Learn more about Search Results ローン - Page 40

- You may be interested
- 「Hugging FaceのTransformerモデルを使用...
- 🧨ディフューザーを使用した安定した拡散
- 「AIを暴走させようとするハッカーたちに...
- 「2024年のデータエンジニアリング&AI X...
- ビッグテックに対抗するためのAIスタート...
- 「メタバース革命:私たちが知る銀行業界...
- 「LlamaIndex vs LangChain 比較分析」
- 「データサイエンスにおけるデータベース...
- AIは、人間の確証バイアスを克服できるか?
- 以下がSteamサマーセールのゲームをGeForc...
- 変形者への鎮魂曲?
- 「PEARLと出会ってください – 顧客...
- 「Llama 2が登場しました – Hugging...
- 「AI時代における学術的誠実性の再考:Cha...
- ハギングフェイスがIDEFICSを導入:視覚言...

Hugging Face Transformers と Amazon SageMaker を使用して、GPT-J 6B を推論のためにデプロイします
約6ヶ月前の今日、EleutherAIはGPT-3のオープンソースの代替となるGPT-J 6Bをリリースしました。GPT-J 6BはEleutherAIs GPT-NEOファミリーの6,000,000,000パラメータの後継モデルであり、テキスト生成のためのGPTアーキテクチャに基づくトランスフォーマーベースの言語モデルです。 EleutherAIの主な目標は、GPT-3と同じサイズのモデルを訓練し、オープンライセンスの下で一般の人々に提供することです。 過去6ヶ月間、GPT-Jは研究者、データサイエンティスト、さらにはソフトウェア開発者から多くの関心を集めてきましたが、実世界のユースケースや製品にGPT-Jを本番環境に展開することは非常に困難でした。 Hugging Face Inference APIやEleutherAIs 6b playgroundなど、製品ワークロードでGPT-Jを使用するためのホステッドソリューションはいくつかありますが、自分自身の環境に簡単に展開する方法の例は少ないです。 このブログ記事では、Amazon SageMakerとHugging Face Inference Toolkitを使用して、数行のコードでGPT-Jを簡単に展開する方法を学びます。これにより、スケーラブルで信頼性の高いセキュアなリアルタイムの推論が可能な通常サイズのNVIDIA T4(約500ドル/月)のGPUインスタンスを使用します。 しかし、それに入る前に、なぜGPT-Jを本番環境に展開するのが困難なのかを説明したいと思います。 背景 6,000,000,000パラメータモデルの重みは、約24GBのメモリを使用します。float32でロードするためには、少なくとも2倍のモデルサイズのCPU RAMが必要です。初期重みのために1倍、チェックポイントのロードのために1倍です。したがって、GPT-Jをロードするには少なくとも48GBのCPU RAMが必要です。 モデルをよりアクセス可能にするために、EleutherAIはfloat16の重みを提供しており、transformersには大規模な言語モデルのロード時のメモリ使用量を削減する新しいオプションがあります。これらすべてを組み合わせると、モデルのロードにはおおよそ12.1GBのCPU…

🤗 Transformersでn-gramを使ってWav2Vec2を強化する
Wav2Vec2は音声認識のための人気のある事前学習モデルです。2020年9月にMeta AI Researchによってリリースされたこの新しいアーキテクチャは、音声認識のための自己教師あり事前学習の進歩を促進しました。例えば、G. Ng et al.、2021年、Chen et al、2021年、Hsu et al.、2021年、Babu et al.、2021年などが挙げられます。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは現在、月間ダウンロード数25万以上です。 