Learn more about Search Results RecursiveCharacterTextSplitter - Page 3

- You may be interested
- 「Jais アラビア語-英語の大規模言語モデ...
- 「データ自体よりもデータ生成プロセスを...
- 10月のためにぜひおそろいを揃えましょう...
- 『トランスフォーマーの位置符号化の解説』
- 「データサイエンティストがより多くの利...
- Hugging Face Unity APIのインストールと...
- 「One-2-3-45++に出会ってみましょう:お...
- このAI論文では、革新的なAIフレームワー...
- 『MakeBlobs + フィクショナルな合成デー...
- 「SDXL 1.0の登場」
- 日本の介護施設はビッグデータを活用して...
- メタのボイスボックス:すべての言語を話すAI
- 「インテリアデザインのための中間プロン...
- 「最もテクノロジー志向のある米国の都市...
- ‘Perceiver IO どんなモダリティに...

「LangChainとOpenAI APIを使用した生成型AIアプリケーションの構築」
イントロダクション 生成AIは、現在の技術の最先端をリードしています。画像生成、テキスト生成、要約、質疑応答ボットなど、生成AIアプリケーションが急速に拡大しています。OpenAIが最近大規模な言語モデルの波を牽引したことで、多くのスタートアップがLLMを使用した革新的なアプリケーションの開発を可能にするツールやフレームワークを開発しました。そのようなツールの一つがLangChainです。LangChainは、LLMによるアプリケーションの構築を可能にする柔軟性と信頼性を備えたフレームワークです。LangChainは、世界中のAI開発者が生成AIアプリケーションを構築するための定番ツールとなっています。LangChainは、外部データソースと市場で利用可能な多くのLLMとの統合も可能にします。また、LLMを利用したアプリケーションは、後で取得するデータを格納するためのベクトルストレージデータベースが必要です。この記事では、OpenAI APIとChromaDBを使用してアプリケーションパイプラインを構築することで、LangChainとその機能について学びます。 学習目標: LangChainの基礎を学んで生成AIパイプラインを構築する方法を学ぶ オープンソースモデルやChromadbなどのベクトルストレージデータベースを使用したテキスト埋め込み LangChainを使用してOpenAI APIを統合し、LLMをアプリケーションに組み込む方法を学ぶ この記事は、データサイエンスブログマラソンの一環として公開されました。 LangChainの概要 LangChainは、最近大規模言語モデルアプリケーションのための人気のあるフレームワークになりました。LangChainは、LLM、外部データソース、プロンプト、およびユーザーインターフェースとの対話を提供する洗練されたフレームワークを提供しています。 LangChainの価値提案 LangChainの主な価値提案は次のとおりです: コンポーネント:これらは言語モデルで作業するために必要な抽象化です。コンポーネントはモジュール化されており、多くのLLMの使用例に簡単に適用できます。 既製のチェーン:特定のタスク(要約、Q&Aなど)を達成するためのさまざまなコンポーネントとモジュールの構造化された組み立てです。 プロジェクトの詳細 LangChainはオープンソースプロジェクトであり、ローンチ以来、54K+のGithubスターを集めています。これは、プロジェクトの人気と受け入れられ方を示しています。 プロジェクトのreadmeファイルでは、次のようにフレームワークを説明しています: 大規模言語モデル(LLM)は、以前は開発者ができなかったアプリケーションを作成するための変革的な技術として現れつつあります。ただし、これらのLLMを単独で使用するだけでは、本当に強力なアプリを作成するには不十分なことがしばしばあります。真のパワーは、他の計算ソースや知識と組み合わせるときに発揮されます。 出典:プロジェクトリポジトリ 明らかに、フレームワークの目的を定義し、ユーザーの知識を活用したアプリケーションの開発を支援することを目指しています。 LangChainコンポーネント(出典:ByteByteGo) LangChainには、LLMアプリケーションを構築するための6つの主要なコンポーネントがあります:モデルI/O、データ接続、チェーン、メモリ、エージェント、およびコールバック。このフレームワークは、OpenAI、Huggingface Transformers、Pineconeやchromadbなどのベクトルストアなど、多くのツールとの統合も可能にします。…

テキストデータのチャンキング方法-比較分析
自然言語処理(NLP)における「テキストチャンキング」プロセスは、非構造化テキストデータを意味のある単位に変換することを意味しますこの見かけ上シンプルなタスクには、複雑さが隠されています

自分自身のデータを使用して、要約と質問応答のために生成型AI基盤モデルを使用してください
大規模言語モデル(LLM)は、複雑なドキュメントを分析し、要約や質問への回答を提供するために使用することができますAmazon SageMaker JumpStart上の金融データにおけるファインチューニングに関する記事「Foundation Modelsのドメイン適応ファインチューニング」では、独自のデータセットを使用してLLMをファインチューニングする方法について説明しています一度しっかりとしたLLMを手に入れたら、そのLLMを公開したいと思うでしょう

