Learn more about Search Results Tensorboard - Page 3

- You may be interested
- ヴァンダービルト大学とUCデービスからの...
- 「データサイエンティストになる夢を諦め...
- Hugging FaceとFlowerを使用したフェデレ...
- チューリングテスト、中国の部屋、そして...
- 「6人の女性が気候変動との戦いをリードし...
- 画像をプロンプトに変換する方法:Img2Pro...
- 「マイクロソフトの研究者たちはDeepSpeed...
- Windows 12はAIの魔法機能を搭載:テクノ...
- PEFTの概要:最先端のパラメータ効率の良...
- ChatGPTがロボットの世界に足を踏み入れる...
- OpenAIとLangChainによるMLエンジニアリン...
- マイクロソフトAI研究は、分子システムの...
- AIガバナンス:専門家との深い探求
- 「このAI論文は、超人的な数学システムの...
- Googleの研究者たちは、RO-ViTを紹介しま...

Pythonコード生成のためのLlama-2 7Bモデルのファインチューニング
約2週間前、生成AIの世界はMeta社が新しいLlama-2 AIモデルをリリースしたことによって驚かされましたその前身であるLlama-1は、LLM産業において画期的な存在であり、…

「UNETアーキテクチャの包括的なガイド | 画像セグメンテーションのマスタリング」
イントロダクション コンピュータビジョンという興奮する分野では、画像には多くの秘密と情報が含まれており、アイテムを区別し強調することが重要です。画像セグメンテーションは、画像を意味のある領域やオブジェクトに分割するプロセスであり、医療画像から自動運転や物体認識までさまざまなアプリケーションで必要です。正確で自動的なセグメンテーションは長い間課題であり、従来の手法では精度と効率が不足することがよくありました。そこで登場するのがUNETアーキテクチャです。UNETは画像セグメンテーションを革新した知能的な手法であり、そのシンプルな設計と独創的な技術により、より正確で堅牢なセグメンテーション結果を実現しました。コンピュータビジョンのエキサイティングな分野に初めて足を踏み入れる方でも、セグメンテーションの能力を向上させたい経験豊富なプラクティショナーでも、この詳細なブログ記事はUNETの複雑さを解き明かし、そのアーキテクチャ、コンポーネント、有用性を完全に理解することができます。 この記事はData Science Blogathonの一部として公開されました。 畳み込みニューラルネットワークの理解 CNNはコンピュータビジョンのタスクで頻繁に使用されるディープラーニングモデルであり、画像分類、物体認識、画像セグメンテーションなどに非常に役立ちます。CNNは主に画像から関連する情報を学習し抽出するため、視覚データ分析に非常に有用です。 CNNの重要なコンポーネント 畳み込み層: CNNは学習可能なフィルタ(カーネル)の集合で構成されており、入力画像または特徴マップに畳み込まれます。各フィルタは要素ごとの乗算と合計を適用し、特定のパターンやローカルな特徴を強調した特徴マップを生成します。これらのフィルタはエッジ、コーナー、テクスチャなど、多くの視覚要素を捉えることができます。 プーリング層: 畳み込み層によって生成された特徴マップをプーリング層を使用してダウンサンプリングします。プーリングは特徴マップの空間的な次元を削減しながら、最も重要な情報を保持し、後続の層の計算量を減らし、モデルを入力の変動に対してより抵抗力のあるものにします。最も一般的なプーリング操作は、与えられた近傍内の最大値を取るマックスプーリングです。 活性化関数: 活性化関数を使用して、CNNモデルに非線形性を導入します。畳み込み層やプーリング層の出力に要素ごとに適用し、ネットワークが複雑な関連性を理解し非線形の決定を行うことができるようにします。勾配消失問題を解決するためのシンプルさと効率性から、ReLU(Rectified Linear Unit)活性化関数がCNNでよく使用されます。 