コネクショニスト時系列分類(CTC)を使用して、事前学習済みのWav2Vec2のようなチェックポイントは、ダウンストリームの音声認識タスクで非常に簡単にファインチューニングできます。要するに、事前学習済みのWav2Vec2のチェックポイントをファインチューニングする方法は次のとおりです。 事前学習チェックポイントの上にはじめに単一のランダムに初期化された線形層が積み重ねられ、生のオーディオ入力を文字のシーケンスに分類するために訓練されます。これは以下のように行います。 生のオーディオからオーディオ表現を抽出する(CNN層を使用する) オーディオ表現のシーケンスをトランスフォーマーレイヤーのスタックで処理する 処理されたオーディオ表現を出力文字のシーケンスに分類する 以前のオーディオ分類モデルでは、分類されたオーディオフレームのシーケンスを一貫した転写に変換するために、追加の言語モデル(LM)と辞書が必要でした。Wav2Vec2のアーキテクチャはトランスフォーマーレイヤーに基づいているため、各処理されたオーディオ表現は他のすべてのオーディオ表現から文脈を得ることができます。さらに、Wav2Vec2はファインチューニングにCTCアルゴリズムを利用しており、変動する「入力オーディオの長さ」と「出力テキストの長さ」の比率の整列の問題を解決しています。 文脈化されたオーディオ分類と整列の問題がないため、Wav2Vec2には受け入れ可能なオーディオ転写を得るために外部の言語モデルや辞書は必要ありません。 公式論文の付録Cに示されているように、Wav2Vec2は言語モデルを使用せずにLibriSpeechで印象的なダウンストリームのパフォーマンスを発揮しています。ただし、付録からも明らかなように、Wav2Vec2を10分間の転写済みオーディオのみで訓練した場合、言語モデルと組み合わせると特に改善が見られます。 最近まで、🤗 TransformersライブラリにはファインチューニングされたWav2Vec2と言語モデルを使用してオーディオファイルをデコードするための簡単なユーザーインターフェースがありませんでした。幸いにも、これは変わりました。🤗…

機械学習の専門家 – マーガレット・ミッチェル
みなさん、こんにちは!Machine Learning Expertsへようこそ。私は司会のBritney Mullerです。今日のゲストは、マーガレット・ミッチェル(通称メグ)です。メグはGoogleのEthical AIグループの創設者兼共同リーダーであり、機械学習の分野でのパイオニアであり、50以上の論文を発表しているだけでなく、Ethical AIの分野でのリーディングリサーチャーでもあります。 メグがエシカルAIの重要性に気づいた瞬間(素晴らしいストーリー!)、MLチームが有害なデータバイアスにより意識的になる方法、およびMLにおける包括性と多様性の力(およびパフォーマンスの利点)について話すことができます。 このパワフルなエピソードをご紹介できることをとても楽しみにしています!こちらがメグ・ミッチェルとの対談です: 転写: 注:転写はわかりやすい読みやすさを提供するためにわずかに修正/再フォーマットされています。 あなたの経歴とHugging Faceへの経緯について少し共有していただけますか? Dr. マーガレット・ミッチェルの経歴: Reed Collegeで言語学の学士号を取得 – NLPに取り組んだ 学士号取得後、補助および補完技術に取り組み、修士課程中も同様に研究 ワシントン大学で計算言語学の修士号を取得 コンピュータサイエンスの博士号を取得 メグ:私はJohns Hopkinsでポスドクとして統計的な研究を行い、その後、Microsoft Researchに移り、ビジョンから言語生成に取り組み、盲目の人々が世界をより簡単に移動できるようにするSeeing…
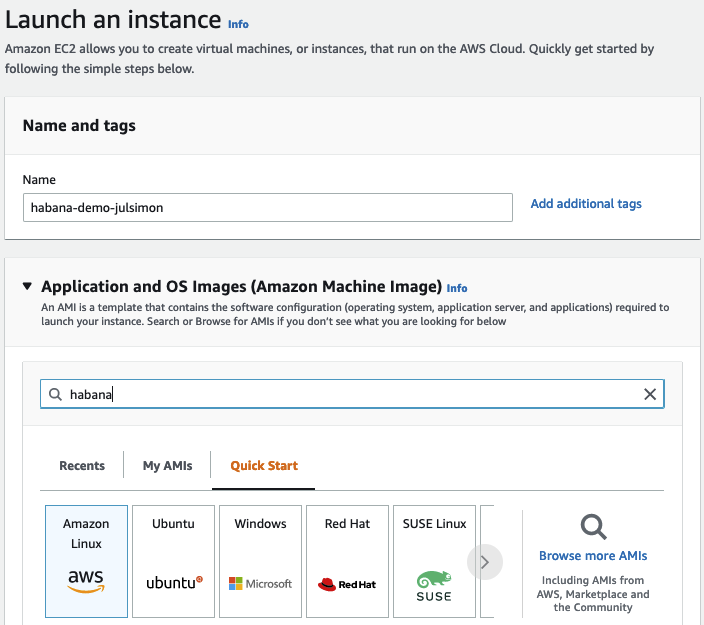
Habana GaudiでのTransformersの始め方
