Learn more about Search Results ローン - Page 41

- You may be interested
- 日本の介護施設はビッグデータを活用して...
- 「Zephyr-7Bの内部:HuggingFaceの超最適...
- 北京大学の研究者は、FastServeを紹介しま...
- 「データサイエンスにおける頻度論者とベ...
- 機械学習のための高品質データセットの作...
- 「世界最小のデータパイプラインフレーム...
- このスタートアップは、クラウドコンピュ...
- Pandas 2.0 データサイエンティストにとっ...
- 「2023年に使用するAI生産性ツールのトッ...
- ラミニAIに会ってください:開発者が簡単...
- 「AI Time Journalが「AIにおけるSEOのト...
- 「トランスフォーマーとサポートベクター...
- ミストラルAI (8x7b)、専門家(MoE)モデ...
- 報告書:中国、生成AIサービスの統治ルー...
- 「人工知能生成コンテンツ(AIGC)におけ...

Hugging Faceの機械学習デモ(arXiv上)
私たちは、Hugging FaceがarXivと協力して論文をよりアクセスしやすく、見つけやすく、楽しくすることを発表できることを非常に嬉しく思っています!今日から、Hugging Face SpacesはarXivLabsとの統合を通じて、コミュニティまたは著者自身によって作成されたデモへのリンクを含むDemoタブとして提供されます。お気に入りの論文のデモタブに移動することで、オープンソースのデモへのリンクを見つけ、すぐに試すことができます🔥 Hugging Face Spacesは2021年10月のローンチ以来、コミュニティによって作成された12,000以上のオープンソースの機械学習デモを構築し共有するために使用されています。Spacesを使用すると、Hugging Faceユーザーはブラウザを使用してコードを実行することなく、モデルを共有、探索、議論し、対話型アプリケーションを構築することができます。これらのデモは、GradioやStreamlitなどのオープンソースのツールを使用し、Hugging Face Hubで利用可能なモデルとデータセットを活用して構築されています。 最新のarXivの統合により、ユーザーは論文のarXivの要約ページで最も人気のあるデモを見つけることができます。たとえば、BERT言語モデルのデモを試したい場合は、BERT論文のarXivページに移動し、デモタブに移動します。そこには、オープンソースコミュニティによって作成された200以上のデモが表示されます。一部のデモは単にBERTモデルを紹介しているだけであり、他のデモはBERTをより大きなパイプラインの一部として変更または使用する関連アプリケーションを紹介しています。上記のデモのようなものです。 デモにより、機械学習だけでなく、生物学、化学、天文学、経済学など、計算モデルが構築される他の分野を広範な視聴者が探索できるようになります。デモはモデルの動作原理の認識と理解を高め、研究者の仕事の可視性を高め、より多様な視聴者がバイアスやその他の問題を特定およびデバッグできるようにします。これらのデモにより、コードを一行も書くことなく、他の人が論文の結果を探索することができるため、研究の再現性が向上します!arXivとのこの統合に興奮しており、研究コミュニティがコミュニケーション、発信、解釈性を向上させるためにどのように活用するかを楽しみにしています。

Apple SiliconでのCore MLを使用した安定した拡散を利用する
