Learn more about Search Results V100 - Page 3

- You may be interested
- この人工知能(AI)の研究では、SAMを医療...
- 「Google Bardの拡張機能を無料で使用する...
- 「Amazon SageMaker Canvasで構築されたML...
- マイクロソフトの研究者たちは、FP8混合精...
- 「SPHINXをご紹介します:トレーニングタ...
- CI/CDパイプライン:Azure上のデータ処理...
- プレイヤーの離脱を予測する方法、ChatGPT...
- このAI研究は、質問応答の実行能力におい...
- NVIDIAはAPECの国々と協力し、人々の生活...
- SRGANs:低解像度と高解像度画像のギャッ...
- パンチカードからChatGPTへ
- 10 ChatGPT プロジェクト チートシート
- 弁護士には、ChatGPTを使用したことについ...
- 単一モダリティとの友情は終わりました &#...
- 「DISCOに会おう:人間のダンス生成のため...

「オーディオソース分離のマスターキー:AudioSepを紹介して、あなたが説明するものを分離します」
Computational Auditory Scene Analysis(CASA)は、複雑な聴覚環境で個別の音源を分離し理解することに焦点を当てた音声信号処理の分野です。LASS(Language-queried Audio Source Separation)は、InterSpeech 2022で導入されたCASAの新しいアプローチです。LASSの目的は、自然言語クエリに基づいてオーディオ混合物からターゲット音を分離することであり、デジタルオーディオアプリケーションにおける自然でスケーラブルなインターフェースを提供します。音楽楽器や一部のオーディオイベントなどの音源に対して優れた分離性能を実現しているにもかかわらず、LASSに関する最近の取り組みは、オープンドメイン設定における音響概念の分離がまだできていません。 これらの課題に対処するため、研究者は「AudioSep – separate anything audio model」と呼ばれる、タスク間での印象的なゼロショット汎化と音声増強、オーディオイベント分離、音楽楽器分離における強力な分離能力を示す基盤モデルを開発しました。 AudioSepには、テキストエンコーダと分離モデルの2つの主要なコンポーネントがあります。テキストエンコーダにはCLIPまたはCLAPのテキストエンコーダが使用され、テキスト埋め込みを抽出します。次に、6つのエンコーダブロックと6つのデコーダブロックからなる30層のResUNetを利用したユニバーサルサウンド分離が行われます。各エンコーダブロックには、3×3のカーネルサイズを持つ2つの畳み込み層が含まれています。AudioSepモデルは、8つのTesla V100 GPUカードで1Mステップトレーニングされました。 AudioSepは、オーディオイベント分離、音楽楽器分離、音声強化などのタスクにおける能力を詳細に評価されました。オーディオキャプションやテキストラベルをクエリとして使用することで、強力な分離性能と印象的なゼロショット汎化能力を発揮し、以前のオーディオクエリや言語クエリによる音響分離モデルを大幅に上回りました。 研究者は、AudioSep-CLAPモデルを使用して、オーディオ混合物とグラウンドトゥルースのターゲット音源のスペクトログラムを視覚化し、さまざまな音源(例:オーディオイベント、声)のテキストクエリを使用して音源を分離しました。分離された音源のスペクトログラムパターンは、グラウンドトゥルース音源のものと類似しており、客観的な実験結果と一致していました。 彼らは、「テキストラベル」の代わりに「オリジナルキャプション」をテキストクエリとして使用することで、パフォーマンスが大幅に向上することを発見しました。これは、人間が注釈付けしたキャプションがオーディオイベントラベルよりも詳細で正確なソースの説明を提供するためです。再注釈されたキャプションの個人の性格や可変的な単語分布にもかかわらず、「再注釈されたキャプション」を使用した結果は「オリジナルキャプション」を使用した結果よりもやや劣っていましたが、「テキストラベル」を使用した結果よりも優れていました。これらの結果は、AudioSepの堅牢性と有望性を実証し、それに対して説明するものを分離するツールとなりました。 AudioSepの次のステップは、教師なし学習技術による分離、ビジョンクエリ分離、オーディオクエリ分離、スピーカー分離タスクへの現在の作業の拡張です。