数週間前に、Habana LabsとHugging Faceが協力してTransformerモデルのトレーニングを加速することを発表できたことを喜んでお知らせいたします。 Habana Gaudiアクセラレータは、最新のGPUベースのAmazon EC2インスタンスと比較して、機械学習モデルのトレーニングにおいて最大40%の価格パフォーマンス向上を提供します。私たちはこの価格パフォーマンスの利点をTransformersにもたらすことに非常に興奮しています🚀 この実践的な投稿では、Amazon Web ServicesでHabana Gaudiインスタンスを素早くセットアップし、テキスト分類用にBERTモデルを微調整する方法を紹介します。通常どおり、コードはすべて提供されているため、プロジェクトで再利用できます。 さあ、始めましょう! AWSでHabana Gaudiインスタンスをセットアップする Habana Gaudiアクセラレータを使用する最も簡単な方法は、Amazon EC2 DL1インスタンスを起動することです。これらのインスタンスには、Habana SynapseAI® SDKがプリインストールされたHabana Deep Learning Amazon Machine Image(AMI)が搭載されています。また、GaudiアクセラレーションされたDockerコンテナを実行するために必要なツールも含まれています。他のAMIやコンテナを使用したい場合は、Habanaのドキュメントに手順が記載されています。…

機械学習インサイトディレクター【パート3:ファイナンスエディション】
もしMLソリューションをより速く構築したい場合は、hf.co/supportを今すぐご覧ください! 👋 MLインサイトシリーズディレクター、ファイナンスエディションへようこそ!以前のエディションを見逃した場合は、以下で見つけることができます: Machine Learning Insightsディレクター[パート1] Machine Learning Insightsディレクター[パート2:SaaSエディション] ファイナンスの機械学習ディレクターは、レガシーシステムの航海、解釈可能なモデルの展開、および顧客の信頼の維持といった独自の課題に直面しています。また、政府の監督が多く、高度に規制されています。これらの課題には、効果的に導くために深い業界知識と技術的な専門知識が必要です。以下のアメリカン・バンク、カナダ王立銀行、ムーディーズ・アナリティクス、および元ブルームバーグAIの研究科学者からの専門家は、機械学習×ファイナンスセクター内のユニークな知見を提供しています。 ギリシャのナショナルジュニアテニスチャンピオン、100以上の特許を取得した出版者、世界最古のポロクラブ(カルカッタポロクラブ)で定期的にプレーしていたサイクルポロプレーヤーなど、彼らはすべて金融MLの専門家に転身しました。 🚀 トップな金融MLマーベリックからの洞察をご紹介します: 免責事項:すべての意見は個人のものであり、過去または現在の雇用主からのものではありません。 イオアニス・バカギアニス – RBCの機械学習マーケティングサイエンスディレクター バックグラウンド:スケーラブルな、本番用の最先端の機械学習ソリューションを提供する経験豊富な情熱的な機械学習エキスパート。イオアニスはまた、Bak Up Podcastのホストでもあり、AIを通じて世界に影響を与えることを目指しています。 おもしろい事実:イオアニスはギリシャのナショナルジュニアテニスチャンピオンでした。🏆 RBC:世界的な組織は、キャピタルマーケット、銀行および金融において革新的かつ信頼できるパートナーとしてRBCキャピタルマーケットを見ています。 1. 機械学習が金融にどのようなポジティブな影響をもたらしましたか?…

プライベートハブのご紹介:機械学習を活用した新しいビルド方法
機械学習は、企業が技術を構築する方法を変えつつあります。革新的な新製品のパワーを供給し、私たちが使い慣れて愛している既知のアプリケーションにスマートな機能を提供することから、MLは開発プロセスの中心にあります。 しかし、すべての技術の変化には新たな課題が伴います。 機械学習モデルの約90%が本番環境に到達しないとされています。馴染みのないツールや非標準的なワークフローがMLの開発を遅くしています。モデルやデータセットが内部で共有されないため、同じような成果物がチーム間で常にゼロから作成されます。データサイエンティストは、ビジネスステークホルダーに技術的な作業を示すのが難しく、正確でタイムリーなフィードバックを共有するのに苦労しています。そして、機械学習チームはDocker/Kubernetesや本番環境向けのモデル最適化に時間を浪費しています。 これらを考慮して、私たちはPrivate Hub(PH)を立ち上げました。