Learn more about Search Results ROUGE - Page 3

- You may be interested
- 「生産性を最大化するための5つの最高のAI...
- DataHour ChatGPTの幻視を80%減らす
- 「挑戦受けた:GeForce NOWが究極の挑戦と...
- 「TensorFlowを使用した異常検出のための...
- 「データサイエンスをマスターするための...
- 十年生のためのニューラルネットワークの...
- 「IBMの研究者たちは、モダリティやタスク...
- 音声認証システムのセキュリティはどの程...
- 「科学者たちが侵略的なカルプを裏切り者...
- ビデオスワップに会おう:対話型意味ポイ...
- 「もっとゲーム、もっと勝利:6ヶ月のGeFo...
- A/Bテストの意味を理解する:厳しい質問で...
- 「InVideoレビュー:2023年11月の最高のAI...
- 「MLOpsの考え方:常に本番準備完了」
- 「人物再識別入門」

2023年に知っておくべきトップ13の自然言語処理プロジェクト
2023年の最先端の技術である自然言語処理(NLP)の世界へようこそ!この記事では、初心者から上級のデータプロフェッショナルが言語処理能力を高めるために使用できるトップ13のNLPプロジェクトをリストアップしています。名前付きエンティティ認識からインスピリングな引用生成まで、これらのプロジェクトを通じてNLPの力を活用し、データ分析への意義深い貢献ができます。 詳細を学ぶ:自然言語処理 | PythonでのNLP トップ13のNLPプロジェクト 出典:BlumeGlobal 1. 名前付きエンティティ認識(NER) 名前付きエンティティ認識(NER)は、与えられたテキストから人物、組織、場所、日付などの名前付きアイテムを認識・分類する自然言語処理の基本的なタスクです。 目的 この研究の目的は、テキスト内の名前付きアイテムを自動的に識別・分類できるNERシステムを作成し、非構造化データから重要な情報を抽出することです。 データセットの概要とデータ前処理 このプロジェクトには、注釈付きエンティティを含むテキストのラベル付きデータセットが必要です。NERの一般的なデータセットには、CoNLL-2003、OntoNotes、Open Multilingual Wordnetなどがあります。 データ前処理にはトークン化が含まれます テキストのトークン化 数値表現への変換 注釈のノイズや不整合の処理 分析のためのクエリ テキスト内の名前付きエンティティ(人物、組織、場所など)を識別・分類する。 テキストで言及される異なるエンティティ間の関係を抽出する。 主な洞察と結果 NERシステムは、提供されたテキスト内の名前付きエンティティを正確に認識・分類することができます。これは情報抽出タスク、感情分析、その他のNLPアプリケーションにおいて非構造化データから洞察を得るために使用することができます。…
大規模言語モデルの挙動を監視する7つの方法
自然言語処理の世界では、大規模言語モデル(LLM)の使用による急速な進化が見られています彼らの印象的なテキスト生成およびテキスト理解能力を通じて、LLMは...

スタンフォード大学の研究者たちは、「ギスティング:言語モデルにおける効率的なプロンプト圧縮のための新しい技術」というものを紹介しました
モデルの特殊化は、事前に学習された機械学習モデルを特定のタスクやドメインに適応させることを意味します。言語モデル(LM)では、モデルの特殊化は、要約、質問応答、翻訳、言語生成など、さまざまなタスクでのパフォーマンス向上に重要です。言語モデルを特定のタスクに特殊化するための2つの主なプロセスは、命令の微調整(事前に学習されたモデルを新しいタスクまたは一連のタスクに適応させること)とモデルの蒸留(事前に学習された「教師」モデルから小型の特殊化された「学生」モデルに知識を転送すること)です。プロンプティングは、LMの特殊化の分野で重要な概念であり、特定の動作にモデルを誘導する方法を提供し、限られたトレーニングデータのより効率的な使用を可能にし、最先端のパフォーマンスを実現するために重要です。プロンプトの圧縮は、計算、メモリ、ストレージの大幅な節約と、出力の全体的なパフォーマンスや品質の実質的な低下をもたらすことを目指して研究されている手法です。 