頼区間)。 確率分布:パラメータ推定の不確実性を直接モデル化する事後分布。 サンプルサイズの要件 大規模サンプル:正確なパラメータ推定にはしばしば大規模なサンプルサイズが必要です。 小規模サンプル:ベイズ法では、特に情報量の多い事前分布を使用することで、小規模なサンプルサイズでも合理的な推定が可能です。…

「Hugging Faceを使用してLLMsを使ったテキスト要約機を構築する」
はじめに 最近、LLMs(Large Language Models)を使用したテキスト要約は多くの関心を集めています。これらのモデルは、GPT-3やT5などの事前訓練モデルであり、人間のようなテキストやテキスト分類、要約、翻訳などのタスクを生成することができます。Hugging Faceは、LLMsを使用するための人気のあるライブラリの一つです。 この記事では、特にHugging Faceに焦点を当てて、LLMの能力について検討し、難解なNLPの問題を解決するための適用方法について説明します。また、Hugging FaceとLLMsを使用して、Streamlit用のテキスト要約アプリケーションを構築する方法についても説明します。まずは、この記事の学習目標について見てみましょう。 学習目標 Hugging Faceをプラットフォームとして使用したLLMsとTransformersの機能と機能を探索する。 Hugging Faceが提供する事前訓練モデルとパイプラインを活用して、チャットボットなどのさまざまなNLPタスクを実行する方法を学ぶ。 Hugging FaceとLLMsを使用したテキスト要約の実践的な理解を開発する。 テキスト要約のための対話型Streamlitアプリケーションを作成する。 この記事は、データサイエンスのブログマラソンの一環として公開されました。 大規模言語モデル(LLMs)の理解 LLMモデルは大量のテキストデータで訓練されます。これらのモデルは、前の文脈に基づいて次の単語を予測することにより、複雑な言語パターンを捉え、一貫したテキストを生成することができます。 LLMsは大量のパラメータを含むデータセットで訓練されます。訓練データの膨大な量により、LLMsは言語の微妙なニュアンスを学び、印象的な言語生成能力を提供することができます。 LLMsは機械翻訳、テキスト生成、質問応答、感情分析などのさまざまなタスクでの突破口を可能にし、NLPの分野に大きな影響を与えました。 これらのモデルはベンチマークで優れたパフォーマンスを発揮し、多くのNLPタスクにおいて頼りになるツールとなっています。 Hugging Face…

「Gensimを使ったWord2Vecのステップバイステップガイド」
はじめに 数か月前、Office Peopleで働き始めた当初、私は言語モデル、特にWord2Vecに興味を持ちました。ネイティブのPythonユーザーとして、私は自然にGensimのWord2Vecの実装に集中し、論文やオンラインのチュートリアルを探しました。私は複数の情報源から直接コードの断片を適用し、複製しました。私はさらに深く探求し、自分の方法がどこで間違っているのかを理解しようとしました。Stackoverflowの会話、GensimのGoogleグループ、およびライブラリのドキュメントを読みました。 しかし、私は常にWord2Vecモデルを作成する上で最も重要な要素の一つが欠けていると考えていました。私の実験の中で、文をレンマ化することやフレーズ/バイグラムを探すことが結果とモデルのパフォーマンスに重要な影響を与えることを発見しました。前処理の影響はデータセットやアプリケーションによって異なりますが、この記事ではデータの準備手順を含め、素晴らしいspaCyライブラリを使って処理することにしました。 これらの問題のいくつかは私をイライラさせるので、自分自身の記事を書くことにしました。完璧だったり、Word2Vecを実装する最良の方法だったりすることは約束しませんが、他の多くの情報源よりも良いと思います。 学習目標 単語の埋め込みと意味的な関係の捉え方を理解する。 GensimやTensorFlowなどの人気のあるライブラリを使用してWord2Vecモデルを実装する。 Word2Vecの埋め込みを使用して単語の類似度を計測し、距離を算出する。 Word2Vecによって捉えられる単語の類推や意味的関係を探索する。 Word2Vecを感情分析や機械翻訳などのさまざまな自然言語処理のタスクに適用する。 特定のタスクやドメインに対してWord2Vecモデルを微調整するための技術を学ぶ。 サブワード情報や事前学習された埋め込みを使用して未知語を処理する。 Word2Vecの制約やトレードオフ、単語の意味の曖昧さや文レベルの意味について理解する。 サブワード埋め込みやWord2Vecのモデル最適化など、高度なトピックについて掘り下げる。 この記事はData Science Blogathonの一部として公開されました。 Word2Vecについての概要 Googleの研究チームは2013年9月から10月にかけて2つの論文でWord2Vecを紹介しました。研究者たちは論文とともにCの実装も公開しました。Gensimは最初の論文の後すぐにPythonの実装を完了しました。 Word2Vecの基本的な仮定は、文脈が似ている2つの単語は似た意味を持ち、モデルからは似たベクトル表現が得られるというものです。例えば、「犬」、「子犬」、「子犬」は似た文脈で頻繁に使用され、同様の周囲の単語(「良い」、「ふわふわ」、「かわいい」など)と共に使用されるため、Word2Vecによると似たベクトル表現を持ちます。 この仮定に基づいて、Word2Vecはデータセット内の単語間の関係を発見し、類似度を計算したり、それらの単語のベクトル表現をテキスト分類やクラスタリングなどの他のアプリケーションの入力として使用することができます。 Word2vecの実装 Word2Vecのアイデアは非常にシンプルです。単語の意味は、それが関連する単語と共に存在することによって推測できるという仮定をしています。これは「友だちを見せて、君が誰かを教えてあげよう」という言葉に似ています。以下はword2vecの実装例です。…
NumPyを使用した効率的なk最近傍(k-NN)解
「NumPyの高度な機能を使って、k最近傍法(k-NN)問題を効率的に解決する方法を学び、ブルートフォースのPythonソリューションとのパフォーマンスを比較しましょう」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.