Learn more about Search Results Redis - Page 3

- You may be interested
- ビデオゲームのGPUが人工知能の発展につな...
- 「今日から使える5つの簡単なPythonの機能...
- 次回のLLM(法務修士)の申請に使用するた...
- このAI論文では、GraphGPTフレームワーク...
- 「教師なし学習の解明」
- インターネット企業が史上最大のサービス...
- このAIサブカルチャーのモットーは、「行...
- 「検索強化生成(RAG) 理論からLangChain...
- 「機械学習の方法の比較:従来の方法と費...
- 「MLを学ぶ勇気:L1とL2の正則化の解明(...
- 「ファイナンシャルアドバイザーがAIを活...
- 文法AIの向上にBERTを活用する:スロット...
- 「バイオメトリクスをサイバーセキュリテ...
- 7つの方法でChatGPTがあなたのコーディン...
- 「オープンソースAI」の神話
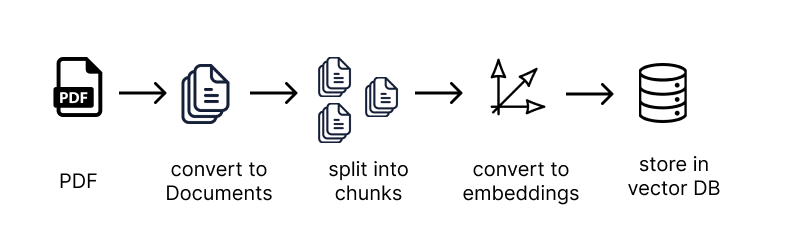
「ワイルドワイルドRAG…(パート1)」
「RAG(Retrieval-Augmented Generation)は、外部の知識源を取り込むことで言語モデルによって生成された応答の品質を向上させるAIフレームワークですこれにより、…のギャップを埋める役割を果たします」

「セマンティックカーネルへのPythonistaのイントロ」
ChatGPTのリリース以来、大規模言語モデル(LLM)は産業界とメディアの両方で非常に注目されており、これによりLLMを活用しようとする前例のない需要が生まれました...

「ScyllaDB NoSQLを使用したAI/MLフィーチャーストアの構築方法」
この記事では、AI/MLフィーチャーストアの基礎について掘り下げ、ScyllaDB NoSQLを使用して自分自身のフィーチャーストアを始める方法を探求します

「Auto-GPT&GPT-Engineer:今日の主要なAIエージェントについての詳細ガイド」
「ChatGPTとAuto-GPT&GPT-Engineerなどの自律型AIエージェントの包括的な分析に没入してください機能、セットアップガイドを探索し、労働市場への影響を理解してください」

「Declarai、FastAPI、およびStreamlitを使用してLLMチャットアプリケーションを展開する」
2022年10月、私が大規模言語モデル(LLM)の実験を始めたとき、最初の傾向はテキストの補完、分類、NER、およびその他のNLP関連の領域を探索することでしたしかし、...

