Learn more about Search Results モード - Page 40

- You may be interested
- 「中国、顔認識技術の規制案を作成」
- データサイエンスのキャリアに転身する際...
- 高度なプロンプトエンジニアリング
- Hugging FaceとAWSが協力し、AIをよりアク...
- ネットワーキングの下手さをやめてくださ...
- ベクトルデータベースについてのすべて &#...
- 「日常生活における人工知能の役割に対す...
- アラゴンAIレビュー:2023年における究極...
- ハイパーパラメータの調整:ニューラルネ...
- 「AutoGenを使った戦略的AIチームビルディ...
- AlphaFold 生物学における50年間の偉大な...
- 「高次元のカテゴリ変数に対する混合効果...
- 「スノーフレーク vs データブリックス:...
- 「AIはほとんどのパスワードを1分以内に解...
- AI音声認識をUnityで

「Java ZGCアルゴリズムのチューニング」
ZGCは、Javaアプリケーションにおいて大きなヒープを管理し、一時停止を最小限に抑えることに特化したガベージコレクターです詳細はこちらをご覧ください!

2023年のYouTuberに最適なAIツール
VidIQ VidIQは、YouTubeのビデオメーカーに知恵を絞ったツールのアーセナルを提供するオンラインサービスです。VidIQのYouTubeコーチは、ChatGPTのパワーを活用して、必要なときに適切な指導を受けることができます。この先端的な機能は、VidIQとChatGPTを統合し、YouTubeチャンネルに基づいた最適なガイダンスをプロデューサーに提供します。VidIQは、コンテンツのアイデア出しやチャンネルの監査を手助けする制作チームとして機能します。スイート内には、自動的にYouTubeのベストプラクティスと視聴予測アルゴリズムを活用して、ビデオの注目を集めるタイトルを作成するためのYouTubeビデオタイトルジェネレーターも含まれています。AIはVidIQのYouTubeチャンネル名ジェネレーターのパワーを活用し、ユーザーがチャンネルの名前をユニークかつ記憶に残るものに作成するのを助けます。VidIQは、より良い検索エンジンのランキングを得るために、チャンネル名、ビデオタイトル、および説明に関連するキーワードを使用することをおすすめします。 Explore AI Explore AIは、AIによって駆動されたYouTube専用のビデオ検索エンジンです。このサイトでは、数多くの役立つYouTubeチャンネル、高品質なポッドキャスト、およびテクノロジー業界の有名人が紹介されています。その最も重要な目標は、検索可能なコンテンツの範囲を広げることであり、その意味的な検索機能により正確な結果を保証しています。Exploring AIは、GPT-3を使用してYouTubeのビデオの詳細な要約、正確なタイムスタンプ、および正確なトランスクリプトを提供します。これらのツールセットは、さまざまなユーザーの要求に応えるために、コンテンツのアクセシビリティと理解力を向上させます。 Vidds Viddsは、あらゆる種類のコンテンツクリエーター向けのAIを活用したビデオ編集プラットフォームです。このプラットフォームでは、プロフェッショナルグレードで使いやすいAI駆動のビデオ編集ツールにアクセスできます。ChatGPT対応のアイデアジェネレーターは、ユーザーがキーワードやフレーズを提供することに基づいてビデオのスクリプトを作成します。ソフトウェアは、ユーザーが選んだ任意のトピックで簡単かつ迅速に完成したビデオを作成することができます。 Rotor Rotorは、アーティストのためにビデオ制作プロセスを簡素化し、ビデオ編集や制作のエキスパートになることなく高品質な映画を作成できるようにするユーザーフレンドリーなプラットフォームです。作成者は、プロフェッショナルなクオリティのビデオを簡単かつ迅速に作成するための専門知識を持たなくても大丈夫です。音楽リリースのプロモーションは、個人がさまざまな魅力的なビデオ素材を簡単に作成できるシンプルさによってサポートされています。Rotorの強力なエンジンは、音楽と選択した映像を分析し、あなたの曲に合った素早くカットされた専門的な映画の作成プロセスを加速します。 Vidyo Vidyoは、ソーシャルメディアで共有するための魅力的なショートフィルムを作成するプロセスを効率化するAIパワードツールです。Vidyoを使用すると、ユーザーは長い映画をTikTok、Instagram、YouTube、LinkedIn、Facebookなどのサービスで共有するために適したエンターテイニングなスニペットに短縮することができます。そのAI駆動技術により、ユーザーは長い映画をトリミングし、解説、テンプレート、絵文字などの注目を集める要素を追加して、短く魅力的なビデオを作成することができます。最も興味深い部分は、アルゴリズムによって自動的に選択され、編集され、キャプションが付けられます。 Wave Video Wave Videoは、人工知能に基づいたビデオ制作および編集システムです。ビデオ制作、編集、サムネイル作成、ビデオホスティング、ビデオ録画、メディアライブラリなど、統合された直感的な環境を提供しています。ライブストリーミング、ビデオ編集、サムネイル作成、ビデオホスティング、ビデオ録画、メディアライブラリなど、ユーザーがサイトでアクセスできるツールの一部です。Wave Videoのユーザーは、簡単に映画をスケーリング、切り取り、マージすることができます。テキストアニメーション、ステッカー、トランジション、カスタムビジュアルエレメントなどが、ユーザーが作成したビデオを引き立てることができます。ソフトウェアはまた、ユーザーが自分の字幕を追加したり、システムが生成した字幕を変更したりしてアクセシビリティとユーザーエクスペリエンスを向上させることも可能です。ユーザーはレイアウトを変更したり、タイトルを追加したり、背景を削除したりするオプションもあります。 YouTube Summarized YouTube Summarizedは、ビデオを簡潔に要約するための迅速で簡単な方法を提供するAI駆動のサービスです。YouTubeで映画を視聴する際に詳細なノートを作成するための強力なツールも搭載されています。ユーザーは、様々なYouTubeのビデオやポッドキャストの詳細な要約を自動的に作成するツールを使用することができます。YouTube Summarizedのクレジットベースの方法により、ユーザーは定期的に支払う必要はありません。これにより、ユーザーはクレジット残高を最大限に活用して、自分に最も適した方法で利用することができ、最終的には自分の体験を向上させることができます。ユーザーは、30日間の返金保証があるため、プラットフォームをリスクフリーで試すことができます。 YT…