Appleのエンジニアのおかげで、Core MLを使用してApple SiliconでStable Diffusionを実行できるようになりました! このAppleのレポジトリは、🧨 Diffusersを基にした変換スクリプトと推論コードを提供しており、私たちはそれが大好きです!できるだけ簡単にするために、私たちは重みを変換し、モデルのCore MLバージョンをHugging Face Hubに保存しました。 更新:この投稿が書かれてから数週間後、私たちはネイティブのSwiftアプリを作成しました。これを使用して、自分自身のハードウェアでStable Diffusionを簡単に実行できます。私たちはMac App Storeにアプリをリリースし、他のプロジェクトがそれを使用できるようにソースコードも公開しました。 この投稿の残りの部分では、変換された重みを自分自身のコードで使用する方法や、追加の重みを変換する方法について説明します。 利用可能なチェックポイント 公式のStable Diffusionのチェックポイントはすでに変換されて使用できる状態です: Stable Diffusion v1.4:変換されたオリジナル Stable Diffusion v1.5:変換されたオリジナル Stable…
インテルのサファイアラピッズを使用してPyTorch Transformersを高速化する – パート1
約1年前、私たちはHugging Faceのtransformersをクラスターまたは第3世代のIntel Xeon Scalable CPU(別名:Ice Lake)でトレーニングする方法を紹介しました。最近、Intelは第4世代のXeon CPUであるSapphire Rapidsというコードネームの新しいCPUを発売しました。このCPUには、深層学習モデルでよく見られる操作を高速化するエキサイティングな新しい命令があります。 この投稿では、AWS上で実行するSapphire Rapidsサーバーのクラスターを使用して、PyTorchトレーニングジョブの処理を高速化する方法を学びます。ジョブの分散にはIntelのoneAPI Collective Communications Library(CCL)を使用し、新しいCPU命令を自動的に活用するためにIntel Extension for PyTorch(IPEX)ライブラリを使用します。両方のライブラリはすでにHugging Face transformersライブラリと統合されているため、コードの1行も変更せずにサンプルスクリプトをそのまま実行できます。 次の投稿では、Sapphire Rapids CPU上での推論とそれによるパフォーマンス向上について説明します。 CPUでのトレーニングを検討すべき理由 Intel Xeon…

ゲーム開発のためのAI:5日間で農業ゲームを作成するパート1
AIゲーム開発へようこそ! このシリーズでは、AIツールを使用してわずか5日間で完全な機能を備えた農業ゲームを作成します。このシリーズの終わりまでに、さまざまなAIツールをゲーム開発のワークフローに組み込む方法を学ぶことができます。以下のようにAIツールを使用する方法を示します: アートスタイル ゲームデザイン 3Dアセット 2Dアセット ストーリー クイックビデオバージョンが必要ですか? こちらでご覧いただけます。それ以外の場合は、技術的な詳細をお読みください! 注意:このチュートリアルは、Unity開発とC#に精通している読者を対象としています。これらの技術に初めて触れる場合は、続ける前に「初心者向けUnityシリーズ」をご覧ください。 Day 1: アートスタイル ゲーム開発プロセスの最初のステップはアートスタイルを決定することです。農業ゲームのアートスタイルを決定するために、Stable Diffusionというツールを使用します。Stable Diffusionは、テキストの説明に基づいて画像を生成するオープンソースのモデルです。このツールを使用して、ゲームのビジュアルスタイルを作成します。 Stable Diffusionのセットアップ Stable Diffusionを実行するためのいくつかのオプションがあります:ローカルまたはオンラインです。デスクトップで十分なGPUを搭載しており、完全な機能を備えたツールセットを使用したい場合は、ローカルをお勧めします。それ以外の場合は、オンラインソリューションを実行できます。 ローカル Stable Diffusionをローカルで実行するためには、Automatic1111 WebUIを使用します。これは、Stable…

効率的で安定した拡散微調整のためのLoRAの使用
