Learn more about Search Results Weaviate - Page 3

- You may be interested
- 予想外な方法でAIがイスラエル・ハマス戦...
- 混乱するデータサイエンティストのためのP...
- Mr. Pavan氏のデータエンジニアリングの道...
- Substraを使用してプライバシーを保護する...
- Amazon DocumentDBを使用して、Amazon Sag...
- 「AIの誤情報:なぜそれが機能するのか、...
- メタは、プライバシー侵害のチェックに関...
- 「CLV予測モデルの完成おめでとうございま...
- 「GeForce NOW-vemberは50以上の新しいゲ...
- このAI論文は、言語エージェントのための...
- ディープサーチ:Microsoft BingがGPT-4と...
- 言語モデルと仲間たち:ゴリラ、HuggingGP...
- 「2023年に使用するためのトップ9のデータ...
- ChatGPTはデータサイエンスの仕事を奪うの...
- 統計的推定と推論の初心者向け解説

「Chromaを使用してマルチモーダル検索アプリを作成する方法」
はじめに 複雑な脳が世界をどのように処理しているのか、あなたは考えたことがありますか? 脳の内部の仕組みは依然として謎ですが、私たちはそれを多目的なニューラルネットワークにたとえることができます。 電気化学的な信号のおかげで、それは様々なデータ型を処理します-音、映像、匂い、味、触覚。 AIが進化するにつれて、マルチモーダルモデルが登場し、検索能力が革新されています。 このイノベーションにより、検索の正確性と関連性が向上し、新たな可能性が開かれています。 マルチモーダル検索の魅力的な世界を発見しましょう。 学習目標 「AIにおけるマルチモーダリティ」という用語を理解する。 OpenAIのイメージテキストモデルCLIPについての洞察を得る。 ベクトルデータベースとベクトルインデックスの概要を理解する。 CLIPとChromaベクトルデータベースを使用して、Gradioインターフェースを使用した食品推薦システムを構築する。 マルチモーダル検索の他の現実世界での使用例を探索する。 この記事はData Science Blogathonの一部として公開されました。 AIにおけるマルチモーダリティとは何ですか? Googleで検索すると、マルチモードはプロセスに複数のモードや方法を関与させることを指すと分かります。 人工知能では、マルチモーダルモデルは異なるデータタイプを処理し理解することができるニューラルネットワークです。 たとえば、GPT-4やバードなどです。 これらは、テキストや画像を理解できるLLMです。 他の例としては、ビジュアルとセンサーデータを組み合わせて周囲の状況を理解するテスラの自動運転車、またはテキストの説明から画像を生成できるMidjourneyやDalleがあります。 コントラスト言語-画像事前トレーニング(CLIP) CLIPは、OpenAIが大量の画像テキストペアのデータセットでトレーニングしたオープンソースのマルチモーダルニューラルネットワークです。…

