Learn more about Search Results Flan T5 XL - Page 3

- You may be interested
- 「ハリー・ポッターとは誰なのか?Microso...
- 「アルマンド・ソラール・レザマが初代デ...
- 2023年に知っておくべきトップ10のパワフ...
- 「2023年のAi4カンファレンスでジェネレー...
- 無料でGoogle Colab上でQLoraを使用してLL...
- ネットワークの強化:異常検知のためのML...
- コーネル大学の研究者たちは、不連続処理...
- テーブル内の重複した値を見つけるための...
- Nvidiaは、エンジニア向けに生成AIを試験...
- 「リアルタイムの高度な物体認識を備えたL...
- 「AIを活用して国連の持続可能な開発目標...
- ネットワークXによるソーシャルネットワー...
- JuliaはPythonとNumbaよりも速いですか?
- 一緒にAIを学ぶ – Towards AI コミ...
- ハイカーディナリティのカテゴリカル変数...

「AWS 上の生成型 AI を使用して、放射線学のレポートの所見から自動的に印象を生成します」
この投稿では、AWSサービスを使用して、公開されているLLMsを放射線学報告の要約のために微調整する戦略を示していますLLMsは、自然言語の理解と生成において卓越した能力を示しており、さまざまなドメインやタスクに適応できる基礎モデルとして機能します事前学習済みモデルを使用することには、重要な利点があります計算コストを削減し、炭素フットプリントを削減し、ゼロからモデルをトレーニングする必要がなく、最先端のモデルを使用できます

トムソン・ロイターが6週間以内に開発したエンタープライズグレードの大規模言語モデルプレイグラウンド、Open Arena
この記事では、トムソン・ロイター・ラボがAWSとの協力のもとで開発したトムソン・ロイターの企業全体で使用される大規模言語モデル(LLM)のプレイグラウンド、Open Arenaについて説明しますオリジナルのコンセプトは、Simone Zucchet(AWSソリューションアーキテクト)とTim Precious(AWSアカウントマネージャー)のサポートを受けたAI/MLハッカソンで生まれ、AWSのサービスを使用して6週間以内に本番環境に開発されましたAWS Lambda、Amazon DynamoDB、Amazon SageMakerなどのAWS管理サービス、および事前に構築されたHugging Face Deep Learning Containers(DLC)がイノベーションのスピードに貢献しました

「Amazon SageMaker JumpStartを使用したゼロショットテキスト分類」
自然言語処理(NLP)は、機械学習(ML)の分野であり、コンピュータに人間と同じようにテキストや話された言葉を理解する能力を与えることに関心があります最近では、トランスフォーマーアーキテクチャなどの最先端のアーキテクチャが使用され、テキスト要約、テキスト分類、エンティティ認識などのNLP下流タスクでほぼ人間のパフォーマンスを実現するために使用されています

PythonでのZeroからAdvancedなPromptエンジニアリングをLangchainで
大規模言語モデル(LLM)の重要な要素は、これらのモデルが学習に使用するパラメータの数ですモデルが持つパラメータが多いほど、単語やフレーズの関係をより理解することができますつまり、数十億のパラメータを持つモデルは、さまざまな創造的なテキスト形式を生成し、開放的な質問に回答する能力を持っています
このAIニュースレターは、あなたが必要なもの全てです#58
今週、私たちはNLPの領域外でAIの2つの新しい進展を見ることに興奮しましたMeta AIの最新の開発では、彼らのOpen Catalystシミュレーターアプリケーションの発表が含まれています