LoRA:Large Language Modelsの低ランク適応は、Microsoftの研究者によって導入された新しい技術で、大規模言語モデルの微調整の問題に取り組むためのものです。GPT-3などの数十億のパラメータを持つ強力なモデルは、特定のタスクやドメインに適応させるために微調整することが非常に高価です。LoRAは、事前学習済みモデルの重みを凍結し、各トランスフォーマーブロックにトレーニング可能な層(ランク分解行列)を注入することを提案しています。これにより、トレーニング可能なパラメータとGPUメモリの要件が大幅に削減されます。なぜなら、ほとんどのモデルの重みの勾配を計算する必要がないからです。研究者たちは、大規模言語モデルのトランスフォーマーアテンションブロックに焦点を当てることで、LoRAと完全なモデルの微調整と同等の品質を実現できることを発見しました。さらに、LoRAはより高速で計算量が少なくなります。 DiffusersのためのLoRA 🧨 LoRAは、当初大規模言語モデルに提案され、トランスフォーマーブロック上でデモンストレーションされたものですが、この技術は他の場所でも適用することができます。Stable Diffusionの微調整の場合、LoRAは画像表現とそれらを説明するプロンプトとの関連付けを行うクロスアテンションレイヤーに適用することができます。以下の図(Stable Diffusion論文から引用)の詳細は重要ではありませんが、黄色のブロックが画像とテキスト表現の関係を構築する役割を担っていることに注意してください。 私たちの知る限りでは、Simo Ryu(@cloneofsimo)がStable Diffusionに適応したLoRAの実装を最初に考案しました。興味深いディスカッションや洞察がたくさんあるGitHubのプロジェクトをご覧いただくために、彼らのGitHubプロジェクトをぜひご覧ください。 クロスアテンションレイヤーにLoRAトレーニング可能行列を深く注入するために、以前はDiffusersのソースコードを工夫(しかし壊れやすい方法)してハックする必要がありました。Stable Diffusionが私たちに示してくれたことの一つは、コミュニティが常に創造的な目的のためにモデルを曲げて適応する方法を見つけ出すことです。クロスアテンションレイヤーを操作する柔軟性を提供することは、xFormersなどの最適化技術を採用するのが容易になるなど、他の多くの理由で有益です。Prompt-to-Promptなどの創造的なプロジェクトには、これらのレイヤーに簡単にアクセスできる方法が必要です。そのため、ユーザーがこれを行うための一般的な方法を提供することにしました。私たちは昨年12月末からそのプルリクエストをテストしており、昨日のdiffusersリリースと共に公式にローンチしました。 私たちは@cloneofsimoと協力して、Dreamboothと完全な微調整方法の両方でLoRAトレーニングサポートを提供しています!これらの技術は次の利点を提供します: 既に議論されているように、トレーニングがはるかに高速です。 計算要件が低くなります。11 GBのVRAMを持つ2080 Tiで完全な微調整モデルを作成できました! トレーニングされた重みははるかに小さくなります。元のモデルが凍結され、新しいトレーニング可能な層が注入されるため、新しい層の重みを1つのファイルとして保存できます。そのサイズは約3 MBです。これは、UNetモデルの元のサイズの約1000分の1です。 私たちは特に最後のポイントに興奮しています。ユーザーが素晴らしい微調整モデルやドリームブーストモデルを共有するためには、最終モデルの完全なコピーを共有する必要がありました。それらを試すことを望む他のユーザーは、お気に入りのUIで微調整された重みをダウンロードする必要があり、膨大なストレージとダウンロードコストがかかります。現在、Dreamboothコンセプトライブラリには約1,000のDreamboothモデルが登録されており、おそらくさらに多くのモデルがライブラリに登録されていません。 LoRAを使用することで、他の人があなたの微調整モデルを使用できるようにするためのたった1つの3.29 MBのファイルを公開することができるようになりました。 (@mishig25への感謝、普通の会話で「dreamboothing」という動詞を使った最初の人です)。…

UnityゲームをSpaceにホストする方法