LLama Indexを使用してRAGパイプラインを構築する
イントロダクション 最も人気のある大規模言語モデル(LLM)の応用の一つは、カスタムデータセットに関する質問に回答することです。ChatGPTやBardなどのLLMは、優れたコミュニケーターであり、彼らが訓練されたものに関してはほとんど何でも答えることができます。これはLLMの最大のボトルネックの一つでもあります。彼らはモデルの訓練中に見た質問にしか答えられません。言語モデルは世界の知識に制限があります。例えば、Chatgptは2021年までのデータを利用して訓練されています。また、GPTはあなたの個人ファイルについて学ぶ方法はありません。では、モデルにまだ持っていない知識をどのようにして認識させることができるでしょうか?その答えが「検索補完生成パイプライン(RAG)」です。この記事では、RAG(検索補完生成)パイプラインについて学び、LLamaインデックスを使用してそれを構築する方法について説明します。 学習目標 RAG(検索補完生成)とは何か、またいつ使用するべきかを探求する。 RAGの異なるコンポーネントについて簡単に理解する。 Llamaインデックスについて学び、PDFのためのシンプルなRAGパイプラインを構築する方法を理解する。 埋め込みとベクトルデータベースとは何か、またLlamaインデックスの組み込みモジュールを使用してPDFから知識ベースを構築する方法を学ぶ。 RAGベースのアプリケーションの実世界での使用例を発見する。 この記事はData Science Blogathonの一環として公開されました。 RAGとは何ですか? LLMは、これまでのところ最も効率的かつ強力なNLPモデルです。翻訳、エッセイの執筆、一般的な質問応答の分野でLLMの潜在能力を見てきました。しかし、特定のドメインに特化した質問応答においては、彼らは幻覚に苦しんでいます。また、ドメイン固有のQAアプリでは、クエリごとに関連する文脈を持つドキュメントはわずかです。したがって、ドキュメントの抽出から回答生成、およびその間のすべてのプロセスを統合する統一されたシステムが必要です。このプロセスは「検索補完生成」と呼ばれています。 詳しくはこちらを参照:AIにおける検索補完生成(RAG) では、なぜRAGが実世界の特定のドメインに特化したQAアプリケーションの構築に最も効果的なのかを理解しましょう。 なぜRAGを使用すべきか? LLMが新しいデータを学ぶ方法は3つあります。 トレーニング:兆個のトークンと数十億のパラメータを持つニューラルネットワークの大規模なメッシュが使用されて、大規模言語モデルを作成するために訓練されます。ディープラーニングモデルのパラメータは、特定のモデルに関するすべての情報を保持する係数または重みです。GPT-4のようなモデルを訓練するには、数億ドルがかかります。この方法は誰にでも容易にはできません。このような巨大なモデルを新しいデータで再訓練することは実現不可能です。 ファインチューニング:別のオプションとして、既存のデータに対してモデルをファインチューニングすることが考えられます。ファインチューニングは、トレーニング中に事前に訓練されたモデルを起点として使用することを意味します。事前に訓練されたモデルの知識を利用して、異なるデータセット上で新たなモデルを訓練します。これは非常に強力ですが、時間とお金の面で高コストです。特別な要件がない限り、ファインチューニングは意味がありません。 プロンプティング:プロンプティングは、LLMのコンテキストウィンドウ内に新しい情報を適応させ、提示された情報からクエリに回答させる方法です。これは、訓練やファインチューニングで学んだ知識ほど効果的ではありませんが、ドキュメントの質問応答など多くの実世界のユースケースには十分です。 テキストドキュメントからの回答を促すことは効果的ですが、これらのドキュメントはしばしばLarge Language Models(LLM)のコンテキストウィンドウよりもはるかに大きくなるため、課題を提起します。リトリーバルオーグメンテッドジェネレーション(RAG)パイプラインは、関連するドキュメントセクションの処理、保存、および検索を行うことで、LLMが効率的にクエリに答えることができるようにします。それでは、RAGパイプラインの重要なコンポーネントについて議論しましょう。 RAGコンポーネントとは何ですか?…

