Learn more about Search Results He et al., 2016 - Page 3

- You may be interested
- 「データ自体よりもデータ生成プロセスを...
- LinkedInとUCバークレーの研究者らは、AI...
- 「Azure Data Factory(ADF)とは何ですか...
- 進歩のために曲を作るためのデータ利用
- 機械学習とは何か?メリットとトップMLaaS...
- AI(人工知能)の謎を解明:フォローすべ...
- 「アメリカで最も優れた5つのデータサイエ...
- 「機械学習を使用するかどうか」
- Google Cloudがマッコーリー銀行のAIバン...
- わかりやすいYOLOv8 Eigen-CAMを使ったYOL...
- このAI論文は、柔軟なタスクシステムと手...
- 非ユークリッド空間における機械学習
- 宇宙におけるAIの10の使用例
- 「転移学習の非合理的な効果」
- 高度なAIの約束とリスクについて、ジェフ...

注釈付き拡散モデル
このブログ記事では、Denoising Diffusion Probabilistic Models(DDPM、拡散モデル、スコアベースの生成モデル、または単にオートエンコーダーとも呼ばれる)について詳しく見ていきます。これらのモデルは、(非)条件付きの画像/音声/ビデオの生成において、驚くべき結果が得られています。具体的な例としては、OpenAIのGLIDEやDALL-E 2、University of HeidelbergのLatent Diffusion、Google BrainのImageGenなどがあります。 この記事では、(Hoら、2020)による元のDDPMの論文を取り上げ、Phil Wangの実装をベースにPyTorchでステップバイステップで実装します。なお、このアイデアは実際には(Sohl-Dicksteinら、2015)で既に導入されていました。ただし、改善が行われるまでには(Stanford大学のSongら、2019)を経て、Google BrainのHoら、2020)が独自にアプローチを改良しました。 拡散モデルにはいくつかの視点がありますので、ここでは離散時間(潜在変数モデル)の視点を採用していますが、他の視点もチェックしてください。 さあ、始めましょう! from IPython.display import Image Image(filename='assets/78_annotated-diffusion/ddpm_paper.png') まず必要なライブラリをインストールしてインポートします(PyTorchがインストールされていることを前提としています)。 !pip install -q -U…