UnityゲームをHugging Face Spaceでホストできることを知っていますか?いいえ?そうです、できます! Hugging Face Spacesは、デモを構築、ホスト、共有するための簡単な方法です。通常は機械学習のデモに使用されますが、プレイ可能なUnityゲームもホストできます。以下にいくつかの例を示します。 Huggy Farming Game Unity APIデモ 次に、Spaceで独自のUnityゲームをホストする方法を説明します。 ステップ1:静的HTMLテンプレートを使用してSpaceを作成する まず、Hugging Face Spacesに移動してスペースを作成します。 “Static HTML”テンプレートを選択し、スペースに名前を付けて作成します。 ステップ2:Gitを使用してスペースをクローンする Gitを使用して、新しく作成したスペースをローカルマシンにクローンします。ターミナルまたはコマンドプロンプトで次のコマンドを実行することでこれを行うことができます。 git clone https://huggingface.co/spaces/{your-username}/{your-space-name} ステップ3:Unityプロジェクトを開く…

テキストからビデオへのモデルの深掘り
ModelScopeで生成されたビデオサンプルです。 テキストからビデオへの変換は、生成モデルの驚くべき進歩の長いリストの中で次に来るものです。その名前の通り、テキストからビデオへの変換は、時間的にも空間的にも一貫性のある画像のシーケンスをテキストの説明から生成する、比較的新しいコンピュータビジョンのタスクです。このタスクは、テキストから画像への変換と非常によく似ているように思えるかもしれませんが、実際にははるかに難しいものです。これらのモデルはどのように動作し、テキストから画像のモデルとはどのように異なり、どのようなパフォーマンスが期待できるのでしょうか? このブログ記事では、テキストからビデオモデルの過去、現在、そして未来について論じます。まず、テキストからビデオとテキストから画像のタスクの違いを見直し、条件付きと非条件付きのビデオ生成の独特の課題について話し合います。さらに、テキストからビデオモデルの最新の開発について取り上げ、これらの方法がどのように機能し、どのような能力があるのかを探ります。最後に、Hugging Faceで取り組んでいるこれらのモデルの統合と使用を容易にするための取り組みや、Hugging Face Hub内外でのクールなデモやリソースについて話します。 さまざまなテキストの説明を入力として生成されたビデオの例、Make-a-Videoより。 テキストからビデオ対テキストから画像 最近の開発が非常に多岐にわたるため、テキストから画像の生成モデルの現在の状況を把握することは困難かもしれません。まずは簡単に振り返りましょう。 わずか2年前、最初のオープンボキャブラリ、高品質なテキストから画像の生成モデルが登場しました。VQGAN-CLIP、XMC-GAN、GauGAN2などの最初のテキストから画像のモデルは、すべてGANアーキテクチャを採用していました。これらに続いて、2021年初めにOpenAIの非常に人気のあるトランスフォーマーベースのDALL-E、2022年4月のDALL-E 2、Stable DiffusionとImagenによって牽引された新しい拡散モデルの新たな波が続きました。Stable Diffusionの大成功により、DreamStudioやRunwayML GEN-1などの多くの製品化された拡散モデルや、Midjourneyなどの既存製品との統合が実現しました。 テキストから画像生成における拡散モデルの印象的な機能にもかかわらず、拡散および非拡散ベースのテキストからビデオモデルは、生成能力においてはるかに制約があります。テキストからビデオは通常、非常に短いクリップで訓練されるため、長いビデオを生成するためには計算コストの高いスライディングウィンドウアプローチが必要です。そのため、これらのモデルは展開とスケーリングが困難であり、文脈と長さに制約があります。 テキストからビデオのタスクは、さまざまな面で独自の課題に直面しています。これらの主な課題のいくつかには以下があります: 計算上の課題:フレーム間の空間的および時間的な一貫性を確保することは、長期的な依存関係を伴い、高い計算コストを伴います。