「ベクターデータベースを使用してLLMアプリを作成する方法」
イントロダクション 人工知能の領域では、OpenAIのGPT-4、AnthropicのClaude 2、MetaのLlama、Falcon、GoogleのPalmなど、Large Language Models(LLMs)やGenerative AIモデルが問題解決の方法を革新しています。LLMsはディープラーニングの技術を使用して、自然言語処理のタスクを実行します。この記事では、ベクトルデータベースを使用してLLMアプリを構築する方法を紹介します。おそらくAmazonの顧客サービスやFlipkartのDecision Assistantのようなチャットボットと対話したことがあるかもしれません。それらは人間に近いテキストを生成し、実際の会話と区別がつきにくいインタラクティブなユーザーエクスペリエンスを提供します。しかし、これらのLLMsは最適化する必要があります。特定のユースケースに対して非常に関連性が高く具体的な結果を生成するようにするためには。 例えば、Amazonの顧客サービスアプリに「Androidアプリで言語を変更する方法は?」と尋ねた場合、正確にこのテキストでトレーニングされていないため、答えることができないかもしれません。ここでベクトルデータベースが助けになります。ベクトルデータベースは、ドメインのテキスト(この場合はヘルプドキュメント)と、注文履歴などを含むすべてのユーザーの過去のクエリを数値の埋め込みとして保存し、リアルタイムで似たようなベクトルの検索を提供します。この場合、このクエリを数値ベクトルにエンコードし、ベクトルデータベース内で類似のベクトルを検索し、最も近い隣人を見つけるために使用します。このようなヘルプを通じて、チャットボットはユーザーを正しくAmazonアプリの「言語設定の変更」セクションに案内できます。 学習目標 LLMsの動作原理、制約、およびベクトルデータベースの必要性について学ぶ。 埋め込みモデルの紹介と、アプリケーションでのエンコードと使用方法について学ぶ。 ベクトルデータベースとそれがLLMアプリケーションアーキテクチャの一部である方法について学ぶ。 ベクトルデータベースとTensorFlowを使用してLLM/Generative AIアプリケーションをコーディングする方法を学ぶ。 この記事はデータサイエンスブログマラソンの一環として公開されました。 LLMsとは何ですか? Large Language Models(LLMs)は、自然言語を処理し理解するためにディープラーニングアルゴリズムを使用する基本的な機械学習モデルです。これらのモデルは大量のテキストデータでトレーニングされ、言語のパターンやエンティティの関係を学習します。LLMsは、言語の翻訳、感情分析、チャットボットの会話などのさまざまなタイプの言語タスクを実行することができます。彼らは複雑なテキストデータを理解し、エンティティとそれらの間の関係を識別し、統率的で文法的に正確な新しいテキストを生成することができます。 LLMsについてもっと詳しく読む。 LLMsはどのように動作するのですか? LLMsは大量のデータ(しばしばテラバイト、さらにはペタバイト)を使用してトレーニングされ、数十億または数兆のパラメータを持ち、ユーザーのプロンプトやクエリに基づいて関連する応答を予測および生成することができます。入力データをワード埋め込み、自己注意層、およびフィードフォワードネットワークを通じて処理し、意味のあるテキストを生成します。LLMアーキテクチャについてもっと読むことができます。 LLMsの制約 LLMsは非常に高い精度で応答を生成するように見えますが、多くの標準化テストでは人間を超える結果を示すことがありますが、それでもこれらのモデルには制約があります。まず第一に、彼らは自身のトレーニングデータに頼ることだけで推論を行い、データ内の特定の情報や現在の情報が欠けているかもしれません。これにより、モデルが誤ったまたは異常な応答を生成することがあります(「幻覚」とも言われます)。これを軽減するための取り組みが継続中です。第二に、モデルはユーザーの期待に合致するように振る舞ったり応答するとは限りません。…

「フリーODSCウェストオープンパス」を紹介します
「オープンデータとデータサイエンス、AIコミュニティの成長のために、私たちは喜んでお知らせします今年10月30日から11月2日に行われるODSCウエストでは、参加者全員に無料のODSCオープンパスを提供しています参加経験のない方々にとっては...」

「GPT-4を超えて 新機能は何ですか?」
「GPT-4を超えて:生成AIの4つの主要なトレンド:LLMからマルチモーダル、ベクトルデータベースへの接続、エージェントからOSへ、そしてファインチューニングからプラグインへそして、MetaのLlama 2とCode Llama」

「Verbaに会ってください:自分自身のRAG検索増強生成パイプラインを構築し、LLMを内部ベースの出力に活用するためのオープンソースツール」
Verbaは、RAGアプリにシンプルで使いやすいインターフェースを提供するオープンソースプロジェクトです。データにダイブして関連する会話をすばやく開始することができます。 Verbaは、データのクエリと操作に関する単なるツールではなく、むしろコンパニオンです。文書間の書類作成、比較、数値セット間の対比、データ分析など、WeaviateとLarge Language Models(LLMs)を通じて、Verbaはこれらすべてを実現することができます。 Weaviateの先端的なGenerative Searchエンジンに基づいて、Verbaは検索を実行するたびに必要な背景情報を自動的に取得します。LLMsの処理能力を使用して、徹底的でコンテキストに即したソリューションを提供します。Verbaのわかりやすいレイアウトにより、これらすべての情報を簡単に取得することができます。Verbaのわかりやすいデータインポート機能は、.txt、.mdなどさまざまなファイル形式をサポートしています。データをWeaviateにフィードする前に、技術はデータのチャンキングとベクトル化を自動的に実行し、検索と取得に適した形式にします。 Verbaを使用する際には、Weaviateの作成モジュールとハイブリッド検索オプションを利用してください。これらの高度な検索方法は、重要な文脈の断片を探し出すために論文をスキャンし、それを元にLarge Language Modelsが照会に対して詳細な応答を提供します。 将来の検索の速度を向上させるために、Verbaは生成された結果とクエリをWeaviateのSemantic Cacheに埋め込みます。質問に答える前に、VerbaはSemantic Cacheを調べて、すでに似たような質問に回答されているかどうかを判断します。 データ入力とクエリ機能を有効にするには、デプロイメントの方法に関係なくOpenAI APIキーが必要です。プロジェクトをクローンする際に、APIキーをシステムの環境変数に追加するか、.envファイルを作成してください。 Verbaは、特定のユースケースに応じてさまざまな方法でWeaviateインスタンスに接続することができます。VERBA_URLおよびVERBA_API_KEYの環境変数が存在しない場合、VerbaはWeaviate Embeddedを使用します。プロトタイピングやテストのためにWeaviateデータベースを起動する最も簡単な方法は、このローカルデプロイメントです。 Verbaは、さらなる処理のためのデータのインポートに関する簡単な指示を提供します。続行する前に、OpenAIアクセスキーの設定に基づいてデータのインポートにはお金がかかることに注意してください。OpenAIモデルはVerbaのみで使用されます。APIキーの料金はこれらのモデルの使用料にかかります。データの埋め込みと回答の生成が主なコスト要素です。 https://verba.weaviate.io/ で試すことができます。 Verbaには3つの主要なパートがあります: Weaviate Cloud Service(WCS)またはサーバー上でWeaviateデータベースをホストすることができます。 このFastAPIエンドポイントは、Large…