SEER:セルフスーパーバイズドコンピュータビジョンモデルの突破口?
過去10年間、人工知能(AI)と機械学習(ML)は著しい進歩を遂げてきました現在では、これまで以上に正確で効率的で、かつ能力が高まっています最新のAIとMLモデルは、画像やビデオファイル内のオブジェクトをシームレスに正確に認識することができますさらに、人間の知性に匹敵するテキストや音声を生成することも可能です[…]
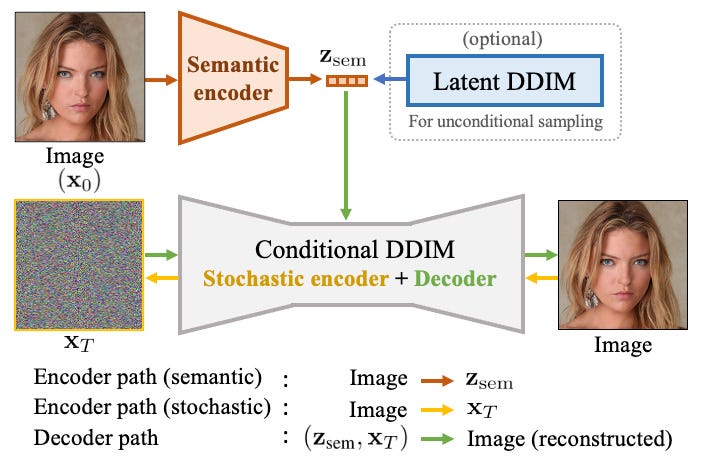
「DAE Talking 高忠実度音声駆動の話し相手生成における拡散オートエンコーダー」
今日は、新しい論文と、私が出会った中で最高品質の音声駆動ディープフェイクモデルについて話し合いますマイクロソフトリサーチから来たDAE-talkerは、個別の人物に特化したフルヘッドモデルです...
このAIニュースレターは、あなたが必要とするすべてです #55
今週、私たちはついにOpen AIのCode Interpreterをテストすることができ、ChatGPT内のGPT-4の新機能に興奮していましたOpenAIは他の発表も行い、その計画を明らかにしました...
このAIニュースレターは、あなたが必要な全てです #55
今週は、ついにOpen AIのCode Interpreterをテストする機会を得て、とても興奮しましたこれは、ChatGPT内のGPT-4の新しい機能ですOpenAIは他にも発表があり、その中で...

Hugging Face Transformersでより高速なTensorFlowモデル
ここ数か月、Hugging FaceチームはTransformersのTensorFlowモデルの改良に取り組んできました。目標はより堅牢で高速なモデルを実現することです。最近の改良は主に次の2つの側面に焦点を当てています: 計算パフォーマンス:BERT、RoBERTa、ELECTRA、MPNetの計算時間を大幅に短縮するための改良が行われました。この計算パフォーマンスの向上は、グラフ/イージャーモード、TF Serving、CPU/GPU/TPUデバイスのすべての計算アスペクトで顕著に見られます。 TensorFlow Serving:これらのTensorFlowモデルは、TensorFlow Servingを使用して展開することができ、推論においてこの計算パフォーマンスの向上を享受することができます。 計算パフォーマンス 計算パフォーマンスの向上を実証するために、v4.2.0のTensorFlow ServingとGoogleの公式実装との間でBERTのパフォーマンスを比較するベンチマークを実施しました。このベンチマークは、GPU V100上でシーケンス長128を使用して実行されました(時間はミリ秒単位で表示されます): v4.2.0の現行のBertの実装は、Googleの実装よりも最大で約10%高速です。また、4.1.1リリースの実装よりも2倍高速です。 TensorFlow Serving 前のセクションでは、Transformersの最新バージョンでブランドニューのBertモデルが計算パフォーマンスが劇的に向上したことを示しました。このセクションでは、製品環境で計算パフォーマンスの向上を活用するために、TensorFlow Servingを使用してBertモデルを展開する手順をステップバイステップで説明します。 TensorFlow Servingとは何ですか? TensorFlow Servingは、モデルをサーバーに展開するタスクをこれまで以上に簡単にするTensorFlow Extended(TFX)が提供するツールの一部です。TensorFlow Servingには、HTTPリクエストを使用して呼び出すことができるAPIと、サーバー上で推論を実行するためにgRPCを使用するAPIの2つがあります。 SavedModelとは何ですか? SavedModelには、ウェイトとアーキテクチャを含むスタンドアロンのTensorFlowモデルが含まれています。SavedModelは、モデルの元のソースを実行する必要がないため、Java、Go、C++、JavaScriptなどのSavedModelを読み込むバックエンドをサポートするすべてのバックエンドと共有または展開するために役立ちます。SavedModelの内部構造は次のように表されます:…
分散トレーニング:🤗 TransformersとAmazon SageMakerを使用して、要約のためにBART/T5をトレーニングする
見逃した場合: 3月25日にAmazon SageMakerとのコラボレーションを発表しました。これにより、最新の機械学習モデルを簡単に作成し、先進的なNLP機能をより速く提供できるようになりました。 SageMakerチームと協力して、🤗 Transformers最適化のDeep Learning Containersを構築しました。AWSの皆さん、ありがとうございます!🤗 🚀 SageMaker Python SDKの新しいHuggingFaceエスティメーターを使用すると、1行のコードでトレーニングを開始できます。 発表のブログ投稿では、統合に関するすべての情報、”はじめに”の例、ドキュメント、例、および機能へのリンクが提供されています。 以下に再掲します: 🤗 Transformers ドキュメント: Amazon SageMaker サンプルノートブック Hugging Face用のAmazon SageMakerドキュメント Hugging Face用のPython…