機械学習の構築方法を革新する新しい方法です。研究から本番環境まで、セキュアかつコンプライアンスを確保しながら、機械学習ライフサイクルの各ステップを加速するための統合されたツールセットを提供します。PHはさまざまなMLツールを一つにまとめることで、機械学習の協力をよりシンプルで楽しく、生産的にします。 このブログ投稿では、Private Hubとは何か、なぜ役立つのか、そしてどのようにお客様がそれを使用してMLのロードマップを加速しているのかについて詳しく説明します。 一緒に読んでいただくか、興味を引くセクションにジャンプしてください 🌟: ハグフェースハブとは何ですか? プライベートハブとは何ですか? 企業はプライベートハブをどのように使用してMLのロードマップを加速しているのでしょうか? さあ、始めましょう! 🚀 1. ハグフェースハブとは何ですか? プライベートハブについて詳しく説明する前に、まずハグフェースハブについて見てみましょう。これはPHの中心的な要素です。 ハグフェースハブは、オープンソースで公開されているオンラインプラットフォームで、人々が簡単に協力してMLを構築できる場所です。ハブは、機械学習と一緒に技術を探求し、実験し、協力し、構築するための中心的な場所として機能します。 ハグフェースハブでは、次のようなMLアセットを作成または発見することができます: モデル:NLP、コンピュータビジョン、音声、時系列、生物学、強化学習、化学などの最新の最先端モデルをホスティング。 データセット:さまざまなドメイン、モダリティ、言語に対応したデータの幅広いバリエーション。 スペース:ブラウザ内で直接MLモデルをショーケースするインタラクティブなアプリ。 ハブにアップロードされた各モデル、データセット、またはスペースは、Gitベースのリポジトリです。これはすべてのファイルを含むバージョン管理された場所で、従来のgitコマンドを使用してファイルをプル、プッシュ、クローン、操作することができます。モデル、データセット、およびスペースのコミット履歴を表示し、誰がいつ何を行ったかを確認することができます。 モデルのコミット履歴…

ディープダイブ:Hugging Face Optimum GraphcoreにおけるビジョンTransformer
このブログ投稿では、Hugging Face Optimumライブラリを使用して、事前学習済みのTransformerモデルをあなたのデータセットに簡単に微調整する方法をGraphcoreのIntelligence Processing Units(IPUs)で紹介します。例として、大規模で広く使用されている胸部X線データセットを取り上げ、ビジョンTransformer(ViT)モデルを訓練する手順とノートブックを提供します。 ビジョンTransformer(ViT)モデルの紹介 2017年、GoogleのAI研究者グループがTransformerモデルアーキテクチャを紹介する論文を発表しました。Transformerは新しいセルフアテンションメカニズムによって特徴付けられ、言語アプリケーションのための新しい効率的なモデルのグループとして提案されました。実際、過去5年間でTransformerは爆発的な人気を見ており、自然言語処理(NLP)の事実上の標準として受け入れられています。 言語のためのTransformerは、急速に進化するGPTとBERTモデルファミリーによって特に代表されています。両方とも、Hugging Face Optimum Graphcoreライブラリの一部としてGraphcore IPUs上で簡単かつ効率的に実行することができます。 Transformerモデルアーキテクチャの詳細な説明(NLPに焦点を当てたもの)は、Hugging Faceのウェブサイトで見つけることができます。 Transformerは言語で初期の成功を収めましたが、非常に多目的であり、このブログ投稿でカバーするように、コンピュータビジョン(CV)などのさまざまな目的に使用することができます。 CVは、畳み込みニューラルネットワーク(CNN)が間違いなく最も人気のあるアーキテクチャの1つです。しかし、ビジョンTransformer(ViT)アーキテクチャは、Google Researchが2021年の論文で初めて紹介された画像認識のブレークスルーであり、BERTやGPTと同じセルフアテンションメカニズムを主要なコンポーネントとして使用しています。 