この論文は、スタンフォード大学の研究者によって発表されたもので、プロンプトの圧縮のための新しい手法である「gisting」を提案しています。これは、LMを訓練してプロンプトをより小さな「gist」トークンのセットに圧縮する方法です。プロンプトのコストを削減するためには、微調整や蒸留のような技術を使用して、プロンプトなしで元のモデルと同じように振る舞うモデルを訓練することができますが、その場合、モデルは新しいプロンプトごとに再訓練する必要があり、理想的な状況からはほど遠いです。一方、gistingのアイデアは、メタ学習のアプローチを使用してプロンプトからgistトークンを予測することで、タスクごとにモデルを再訓練することなく、未知の命令に対しても汎化させることができます。これにより、計算コストが削減され、プロンプトを圧縮してキャッシュ化し、計算効率を向上させることができます。また、限られたコンテキストウィンドウにより多くのコンテンツを収めることも可能になります。 著者たちは、このようなモデルを実現するための簡単な方法を試みました。彼らはLM自体(その事前の知識を活用)を使用して、命令の微調整中にgistトークンを予測し、Transformerのアテンションマスクを修正しました。タスクと入力のペアが与えられた場合、彼らはタスクと入力の間にgistトークンを追加し、アテンションマスクを次のように設定しました:gistトークンの後の入力トークンは、gistトークンの前のプロンプトトークンのいずれにもアテンションを向けることができません(ただし、gistトークンにはアテンションを向けることができます)。入力と出力がプロンプトにアテンションを向けることができないため、モデルはプロンプトの情報をgistトークンに圧縮する必要があります。gistモデルを訓練するためには、さまざまなタスクの多様なデータセットが必要でしたので、彼らはAlpaca+と呼ばれるデータセットを作成しました。これは、2つの既存の命令微調整データセット(Standford AlpacaとSelf-Instruct)のデータを組み合わせたもので、合計で13万以上の例が含まれています。その後、トレーニング後にモデルを検証するために3つのバリデーションスプリット(Seen、Unseen、手作りのHuman prompts)を保持しました。これにより、未知の命令に対する汎化性能をテストすることができました。Human splitは、さらに強力な汎化の課題を提供します。また、複数のLMアーキテクチャ(具体的にはLLaMA-7Bm、デコーダのみのGPTスタイルのモデル、およびFLAN-T5-XXL)を使用し、gistトークンの数(1、2、5、または10)を変えながらgistモデルを訓練しました。しかし、結果は、モデルが一般にgistトークンの数に対して敏感でなく、場合によっては、トークンの数が多いほうがパフォーマンスに悪影響を及ぼすことさえ示していました。したがって、残りの実験には単一のgistモデルを使用しました。 プロンプトの圧縮の品質を評価するために、彼らは陽性コントロールとしてのパフォーマンスを調整し、効果的に標準的な命令微調整を提供し、パフォーマンスの上限を示しました。また、モデルが命令にアクセスできず、ランダムなgistトークンが生成されるネガティブコントロールも使用し、パフォーマンスの下限を示しました。彼らは、モデルの出力を陽性コントロールと比較し、その勝率を測定するためにChatGPTによってどちらの応答がより良いかを選択させ、その理由を説明しました。また、単純な語彙の重複統計であるROUGE-L(オープンエンドの命令微調整で生成されたテキストと人間が書いた命令の類似性を測定する指標)も使用しました。50%の勝率は、プロンプトの圧縮を行わないモデルと同等の品質のモデルであることを示します。 結果は、Seenの指示では、要約モデルが陽性対照モデルに非常に近い勝率を持っていることを示しました。LLaMAは48.6%、FLAN-T5は50.8%の勝率です。さらに重要なことに、要約モデルは未知のプロンプトに対しても競争力のある一般化を示すことができました。LLaMAは49.7%、FLAN-T5は46.2%の勝率です。最も難しいHuman splitでは、わずかな勝率の低下が見られましたが(それでも競争力があります)、LLaMAは45.8%、FLAN-T5は42.5%の勝率です。