CycleGANによる画像から画像への変換
イントロダクション 人工知能とコンピュータビジョンの領域において、CycleGANは画像の認識と操作方法を再定義した素晴らしいイノベーションです。この先端技術は、馬をシマウマに変換したり、夏の風景を雪景色に変換したりするなど、ドメイン間のシームレスな変換を可能にしました。本記事では、CycleGANの魔法と、さまざまなドメインでの応用について探求します。 学習目標 CycleGANのコンセプトと革新的な双方向画像変換手法。 CycleGANのジェネレータネットワーク(G_ABとG_BA)のアーキテクチャ、ディスクリミネータネットワーク(D_AとD_B)の設計、およびトレーニングにおける役割。 CycleGANの現実世界での応用例には、スタイル変換、ドメイン適応、季節の変遷、都市計画などがあります。 CycleGANの実装時に直面する課題には、変換品質とドメインのシフトがあります。 CycleGANの機能を向上させるための可能な将来の方向。 この記事はData Science Blogathonの一環として公開されました。 CycleGANとは何ですか? CycleGAN(サイクルコンシステントジェネレーティブアドバーサリーネットワーク)は、教師なしの画像変換を容易にする新しいディープラーニングアーキテクチャです。従来のGANは、ジェネレータとディスクリミネータを最小最大ゲームで対決させますが、CycleGANは巧妙な仕掛けを導入しています。一方向の変換を目指すのではなく、CycleGANは対になったトレーニングデータに依存せずに、2つのドメイン間で双方向マッピングを達成することに焦点を当てています。つまり、CycleGANはドメインAからドメインBへの画像変換だけでなく、重要なのはドメインBからドメインAへの逆変換も行い、画像がサイクルを通じて一貫性を保つことを確認します。 CycleGANのアーキテクチャ CycleGANのアーキテクチャは、ドメインAからドメインBへの画像変換とその逆を担当する2つのジェネレータ、G_AとG_B、そしてそれぞれのドメインの実際の画像と変換された画像の本物かどうかを評価する2つのディスクリミネータ、D_AとD_B、という特徴があります。敵対的なトレーニングにより、ジェネレータはターゲットドメインの実際の画像と区別がつかないような画像を生成するように強制されます。また、サイクル一貫性の損失は、双方向変換後に元の画像を再構築できるようにします。 CycleGANを使用した画像から画像への変換の実装 # ライブラリのインポート import tensorflow as tf import tensorflow_datasets…

