Learn more about Search Results Word2vec - Page 3

- You may be interested
- 「洞察を求める詩的な探求としてのインデ...
- 「誰がどの役職を担当しますか?AIの視点...
- 「生成AIの風景を探索する」
- 「OpenAIが著者の許可なく彼らの著書を使...
- Google Cloudを使用してレコメンドシステ...
- 不動産業界におけるAIの活用法
- (Donna data no shigoto demo ukeru to iu...
- 「Pythonを使ったバックトラックの理解:...
- 「大きな言語モデルの操作(LLMOps)とは...
- NVIDIAはAI市場で権力を乱用しているのか...
- チャットGPT vs Gemini:AIアリーナでのタ...
- 「LangChainとOpenAI GPTを使用して初めて...
- モンテカルロ近似法:どれを選び、いつ選...
- 世界的な障壁を取り払ってアクセスを可能...
- 「AIネットワークは攻撃に対して脆弱性が...

「ワードエンベディング:より良い回答のためにチャットボットに文脈を与える」
ワードエンベディングとChatGPTを使用してエキスパートボットを構築する方法を学びましょうワードベクトルの力を活用して、チャットボットの応答を向上させましょう
「GenAIソリューションがビジネス自動化を革新する方法:エグゼクティブ向けLLMアプリケーションの解説」
最近、バイオファーマ企業の製造エグゼクティブとの協力により、私たちは生成型AI、具体的には大規模な言語モデル(LLM)の世界に深く入り込み、それらがどのように利用できるかを探求しました...
トランスフォーマーにおけるアテンションの説明【エンコーダーの観点から】
この記事では、特にエンコーダの視点から、トランスフォーマーネットワークにおけるアテンションの概念について詳しく掘り下げます以下のトピックをカバーします ...を見ていきます

自然言語処理のための高度なガイド
イントロダクション 自然言語処理(NLP)の変革的な世界へようこそ。ここでは、人間の言語の優雅さが機械の知能の正確さと出会います。NLPの見えない力は、私たちが頼りにしているデジタルのインタラクションの多くを支えています。このナチュラルランゲージプロセッシングガイドは、あなたの質問に応答するチャットボット、意味に基づいて結果を調整する検索エンジン、声のアシスタントがリマインダーを設定するなど、さまざまなアプリケーションで使用されます。 この包括的なガイドでは、ビジネスを革新しユーザーエクスペリエンスを向上させる、最先端のNLPの応用について掘り下げていきます。 文脈埋め込みの理解: 単語は単なる分離された単位ではありません。文脈によってその意味が変わります。Word2Vecのような静的な埋め込みから文脈を必要とする対話型な埋め込みまで、埋め込みの進化について見ていきます。 トランスフォーマーとテキスト要約の技術: 要約は単なるテキストの切り詰めを超える難しい仕事です。トランスフォーマーアーキテクチャとT5などのモデルについて学び、成功する要約の基準がどのように変わっているかを理解しましょう。 深層学習の時代には、層や複雑さのために感情を分析することは困難です。特にトランスフォーマーアーキテクチャに基づく深層学習モデルは、これらの複雑な層を解釈することに長けており、より詳細な感情分析を提供します。 有用な洞察を得るために、Kaggleのデータセット ‘Airline_Reviews’ を使用します。このデータセットには実世界のテキストデータが含まれています。 学習目標 ルールベースのシステムから深層学習アーキテクチャへの移行を認識し、特に転換の重要な瞬間に重点を置きます。 Word2Vecなどの静的単語表現から動的な文脈埋め込みへのシフトについて学び、言語理解における文脈の重要性を強調します。 トランスフォーマーアーキテクチャの内部構造と、T5などのモデルがテキスト要約を革新している方法について詳しく学びます。 特にトランスフォーマーベースのモデルなどの深層学習を活用して、テキストの感情に具体的な洞察を提供できるかを発見します。 この記事はデータサイエンスブログマラソンの一部として公開されました。 NLPの深い探求 自然言語処理(NLP)は、機械に人間の言語を理解し、解釈し、応答することを教える人工知能の分野です。この技術は、人間とコンピュータをつなげ、より自然なインタラクションを可能にします。スペルチェックやキーワード検索などの簡単なタスクから、機械翻訳、感情分析、チャットボットの機能などのより複雑な操作まで、さまざまなアプリケーションでNLPを使用できます。これにより、音声アクティベーションされた仮想アシスタント、リアルタイム翻訳サービス、さらにはコンテンツ推奨アルゴリズムなどが機能することが可能になります。自然言語処理(NLP)は、言語学、コンピュータサイエンス、機械学習の知識を結集し、テキストデータを理解できるアルゴリズムを作成することで、現代のAIアプリケーションの基盤となっています。 NLPの技術の進化 NLPはこれまでに大きく進化し、ルールベースのシステムから統計モデル、そして最近では深層学習へと進化してきました。言語の特異性を捉えるための旅は、従来の袋状モデルからWord2Vec、そして文脈埋め込みへの変化によって見ることができます。計算能力とデータの利用可能性が向上するにつれて、NLPは言語の微妙なニュアンスを理解するために洗練されたニューラルネットワークを使用するようになりました。現代の転移学習の進歩により、モデルは特定のタスクを改善し、実世界のアプリケーションでの効率と正確性を確保することができます。 トランスフォーマーの台頭 トランスフォーマーは、多くの最先端NLPモデルの基盤となる一種のニューラルネットワークアーキテクチャです。トランスフォーマーは、再帰的または畳み込み層に重点を置いた従来のモデルと比較して、入力と出力の間のグローバルな依存関係を引き出すための “アテンション”…