「LangchainなしでPDFチャットボットを構築する方法」
はじめに Chatgptのリリース以来、AI領域では進歩のペースが減速する気配はありません。毎日新しいツールや技術が開発されています。ビジネスやAI領域全般にとっては素晴らしいことですが、プログラマとして、すべてを学んで何かを構築する必要があるでしょうか? 答えはノーです。この場合、より現実的なアプローチは、必要なものについて学ぶことです。ものを簡単にすると約束するツールや技術がたくさんありますが、すべての場合にそれらが必要というわけではありません。単純なユースケースに対して大規模なフレームワークを使用すると、コードが肥大化してしまいます。そこで、この記事では、LangchainなしでCLI PDFチャットボットを構築し、なぜ必ずしもAIフレームワークが必要ではないのかを理解していきます。 学習目標 LangchainやLlama IndexのようなAIフレームワークが必要ない理由 フレームワークが必要な場合 ベクトルデータベースとインデックス作成について学ぶ PythonでゼロからCLI Q&Aチャットボットを構築する この記事は、Data Science Blogathonの一環として公開されました。 Langchainなしで済むのか? 最近の数ヶ月間、LangchainやLLama Indexなどのフレームワークは、開発者によるLLMアプリの便利な開発を可能にする非凡な能力により、注目を集めています。しかし、多くのユースケースでは、これらのフレームワークは過剰となる場合があります。それは、銃撃戦にバズーカを持ってくるようなものです。 これらのフレームワークには、プロジェクトで必要のないものも含まれています。Pythonはすでに肥大化していることで有名です。その上で、ほとんど必要のない依存関係を追加すると、環境が混乱するだけです。そのようなユースケースの一つがドキュメントのクエリです。プロジェクトがAIエージェントやその他の複雑なものを含まない場合、Langchainを捨ててゼロからワークフローを作成することで、不要な肥大化を減らすことができます。また、LangchainやLlama Indexのようなフレームワークは急速に開発が進んでおり、コードのリファクタリングによってビルドが壊れる可能性があります。 Langchainはいつ必要ですか? 複雑なソフトウェアを自動化するエージェントを構築したり、ゼロから構築するのに長時間のエンジニアリングが必要なプロジェクトなど、より高度なニーズがある場合は、事前に作成されたソリューションを使用することは合理的です。改めて発明する必要はありません、より良い車輪が必要な場合を除いては。その他にも、微調整を加えた既製のソリューションを使用することが絶対に合理的な場合は数多くあります。 QAチャットボットの構築 LLMの最も求められているユースケースの一つは、ドキュメントの質問応答です。そして、OpenAIがChatGPTのエンドポイントを公開した後、テキストデータソースを使用して対話型の会話ボットを構築することがより簡単になりました。この記事では、ゼロからLLM Q&A…
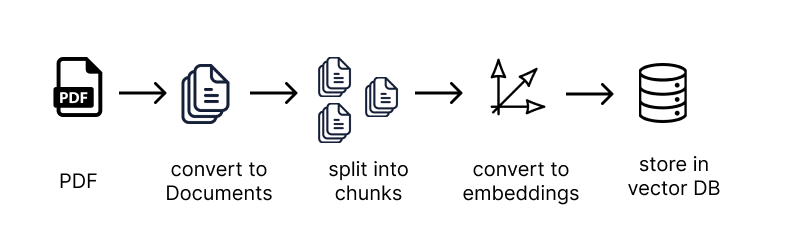
「ワイルドワイルドRAG…(パート1)」
「RAG(Retrieval-Augmented Generation)は、外部の知識源を取り込むことで言語モデルによって生成された応答の品質を向上させるAIフレームワークですこれにより、…のギャップを埋める役割を果たします」