人間のフィードバックからの強化学習(RLHF)の説明
この記事は以下の言語に翻訳されています:中国語(簡体字)とベトナム語。他の言語に翻訳に興味がありますか?nathan at huggingface.co までお問い合わせください。 言語モデルは、過去数年間に人間の入力プロンプトから多様で魅力的なテキストを生成する能力を示してきました。しかし、「良い」テキストとは何かは、主観的で文脈に依存するため、本質的に定義するのは難しいです。創造性を求める物語の執筆などの多くのアプリケーションでは、真実であるべき情報の断片、または実行可能なコードのスニペットなどが必要です。 これらの属性を捉えるための損失関数を作成することは困難であり、ほとんどの言語モデルはまだ単純な次のトークン予測の損失(例:クロスエントロピー)で訓練されています。損失自体の欠点を補うために、人々はBLEUやROUGEなど、人間の優先順位をより適切に捉えるように設計されたメトリクスを定義しています。これらのメトリクスは、パフォーマンスを測定する上で損失関数自体より適しているものの、生成されたテキストを単純なルールで参照テキストと比較するだけなので、制約もあります。生成されたテキストに対する人間のフィードバックをパフォーマンスの指標として使用するか、さらに進んでそのフィードバックを損失としてモデルを最適化することができれば、素晴らしいことではないでしょうか?それが「人間のフィードバックによる強化学習(RLHF)」のアイデアです。強化学習の手法を使用して、言語モデルを人間のフィードバックで直接最適化するのです。RLHFにより、言語モデルは一般的なテキストデータのコーパスで訓練されたモデルを複雑な人間の価値に合わせることができるようになりました。 RLHFの最近の成功例は、ChatGPTでの使用です。ChatGPTの印象的な能力を考慮して、RLHFについて説明してもらいました: それは驚くほどうまくいっていますが、すべてをカバーしているわけではありません。それらのギャップを埋めましょう! 人間のフィードバックによる強化学習(RL from human preferencesとも呼ばれます)は、複数のモデルのトレーニングプロセスと異なる展開の段階を伴うため、難しい概念です。このブログ記事では、トレーニングプロセスを次の3つの主要なステップに分解します: 言語モデル(LM)の事前トレーニング データの収集と報酬モデルのトレーニング 強化学習によるLMの微調整 まず、言語モデルの事前トレーニングについて見ていきましょう。 言語モデルの事前トレーニング RLHFの出発点として、クラシカルな事前トレーニング目標で既に事前トレーニングされた言語モデルを使用します(詳細については、このブログ記事を参照してください)。OpenAIは、最初の人気のあるRLHFモデルであるInstructGPTに対して、より小さなバージョンのGPT-3を使用しました。Anthropicは、このタスクのためにトレーニングされた1,000万から520億のパラメータを持つトランスフォーマーモデルを使用しました。DeepMindは、2800億のパラメータモデルGopherを使用しました。 この初期モデルは、追加のテキストや条件で微調整することもできますが、必ずしも必要ではありません。たとえば、OpenAIは「好ましい」とされる人間が生成したテキストを微調整し、Anthropicは彼らの「助けになり、正直で無害な」基準に基づいて元のLMを蒸留することで、RLHFのための初期LMを生成しました。これらは共に、私が高価な増強データと呼ぶものの一部ですが、RLHFを理解するために必要なテクニックではありません。 一般的に、「どのモデル」がRLHFの出発点として最適かは明確な答えがありません。このブログ記事では、RLHFのトレーニングにおけるオプションの設計空間が完全に探索されていないという共通のテーマになります。 次に、言語モデルが必要なデータを生成して、人間の優先順位がシステムに統合される「報酬モデル」をトレーニングする必要があります。 報酬モデルのトレーニング 人間の優先順位に合わせてキャリブレーションされた報酬モデル(RM、優先モデルとも呼ばれます)を生成することは、RLHFの比較的新しい研究の出発点です。その基本的な目標は、テキストのシーケンスを受け取り、数値で人間の優先順位を表すべきスカラー報酬を返すモデルまたはシステムを取得することです。システムはエンドツーエンドのLMであるか、報酬を出力するモジュラーシステム(例:モデルが出力をランク付けし、ランキングが報酬に変換される)である場合があります。出力がスカラーの報酬であることは、既存のRLアルゴリズムが後のRLHFプロセスにシームレスに統合されるために重要です。 報酬モデリングのためのこれらの言語モデルは、別の微調整された言語モデルまたは好みのデータでスクラッチからトレーニングされた言語モデルのいずれかです。例えば、Anthropicは、これらのモデルを事前トレーニング(好みモデルの事前トレーニング、PMP)の後に初期化するために専門の微調整方法を使用しています。彼らは、これが微調整よりもサンプル効率が高いと結論付けましたが、報酬モデリングのバリエーションの中で明確な最良の選択肢はありません。…
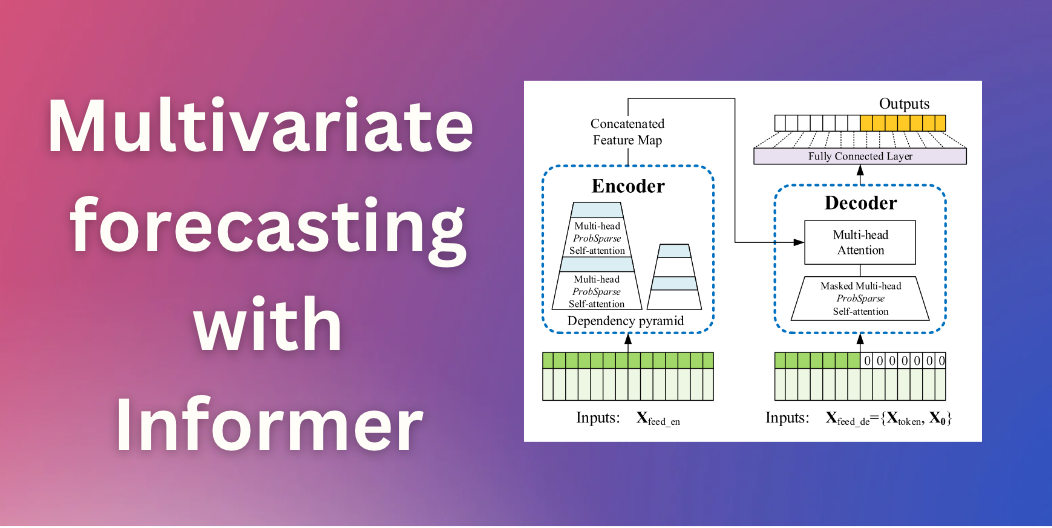
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