そのため、このようなモデルを訓練することは、ほとんどの研究者にとって手の届かないものです。 高品質なデータセットの不足:テキストからビデオの生成のためのマルチモーダルなデータセットは希少で、しばしばスパースに注釈が付けられているため、複雑な動きのセマンティクスを学ぶのが難しいです。 ビデオのキャプションに関する曖昧さ:モデルが学習しやすいようにビデオを記述する方法は未解決の問題です。完全なビデオの説明を提供するためには、複数の短いテキストプロンプトが必要です。生成されたビデオは、時間の経過に沿って何が起こるかを物語る一連のプロンプトやストーリーに基づいて条件付ける必要があります。 次のセクションでは、テキストからビデオへの進展のタイムラインと、これらの課題に対処するために提案されたさまざまな手法について別々に議論します。高レベルでは、テキストからビデオの作業では以下のいずれかを提案しています: 学習しやすいより高品質なデータセットの作成。 テキストとビデオのペアデータなしでこのようなモデルを訓練する方法。 より計算効率の良い方法で長く、高解像度のビデオを生成する方法。 テキストからビデオを生成する方法…

スターコーダーでコーディングアシスタントを作成する
ソフトウェア開発者であれば、おそらくGitHub CopilotやChatGPTを使用して、プログラミングのタスクを解決したことがあるでしょう。これらのタスクには、コードを別の言語に変換したり、自然言語のクエリ(「N番目のフィボナッチ数を見つけるPythonプログラムを書いてください」といったもの)から完全な実装を生成したりするものがあります。これらの独自のシステムは、その機能には感動的ですが、一般にはいくつかの欠点があります。これらには、トレーニングに使用される公開データの透明性の欠如や、ドメインやコードベースに適応することのできなさなどがあります。 幸いにも、今はいくつかの高品質なオープンソースの代替品があります!これには、SalesForceのPython用CodeGen Mono 16B、またはReplitの20のプログラミング言語でトレーニングされた3Bパラメータモデルなどがあります。 新しいオープンソースの選択肢としては、BigCodeのStarCoderがあります。80以上のプログラミング言語、GitHubの問題、Gitのコミット、Jupyterノートブックから1兆トークンを収集した16Bパラメータモデルで、これらはすべて許可されたライセンスです。エンタープライズ向けのライセンス、8,192トークンのコンテキスト長、およびマルチクエリアテンションによる高速な大規模バッチ推論を備えたStarCoderは、現在、コードベースのアプリケーションにおいて最も優れたオープンソースの選択肢です。 このブログポストでは、StarCoderをチャット用にファインチューニングして、パーソナライズされたコーディングアシスタントを作成する方法を紹介します! StarChatと呼ばれるこのアシスタントには、次のようないくつかの技術的な詳細があります。 LLMを会話エージェントのように動作させる方法。 OpenAIのChat Markup Language(ChatMLとも呼ばれる)は、人間のユーザーとAIアシスタントの間の会話メッセージに対する構造化された形式を提供します。 🤗 TransformersとDeepSpeed ZeRO-3を使用して、多様な対話のコーパスで大きなモデルをファインチューニングする方法。 最終結果の一部を見るために、以下のデモでStarChatにいくつかのプログラミングの質問をしてみてください! デモで使用されたコード、データセット、およびモデルは、以下のリンクで見つけることができます。 コード: https://github.com/bigcode-project/starcoder データセット: https://huggingface.co/datasets/HuggingFaceH4/oasst1_en モデル: https://huggingface.co/HuggingFaceH4/starchat-alpha 始める準備ができたら、まずはファインチューニングなしで言語モデルを会話エージェントに変換する方法を見てみましょう。…

iPhone、iPad、およびMacでのCore MLによる高速で安定した拡散
