Learn more about Search Results リポジトリ - Page 42

- You may be interested
- 「アメリカではデータサイエンティストの...
- NVIDIAのAI研究者は、オブジェクト周囲の...
- 「DreamBooth:カスタム画像の安定拡散」
- 「時系列分析における移動平均の総合ガイド」
- 「AWSサービスを使用して完全なウェブアプ...
- 研究者たちは「絶対的に安全な」量子デジ...
- 機械学習とは何か?メリットとトップMLaaS...
- 「教師付き学習の実践:線形回帰」
- 地球は平らではなく、あなたのボロノイ図...
- 「自己教師あり学習とトランスフォーマー...
- 『AIの未来、心の索引化、より良いAIの構築』
- スタンフォード大学の研究者がRT-Sketchを...
- 偽のレビューがオンラインで横行していま...
- 「コーヒーマシンを介して侵害された R...
- 「CHATGPTの内部機能について:AIに関する...

「VAST DataのプラットフォームがAIイノベーションの障壁を取り除く方法」
データが存在する場所に関係なく、より多くのデータへの高速アクセスは、AIに基づくアプリケーション、ソリューション、および発見の採用と成功を加速させます
「カスタムPyTorchオペレーターを使用してDLデータ入力パイプラインを最適化する方法」
この投稿は、GPUベースのPyTorchワークロードのパフォーマンス分析と最適化に関する一連の投稿の5番目であり、直接的な続編です第4部では、私たちはどのように...をデモンストレーションしました

Amazon CloudWatchで、ポッドベースのGPUメトリクスを有効にします
この記事では、コンテナベースのGPUメトリクスの設定方法と、EKSポッドからこれらのメトリクスを収集する例について詳しく説明します

「過去のデータ、Ray、およびAmazon SageMakerを使用して装置のパフォーマンスを最適化する」
この記事では、Amazon SageMakerを使用してRayのRLlibライブラリを使って、過去のデータのみを使用して最適な制御ポリシーを見つけるためのエンドツーエンドのソリューションを構築します強化学習についてもっと学ぶには、Amazon SageMakerで強化学習を使用するを参照してください

「データサイエンスのベストプラクティス、パート1 – クエリをテストする」
データサイエンスの領域は、数学と統計学、そしてコンピュータサイエンスにそのルーツを持っています過去数十年間でかなり進化してきましたが、過去10〜15年間で初めて...

「カタストロフィックな忘却を防ぎつつ、タスクに微調整されたモデルのファインチューニングにqLoRAを活用する:LLaMA2(-chat)との事例研究」
大規模言語モデル(LLM)のAnthropicのClaudeやMetaのLLaMA2などは、さまざまな自然言語タスクで印象的な能力を示していますしかし、その知識とタスク固有の...
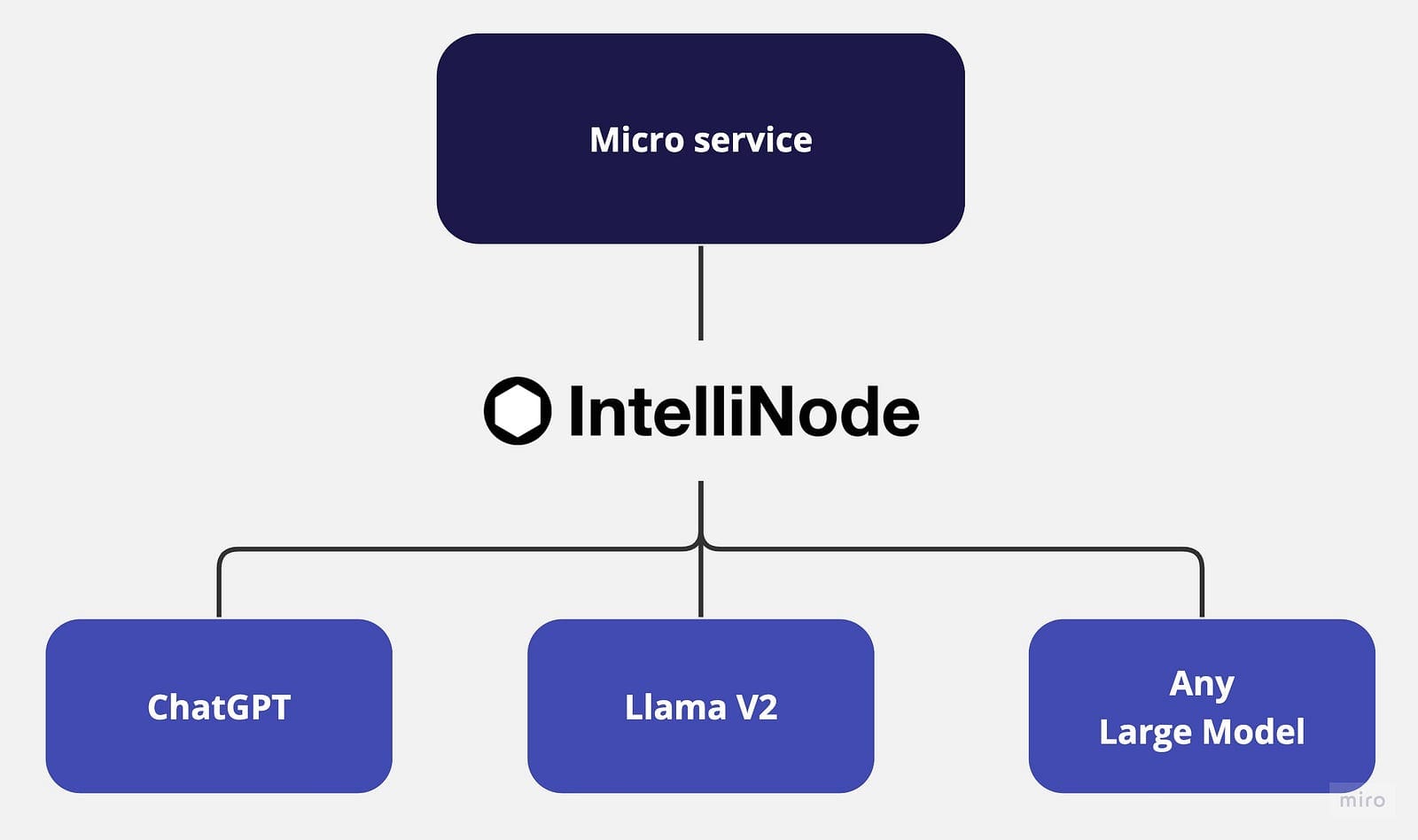
ラマとChatGPTを使用してマルチチャットバックエンドのマイクロサービスを構築する
LLM(Language Model)が進化し続けるにつれて、複数のモデルを統合したり、それらを切り替えることはますます困難になっていますこの記事では、モデルの統合をビジネスアプリケーションから分離し、プロセスを単純化するために、マイクロサービスアプローチを提案しています