はい、トランスフォーマーは時系列予測に効果的です(+オートフォーマー)
イントロダクション 数ヶ月前、AAAI 2021のベストペーパーアワードを受賞したTime Series TransformerであるInformerモデル(Zhou, Haoyiら、2021)を紹介しました。また、Informerを使用した多変量確率予測の例も提供しました。この記事では、「Transformerは時系列予測に効果的か?」(AAAI 2023)という疑問について議論します。見ていくとわかりますが、それらは効果的です。 まず、Transformerは確かに時系列予測に効果的であることを経験的に証明します。私たちの比較では、線形モデルであるDLinearが主張されるほど優れていないことが示されています。線形モデルと同じ設定の同等の大きさのモデルと比較した場合、Transformerベースのモデルは私たちが考慮するテストセットのメトリックでより優れた性能を発揮します。その後、Informerモデルの後にNeurIPS 2021で発表されたAutoformerモデル(Wu, Haixuら、2021)を紹介します。Autoformerモデルは現在🤗 Transformersで利用できます。最後に、Autoformerの分解層を使用するシンプルなフィードフォワードネットワークであるDLinearモデルについて説明します。DLinearモデルは、「Transformerは時系列予測に効果的か?」という論文で初めて紹介され、Transformerベースのモデルを時系列予測で上回ると主張されています。 さあ、始めましょう! ベンチマーキング – Transformers vs. DLinear 最近AAAI 2023で発表された「Transformerは時系列予測に効果的か?」という論文では、著者らはTransformerが時系列予測に効果的ではないと主張しています。彼らは、DLinearと呼ばれるシンプルな線形モデルとTransformerベースのモデルを比較しています。DLinearモデルはAutoformerモデルの分解層を使用しており、後ほどこの記事で紹介します。著者らは、DLinearモデルがTransformerベースのモデルを時系列予測で上回ると主張しています。本当にそうなのでしょうか?さあ、確かめましょう。 上記の表は、論文で使用された3つのデータセットにおけるAutoformerモデルとDLinearモデルの比較結果を示しています。結果からわかるように、Autoformerモデルは3つのデータセットすべてでDLinearモデルを上回っています。 次に、上記の表のTrafficデータセットを使用してAutoformerモデルとDLinearモデルを比較し、得られた結果の説明を提供します。 要約: 簡単な線形モデルは一部の場合において有利ですが、ユニバリエートの設定では変数を組み込む能力がTransformerのようなより複雑なモデルに比べてありません。 Autoformer…

行動の組み合わせによる高速強化学習
新しいレシピを学ぶたびに、切る・皮をむく・かき混ぜる方法を再び学ばなければならないとしたらどうでしょうか多くの機械学習システムでは、新たな課題に直面するときに、エージェントは完全にゼロから学ばなければなりませんしかし、明らかなことは、人々はこれよりも効率的に学ぶことができるということです彼らは以前に学んだ能力を組み合わせることができます有限の単語の辞書がほぼ無限の意味を持つ文に再構成されるように、人々は既に持っているスキルを再利用し再組み合わせして新しい課題に取り組むのです