スタンフォード大学の研究者たちは、「ギスティング:言語モデルにおける効率的なプロンプト圧縮のための新しい技術」というものを紹介しました
モデルの特殊化は、事前に学習された機械学習モデルを特定のタスクやドメインに適応させることを意味します。言語モデル(LM)では、モデルの特殊化は、要約、質問応答、翻訳、言語生成など、さまざまなタスクでのパフォーマンス向上に重要です。言語モデルを特定のタスクに特殊化するための2つの主なプロセスは、命令の微調整(事前に学習されたモデルを新しいタスクまたは一連のタスクに適応させること)とモデルの蒸留(事前に学習された「教師」モデルから小型の特殊化された「学生」モデルに知識を転送すること)です。プロンプティングは、LMの特殊化の分野で重要な概念であり、特定の動作にモデルを誘導する方法を提供し、限られたトレーニングデータのより効率的な使用を可能にし、最先端のパフォーマンスを実現するために重要です。プロンプトの圧縮は、計算、メモリ、ストレージの大幅な節約と、出力の全体的なパフォーマンスや品質の実質的な低下をもたらすことを目指して研究されている手法です。 この論文は、スタンフォード大学の研究者によって発表されたもので、プロンプトの圧縮のための新しい手法である「gisting」を提案しています。これは、LMを訓練してプロンプトをより小さな「gist」トークンのセットに圧縮する方法です。プロンプトのコストを削減するためには、微調整や蒸留のような技術を使用して、プロンプトなしで元のモデルと同じように振る舞うモデルを訓練することができますが、その場合、モデルは新しいプロンプトごとに再訓練する必要があり、理想的な状況からはほど遠いです。一方、gistingのアイデアは、メタ学習のアプローチを使用してプロンプトからgistトークンを予測することで、タスクごとにモデルを再訓練することなく、未知の命令に対しても汎化させることができます。これにより、計算コストが削減され、プロンプトを圧縮してキャッシュ化し、計算効率を向上させることができます。また、限られたコンテキストウィンドウにより多くのコンテンツを収めることも可能になります。 著者たちは、このようなモデルを実現するための簡単な方法を試みました。彼らはLM自体(その事前の知識を活用)を使用して、命令の微調整中にgistトークンを予測し、Transformerのアテンションマスクを修正しました。タスクと入力のペアが与えられた場合、彼らはタスクと入力の間にgistトークンを追加し、アテンションマスクを次のように設定しました:gistトークンの後の入力トークンは、gistトークンの前のプロンプトトークンのいずれにもアテンションを向けることができません(ただし、gistトークンにはアテンションを向けることができます)。入力と出力がプロンプトにアテンションを向けることができないため、モデルはプロンプトの情報をgistトークンに圧縮する必要があります。gistモデルを訓練するためには、さまざまなタスクの多様なデータセットが必要でしたので、彼らはAlpaca+と呼ばれるデータセットを作成しました。これは、2つの既存の命令微調整データセット(Standford AlpacaとSelf-Instruct)のデータを組み合わせたもので、合計で13万以上の例が含まれています。その後、トレーニング後にモデルを検証するために3つのバリデーションスプリット(Seen、Unseen、手作りのHuman prompts)を保持しました。これにより、未知の命令に対する汎化性能をテストすることができました。Human splitは、さらに強力な汎化の課題を提供します。また、複数のLMアーキテクチャ(具体的にはLLaMA-7Bm、デコーダのみのGPTスタイルのモデル、およびFLAN-T5-XXL)を使用し、gistトークンの数(1、2、5、または10)を変えながらgistモデルを訓練しました。しかし、結果は、モデルが一般にgistトークンの数に対して敏感でなく、場合によっては、トークンの数が多いほうがパフォーマンスに悪影響を及ぼすことさえ示していました。したがって、残りの実験には単一のgistモデルを使用しました。 プロンプトの圧縮の品質を評価するために、彼らは陽性コントロールとしてのパフォーマンスを調整し、効果的に標準的な命令微調整を提供し、パフォーマンスの上限を示しました。また、モデルが命令にアクセスできず、ランダムなgistトークンが生成されるネガティブコントロールも使用し、パフォーマンスの下限を示しました。彼らは、モデルの出力を陽性コントロールと比較し、その勝率を測定するためにChatGPTによってどちらの応答がより良いかを選択させ、その理由を説明しました。また、単純な語彙の重複統計であるROUGE-L(オープンエンドの命令微調整で生成されたテキストと人間が書いた命令の類似性を測定する指標)も使用しました。50%の勝率は、プロンプトの圧縮を行わないモデルと同等の品質のモデルであることを示します。 結果は、Seenの指示では、要約モデルが陽性対照モデルに非常に近い勝率を持っていることを示しました。LLaMAは48.6%、FLAN-T5は50.8%の勝率です。さらに重要なことに、要約モデルは未知のプロンプトに対しても競争力のある一般化を示すことができました。LLaMAは49.7%、FLAN-T5は46.2%の勝率です。最も難しいHuman splitでは、わずかな勝率の低下が見られましたが(それでも競争力があります)、LLaMAは45.8%、FLAN-T5は42.5%の勝率です。FLAN-T5のわずかに悪い性能と特定の失敗事例は、将来の論文でさらに検証すべき仮説をもたらしました。 研究者たちはまた、研究の主な動機である要約によって実現できる潜在的な効率の向上も調査しました。その結果は非常に励みになりました。要約キャッシングによってFLOPsが40%削減され、最適化されていないモデルと比較して壁時計時間が4-7%低下しました。これらの改善は、デコーダのみの言語モデルでは小さいとわかりましたが、研究者たちはまた、要約モデルによって未知のプロンプトを26倍圧縮できることを示しました。これにより、入力コンテキストウィンドウにかなりの追加スペースが提供されます。 全体的に、これらの結果は、要約が専門的な言語モデルの有効性と効率を向上させるための大きな潜在能力を示しています。著者たちはまた、要約に関する追加の研究のためのいくつかの有望な方向性を提案しています。例えば、要約から最も大きな計算および効率の利益は、より長いプロンプトの圧縮から得られると述べており、「要約の事前学習」は、まず自然言語の任意の範囲を圧縮することを学習してからプロンプトの圧縮を改善することができると示唆しています。