キャッシング生成的LLMs | APIコストの節約
はじめに 生成AIは非常に広まっており、私たちのほとんどは、画像生成器または有名な大規模言語モデルなど、生成AIモデルを使用したアプリケーションの開発に取り組んでいるか、既に取り組んでいます。私たちの多くは、特にOpenAIなどのクローズドソースの大規模言語モデルを使用して、彼らが開発したモデルの使用に対して支払いをする必要があります。もし私たちが十分注意を払えば、これらのモデルを使用する際のコストを最小限に抑えることができますが、どういうわけか、価格はかなり上昇してしまいます。そして、この記事では、つまり大規模言語モデルに送信される応答/ API呼び出しをキャッチすることについて見ていきます。Caching Generative LLMsについて学ぶのが楽しみですか? 学習目標 Cachingとは何か、そしてそれがどのように機能するかを理解する 大規模言語モデルをキャッシュする方法を学ぶ LangChainでLLMをキャッシュするための異なる方法を学ぶ Cachingの潜在的な利点とAPIコストの削減方法を理解する この記事は、Data Science Blogathonの一部として公開されました。 Cachingとは何か?なぜ必要なのか? キャッシュとは、データを一時的に保存する場所であり、このデータの保存プロセスをキャッシングと呼びます。ここでは、最も頻繁にアクセスされるデータがより速くアクセスできるように保存されます。これはプロセッサのパフォーマンスに劇的な影響を与えます。プロセッサが計算時間がかかる集中的なタスクを実行する場合を想像してみてください。今度は、プロセッサが同じ計算を再度実行する状況を想像してみてください。このシナリオでは、前回の結果をキャッシュしておくと非常に役立ちます。タスクが実行された時に結果がキャッシュされていたため、計算時間が短縮されます。 上記のタイプのキャッシュでは、データはプロセッサのキャッシュに保存され、ほとんどのプロセスは組み込みのキャッシュメモリ内にあります。しかし、これらは他のアプリケーションには十分ではない場合があります。そのため、これらの場合はキャッシュをRAMに保存します。RAMからのデータアクセスはハードディスクやSSDからのアクセスよりもはるかに高速です。キャッシュはAPI呼び出しのコストも節約することができます。例えば、Open AIモデルに類似のリクエストを送信した場合、各リクエストに対して請求がされ、応答時間も長くなります。しかし、これらの呼び出しをキャッシュしておくと、モデルに類似のリクエストをキャッシュ内で検索し、キャッシュ内に類似のリクエストがある場合は、APIを呼び出す代わりにデータ、つまりキャッシュから応答を取得することができます。 大規模言語モデルのキャッシュ 私たちは、GPT 3.5などのクローズドソースのモデル(OpenAIなど)が、ユーザーにAPI呼び出しの料金を請求していることを知っています。請求額または関連する費用は、渡されるトークンの数に大きく依存します。トークンの数が多いほど、関連するコストも高くなります。これは大金を支払うことを避けるために慎重に扱う必要があります。 さて、APIを呼び出すコストを解決する/削減する方法の一つは、プロンプトとそれに対応する応答をキャッシュすることです。最初にモデルにプロンプトを送信し、それに対応する応答を取得したら、それをキャッシュに保存します。次に、別のプロンプトが送信される際には、モデルに送信する前に、つまりAPI呼び出しを行う前に、キャッシュ内の保存されたプロンプトのいずれかと類似しているかどうかをチェックします。もし類似している場合は、モデルにプロンプトを送信せずに(つまりAPI呼び出しを行わずに)キャッシュから応答を取得します。 これにより、モデルに類似のプロンプトを要求するたびにコストを節約することができ、さらに、応答時間も短縮されます。なぜなら、キャッシュから直接データを取得するため、モデルにリクエストを送信してから応答を取得する必要がないからです。この記事では、モデルからの応答をキャッシュするための異なる方法を見ていきます。 LangChainのInMemoryCacheを使用したキャッシュ はい、正しく読みました。LangChainライブラリを使用して、応答とモデルへの呼び出しをキャッシュすることができます。このセクションでは、キャッシュメカニズムの設定方法と、結果がキャッシュされており、類似のクエリに対する応答がキャッシュから取得されていることを確認するための例を見ていきます。必要なライブラリをダウンロードして開始しましょう。…

「AI企業がソフトウェア供給チェーンの脆弱性に対して被害を受けた場合、何が起こるのか」
OpenAIの侵害を見て、AI企業SSCのハッキングとその可能な影響を推測する自分自身を守るために何ができるか?