インターネット上でのディープラーニング:言語モデルの共同トレーニング
Quentin LhoestさんとSylvain Lesageさんの追加の助けを得ています。 現代の言語モデルは、事前学習に多くの計算リソースを必要とするため、数十から数百のGPUやTPUへのアクセスなしでは入手することが不可能です。理論的には、複数の個人のリソースを組み合わせることが可能かもしれませんが、実際には、インターネット上の接続速度は高性能GPUスーパーコンピュータよりも遅いため、このような分散トレーニング手法は以前は限定的な成功しか収めていませんでした。 このブログ記事では、参加者のネットワークとハードウェアの制約に適応することができる新しい協力的な分散トレーニング方法であるDeDLOCについて説明します。私たちは、40人のボランティアを使ってベンガル語の言語モデルであるsahajBERTの事前学習を行うことで、実世界のシナリオでの成功を示します。ベンガル語の下流タスクでは、このモデルは数百の高級アクセラレータを使用したより大きなモデルとほぼ同等のクオリティを実現しています。 オープンコラボレーションにおける分散深層学習 なぜやるべきなのか? 現在、多くの高品質なNLPシステムは大規模な事前学習済みトランスフォーマーに基づいています。一般的に、その品質はサイズとともに向上します。パラメータ数をスケールアップし、未ラベルのテキストデータの豊富さを活用することで、自然言語理解や生成において類を見ない結果を実現することができます。 残念ながら、これらの事前学習済みモデルを使用するのは、便利なだけではありません。大規模なデータセットでのトランスフォーマーのトレーニングに必要なハードウェアリソースは、一般の個人やほとんどの商業または研究機関には手の届かないものです。例えば、BERTのトレーニングには約7000ドルかかると推定され、GPT-3のような最大のモデルでは、この数は1200万ドルにもなります!このリソースの制約は明らかで避けられないもののように思えますが、広範な機械学習コミュニティにおいて事前学習済みモデル以外の代替手段は本当に存在しないのでしょうか? ただし、この状況を打破する方法があるかもしれません。解決策を見つけるために、周りを見渡すだけで十分かもしれません。求めている計算リソースは既に存在している可能性があるかもしれません。たとえば、多くの人々は自宅にゲームやワークステーションのGPUを搭載したパワフルなコンピュータを持っています。おそらく、私たちがFolding@home、Rosetta@home、Leela Chess Zero、または異なるBOINCプロジェクトのように、ボランティアコンピューティングを活用することで、彼らのパワーを結集しようとしていることはお分かりいただけるかもしれませんが、このアプローチはさらに一般的です。たとえば、いくつかの研究所は、自身の小規模なクラスタを結集して利用することができますし、低コストのクラウドインスタンスを使用して実験に参加したい研究者もいるかもしれません。 疑い深い考え方をすると、ここで重要な要素が欠けているのではないかと思うかもしれません。分散深層学習においてデータ転送はしばしばボトルネックとなります。複数のワーカーから勾配を集約する必要があるためです。実際、インターネット上での分散トレーニングへの単純なアプローチは必ず失敗します。ほとんどの参加者はギガビットの接続を持っておらず、いつでもネットワークから切断される可能性があるためです。では、家庭用のデータプランで何かをトレーニングする方法はどうすればいいのでしょうか? 🙂 この問題の解決策として、私たちは新しいトレーニングアルゴリズム、Distributed Deep Learning in Open Collaborations(またはDeDLOC)を提案しています。このアルゴリズムの詳細については、最近公開されたプレプリントで詳しく説明しています。では、このアルゴリズムの中核となるアイデアについて見てみましょう! ボランティアと一緒にトレーニングする 最も頻繁に使用される形態の分散トレーニングにおいては、複数のGPUを使用したトレーニングは非常に簡単です。ディープラーニングを行う場合、通常はトレーニングデータのバッチ内の多くの例について損失関数の勾配を平均化します。データ並列の分散DLの場合、データを複数のワーカーに分割し、個別に勾配を計算し、ローカルのバッチが処理された後にそれらを平均化します。すべてのワーカーで平均勾配が計算されたら、モデルの重みをオプティマイザで調整し、モデルのトレーニングを続けます。以下に、実行されるさまざまなタスクのイラストを示します。 多くの場合、同期の量を減らし、学習プロセスを安定化させるために、ローカルのバッチを平均化する前にNバッチの勾配を蓄積することができます。これは実際のバッチサイズをN倍にすることと同等です。このアプローチは、最先端の言語モデルのほとんどが大規模なバッチを使用しているという観察と組み合わせることで、次のようなシンプルなアイデアに至りました。各オプティマイザステップの前に、すべてのボランティアのデバイスをまたいで非常に大規模なバッチを蓄積しましょう!この方法は、通常の分散トレーニングと完全に等価であり、簡単にスケーラビリティを実現するだけでなく、組み込みの耐障害性も持っています。以下に、それを説明する例を示します。 共同の実験中に遭遇する可能性のあるいくつかの故障ケースを考えてみましょう。今のところ、最も頻繁なシナリオは、1人または複数の参加者がトレーニング手続きから切断されることです。彼らは不安定な接続を持っているか、単に自分のGPUを他の用途に使用したいだけかもしれません。この場合、トレーニングにはわずかな遅れが生じますが、これらの参加者の貢献は現在蓄積されているバッチサイズから差し引かれます。しかし、他の参加者が彼らの勾配でそれを補ってくれるでしょう。また、さらに多くの参加者が加わる場合、目標のバッチサイズは単純により速く達成され、トレーニング手続きは自然にスピードアップします。これを以下のビデオでデモンストレーションしています。…