「開発チームのためのAIツール 採用するべきか否か?」
「AIツールがより人気になるにつれて、それを導入する際のリスクと利点を知ることが重要ですCodiumAIのイタマール・フリードマンがDev Interruptedに参加し、お手伝いします」

「簡単な英語プロンプトでLLMをトレーニング!gpt-llm-trainerと出会って、タスク固有のLLMをトレーニングする最も簡単な方法」
大規模な言語モデル(LLM)と呼ばれるAIの形式は、人間と同等のテキストを生成することが証明されています。しかし、LLMの訓練は、高性能のコンピュータと膨大なデータの必要性を伴う、リソースを多く消費する操作です。 gpt-llm-trainerは、ローカルマシン上でLLMのトレーニングを容易にするプログラムです。GPT-4言語モデルを使用して、ユニークなLLMを訓練し、質問と回答のデータセットを生成します。このソフトウェアはまた、テキスト生成、言語翻訳、クリエイティブライティングなどの特定の目標に対してモデルを微調整することも可能です。 gpt-llm-trainerの特徴は次のとおりです: 指定されたユースケースを使用して、get-llm-trainerはGPT-4を使用して、幅広い質問と回答を含むデータセットを生成します。その結果、手作業でデータを収集する時間を節約することができます。 モデルに対して効率的なシステムメッセージを生成するために、get-llm-trainerはシステムプロンプトを生成することができます。これにより、モデルがユーザーの入力とその結果の行動を正確に解釈することができます。 データセットがトレーニングセットとバリデーションセットに自動的に分割された後、システムはモデルを微調整し、推論の準備を行います。そのため、モデルを手作業で微調整する時間を節約することができます。 gpt-llm-trainerはクラウドとコンピュータのハードドライブの両方で動作します。この柔軟性により、さまざまな予算でLLMをトレーニングするための有用なリソースとなります。 gpt-llm-trainerは、自分のLLMをトレーニングしたい人にとって優れたリソースです。学習曲線が低く、多機能であり、オンプレミスとリモートサーバーの両方と互換性があります。 gpt-llm-trainerの使用例は次のとおりです: 記事、ブログ投稿、オリジナルの散文などを、gpt-llm-trainerの助けを借りて生成することができます。 gpt-llm-trainerは、翻訳においてさまざまな話される言語や方言の間を変換することができます。 詩、コード、スクリプト、楽曲、メール、手紙など、クリエイティブなコンテンツの作成には、gpt-llm-trainerの助けがあります。 問い合わせがオープンエンド、困難であるか、または奇妙である場合でも、get-llm-trainerは有用な応答を提供することができます。 要約、質問応答、自然言語推論に加えて、gpt-llm-trainerには多くの潜在的な応用があります。 制限事項 get-llm-trainerは進行中の作業のため、いくつかの既知の制限事項があります。生成されたコンテンツは必ずしも真実である必要はなく、文法的にも正しいとは限りません。また、訓練手順は計算資源と時間を消費する場合があります。 まとめると、get-llm-trainerはLLMをトレーニングするための強力なツールです。さまざまな機能をサポートし、非常に使いやすいです。ただし、ツールを使用する前に制限事項を知っておく必要があります。

「目指すべき人工知能の高収入の仕事6選」
AIと就職市場に関連する否定的なニュースが多く報道されていますが、多くの人々が見逃しているのは、AIがどのように変革し、新たな高収入の人工知能の仕事を創造しているかということです一部の職種は要件を満たすためには...