人工知能、IoT、深層学習、機械学習、データサイエンス、その他のソフトウェアアプリケーションに最適なトップデータベース
データベースがなければ、ほとんどのソフトウェアアプリケーションは実現不可能です。データベースは、ウェブベースのデータストレージから大量のデータをネットワークを通じて高速に転送するために必要なエンタープライズレベルのプロジェクトまで、あらゆるタイプとサイズのアプリケーションの基盤です。組み込みシステムでは、リアルタイムシステムとは異なるタイトなタイミング要件を持つ低レベルのインタフェースを見つけることができます。もちろん、データに完全に依存し、後でそれらを保存して処理するためにデータベースが必要な人工知能、ディープラーニング、機械学習、データサイエンス、HPC、ブロックチェーン、IoTなども見逃せません。 では、いくつかの主要なデータベースの種類について読んでみましょう。 Oracle: オラクルは、およそ40年にわたり、丈夫でエンタープライズグレードのデータベースを提供してきました。DB-Enginesによると、オープンソースのSQLデータベースやNoSQLデータベースとの激しい競争にもかかわらず、まだ最も使用されているデータベースシステムです。組み込みのアセンブリ言語として、C、C++、Javaを備えています。このデータベースの最新版である21cには、多数の新機能が含まれています。JSONからSQLなどの追加機能を備えた、コンパクトで高速なデータベースです。 MySQL: ウェブ開発ソリューションが最も一般的な利用方法です。MySQLはCとC++で構築された構造化クエリ言語です。MySQLのエンタープライズグレードの機能と無料で柔軟な(GPL)コミュニティライセンス、および更新された商用ライセンスは、瞬時に業界とコミュニティで有名になりました。このデータベースの主な目標は、安定性、堅牢性、成熟性です。SQLデータベースには、それぞれ独自の機能が備わったいくつかのエディションがあります。 PostgreSQL: PostgreSQLは最も高度なオープンソースの関係型データベースです。大量のデータを扱う企業で使用されるCベースのデータベース管理システムです。このデータベース管理ソフトウェアは、さまざまなゲームアプリ、データベース自動化ツール、ドメイン登録などで使用されています。 Microsoft SQL Server: MS SQLは、構造化データ(SQL)、半構造化データ(JSON)、および空間データをサポートするマルチモデルデータベースです。WindowsとLinuxオペレーティングシステムでサポートされています。過去30年間、Windowsシステム上で最も人気のある商用中堅データベースでした。マイクロソフトSQL Serverは、他のデータベースと比べて革新的または先進的ではないものの、年々大幅な改良と改装を行ってきました。開発プラットフォームが他のマイクロソフト製品と強く結びついている場合には非常に有益です。 MongoDB: オブジェクト指向プログラミング言語を使用してRDBMSでデータをロードおよび取得するには、追加のアプリケーションレベルマッピングが必要です。2009年に、特にドキュメントデータの処理に対応するために、MongoDBが最初のドキュメントデータベースとしてリリースされました。一貫性が可用性よりも重要な半構造化データに使用されます。 IBM DB2: DB2は、構造化(SQL)、半構造化(JSON)、およびグラフデータをサポートするマルチモデルデータベースです。また、IBM BLU Accelerationによる優れたOLAP機能を備えた統合データベースでもあります。DB2 LUWはWindows、Linux、Unixにも利用できます。 Redis: よく知られたオープンソースのデータベースです。Redisは、メモリ内で動作する分散キーバリューデータベースとして使用することができます。また、メッセージブローカーや分散キャッシュとしても使用できます。大量のデータを処理することができます。さまざまなデータ構造をサポートしています。 Cassandra: オープンコアで広範なカラムストアであるCassandraは、広範なデータを扱うために頻繁に使用されるデータベースです。分散型のデータベース(リーダーレス)は自動レプリケーションを備えており、障害に強くなっています。Cassandra Query Language(CQL)は、ユーザーフレンドリーでSQLに似たクエリ言語です。 Elasticsearch: 2010年にリリースされたElasticsearchは、REST APIを備えたオープンソースの分散型マルチテナント全文検索エンジンです。また、構造化データとスキーマレスデータ(JSON)の両方をサポートしており、ログ解析やモニタリングデータの分析に最適です。大量のデータを処理することができます。…

13分でハミルトンを使用したメンテナブルでモジュラーなLLMアプリケーションスタックの構築
この投稿では、オープンソースのフレームワークであるHamiltonが、大規模な言語モデル(LLM)アプリケーションスタックのために、モジュール化されて保守性の高いコードの作成をサポートする方法を共有しますHamiltonは素晴らしいです...