FLAN-T5のわずかに悪い性能と特定の失敗事例は、将来の論文でさらに検証すべき仮説をもたらしました。 研究者たちはまた、研究の主な動機である要約によって実現できる潜在的な効率の向上も調査しました。その結果は非常に励みになりました。要約キャッシングによってFLOPsが40%削減され、最適化されていないモデルと比較して壁時計時間が4-7%低下しました。これらの改善は、デコーダのみの言語モデルでは小さいとわかりましたが、研究者たちはまた、要約モデルによって未知のプロンプトを26倍圧縮できることを示しました。これにより、入力コンテキストウィンドウにかなりの追加スペースが提供されます。 全体的に、これらの結果は、要約が専門的な言語モデルの有効性と効率を向上させるための大きな潜在能力を示しています。著者たちはまた、要約に関する追加の研究のためのいくつかの有望な方向性を提案しています。例えば、要約から最も大きな計算および効率の利益は、より長いプロンプトの圧縮から得られると述べており、「要約の事前学習」は、まず自然言語の任意の範囲を圧縮することを学習してからプロンプトの圧縮を改善することができると示唆しています。

新しいAI研究が「方向性刺激プロンプティング(DSP)」を導入:望ましい要約を生成するためにLLMをより適切に導くための新しいプロンプティングフレームワーク
自然言語処理(NLP)は、最近の大規模言語モデル(LLM)の出現により、従来の比較的小さな言語モデル(LM)であるGPT-2やT5 Raffel et al.などを上回る性能を示すようになり、さまざまなNLPタスクでパラダイムシフトを経験しています。プロンプトは、LLMを使用して自然言語の指示を使用してさまざまなタスクを実行するための事実上の方法であり、パラメータの更新なしにLLMを誘導して望ましい出力を生成させるための方法です。これに対して、従来のファインチューニングパラダイムでは、LMのパラメータを各ダウンストリームタスクごとに更新することができます。 このプロンプトスキーマにより、LLMはゼロショットまたはフューショットの環境でさまざまなタスクで非常によいパフォーマンスを発揮することができますが、特定のダウンストリームタスクにおけるパフォーマンスはまだ改善が必要であり、特にトレーニングデータが利用可能な場合には追加の改良が必要です。それにもかかわらず、ほとんどのLLMはブラックボックスの推論APIのみを提供し、ファインチューニングにはコストがかかるため、ほとんどのユーザーや研究者はこれらのLLMを直接最適化することはできません。したがって、解決する必要のある難しいトピックは、トレーニングインスタンスが限られている場合にどのように効果的にLLMのパフォーマンスを向上させるか、です。カリフォルニア大学サンタバーバラ校とマイクロソフトの新しい研究では、指向性刺激プロンプティング(DSP)アーキテクチャを提案しています。このアーキテクチャは、小さなチューナブルLM(RL)を使用して、凍結されたブラックボックスLLMをダウンストリームタスクで強化するものです。 ソース:https://arxiv.org/pdf/2302.11520.pdf | 図1:通常のプロンプトアプローチと提案された指向性刺激プロンプティングを使用した要約タスクに使用される時間の比較。この例では、キーワードが刺激として使用され、それからLLMによって所望の要約がよりスコアリングスコアや他のメトリック(青色でハイライト表示)で提供されるように指示します。 具体的には、各入力テキストに対して、小さなLM(ポリシーLMと呼ばれる)が指示された刺激として一連の離散トークンを提供し、ジョブに対する一般的なキューではなく、入力サンプルに関する特定の情報や指示を提供するように学習します。目的の目標、例えばパフォーマンスメジャースコアの向上などに向けて、作成された刺激は元の入力とブレンドされ、LLMに供給されます。彼らは最初に、収集されたわずかなトレーニングサンプルを使用して、事前トレーニングされたLMを使用した教師ありファインチューニング(SFT)を行います。トレーニングは、ポリシーLMによって生成される刺激に基づいてLLM生成のダウンストリームパフォーマンスメジャーのスコアを最大化することを目指しています。