ハグフェイスでの夏
夏は公式に終わり、この数か月はHugging Faceでかなり忙しかったです。Hubの新機能や研究、オープンソースの開発など、私たちのチームはオープンで協力的な技術を通じてコミュニティを支援するために一生懸命取り組んできました。 このブログ投稿では、6月、7月、8月のHugging Faceで起こったすべてのことをお伝えします! この投稿では、私たちのチームが取り組んでいるさまざまな分野について取り上げていますので、最も興味のある部分にスキップすることを躊躇しないでください 🤗 新機能 コミュニティ オープンソース ソリューション 研究 新機能 ここ数か月で、Hubは10,000以上のパブリックモデルリポジトリから16,000以上のモデルに増えました!コミュニティの皆さんが世界と共有するために素晴らしいモデルをたくさん共有してくれたおかげです。そして、数字の背後には、あなたと共有するためのたくさんのクールな新機能があります! Spaces Beta ( hf.co/spaces ) Spacesは、ユーザープロファイルまたは組織hf.coプロファイルに直接機械学習デモアプリケーションをホストするためのシンプルで無料のソリューションです。GradioとStreamlitの2つの素晴らしいSDKをサポートしており、Pythonで簡単にクールなアプリを構築することができます。数分でアプリをデプロイしてコミュニティと共有することができます! 🚀 Spacesでは、シークレットの設定、カスタム要件の許可、さらにはGitHubリポジトリから直接管理することもできます。ベータ版にはhf.co/spacesでサインアップできます。以下はいくつかのお気に入りです! Chef Transformerの助けを借りてレシピを作成 HuBERTを使用して音声をテキストに変換…

Hugging Face TransformersとHabana Gaudiを使用して、BERTを事前に学習する
このチュートリアルでは、Habana GaudiベースのDL1インスタンスを使用してBERT-baseをゼロから事前トレーニングする方法を学びます。Gaudiのコストパフォーマンスの利点を活用するためにAWSで使用します。Hugging Face Transformers、Optimum Habana、およびDatasetsライブラリを使用して、マスクされた言語モデリングを使用してBERT-baseモデルを事前トレーニングします。これは、最初のBERT事前トレーニングタスクの一つです。始める前に、ディープラーニング環境をセットアップする必要があります。 コードを表示する 以下のことを学びます: データセットの準備 トークナイザのトレーニング データセットの前処理 Habana Gaudi上でBERTを事前トレーニングする 注意:ステップ1から3は、CPUを多く使用するタスクのため、異なるインスタンスサイズで実行することができます/すべきです。 要件 始める前に、以下の要件を満たしていることを確認してください DL1インスタンスタイプのクオータを持つAWSアカウント AWS CLIがインストールされていること AWS IAMユーザーがCLIで構成され、ec2インスタンスの作成と管理の権限を持っていること 役立つリソース Hugging Face TransformersとHabana…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.