BERTや他のTransformerベースの言語処理モデルは、文(つまり単語のリスト)を入力として受け取りますが、ViTモデルは入力画像をいくつかの小さなパッチに分割し、言語処理における個々の単語に相当するものにします。各パッチは、Transformerモデルによって線形にエンコードされ、個別に処理できるベクトル表現に変換されます。この画像をパッチやビジュアルトークンに分割するアプローチは、CNNが使用するピクセル配列とは対照的です。 事前学習により、ViTモデルは画像の内部表現を学習し、それを下流タスクに役立つ視覚的な特徴を抽出するために使用できます。たとえば、事前学習されたビジュアルエンコーダの上に線形層を配置することで、新しいラベル付き画像データセットで分類器を訓練することができます。通常、[CLS]トークンの上に線形層を配置します。このトークンの最後の隠れ状態は、画像全体の表現と見なすことができます。 CNNと比較して、ViTモデルはより高い認識精度を持ちながら、より低い計算コストで動作し、画像分類、物体検出、セグメンテーションなどのさまざまなアプリケーションに適用されています。医療領域のユースケースには、COVID-19、大腿骨骨折、肺気腫、乳がん、アルツハイマー病などの検出と分類などが含まれます。 ViTモデル – IPUに最適なモデル GraphcoreのIPUは、データパイプライニングとモデル並列処理の組み合わせを使用して、ViTモデルに特に適しています。この大規模並列プロセスの高速化は、IPUのMIMDアーキテクチャとIPU-Fabricを中心としたスケールアウトソリューションによって可能になっています。…

最初のデシジョン トランスフォーマーをトレーニングする
以前の投稿で、transformersライブラリでのDecision Transformersのローンチを発表しました。この新しい技術は、Transformerを意思決定モデルとして使用するというもので、ますます人気が高まっています。 今日は、ゼロからオフラインのDecision Transformerモデルをトレーニングして、ハーフチータを走らせる方法を学びます。このトレーニングは、Google Colab上で直接行います。こちらで見つけることができます👉 https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb *ジムのHalfCheetah環境でオフラインRLを使用して学習された「専門家」Decision Transformersモデルです。 ワクワクしませんか?では、始めましょう! Decision Transformersとは何ですか? Decision Transformersのトレーニング データセットの読み込みとカスタムデータコレータの構築 🤗 transformers Trainerを使用したDecision Transformerモデルのトレーニング 結論 次は何ですか? 参考文献 Decision Transformersとは何ですか? Decision…

Megatron-LMを使用して言語モデルをトレーニングする方法
PyTorchで大規模な言語モデルをトレーニングするには、単純なトレーニングループだけでは不十分です。通常、複数のデバイスに分散しており、安定した効率的なトレーニングのための多くの最適化技術があります。Hugging Face 🤗 Accelerateライブラリは、トレーニングループに非常に簡単に統合できるように、GPUとTPUを跨いで分散トレーニングをサポートするために作成されました。🤗 TransformersもTrainer APIを介して分散トレーニングをサポートしており、トレーニングループの実装を必要とせずにPyTorchでの完全なトレーニングを提供します。 大規模なトランスフォーマーモデルを事前トレーニングするための研究者の間でのもう一つの人気ツールはMegatron-LMです。これはNVIDIAのApplied Deep Learning Researchチームによって開発された強力なフレームワークです。🤗 AccelerateとTrainerとは異なり、Megatron-LMの使用は直感的ではなく、初心者には少し抵抗があるかもしれません。