全結合層: 全結合層、または密結合層とも呼ばれるものは、取得した特徴を使用して最終的な分類または回帰操作を行います。これにより、1つの層のすべてのニューロンが次の層のすべてのニューロンに接続され、ネットワークは前の層の組み合わせ入力に基づいてグローバルな表現を学習し、高レベルの判断を行うことができます。 ネットワークは、低レベルの特徴を捉えるために畳み込み層のスタックから始まり、その後プーリング層が続きます。より深い畳み込み層はネットワークが進化するにつれてより高レベルの特徴を学習します。最後に、1つまたは複数の全結合層を使用して分類または回帰操作を行います。 全結合ネットワークの必要性 従来のCNNは通常、単一のラベルが入力画像全体に割り当てられる画像分類のジョブに適しています。一方、従来のCNNアーキテクチャは、各ピクセルをさまざまなクラスや領域に分類するセマンティックセグメンテーションのようなより詳細なタスクには問題があります。ここでFully Convolutional Networks(FCN)が活躍します。 セグメンテーションタスクにおける従来のCNNアーキテクチャの制約…

機械学習の簡素化と標準化のためのトップツール
人工知能と機械学習は、技術の進歩によって世界中のさまざまな分野に恩恵をもたらす革新的なリーダーです。競争力を保つために、どのツールを選ぶかは難しい決断です。 機械学習ツールを選ぶことは、あなたの未来を選ぶことです。人工知能の分野では、すべてが非常に速く進化しているため、「昔の犬、昔の技」を守ることと、「昨日作ったばかり」のバランスを保つことが重要です。 機械学習ツールの数は増え続けており、それに伴い、それらを評価し、最適なものを選ぶ方法を理解する必要があります。 この記事では、いくつかのよく知られた機械学習ツールを紹介します。このレビューでは、MLライブラリ、フレームワーク、プラットフォームについて説明します。 Hermione 最新のオープンソースライブラリであるHermioneは、データサイエンティストがより整理されたスクリプトを簡単かつ迅速に設定できるようにします。また、Hermioneはデータビュー、テキストベクトル化、列の正規化と非正規化など、日常の活動を支援するためのトピックに関するクラスを提供しています。Hermioneを使用する場合、手順に従う必要があります。あとは彼女が魔法のように処理してくれます。 Hydra HydraというオープンソースのPythonフレームワークは、研究やその他の目的のために複雑なアプリを作成することを容易にします。Hydraは、多くの頭を持つヒドラのように多くの関連タスクを管理する能力を指します。主な機能は、階層的な構成を動的に作成し、構成ファイルとコマンドラインを介してそれをオーバーライドする能力です。 もう一つの機能は、動的なコマンドラインのタブ補完です。さまざまなソースから階層的に構成でき、構成はコマンドラインから指定または変更できます。また、単一のコマンドでリモートまたはローカルでプログラムを起動し、さまざまな引数で複数のタスクを実行することもできます。 Koalas Koalasプロジェクトは、巨大なデータ量で作業するデータサイエンティストの生産性を向上させるために、Apache Sparkの上にpandas DataFrame APIを統合しています。 pandasは(シングルノードの)Python DataFrameの事実上の標準実装であり、Sparkは大規模なデータ処理の事実上の標準です。pandasに慣れている場合、このパッケージを使用してすぐにSparkを使用し始め、学習曲線を回避することができます。単一のコードベースはSparkとPandasに互換性があります(テスト、より小さいデータセット)(分散データセット)。 Ludwig Ludwigは、機械学習パイプラインを定義するための明確で柔軟なデータ駆動型の設定アプローチを提供する宣言的な機械学習フレームワークです。Linux Foundation AI & DataがホストするLudwigは、さまざまなAI活動に使用することができます。 入力と出力の特徴と適切なデータ型は設定で宣言されます。ユーザーは、前処理、エンコード、デコードの追加のパラメータを指定したり、事前学習モデルからデータをロードしたり、内部モデルアーキテクチャを構築したり、トレーニングパラメータを調整したり、ハイパーパラメータ最適化を実行したりするための追加のパラメータを指定できます。 Ludwigは、設定の明示的なパラメータを使用してエンドツーエンドの機械学習パイプラインを自動的に作成し、設定されていない設定にはスマートなデフォルト値を使用します。…