より良い刺激を探索するための追加の最適化の後、洗練されたLMはRLでポリシーLMを初期化します。 図1は要約のジョブのサンプルを示しています。キーワードに基づいて必要な要約をLLMに生成させるために、キーワードは刺激(ヒント)として機能します。ポリシーLMは、ROUGEなどの評価メトリックスコアをインセンティブとして使用して最適化することができ、LLMがより良い要約を生成するためにポリシーLMがキーワードを提供するようにします。LLMは優れた生成スキルを持っていますが、しばしば望ましくない振る舞いを示すため、特定のダウンストリームタスクにおいて意図した生成特性と方向に対する詳細なガイダンスが必要です。これが彼らの提案手法の基礎です。小さなポリシーLMは、サンプルごとの細かいガイダンスを意図した目標に向けて提供するための一連のトークンを生成することができますが、人間の話し言葉に似たテキストを生成することはできません。 従来の研究がクエリをより明確に説明しようとするプロンプトエンジニアリング/最適化を介して最適なプロンプトを見つけるのに対して、RLは最適化されたオブジェクト(例:刺激を生成する小さなポリシーLM)とLLM生成によって定義される最適化目標とのギャップを埋める自然な解決策を提供します。彼らのアプローチは、各「質問」に対して「ヒント」または「手がかり」を提供しようとするものであり、推論タスクを解決する際に中間の推論ステップを生成することを促すチェーンオブソートプロンプティングとは異なります。彼らのアプローチは、1つの正しい「答え」だけではない生成タスクを対象とし、小さなチューナブルモデルを使用してLLMを制御およびガイドし、要約および対話応答生成タスクでフレームワークを評価しています。 たとえば、刺激を作り出す小さなポリシーLMは最適化されたオブジェクトですが、LLMの生成は最適化の目標を決定します。RLはこのギャップを埋めるための簡単な方法を提供します。以前の研究とは異なり、この研究ではプロンプトエンジニアリングや最適化を使用して「質問」を明確にしようと試みます。彼らの戦略は、各「質問」に対して「ヒント」や「手がかり」を提供することを目指しています。また、論理を必要とするタスクを完了する際に、Mindが独自の推論の中間ステップを生成することを奨励するチェーンオブソートプロンプティングとは異なります。彼らの手法は、複数の有効な「応答」を生成するジョブを対象とし、シンプルな調整可能なモデルを使用してLLMを制御・誘導します。ディスカッションの応答や要約の開発を必要とする課題に対して、彼らのフレームワークを評価します。テストでは、750M Flan-T5-largeをポリシーLMとし、175B CodexをLLMとして使用します。テスト結果によると、Codexは調整されたT5が生成した指示に依存すると、下流のタスクでのパフォーマンスが著しく向上します。要約に含まれるべきキーワードは、要約ジョブへの誘導刺激として使用されます。CNN/Daily Mailデータセットから2,000のサンプルを使用してトレーニングされたT5を使用することで、すでにCodexのパフォーマンスは7.2%向上しています。 MultiWOZデータセットからの500の対話に対して、意図された応答の背後の意味を指定する会話アクトを開発するために、彼らはポリシーLMをトレーニングします。ポリシーLMによって生成された対話アクションにより、Codexのパフォーマンスは合計スコアで52.5%向上しました。これにより、以前の完全なトレーニングデータ(8438の対話)でトレーニングされたシステムと同等またはそれ以上の性能を発揮します。

GenAIOps:MLOpsフレームワークの進化
「2019年には、私はLinkedInのブログを公開しましたタイトルは『成功するためになぜML Opsが必要か』でした今日になって、分析、機械学習(ML)、人工知能(AI)を運用化することが求められています...」

メタからのLlama 2基盤モデルは、Amazon SageMaker JumpStartで利用可能になりました
「本日、Metaによって開発されたLlama 2 ファウンデーションモデルがAmazon SageMaker JumpStartを通じてお客様に提供できることを喜んでお知らせしますLlama 2 ファミリーは、7兆から700兆のパラメータを持つ事前学習および微調整済みの生成テキストモデルのコレクションです微調整済みのLLMはLlama-2-chatと呼ばれています」

エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Raffel et al.(2019)、Zhang et al.(2020)、Zaheer et al.(2020)、Yan et al.(2020)などにおいて大きな関心を集めています。 BERTやGPT2と同様に、大規模な事前学習済みエンコーダーデコーダーモデルは、Lewis et al.(2019)、Raffel et al.(2019)などのさまざまなシーケンス対シーケンスのタスクにおいて性能を大幅に向上させることが示されています。しかし、エンコーダーデコーダーモデルの事前学習には膨大な計算コストがかかるため、そのようなモデルの開発は主に大企業や研究所に限定されています。 Sascha Rothe、Shashi Narayan、Aliaksei Severynによる「シーケンス生成タスクのための事前学習済みチェックポイントの活用」(2020)では、事前学習済みのエンコーダーやデコーダーのみのチェックポイント(例:BERT、GPT2)でエンコーダーデコーダーモデルを初期化して、コストのかかる事前学習をスキップする方法が紹介されています。著者らは、このようなウォームスタートされたエンコーダーデコーダーモデルが、T5やPegasusなどの大規模な事前学習済みエンコーダーデコーダーモデルと比較して、複数のシーケンス対シーケンスのタスクで競争力のある結果をもたらすことを示しています。 このノートブックでは、エンコーダーデコーダーモデルをウォームスタートする方法の詳細を説明し、Rothe et…
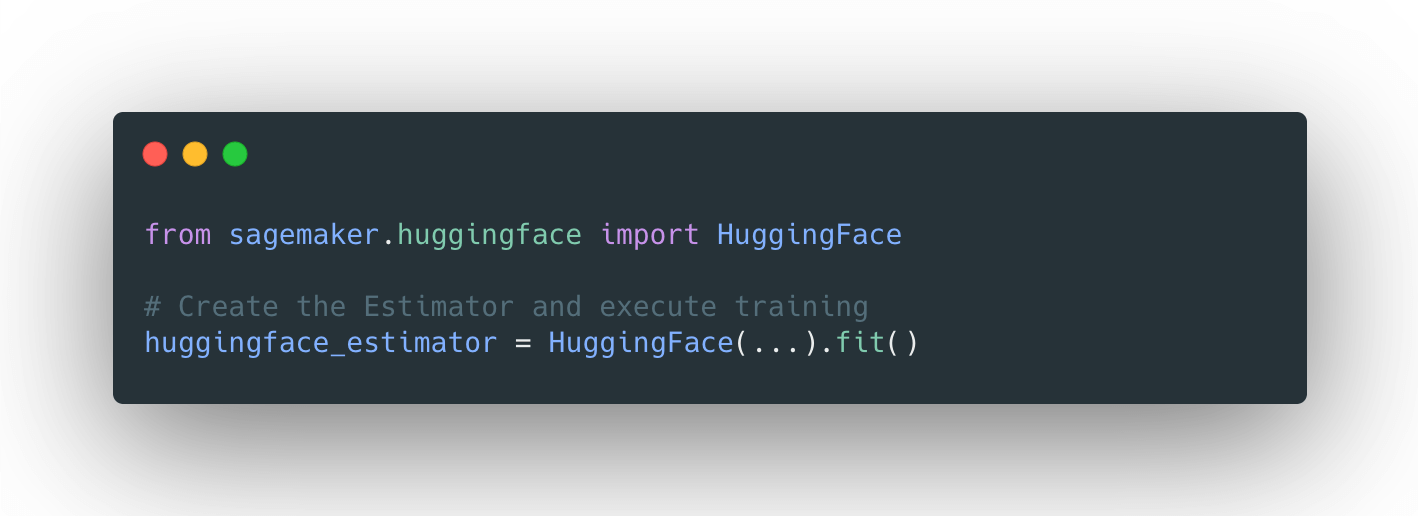
分散トレーニング:🤗 TransformersとAmazon SageMakerを使用して、要約のためにBART/T5をトレーニングする
見逃した場合: 3月25日にAmazon SageMakerとのコラボレーションを発表しました。これにより、最新の機械学習モデルを簡単に作成し、先進的なNLP機能をより速く提供できるようになりました。 SageMakerチームと協力して、🤗 Transformers最適化のDeep Learning Containersを構築しました。AWSの皆さん、ありがとうございます!🤗 🚀 SageMaker Python SDKの新しいHuggingFaceエスティメーターを使用すると、1行のコードでトレーニングを開始できます。 発表のブログ投稿では、統合に関するすべての情報、”はじめに”の例、ドキュメント、例、および機能へのリンクが提供されています。 以下に再掲します: 🤗 Transformers ドキュメント: Amazon SageMaker サンプルノートブック Hugging Face用のAmazon SageMakerドキュメント Hugging Face用のPython…

人間のフィードバックからの強化学習(RLHF)の説明
この記事は以下の言語に翻訳されています:中国語(簡体字)とベトナム語。他の言語に翻訳に興味がありますか?nathan at huggingface.co までお問い合わせください。 言語モデルは、過去数年間に人間の入力プロンプトから多様で魅力的なテキストを生成する能力を示してきました。しかし、「良い」テキストとは何かは、主観的で文脈に依存するため、本質的に定義するのは難しいです。創造性を求める物語の執筆などの多くのアプリケーションでは、真実であるべき情報の断片、または実行可能なコードのスニペットなどが必要です。 これらの属性を捉えるための損失関数を作成することは困難であり、ほとんどの言語モデルはまだ単純な次のトークン予測の損失(例:クロスエントロピー)で訓練されています。損失自体の欠点を補うために、人々はBLEUやROUGEなど、人間の優先順位をより適切に捉えるように設計されたメトリクスを定義しています。これらのメトリクスは、パフォーマンスを測定する上で損失関数自体より適しているものの、生成されたテキストを単純なルールで参照テキストと比較するだけなので、制約もあります。