しかし、これはGPU上でのトレーニングに最適化されており、いくつかの高速化を提供することができます。このブログ記事では、Megatron-LMを使用してNVIDIAのGPU上で言語モデルをトレーニングし、それをtransformersと一緒に使用する方法を学びます。 このフレームワークでGPT2モデルをトレーニングするためのさまざまなステップを紹介します。これには以下が含まれます。 環境のセットアップ データの前処理 トレーニング モデルの🤗 Transformersへの変換 なぜMegatron-LMを選ぶのか? トレーニングの詳細に入る前に、他のフレームワークよりもこのフレームワークが効率的である理由を理解しましょう。このセクションは、Megatron-DeepSpeedでのBLOOMトレーニングについての素晴らしいブログから着想を得ています。詳細については参照してください。このブログ記事はMegatron-LMへの優しい入門を提供することを目的としています。 データローダー Megatron-LMには、データがトークン化され、トレーニング前にシャッフルされる効率的なデータローダーが付属しています。また、データは番号付きのシーケンスに分割され、それらは計算が必要な場合にのみ計算されるようにインデックスで保存されます。インデックスを作成するために、エポック数はトレーニングパラメータに基づいて計算され、順序が作成され、その後シャッフルされます。これは通常の場合とは異なり、データセット全体を繰り返し処理してから2番目のエポックのために繰り返すというものです。これにより、学習曲線が滑らかになり、トレーニング中の時間が節約されます。 組み込みCUDAカーネル GPU上で計算を実行する場合、必要なデータはメモリから取得され、計算が実行され、結果がメモリに保存されます。簡単に言えば、組み込みカーネルのアイデアは、通常はPyTorchによって別々に実行される類似の操作を、単一のハードウェア操作に統合することです。そのため、複数の個別の計算で行われるメモリ移動の回数を減らします。以下の図は、カーネルフュージョンのアイデアを示しています。これは、詳細について説明しているこの論文からインスピレーションを受けています。 f、g、hが1つのカーネルで結合された場合、fとgの中間結果x’とy’はGPUレジスタに保存され、hによって即座に使用されます。しかし、フュージョンがない場合、x’とy’はメモリにコピーされ、hによって読み込まれる必要があります。したがって、カーネルフュージョンは計算に著しいスピードアップをもたらします。Megatron-LMはまた、PyTorchの実装よりも高速なApexのFused…

🤗 Accelerateは、PyTorchのおかげで非常に大規模なモデルを実行する方法です
大規模モデルの読み込みと実行 Meta AIとBigScienceは最近、ほとんどの一般的なハードウェアのメモリ(RAMまたはGPU)に収まらない非常に大きな言語モデルをオープンソース化しました。Hugging Faceでは、私たちの使命の一部として、それらの大きなモデルにアクセスできるようにするためのツールを開発しました。そのため、スーパーコンピュータを所有していなくても、これらのモデルを実行できるようにするためのツールを開発しました。このブログ投稿で選ばれたすべての例は、無料のColabインスタンス(制限付きのRAMとディスク容量)で実行されます。ディスク容量に余裕がある場合は、より大きなチェックポイントを選択することもできます。 ここでは、OPT-6.7Bを実行する方法を示します: import torch from transformers import pipeline # これは基本的なColabインスタンスで動作します。 # もし時間がかかっても待つ時間と十分なディスク容量がある場合は、より大きなチェックポイントを選択してください! checkpoint = "facebook/opt-6.7b" generator = pipeline("text-generation", model=checkpoint, device_map="auto", torch_dtype=torch.float16)…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.