このAI研究は、OpenAIの埋め込みを使用した強力なベクトル検索のためのLuceneの統合を提案します
最近、機械学習の検索分野において、深層ニューラルネットワークを応用することで大きな進歩がありました。特に、バイエンコーダーアーキテクチャ内の表現学習に重点を置いています。このフレームワークでは、クエリ、パッセージ、さらには画像などのマルチメディアなど、さまざまな種類のコンテンツが、密なベクトルとして表されるコンパクトで意味のある「埋め込み」として変換されます。このアーキテクチャに基づいて構築されたこれらの密な検索モデルは、大規模な言語モデル(LLM)内の検索プロセスの強化の基盤として機能します。このアプローチは人気があり、現在の生成的AIの広い範囲でLLMの全体的な能力を高めるのに非常に効果的であることが証明されています。 この論文では、多くの密なベクトルを処理する必要があるため、企業は「AIスタック」に専用の「ベクトルストア」または「ベクトルデータベース」を組み込むべきだと示唆しています。一部のスタートアップ企業は、これらのベクトルストアを革新的で不可欠な現代の企業アーキテクチャの要素として積極的に推進しています。有名な例には、Pinecone、Weaviate、Chroma、Milvus、Qdrantなどがあります。一部の支持者は、これらのベクトルデータベースが従来のリレーショナルデータベースをいずれ置き換える可能性さえ示しています。 この論文では、この説に対して反論を示しています。その議論は、既存の多くの組織で存在し、これらの機能に大きな投資がなされているという点を考慮した、簡単なコスト対効果分析を中心に展開されています。生産インフラストラクチャは、Elasticsearch、OpenSearch、Solrなどのプラットフォームによって主導されている、オープンソースのLucene検索ライブラリを中心とした広範なエコシステムによって支配されています。 https://arxiv.org/abs/2308.14963 上記の画像は、標準的なバイエンコーダーアーキテクチャを示しており、エンコーダーがクエリとドキュメント(パッセージ)から密なベクトル表現(埋め込み)を生成します。検索はベクトル空間内のk最近傍探索としてフレーム化されています。実験は、ウェブから抽出された約880万のパッセージから構成されるMS MARCOパッセージランキングテストコレクションに焦点を当てて行われました。評価には、標準の開発クエリとTREC 2019およびTREC 2020 Deep Learning Tracksのクエリが使用されました。 調査結果は、今日ではLuceneを直接使用してOpenAIの埋め込みを使用したベクトル検索のプロトタイプを構築することが可能であることを示唆しています。埋め込みAPIの人気の増加は、私たちの主張を支持しています。これらのAPIは、コンテンツから密なベクトルを生成する複雑なプロセスを簡素化し、実践者にとってよりアクセスしやすくしています。実際には、今日の検索エコシステムを構築する際に必要なのはLuceneだけです。しかし、時間が経って初めて正しいかどうかがわかります。最後に、これはコストと利益を比較することが主要な考え方であり続けることを思い起こさせてくれるものです。急速に進化するAIの世界でも同様です。

「Pythonベクトルデータベースとベクトルインデックス:LLMアプリの設計」
ベクトルデータベースは、データポイント間での高速な類似度検索とスケーラビリティを可能にしますLLMアプリケーションでは、ベクトルインデックスを既存のストレージにアタッチすることで、完全なベクトルデータベースよりもアーキテクチャを簡素化することができますインデックスとデータベースの選択は、特殊なニーズ、既存のインフラストラクチャ、およびより広範な企業の要件に依存します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.