「機械学習モデルのログと管理のためのトップツール」
機械学習において、実験トラッキングはすべての実験メタデータを1つの場所(データベースまたはリポジトリ)に保存します。モデルのハイパーパラメータ、性能の測定値、実行ログ、モデルのアーティファクト、データのアーティファクトなど、すべてが含まれています。 実験ログの実装方法はさまざまです。スプレッドシートは1つのオプションです(もはや使用されていません!)、またはテストの追跡にGitHubを使用することもできます。 機械学習の実験を追跡することは常にMLの開発において重要なステップでしたが、以前は手間のかかる、遅くてエラーが発生しやすい手続きでした。 近年、機械学習の実験管理とトラッキングのための現代的なソリューションの市場が発展し増加しました。現在、さまざまな選択肢があります。オープンソースまたはエンタープライズソリューション、スタンドアロンの実験トラッキングフレームワーク、エンドツーエンドのプラットフォームなど、適切なツールを必ず見つけることができます。 MLFlowのようなオープンソースのライブラリやフレームワークを利用するか、Weights & Biases、Cometなどのこれらの機能を備えたエンタープライズツールプラットフォームを購入することが、実験ログを行うための最も簡単な方法です。この記事では、データサイエンティストにとって非常に役立つ実験トラッキングツールをいくつか紹介しています。 MLFlow MLflowは、実験、再現性、デプロイメント、および中央モデルレジストリを含む機械学習ライフサイクルを管理するオープンソースプラットフォームです。複数の機械学習ライブラリからモデルを異なるプラットフォームに配布およびサービングする(MLflowモデルレジストリ)機能も提供しています。MLflowは現在、MLコードを再利用可能で再現可能な形式でパッケージングする機能(MLflowプロジェクト)、パラメータと結果を記録および比較するための実験のトラッキング機能(MLflowトラッキング)をサポートしています。さらに、モデルのバージョン管理、ステージ遷移、注釈など、MLflowモデルのライフサイクル全体を共同で管理するための中央モデルストアも提供しています。 Weights & Biases Weights & Biasesは、実験トラッキング、データセットのバージョン管理、およびモデルの管理により、より速くより優れたモデルを生成するためのMLOpsプラットフォームです。Weights & Biasesはプライベートインフラストラクチャにインストールすることも、クラウドで利用することもできます。 Comet Cometは、現在のインフラストラクチャとツールと連携してモデルを管理、可視化、最適化する機械学習プラットフォームです。コード、ハイパーパラメータ、メトリックを自動的に追跡するために、スクリプトまたはノートブックに2行のコードを追加するだけで使用できます。 Cometは、ML実験の全ライフサイクルのためのプラットフォームです。コード、ハイパーパラメータ、メトリック、予測、依存関係、システムメトリックを比較してモデルのパフォーマンスの違いを分析することができます。モデルはモデルレジストリに登録して、エンジニアリングへの簡単な引き継ぎが可能であり、トレーニングランからデプロイまでの完全な監査トレイルで使用中のモデルを把握することができます。 Arize AI Arize AIは、MLチームがプロダクションでより成功したAIを提供および維持するための機械学習可観測性プラットフォームです。Arizeの自動モデルモニタリングおよび可観測性プラットフォームにより、MLチームは問題が発生したときに問題を検出し、なぜ問題が発生したかをトラブルシューティングし、モデルのパフォーマンスを管理することができます。コンピュータビジョンおよび自然言語処理モデルの非構造化データの埋め込みを監視することで、チームは次にラベル付けするデータを予測的に特定し、プロダクションでの問題をトラブルシューティングすることもできます。ユーザーはArize.comで無料アカウントにサインアップできます。…