言語モデルによるレッドチーミング:言語モデルによる言語モデル
私たちの最近の論文では、言語モデル自体を使用して入力を生成することで、言語モデルから有害なテキストを引き出す可能性があることを示しています私たちのアプローチは、ユーザーに影響を与える前に有害なモデルの振る舞いを見つけるためのツールの一つとして提供されますが、見つけた後の有害な行動を見つけるために必要な他の多くの技術と一緒に考えるべきであると強調しています

MuZeroの研究から現実世界への第一歩
YouTubeとの協力により、オープンソースのVP9コーデックにおける動画圧縮の最適化を行っています
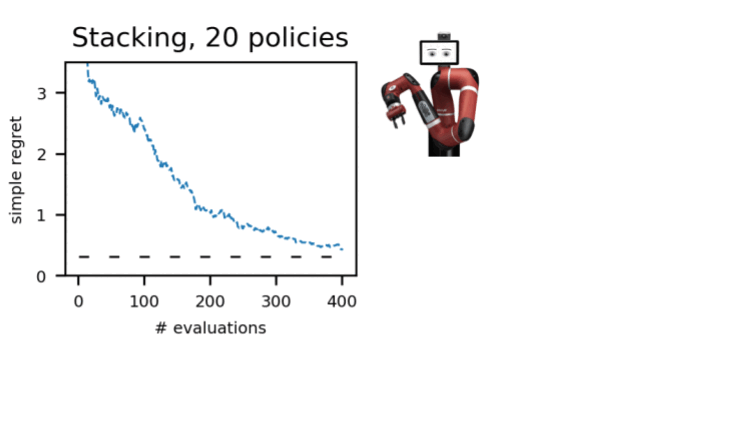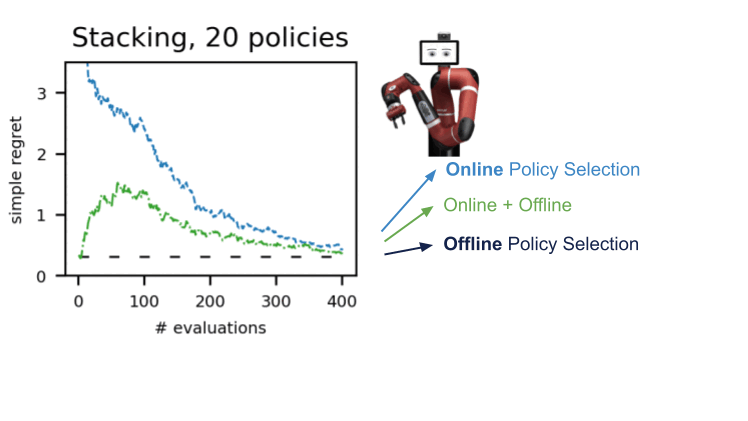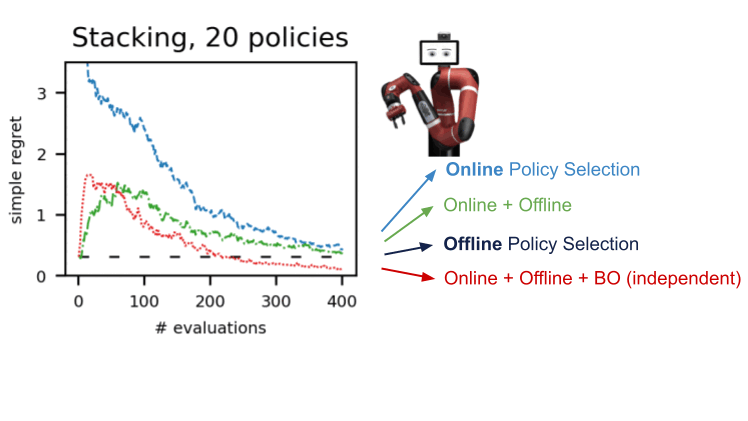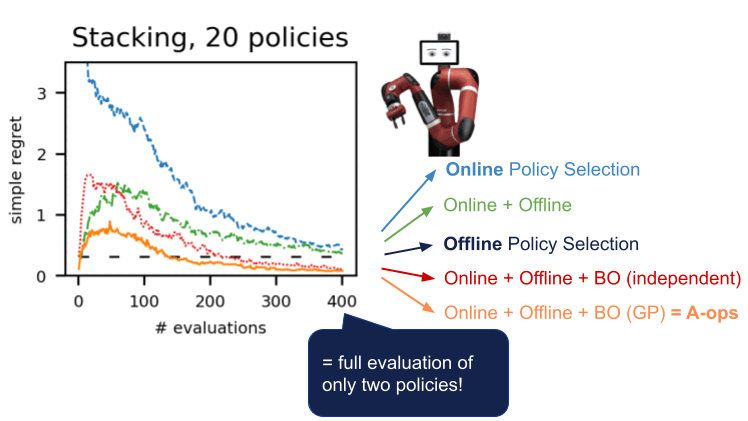
オフラインでのアクティブなポリシー選択
実際のロボット工学などの現実世界のアプリケーションに強化学習をより適用可能にするために、私たちは展開に適した方針を選択するための知的な評価手法、アクティブオフラインポリシー選択(A-OPS)を提案しますA-OPSでは、事前に録画されたデータセットを活用し、限定的な実環境との相互作用を許可することで、選択の品質を向上させます