「GPT-5がOpenAIによって商標登録されました:それがChatGPTの未来について何を示しているのでしょうか?」
「GPT-5とは何ですか?また、OpenAIがなぜそれに商標を取得したのでしょうか?人工一般知能(AGI)に向けた次のステップとなる可能性のあるマルチモーダルAIについて調べてみましょうこの記事を読んで、GPT-5およびその商標の潜在的な機能、課題、および影響について詳しく知りましょう」

「生成AIの布地を調整する:FABRICは反復的なフィードバックで拡散モデルを個別化するAIアプローチです」
ジェネラティブAIは、今では私たち全員が馴染みのある用語です。最近、彼らは大きく進化し、多くのアプリケーションで重要なツールとなっています。 ジェネラティブAIの主役は拡散モデルです。これらは強力なジェネラティブモデルの一種として登場し、画像合成や関連するタスクを革新しています。これらのモデルは、高品質かつ多様な画像を生成することで、驚異的なパフォーマンスを示しています。GANやVAEなどの従来のジェネラティブモデルとは異なり、拡散モデルはノイズ源を反復的に洗練することで、安定した一貫した画像生成を実現しています。 拡散モデルは、トレーニング中の高品質な画像生成とモードの崩壊の削減において、大きな注目を集めています。これにより、画像合成、インペイント、スタイル転送など、さまざまなドメインでの広範な採用と応用が実現されています。 しかし、完璧ではありません。印象的な能力にも関わらず、拡散モデルの課題の1つは、テキストの説明に基づいてモデルを特定の望ましい出力に効果的に誘導することです。テキストのプロンプトを通じて好みを正確に説明することは通常困難であり、時には不十分であったり、モデルがそれらを無視し続けることもあります。そのため、通常は生成された画像を洗練させて利用可能にする必要があります。 しかし、あなたはモデルに何を描かせたいのかを知っています。したがって、理論的には、生成された画像の品質、それが想像にどれだけ近いかを評価するのに最適な人物です。私たちが見たいものをモデルが理解できるように、このフィードバックを画像生成パイプラインに統合できればどうでしょうか?それでは、FABRICに出会う時がきました。 FABRIC(Attention-Based Reference Image Conditioningを介したフィードバック)は、拡散モデルの生成プロセスに反復的なフィードバックの統合を可能にする新しいアプローチです。 FABRICは、ユーザーフィードバックに基づいて機能します。出典: https://arxiv.org/pdf/2307.10159.pdf FABRICは、以前の世代または人間の入力から収集された肯定的および否定的なフィードバック画像を利用します。これにより、将来の結果を洗練するためにリファレンスイメージを利用した調整が可能となります。この反復的なワークフローにより、ユーザーの好みに基づいて生成された画像を微調整し、より制御可能かつインタラクティブなテキストから画像への生成プロセスを提供します。 FABRICは、ControlNetに触発されており、リファレンスイメージに似た新しい画像を生成する能力を導入しました。 FABRICは、U-Net内の自己注意モジュールを活用し、画像内の他のピクセルに「注意」を向け、リファレンスイメージから追加情報を注入することができます。リファレンスイメージを通過させて、Stable DiffusionのU-Netを介してキーと値を計算し、これらのキーと値をU-Netの自己注意層に保存することで、ノイズ除去プロセスがリファレンスイメージに注意を向け、意味情報を組み込むことができます。 FABRICの概要。出典: https://arxiv.org/pdf/2307.10159.pdf さらに、FABRICは、マルチラウンドの肯定的および否定的なフィードバックを組み込むために拡張されており、好きな画像と嫌いな画像ごとに別々のU-Netパスが実行され、フィードバックに基づいて注目スコアが再重み付けされます。フィードバックプロセスは、ノイズ除去ステップに従ってスケジュールされるため、生成された画像の反復的な洗練が可能となります。