機械学習(ML)の実験トラッキングと管理のためのトップツール(2023年)
機械学習プロジェクトを行う際に、単一のモデルトレーニング実行から良い結果を得ることは一つのことです。機械学習の試行をきちんと整理し、信頼性のある結論を導き出すための方法を持つことは別のことです。 実験トラッキングはこれらの問題に対する解決策を提供します。機械学習における実験トラッキングとは、実施する各実験の関連データを保存することの実践です。 実験トラッキングは、スプレッドシート、GitHub、または社内プラットフォームを使用するなど、さまざまな方法でMLチームによって実装されています。ただし、ML実験の管理とトラッキングに特化したツールを使用することが最も効率的な選択肢です。 以下は、ML実験トラッキングと管理のトップツールです Weight & Biases 重みとバイアスと呼ばれる機械学習フレームワークは、モデルの管理、データセットのバージョン管理、および実験の監視に使用されます。実験トラッキングコンポーネントの主な目的は、データサイエンティストがモデルトレーニングプロセスの各ステップを記録し、モデルを可視化し、試行を比較するのを支援することです。 W&Bは、オンプレミスまたはクラウド上の両方で使用できるツールです。Weights & Biasesは、Keras、PyTorch環境、TensorFlow、Fastai、Scikit-learnなど、さまざまなフレームワークとライブラリの統合をサポートしています。 Comet Comet MLプラットフォームを使用すると、データサイエンティストはモデルのトレーニングから本番まで、実験とモデルの追跡、比較、説明、最適化を行うことができます。実験トラッキングでは、データセット、コードの変更、実験履歴、モデルを記録することができます。 Cometは、チーム、個人、学術機関、企業向けに提供され、誰もが実験を行い、作業を容易にし、結果を素早く可視化することができます。ローカルにインストールするか、ホステッドプラットフォームとして使用することができます。 Sacred + Omniboard Sacredは、オープンソースのプログラムであり、機械学習の研究者は実験を設定、配置、ログ記録、複製することができます。Sacredには優れたユーザーインターフェースがないため、Omniboardなどのダッシュボードツールとリンクすることができます(他のツールとも統合することができます)。しかし、Sacredは他のツールのスケーラビリティに欠け、チームの協力のために設計されていない(別のツールと組み合わせる場合を除く)が、単独の調査には多くの可能性があります。 MLflow MLflowと呼ばれるオープンソースのフレームワークは、機械学習のライフサイクル全体を管理するのに役立ちます。これには実験、モデルの保存、複製、使用が含まれます。Tracking、Model Registry、Projects、Modelsの4つのコンポーネントは、それぞれこれらの要素を代表しています。 MLflow TrackingコンポーネントにはAPIとUIがあり、パラメータ、コードバージョン、メトリック、出力ファイルなどの異なるログメタデータを記録し、後で結果を表示することができます。…

「TransformersとTokenizersを使用して、ゼロから新しい言語モデルを訓練する方法」