「AI駆動の洞察:LangChainとPineconeを活用したGPT-4」
「質的データと効果的に取り組むことは、プロダクトマネージャーが持つべき最も重要なスキルの一つですデータを収集し、分析し、効率的な方法で伝えることができるようにすることは、...」
ドキュメント指向エージェント:ベクトルデータベース、LLMs、Langchain、FastAPI、およびDockerとの旅
ChromaDB、Langchain、およびChatGPTを活用した大規模ドキュメントデータベースからの強化された応答と引用されたソース
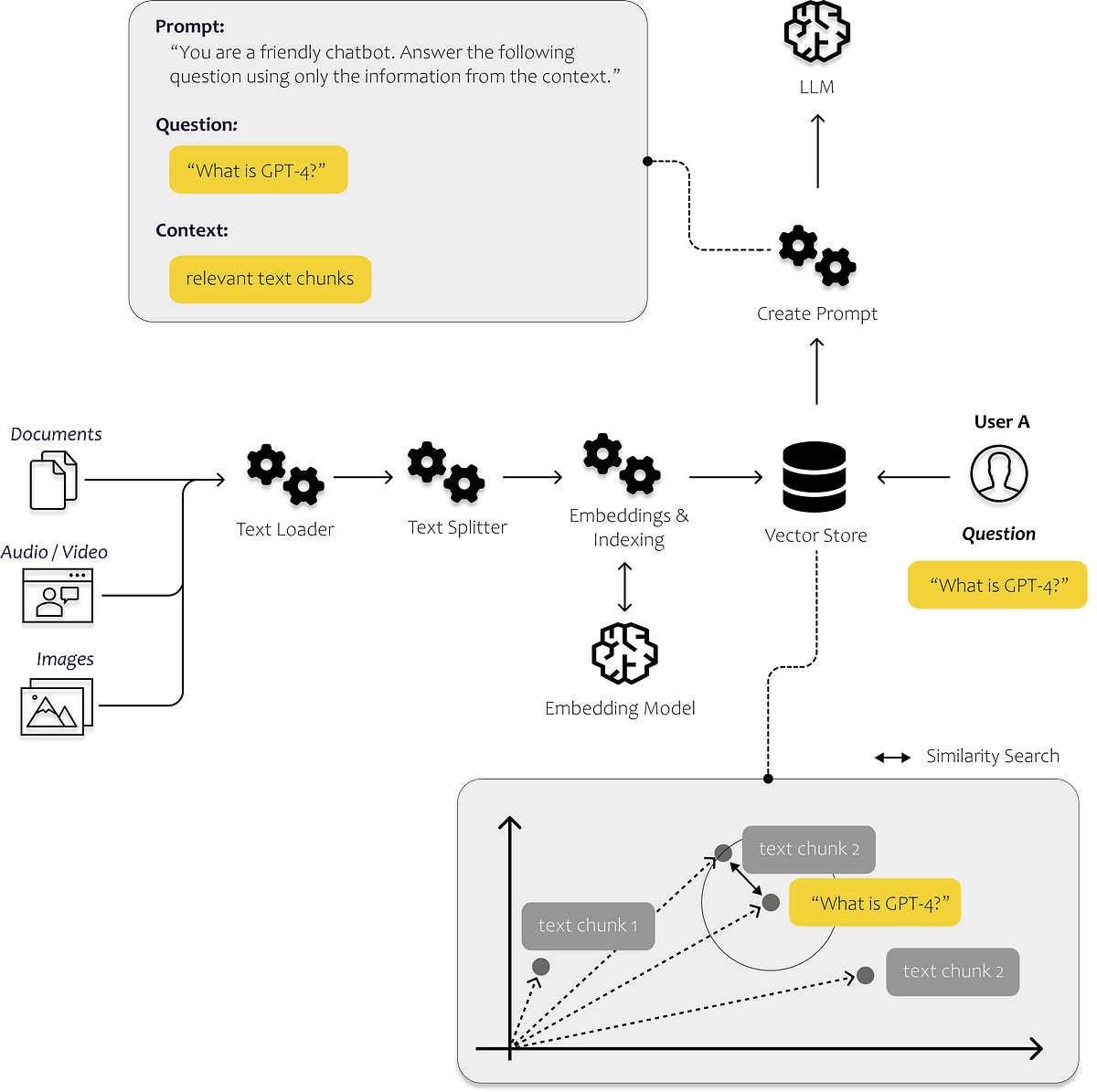
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...

GPT4Allは、あなたのドキュメント用のローカルChatGPTであり、無料です!
あなたのラップトップにGPT4Allをインストールし、AIにあなた自身のドメイン知識(あなたのドキュメント)について尋ねる方法... そして、それはCPUのみで動作します!
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.