実験から展開へ:MLflow 101 | パート02
こんにちは👋、そしてこのブログの第2セグメントへの暖かい歓迎です!もし最初から一緒にいてくれたなら、最初の部分では…
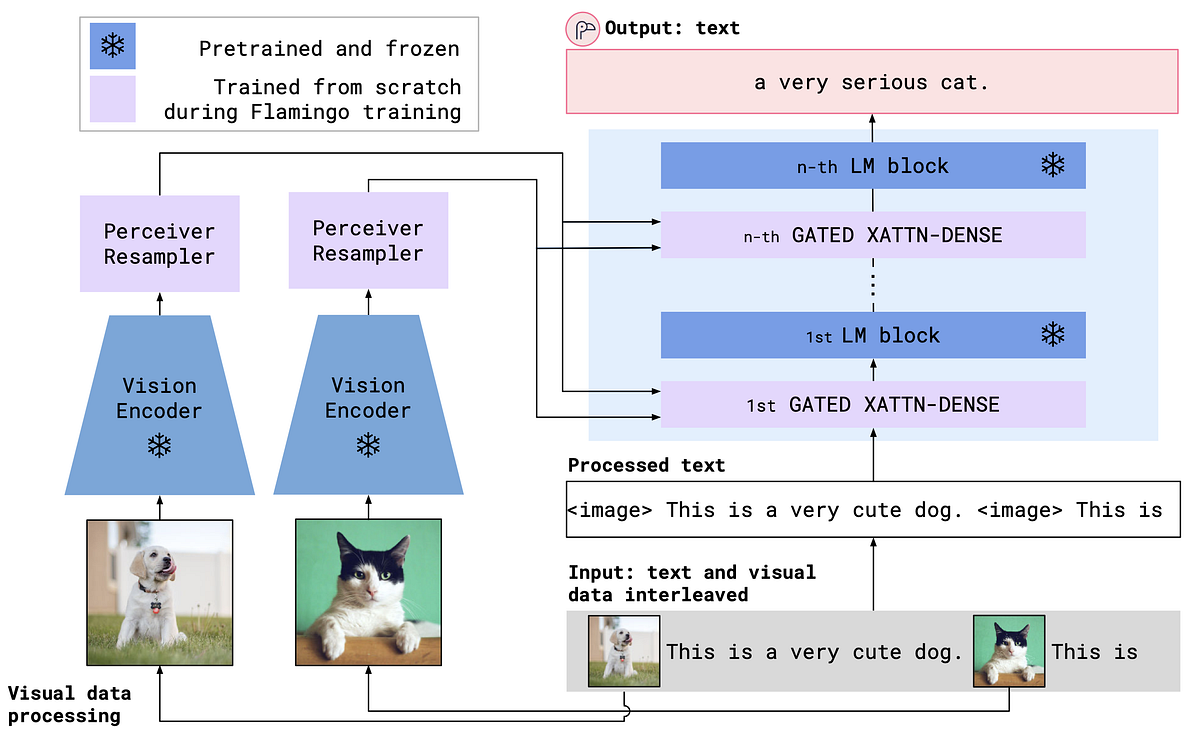
マルチモーダル言語モデルの解説:ビジュアル指示の調整
「LLMは、多くの自然言語タスクでゼロショット学習とフューショット学習の両方で有望な結果を示していますしかし、LLMは視覚的な推論を必要とするタスクにおいては不利です...」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.