生成されたテキストに対する人間のフィードバックをパフォーマンスの指標として使用するか、さらに進んでそのフィードバックを損失としてモデルを最適化することができれば、素晴らしいことではないでしょうか?それが「人間のフィードバックによる強化学習(RLHF)」のアイデアです。強化学習の手法を使用して、言語モデルを人間のフィードバックで直接最適化するのです。RLHFにより、言語モデルは一般的なテキストデータのコーパスで訓練されたモデルを複雑な人間の価値に合わせることができるようになりました。 RLHFの最近の成功例は、ChatGPTでの使用です。ChatGPTの印象的な能力を考慮して、RLHFについて説明してもらいました: それは驚くほどうまくいっていますが、すべてをカバーしているわけではありません。それらのギャップを埋めましょう! 人間のフィードバックによる強化学習(RL from human preferencesとも呼ばれます)は、複数のモデルのトレーニングプロセスと異なる展開の段階を伴うため、難しい概念です。このブログ記事では、トレーニングプロセスを次の3つの主要なステップに分解します: 言語モデル(LM)の事前トレーニング データの収集と報酬モデルのトレーニング 強化学習によるLMの微調整 まず、言語モデルの事前トレーニングについて見ていきましょう。 言語モデルの事前トレーニング RLHFの出発点として、クラシカルな事前トレーニング目標で既に事前トレーニングされた言語モデルを使用します(詳細については、このブログ記事を参照してください)。OpenAIは、最初の人気のあるRLHFモデルであるInstructGPTに対して、より小さなバージョンのGPT-3を使用しました。Anthropicは、このタスクのためにトレーニングされた1,000万から520億のパラメータを持つトランスフォーマーモデルを使用しました。DeepMindは、2800億のパラメータモデルGopherを使用しました。 この初期モデルは、追加のテキストや条件で微調整することもできますが、必ずしも必要ではありません。たとえば、OpenAIは「好ましい」とされる人間が生成したテキストを微調整し、Anthropicは彼らの「助けになり、正直で無害な」基準に基づいて元のLMを蒸留することで、RLHFのための初期LMを生成しました。これらは共に、私が高価な増強データと呼ぶものの一部ですが、RLHFを理解するために必要なテクニックではありません。 一般的に、「どのモデル」がRLHFの出発点として最適かは明確な答えがありません。このブログ記事では、RLHFのトレーニングにおけるオプションの設計空間が完全に探索されていないという共通のテーマになります。 次に、言語モデルが必要なデータを生成して、人間の優先順位がシステムに統合される「報酬モデル」をトレーニングする必要があります。 報酬モデルのトレーニング 人間の優先順位に合わせてキャリブレーションされた報酬モデル(RM、優先モデルとも呼ばれます)を生成することは、RLHFの比較的新しい研究の出発点です。その基本的な目標は、テキストのシーケンスを受け取り、数値で人間の優先順位を表すべきスカラー報酬を返すモデルまたはシステムを取得することです。システムはエンドツーエンドのLMであるか、報酬を出力するモジュラーシステム(例:モデルが出力をランク付けし、ランキングが報酬に変換される)である場合があります。出力がスカラーの報酬であることは、既存のRLアルゴリズムが後のRLHFプロセスにシームレスに統合されるために重要です。 報酬モデリングのためのこれらの言語モデルは、別の微調整された言語モデルまたは好みのデータでスクラッチからトレーニングされた言語モデルのいずれかです。例えば、Anthropicは、これらのモデルを事前トレーニング(好みモデルの事前トレーニング、PMP)の後に初期化するために専門の微調整方法を使用しています。彼らは、これが微調整よりもサンプル効率が高いと結論付けましたが、報酬モデリングのバリエーションの中で明確な最良の選択肢はありません。…

より小さい相手による言語モデルからの知識蒸留に深く潜入する:MINILLMによるAIのポテンシャルの解放