ここ数か月間で、私たちはtransformersとtokenizersライブラリにいくつかの改良を加え、新しい言語モデルをゼロからトレーニングすることをこれまで以上に簡単にすることを目指しました。 この記事では、”小さな”モデル(84 Mパラメータ = 6層、768隠れユニット、12アテンションヘッド)を「エスペラント」でトレーニングする方法をデモンストレーションします。その後、モデルを品詞タグ付けの下流タスクでファインチューニングします。 エスペラントは学習しやすいことを目標とした人工言語です。このデモンストレーションのために選んだ理由は以下のとおりです: 比較的リソースが少ない言語です(約200万人が話すにもかかわらず)、このデモンストレーションはもう1つの英語モデルのトレーニングよりも面白くなります 😁 文法が非常に規則的です(例:一般的な名詞は-oで終わり、すべての形容詞は-aで終わります)。そのため、小さなデータセットでも興味深い言語的結果が得られるはずです。 最後に、この言語の基盤となる目標は人々をより近づけることです(世界平和と国際理解を促進すること)。これはNLPコミュニティの目標と一致していると言えるでしょう 💚 注:この記事を理解するためにはエスペラントを理解する必要はありませんが、学びたい場合はDuolingoには280,000人のアクティブな学習者がいる素敵なコースがあります。 私たちのモデルの名前は…待ってください…EsperBERTo 😂 1. データセットを見つける まず、エスペラントのテキストコーパスを見つけましょう。ここでは、INRIAのOSCARコーパスのエスペラント部分を使用します。OSCARは、WebのCommon Crawlダンプの言語分類とフィルタリングによって得られた巨大な多言語コーパスです。 データセットのエスペラント部分はわずか299Mですので、Leipzig Corpora Collectionのエスペラントサブコーパスと連結します。このサブコーパスには、ニュース、文学、ウィキペディアなど様々なソースのテキストが含まれています。 最終的なトレーニングコーパスのサイズは3 GBですが、モデルに先行学習するためのデータが多ければ多いほど、より良い結果が得られます。 2.…

TransformersとRay Tuneを使用したハイパーパラメータの検索
Anyscale チームの Richard Liaw によるゲストブログ投稿 最先端の研究実装や数千ものトレーニング済みモデルへの簡単なアクセスが可能な Hugging Face transformers ライブラリは、自然言語処理の成功と成長において重要な存在となっています。 良いパフォーマンスを達成するために、ほとんどのユーザーはパラメータのチューニングを行う必要があります。しかし、ほとんどの人はハイパーパラメータのチューニングを無視するか、小さな探索空間で簡素なグリッドサーチを行うことを選択します。 しかし、簡単な実験でも高度なチューニング手法の利点を示すことができます。以下は、Hugging Face transformers の BERT モデルを RTE データセットで実行した最近の実験結果です。PBT のような遺伝的最適化手法は、標準的なハイパーパラメータ最適化手法と比較して大幅なパフォーマンス向上を提供できます。 アルゴリズム 最高の検証精度 最高のテスト精度 合計…

PyTorch / XLA TPUsでのHugging Face
お気に入りのトランスフォーマーをPyTorch / XLAを使用してCloud TPUsでトレーニングする PyTorch-TPUプロジェクトは、Facebook PyTorchチームとGoogle TPUチームの共同作業として始まり、2019年のPyTorch Developer Conference 2019で正式に開始されました。それ以来、私たちはHugging Faceチームと協力して、PyTorch / XLAを使用してCloud TPUsでトレーニングをサポートするための一流のサポートを提供してきました。この新しい統合により、PyTorchユーザーはHugging Faceトレーナーインターフェースをそのまま維持しながら、Cloud TPUs上でモデルを実行しスケーリングすることができます。 このブログ記事では、Hugging Faceライブラリで行われた変更の概要、PyTorch / XLAライブラリの機能、Cloud TPUsでお気に入りのトランスフォーマーをトレーニングするための例、およびいくつかのパフォーマンスベンチマークについて説明します。TPUsで始めるのが待ちきれない場合は、「Cloud TPUsでトランスフォーマーをトレーニングする」セクションにスキップしてください – 私たちはTrainerモジュール内でPyTorch…