最適化ストーリー:ブルーム推論
この記事では、bloomをパワーアップする効率的な推論サーバーの裏側について説明します。 数週間にわたり、レイテンシーを5倍削減し(スループットを50倍に増やしました)、このような速度向上を達成するために私たちが経験した苦労やエピックな勝利を共有したかったです。 さまざまな人々が多くの段階で関与していたため、ここではすべてをカバーすることはできません。また、最新のハードウェア機能やコンテンツが定期的に登場するため、一部の内容は古くなっているか、まったく間違っている可能性があることをご了承ください。 もし、お好みの最適化手法が議論されていなかったり、正しく表現されていなかったりした場合は、お詫び申し上げます。新しいことを試してみたり、間違いを修正するために、ぜひお知らせください。 言うまでもなく、まず大きなモデルが最初にアクセス可能でなければ、それを最適化する理由はありません。これは、多くの異なる人々によってリードされた信じられないほどの取り組みでした。 トレーニング中にGPUを最大限に活用するために、いくつかの解決策が検討され、結果としてMegatron-Deepspeedが最終的なモデルのトレーニングに選ばれました。これは、コードがそのままではtransformersライブラリと互換性がない可能性があることを意味します。 元のトレーニングコードのため、通常行っていることの1つである既存のモデルをtransformersに移植することに取り組みました。目標は、トレーニングコードから関連する部分を抽出し、transformers内に実装することでした。この取り組みには「Younes」が取り組みました。これは、1ヶ月近くかかり、200のコミットが必要でした。 後で戻ってくるいくつかの注意点があります: 小さなモデルbigscience/bigscience-small-testingとbigscience/bloom-560mを用意する必要があります。これは非常に重要です。なぜなら、それらと一緒に作業するとすべてが高速化されるからです。 まず、最後のログがバイトまで完全に同じになることを望むことをあきらめる必要があります。PyTorchのバージョンがカーネルを変更し、微妙な違いを導入する可能性があり、異なるハードウェアでは異なるアーキテクチャのため異なる結果が得られる場合があります(コストの理由から常にA100 GPUで開発したくはないでしょう)。 すべてのモデルにとって、良い厳格なテストスイートを作ることは非常に重要です 私たちが見つけた最高のテストは、固定された一連のプロンプトを持つことでした。プロンプトを知っており、決定論的な結果が得られる必要があります。2つの生成物が同じであれば、小さなログの違いは無視できます。ドリフトが見られるたびに調査する必要があります。それは、あなたのコードがやるべきことをしていないか、または実際にそのモデルがドメイン外であるためにノイズに対してより敏感であるかのいずれかです。いくつかのプロンプトと十分に長いプロンプトがあれば、すべてのプロンプトを誤ってトリガーする可能性は低くなります。プロンプトが多ければ多いほど良く、プロンプトが長ければ長いほど良いです。 最初のモデル(small-testing)は、bloomと同じようにbfloat16であり、すべてが非常に似ているはずですが、それほどトレーニングされていないか、うまく機能しないため、出力が大きく変動します。そのため、これらの生成テストに問題がありました。2番目のモデルはより安定していましたが、bfloat16ではなくfloat16でトレーニングおよび保存されていました。そのため、2つの間にはエラーの余地があります。 完全に公平を期すために言えば、bfloat16→float16への変換は推論モードでは問題なさそうです(bfloat16は主に大きな勾配を扱うために存在しません)。 このステップでは、重要なトレードオフが発見され、実装されました。bloomは分散環境でトレーニングされたため、一部のコードはLinearレイヤー上でテンソル並列処理を行っており、単一のGPU上で同じ操作を実行すると異なる結果が得られていました。これを特定するのにかなりの時間がかかり、100%の準拠を選択した場合、モデルの速度が遅くなりましたが、少しの差がある場合は実行が速く、コードがシンプルになりました。設定可能なフラグを選択しました。 注:この文脈でのパイプライン並列処理(PP)は、各GPUがいくつかのレイヤーを所有し、各GPUがデータの一部を処理してから次のGPUに渡すことを意味します。 これで、動作可能なtransformersのクリーンなバージョンがあり、これに取り組むことができます。 Bloomは352GB(176Bパラメーターのbf16)のモデルであり、それに合わせるために少なくともそれだけのGPU RAMが必要です。一時的に小さなマシンでCPUにオフロードすることを検討しましたが、推論速度が桁違いに遅くなるため、それを取り下げました。 次に、基本的にはパイプラインを使用したかったのです。つまり、ドッグフーディングであり、これがAPIが常に裏で使用しているものです。 ただし、pipelinesは分散意識がありません(それがその目的ではありません)。オプションを簡単に話し合った後、新しく作成されたdevice_map="auto"を使用してモデルのシャーディングを管理するためにaccelerateを使用することにしました。いくつかのバグを修正し、transformersのコードを修正してaccelerateが正しい仕事をするのを助ける必要がありました。 これは、transformersのさまざまなレイヤーを分割し、各GPUにモデルの一部を与えて動作させることで機能します。つまり、GPU0が作業を行い、次にGPU1に引き渡し、それ以降同様に行います。 最終的には、上に小さなHTTPサーバーを置くことで、bloom(大規模なモデル)を提供できるようになりました!…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.