「Hugging Face Transformersを使用したBERT埋め込みの作成」
はじめに Transformersはもともと、テキストを一つの言語から別の言語に変換するために作られました。BERTは、人間の言語を学習し作業する方法に大きな影響を与えました。それはテキストを理解する元々のトランスフォーマーモデルの部分を改良しました。BERTの埋め込みを作成することは、特に複雑な意味を持つ文章を把握するのに適しています。これは、文章全体を調べ、単語のつながり方を理解することで行います。Hugging Faceのtransformersライブラリは、ユニークな文章コードを作成し、BERTを導入するための鍵です。 学習目標 BERTと事前学習モデルの理解を深める。これらが人間の言語との作業にどれだけ重要かを理解する。 Hugging FaceのTransformersライブラリを効果的に使用する方法を学ぶ。これを使用してテキストの特殊な表現を作成する。 事前学習されたBERTモデルからこれらの表現を正しく削除する様々な方法を見つける。これは、異なる言語タスクには異なるアプローチが必要なため重要です。 実際にこれらの表現を作成するために必要な手順を実際に行い、実践的な経験を積む。自分自身でできることを確認する。 作成したこれらの表現を使用して、テキストのソートやテキスト内の感情の把握など、他の言語タスクを改善する方法を学ぶ。 特定の言語タスクにさらに適したように事前学習モデルを調整する方法を探索する。これにより、より良い結果が得られる可能性があります。 これらの表現が言語タスクの改善にどのように使用され、言語モデルの正確性とパフォーマンスを向上させるかを調べる。 この記事はデータサイエンスブログマラソンの一部として公開されました。 パイプラインはトランスフォーマーのコンテキスト内で何を含むのか? パイプラインは、トランスフォーマーライブラリに含まれる複雑なコードを簡素化するユーザーフレンドリーなツールと考えてください。言語の理解、感情分析、特徴の抽出、質問に対する回答などのタスクにモデルを使用することを簡単にします。これらの強力なモデルとの対話を簡潔な方法で提供します。 パイプラインにはいくつかの重要なコンポーネントが含まれます:トークナイザ(通常のテキストをモデルが処理するための小さな単位に変換するもの)、モデル自体(入力に基づいて予測を行うもの)、そしてモデルがうまく動作するようにするためのいくつかの追加の準備ステップ。 Hugging Face Transformersの使用の必要性は何ですか? トランスフォーマーモデルは通常非常に巨大であり、トレーニングや実際のアプリケーションで使用するために取り扱うことは非常に複雑です。Hugging Face transformersは、このプロセス全体を簡単にすることを目指しています。どれほど巨大であっても、どんなTransformerモデルでも、ロード、トレーニング、保存するための単一の方法を提供します。モデルのライフサイクルの異なる部分に異なるソフトウェアツールを使用することはさらに便利です。一連のツールでトレーニングを行い、その後、手間をかけずに実世界のタスクに使用することができます。 高度な機能 これらの最新のモデルは使いやすく、人間の言語の理解と生成、コンピュータビジョンや音声に関連するタスクにおいて優れた結果を提供します。…
「キャリアのために右にスワイプ:仕事のためのTinderを作る」
「幅広い雇用の世界で完璧な仕事や候補者を見つけることは、ハンニンを干し草の中から見つけるよりも難しいと知っていますか?心配しないでください、親愛なる読者の皆さん、私たちは今、探求の旅に乗り出す準備をしています...」

「コンテキストの解読:NLPにおける単語ベクトル化技術」
「あなたは自国から遠く離れた新しい町に引っ越しましたそこで偶然、コーヒーショップで誰かにぶつかりましたあなたと同じくらいの年の若い女性で、すぐに二人は会話に夢中になりましたそれは…」