ハグフェイスでの夏
夏は公式に終わり、この数か月はHugging Faceでかなり忙しかったです。Hubの新機能や研究、オープンソースの開発など、私たちのチームはオープンで協力的な技術を通じてコミュニティを支援するために一生懸命取り組んできました。 このブログ投稿では、6月、7月、8月のHugging Faceで起こったすべてのことをお伝えします! この投稿では、私たちのチームが取り組んでいるさまざまな分野について取り上げていますので、最も興味のある部分にスキップすることを躊躇しないでください 🤗 新機能 コミュニティ オープンソース ソリューション 研究 新機能 ここ数か月で、Hubは10,000以上のパブリックモデルリポジトリから16,000以上のモデルに増えました!コミュニティの皆さんが世界と共有するために素晴らしいモデルをたくさん共有してくれたおかげです。そして、数字の背後には、あなたと共有するためのたくさんのクールな新機能があります! Spaces Beta ( hf.co/spaces ) Spacesは、ユーザープロファイルまたは組織hf.coプロファイルに直接機械学習デモアプリケーションをホストするためのシンプルで無料のソリューションです。GradioとStreamlitの2つの素晴らしいSDKをサポートしており、Pythonで簡単にクールなアプリを構築することができます。数分でアプリをデプロイしてコミュニティと共有することができます! 🚀 Spacesでは、シークレットの設定、カスタム要件の許可、さらにはGitHubリポジトリから直接管理することもできます。ベータ版にはhf.co/spacesでサインアップできます。以下はいくつかのお気に入りです! Chef Transformerの助けを借りてレシピを作成 HuBERTを使用して音声をテキストに変換…
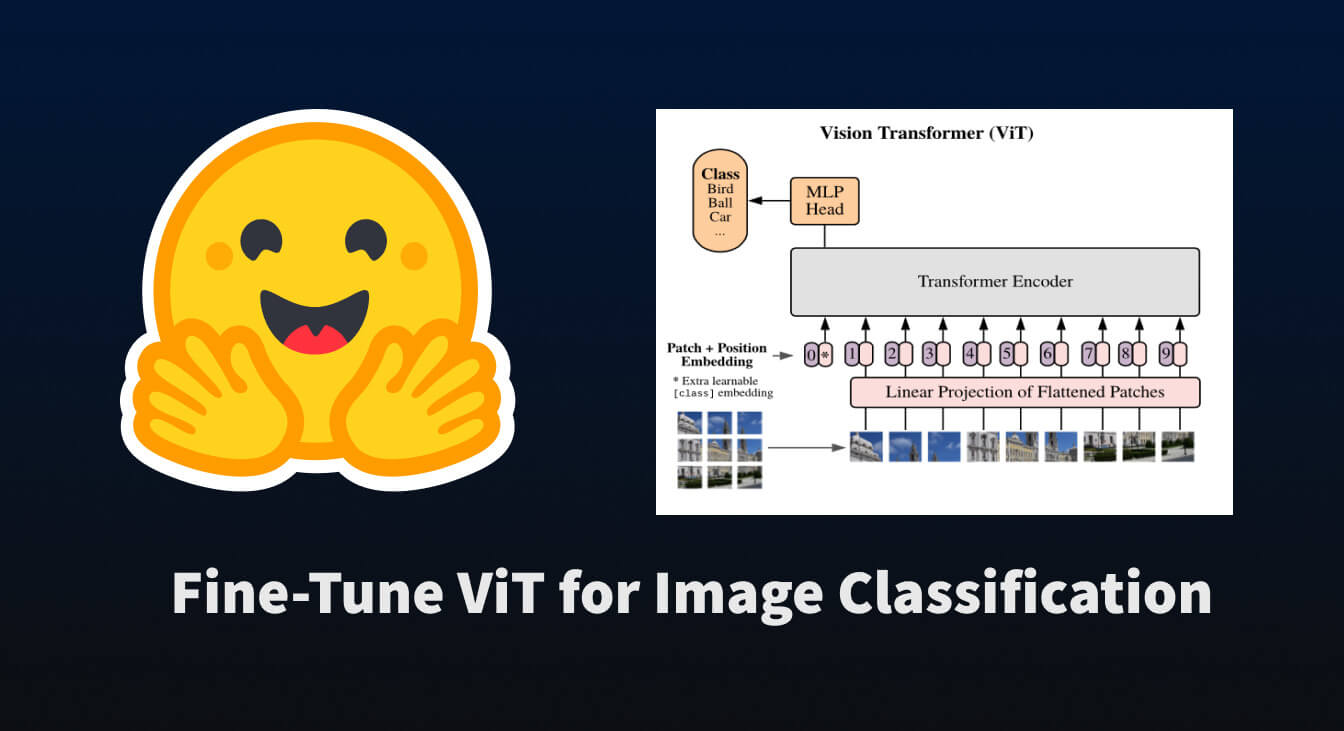
🤗 Transformersを使用して、画像分類のためにViTを微調整する
トランスフォーマーベースのモデルがNLPを革命化したように、我々は今、それらを他のさまざまな領域に適用する論文の爆発を目撃しています。その中でも最も革命的なものの一つが「Vision Transformer(ViT)」です。これは、Google Brainの研究チームによって2021年6月に紹介されました。 この論文では、文をトークン化するように画像をトークン化する方法を探求しており、それによってトランスフォーマーモデルにトレーニング用のデータとして渡すことができます。実際には非常にシンプルな概念です… 画像をサブ画像パッチのグリッドに分割する 各パッチを線形変換で埋め込む 各埋め込まれたパッチがトークンとなり、埋め込まれたパッチのシーケンスがモデルに渡される 上記の手順を実行すると、NLPのタスクと同様にトランスフォーマーを事前学習および微調整することができることがわかります。かなり便利です 😎。 このブログポストでは、🤗 datasets を使用して画像分類データセットをダウンロードおよび処理し、それを使用して事前学習済みの ViT を 🤗 transformers を使用して微調整する方法について説明します。 まずは、それらのパッケージをインストールしましょう。 pip install datasets transformers データセットの読み込み まずは、小規模な画像分類データセットを読み込んで、その構造を確認しましょう。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.