大規模言語モデルの急速な発展による過剰な計算リソースの需要を減らすために、大きな先生モデルの監督の下で小さな学生モデルを訓練する知識蒸留は、典型的な戦略です。よく使われる2つのKDは、先生の予測のみにアクセスするブラックボックスKDと、先生のパラメータを使用するホワイトボックスKDです。最近、ブラックボックスKDは、LLM APIによって生成されたプロンプト-レスポンスペアで小さなモデルを最適化することで、励ましを示しています。オープンソースのLLMが開発されるにつれて、ホワイトボックスKDは、研究コミュニティや産業セクターにとってますます有用になります。なぜなら、学生モデルはホワイトボックスのインストラクターモデルからより良いシグナルを得るため、性能が向上する可能性があるためです。 生成的LLMのホワイトボックスKDはまだ調査されていませんが、小規模(1Bパラメータ)の言語理解モデルについては、主にホワイトボックスKDが調査されています。この論文では、彼らはLLMのホワイトボックスKDを調べています。彼らは、一般的なKDが課題を生成的に実行するLLMにとってより優れている可能性があると主張しています。シーケンスレベルモデルのいくつかの変種を含む標準的なKD目標は、教師と学生の分布の近似前方クルバック・ライブラー発散(KLD)を最小化し、KLとして知られています。教師分布p(y|x)と学生分布q(y|x)によってパラメータ化され、pがqのすべてのモードをカバーするように強制する。出力空間が有限の数のクラスを含むため、テキスト分類問題においてKLはよく機能します。したがって、p(y|x)とq(y|x)の両方に少数のモードがあることが保証されます。 しかし、出力空間がはるかに複雑なオープンテキスト生成問題では、p(y|x)はq(y|x)よりもはるかに広い範囲のモードを表す場合があります。フリーラン生成中、前方KLDの最小化は、qがpの空白領域に過剰な確率を与え、pの下で非常にありそうもないサンプルを生成することにつながる可能性があります。この問題を解決するために、コンピュータビジョンや強化学習で一般的に使用される逆KLD、KLを最小化することを提案しています。パイロット実験は、KLを過小評価することで、qがpの主要なモードを探し、空いている領域を低い確率で与えるように駆動することを示しています。 これは、LLMの言語生成において、学生モデルがインストラクター分布の長いテールバージョンを学習しすぎず、誠実さと信頼性が必要な実世界の状況で重要な応答の正確性に集中することを意味します。彼らは、ポリシーグラディエントで目標の勾配を生成してmin KLを最適化します。最近の研究では、PLMの最適化にポリシーオプティマイゼーションの効果が示されています。ただし、モデルのトレーニングはまだ過剰な変動、報酬のハッキング、および世代の長さのバイアスに苦しんでいることがわかりました。そのため、彼らは以下を含めます。 バリエーションを減らすための単一ステップの正則化。 報酬のハッキングを減らすためのティーチャー混合サンプリング。 長さのバイアスを減らすための長さ正規化。 広範なNLPタスクを含む指示に従う設定では、The CoAI Group、清華大学、Microsoft Researchの研究者は、MINILLMと呼ばれる新しい技術を提供し、パラメータサイズが120Mから13Bまでのいくつかの生成言語モデルに適用します。5つの指示に従うデータセットと評価のためのRouge-LおよびGPT-4フィードバックを使用します。彼らのテストは、MINILMがすべてのデータセットでベースラインの標準KDモデルを常に打ち負かすことを示しています(図1を参照)。さらに研究により、MINILLMは、より多様な長い返信を生成するのに適しており、露出バイアスが低く、キャリブレーションが向上していることがわかりました。モデルはGitHubで利用可能です。 図1は、MINILLMとシーケンスレベルKD(SeqKD)の評価セットでの平均GPT-4フィードバックスコアの比較を示しています。左側にはGPT-2-1.5Bがあり、生徒としてGPT-2 125M、340M、および760Mが動作します。中央には、GPT-2 760M、1.5B、およびGPT-Neo 2.7Bが生徒であり、GPT-J 6Bがインストラクターです。右側にはOPT 13Bがあり、生徒としてOPT 1.3B、2.7B、および6.7Bが動作しています。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.