「NLP入門コースでNLPを始めましょう」
新しいスキルを学ぶには、どんなに詳細なものであっても多くのことが必要です自然言語処理(NLP)を始める場合も例外ではありません機械学習、ディープラーニング、言語などに精通している必要があります特に、生成AIやプロンプトエンジニアリングの発展と共に...
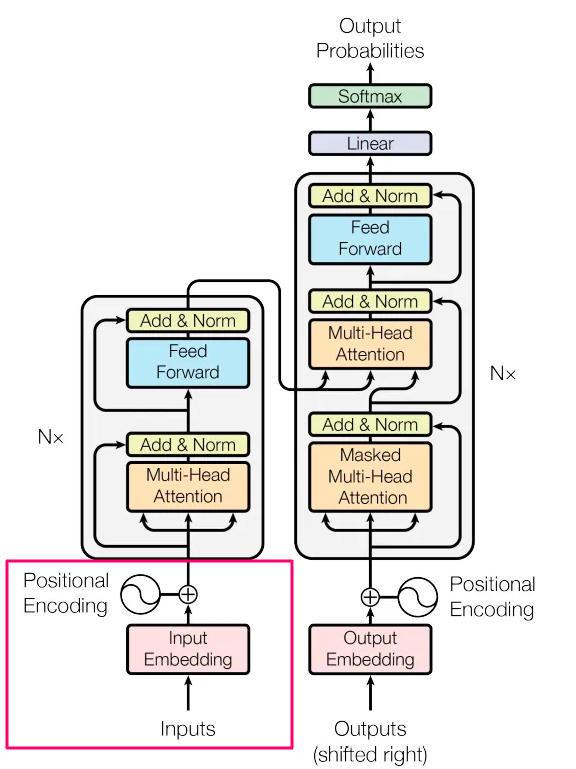
「トランスフォーマーの簡素化:理解できる単語を使った最先端の自然言語処理(NLP)-パート2- 入力」
ドラゴンは卵から孵り、赤ちゃんはおなかから飛び出し、AIに生成されたテキストは入力から始まります私たちはみんなどこかから始めなければなりません どんな種類の入力ですか?それは手元のタスクによりますもしもあなたが構築しているならば...

「spaCyを使用したNLPパイプラインの強化」
はじめに spaCyは、自然言語処理(NLP)のためのPythonライブラリです。spaCyを使用したNLPパイプラインは無料でオープンソースです。開発者は、Cythonのように情報抽出や自然言語理解システムを作成するためにそれを使用します。このツールは、コンパクトで使いやすいAPIを持つ製品のために使用します。 テキストを大量に扱う場合は、それについてもっと学びたいと思うでしょう。例えば、それは何についてですか?どの文脈で用語は意味を持ちますか?誰に対して何が行われていますか?どのビジネスや商品が言及されていますか?どのテキストが互いに比較できますか? spaCyは、本番使用を想定しており、膨大な量のテキストを処理して「理解」するアプリケーションの開発を支援します。情報抽出システム、自然言語解釈、深層学習のためのテキストの前処理など、さまざまなタスクに対応できます。 学習目標 トークン化、品詞タグ付け、固有名詞の識別など、spaCyの基礎を学ぶ。 効率的かつ高速なテキスト処理アーキテクチャであるspaCyのテキスト処理アーキテクチャを理解し、大規模なNLPジョブに適している。 spaCyでは、NLPパイプラインを探索し、特定のタスクに特化したカスタムパイプラインを作成できます。 ルールベースのマッチング、構文解析、エンティティリンクなど、spaCyの高度な機能を探索する。 spaCyで利用可能な多数の事前学習済み言語モデルについて学び、さまざまなNLPアプリケーションでそれらを利用する方法を学ぶ。 spaCyを使用してテキスト内のエンティティを識別し、分類するための固有名詞認識(NER)戦略を学ぶ。 この記事は、データサイエンスブログマラソンの一環として公開されました。 統計モデル 一部のspaCyの機能は自律的に機能しますが、他の機能は統計モデルのロードが必要です。これらのモデルにより、spaCyは単語が動詞か名詞かを決定するなど、言語の注釈を予測することができます。現在、spaCyはさまざまな言語の統計モデルを提供しており、それらを個別のPythonモジュールとしてインストールすることができます。通常、以下の要素を組み込んでいます: 品詞タガー、依存パーサー、固有名詞認識器に対してバイナリの重みを割り当てることで、それらの注釈を文脈で予測します。 語彙中の形態素とその文脈に依存しない特徴(形式や綴りなど)を含む語彙項目。 レンマ化のルールやルックアップテーブルなどのデータファイル。 単語の多次元の意味表現である単語ベクトルで、単語間の類似性を特定することができます。 モデルのロード時に、言語や処理パイプラインの設定などの設定オプションを使用してspaCyを適切な状態にすることができます。 モデルをインポートするには、以下のようにspacy.load(‘モデル名’)を実行します: !python -m spacy download…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.