アフリカにおける機械学習の強化を推進する運動のリーダーシップ
オープンな役割を表示する: https://www.deepmind.com/careers/jobs?sort=alphabetical Game Theory and Multi-agentチームの研究エンジニアであるAvishkar Bhoopchandは、DeepMindへの道のりと、彼がアフリカ全土でディープラーニングの知名度を高めるために取り組んでいることについて共有しています。 Deep Learning Indaba 2022について詳しく知るには、毎年開催されるアフリカのAIコミュニティの集まりであるDeep Learning Indaba 2022をご覧ください。今年の8月、チュニジアで開催されます。 仕事の典型的な1日はどのようなものですか? 研究エンジニアおよびテクニカルリードとして、毎日同じではありません。通勤中にポッドキャストやオーディオブックを聴くことから始めることが多いです。朝食後、メールとアドミンに集中してから最初のミーティングに入ります。これらは、チームメンバーとの個別のミーティングやプロジェクトの更新、多様性、公平性、包含(DE&I)の作業グループなど様々です。 午後には、自分のやることリストのための時間を確保しようとします。これらのタスクには、プレゼンテーションの準備、研究論文の読み込み、コードの記述やレビュー、実験の設計と実施、結果の分析などが含まれることがあります。 在宅勤務の場合、私の犬フィンが私を忙しくさせます!彼に教えることは、強化学習(RL)のようなものです – 職場で人工エージェントを訓練する方法のようなものです。そのため、私の時間の多くはディープラーニングや機械学習について考えることに費やされます。 AIに興味を持つようになったきっかけは何ですか? ケープタウン大学で知能エージェントのコースを受講している最中、私の講師がRLを用いてゼロから歩くことを学んだ六脚ロボットのデモを行いました。その瞬間から、人間や動物のメカニズムを使用して学習可能なシステムを構築する可能性について考えることができなくなりました。 当時、南アフリカでは機械学習の応用や研究は実際には選択肢ではありませんでした。私の同僚の多くと同様に、私もソフトウェアエンジニアとして金融業界で働くことになりました。大規模で堅牢なシステムの設計やユーザー要件を満たすための経験を積むことができました。しかし、6年後、私はもっと何かを求めるようになりました。 その頃、ディープラーニングが急速に広まり始めました。最初はCourseraのAndrew…

AI研究の善循環
最近、私たちはDeepMindの研究科学者であるペタル・ヴェリチコビッチさんに取材しましたペタルさんは共著者とともに、彼の論文「The CLRS Algorithmic Reasoning Benchmark」をアメリカのメリーランド州ボルチモアで開催されるICML 2022で発表します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.