先週、WWDC’23(Apple Worldwide Developers Conference)が開催されました。キーノート中のVision Proの発表に焦点が当てられましたが、それだけではありません。毎年のように、WWDC週はAppleのオペレーティングシステムとフレームワークの新機能について深く掘り下げる200以上の技術セッションが詰まっています。今年は特に、圧縮と最適化のためのCore MLの変更に興奮しています。これらの変更により、Stable Diffusionなどのモデルの実行が高速化され、メモリ使用量も少なくなります!一例として、12月にiPhone 13で実行したテストと現在の6ビットパレット化を使用した速度の比較を考えてみましょう: 12月のiPhoneでのStable Diffusionと現在の6ビットパレット化 目次 新しいCore MLの最適化 量子化および最適化されたStable Diffusionモデルの使用 カスタムモデルの変換と最適化 6ビット未満の使用 結論 新しいCore MLの最適化 Core MLは、Appleのデバイス内で効率的に機械学習モデルを実行するための成熟したフレームワークであり、CPU、GPU、およびMLタスクに特化したニューラルエンジンなど、Appleデバイスのすべてのコンピューティングハードウェアを活用します。デバイス上での実行は、Stable Diffusionや大規模な言語モデルの人気によって引き起こされた非常に興味深い時期を迎えています。多くの人々がこれらのモデルをさまざまな理由でハードウェア上で実行したいと考えており、利便性やプライバシー、APIのコスト削減などがその理由です。自然に、多くの開発者がデバイス上でこれらのモデルを効率的に実行する方法を探求し、新しいアプリやユースケースを作成しています。この目標を達成するためのCore MLの改善は、コミュニティにとって大きなニュースです!…
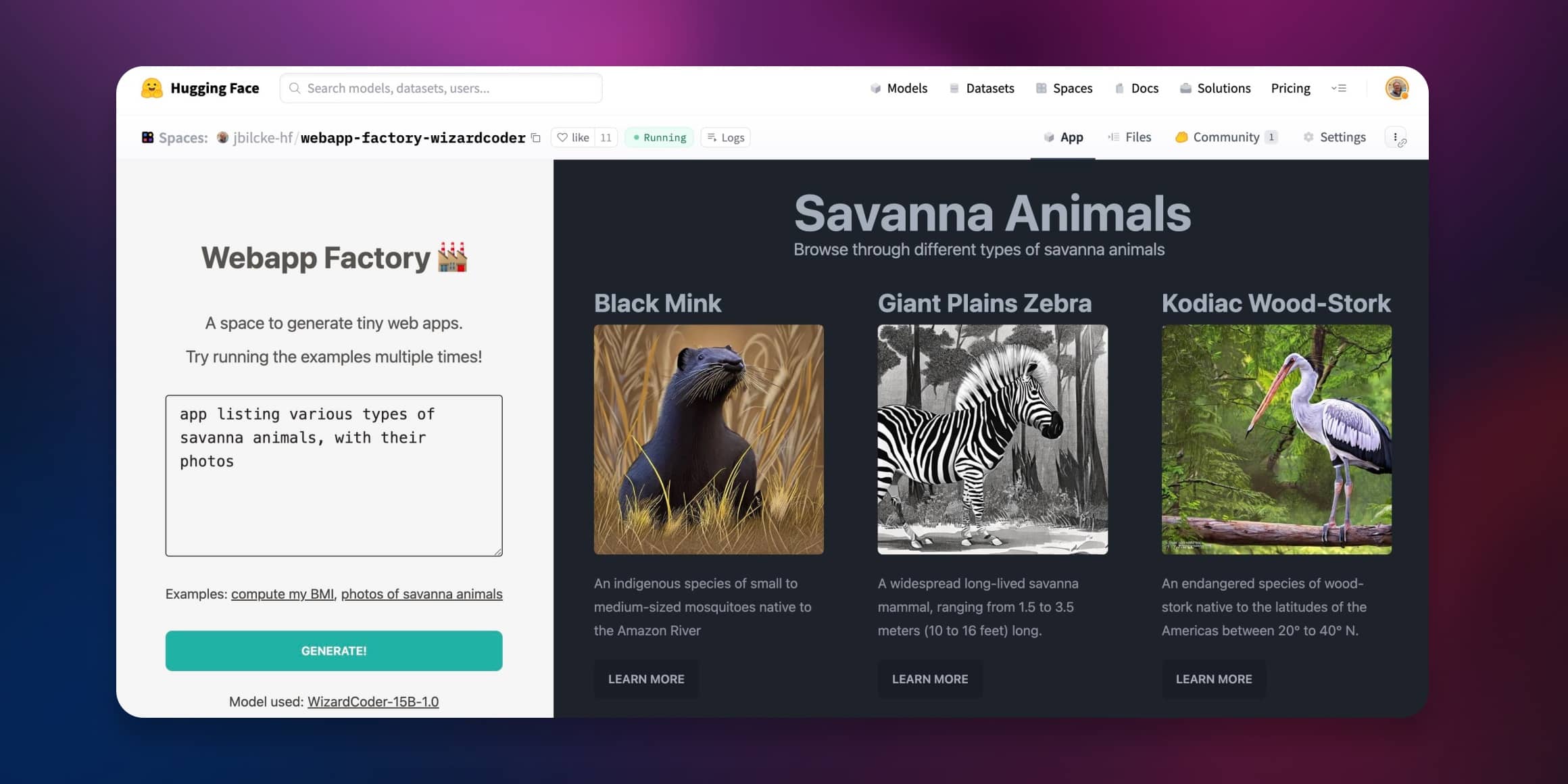
オープンなMLモデルを使用してWebアプリジェネレータを作成する
コード生成モデルがますます一般公開されるようになると、以前には想像もできなかった方法でテキストからウェブやアプリへの変換が可能になりました。 このチュートリアルでは、コンテンツのストリーミングとレンダリングを一度に行うことで、AIウェブコンテンツ生成への直接的なアプローチを紹介します。 ここでライブデモを試してみてください! → Webapp Factory NodeアプリでのLLMの使用方法 AIやMLに関連するすべてのことをPythonで行うと思われがちですが、ウェブ開発コミュニティではJavaScriptとNodeに大いに依存しています。 このプラットフォームで大きな言語モデルを使用する方法をいくつか紹介します。 ローカルでモデルを実行する JavaScriptでLLMを実行するためのさまざまなアプローチがあります。ONNXを使用したり、コードをWASMに変換して他の言語で書かれた外部プロセスを呼び出したりする方法などがあります。 これらの技術のいくつかは、次のような使いやすいNPMライブラリとして利用できます: コード生成をサポートするtransformers.jsなどのAI/MLライブラリの使用 ブラウザ用のllama-node(またはweb-llm)など、専用のLLMライブラリの使用 Pythoniaなどのブリッジを介してPythonライブラリを使用 ただし、このような環境で大きな言語モデルを実行すると、リソースをかなり消費することがあります。特にハードウェアアクセラレーションを使用できない場合はさらにリソースが必要です。 APIを使用する 現在、さまざまなクラウドプロバイダが言語モデルの使用を提案しています。以下はHugging Faceの提供するオプションです: コミュニティから小さなモデルからVoAGIサイズのモデルまで使用できる無料の推論API。 より高度で本番向けの推論エンドポイントAPIで、より大きなモデルやカスタム推論コードが必要な方向けのもの。 これらの2つのAPIは、NPM上のHugging Face推論APIライブラリを使用してNodeから利用できます。 💡…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.