「HuggingFaceを使用したLlama 2 7B Fine-TunedモデルのGPTQ量子化」
前の記事では、Meta AIが最近リリースした新しいLlama 2モデルを使用して、わずか数行のコードでPythonコードジェネレータを構築する方法を紹介しました今回は、...と説明します

「ナレ・ヴァンダニャン、Ntropyの共同創設者兼CEO- インタビューシリーズ」
Ntropyの共同創設者兼CEOであるナレ・ヴァンダニアンは、開発者が100ミリ秒未満で超人的な精度で金融取引を解析することを可能にするプラットフォームを提供していますこれにより、新世代の自律型ファイナンスへの道が開かれ、以前には不可能だった製品やサービスが動作しますこのプラットフォームは、生の取引ストリームをデータの組み合わせによってコンテキスト化された構造化情報に変換します

「LangchainなしでPDFチャットボットを構築する方法」
はじめに Chatgptのリリース以来、AI領域では進歩のペースが減速する気配はありません。毎日新しいツールや技術が開発されています。ビジネスやAI領域全般にとっては素晴らしいことですが、プログラマとして、すべてを学んで何かを構築する必要があるでしょうか? 答えはノーです。この場合、より現実的なアプローチは、必要なものについて学ぶことです。ものを簡単にすると約束するツールや技術がたくさんありますが、すべての場合にそれらが必要というわけではありません。単純なユースケースに対して大規模なフレームワークを使用すると、コードが肥大化してしまいます。そこで、この記事では、LangchainなしでCLI PDFチャットボットを構築し、なぜ必ずしもAIフレームワークが必要ではないのかを理解していきます。 学習目標 LangchainやLlama IndexのようなAIフレームワークが必要ない理由 フレームワークが必要な場合 ベクトルデータベースとインデックス作成について学ぶ PythonでゼロからCLI Q&Aチャットボットを構築する この記事は、Data Science Blogathonの一環として公開されました。 Langchainなしで済むのか? 最近の数ヶ月間、LangchainやLLama Indexなどのフレームワークは、開発者によるLLMアプリの便利な開発を可能にする非凡な能力により、注目を集めています。しかし、多くのユースケースでは、これらのフレームワークは過剰となる場合があります。それは、銃撃戦にバズーカを持ってくるようなものです。 これらのフレームワークには、プロジェクトで必要のないものも含まれています。Pythonはすでに肥大化していることで有名です。その上で、ほとんど必要のない依存関係を追加すると、環境が混乱するだけです。そのようなユースケースの一つがドキュメントのクエリです。プロジェクトがAIエージェントやその他の複雑なものを含まない場合、Langchainを捨ててゼロからワークフローを作成することで、不要な肥大化を減らすことができます。また、LangchainやLlama Indexのようなフレームワークは急速に開発が進んでおり、コードのリファクタリングによってビルドが壊れる可能性があります。 Langchainはいつ必要ですか? 複雑なソフトウェアを自動化するエージェントを構築したり、ゼロから構築するのに長時間のエンジニアリングが必要なプロジェクトなど、より高度なニーズがある場合は、事前に作成されたソリューションを使用することは合理的です。改めて発明する必要はありません、より良い車輪が必要な場合を除いては。その他にも、微調整を加えた既製のソリューションを使用することが絶対に合理的な場合は数多くあります。 QAチャットボットの構築 LLMの最も求められているユースケースの一つは、ドキュメントの質問応答です。そして、OpenAIがChatGPTのエンドポイントを公開した後、テキストデータソースを使用して対話型の会話ボットを構築することがより簡単になりました。この記事では、ゼロからLLM Q&A…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.