Amazon SageMaker JumpStartを使用して、インターネット接続がないVPCモードで、生成AIの基礎モデルを利用します
最近の生成AIの進歩により、さまざまな業界で特定のビジネス問題を解決するために生成AIをどのように活用するかについての議論が盛んに行われています生成AIは、会話、物語、画像、動画、音楽などの新しいコンテンツやアイデアを作成することができるAIの一種ですこれらはすべて非常に大きなモデルに裏打ちされています

「LLMを使用して、会話型のFAQ機能を搭載したAmazon Lexを強化する」
Amazon Lexは、Amazon Connectなどのアプリケーションのために、会話ボット(「チャットボット」)、バーチャルエージェント、およびインタラクティブ音声応答(IVR)システムを迅速かつ簡単に構築できるサービスです人工知能(AI)と機械学習(ML)は、Amazonの20年以上にわたる焦点であり、顧客が利用する多くの機能の一部です
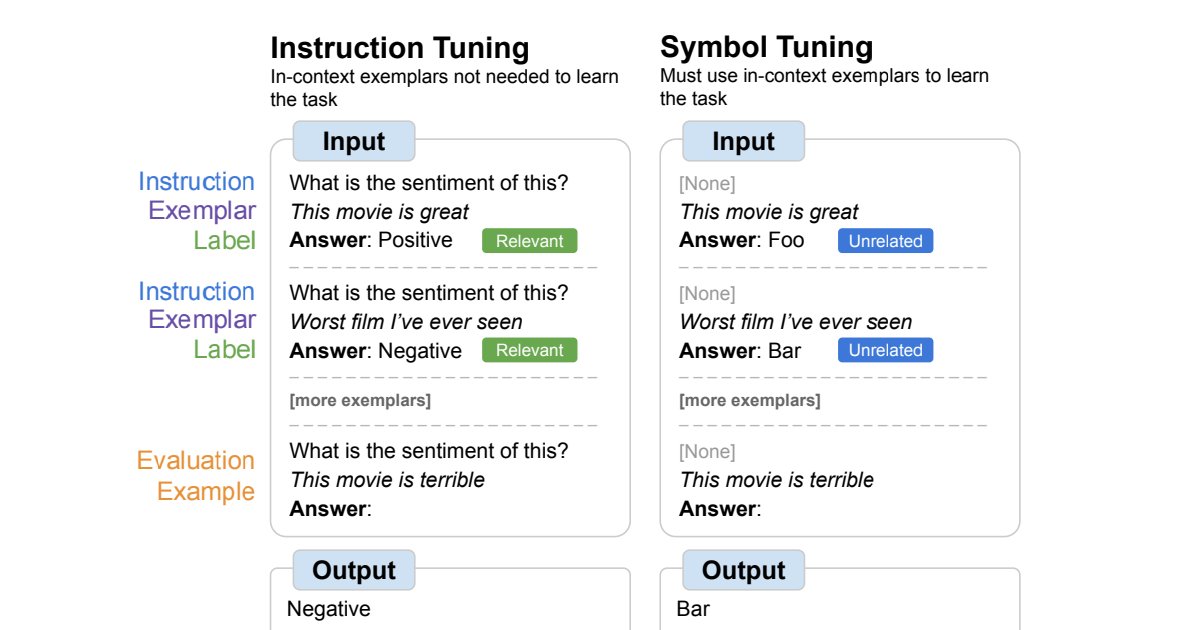
シンボルの調整は言語モデルの文脈における学習を向上させます
Google Researchの学生研究者であるJerry Weiと主任科学者のDenny Zhouによって投稿されました。 人間の知性の重要な特徴の一つは、わずかな例だけを用いて推論することで新しいタスクを学ぶことができることです。言語モデルのスケーリングによって、マシンラーニングにおいて新たな応用やパラダイムを実現することができました。しかし、言語モデルはプロンプトの与え方に敏感であり、頑健な推論を行っているわけではないことを示しています。例えば、言語モデルはしばしばプロンプトエンジニアリングやタスクの指示としてのフレーズのような作業が必要であり、不正確なラベルが表示されてもタスクのパフォーマンスに影響を与えないという予期しない振る舞いを示すことがあります。 「Symbol tuning improves in-context learning in language models」では、シンボルチューニングと呼ばれるシンプルなファインチューニング手法を提案しています。この手法は入力とラベルのマッピングを強調することで、インコンテキスト学習を改善することができます。私たちはFlan-PaLMモデルにおけるシンボルチューニングの実験を行い、さまざまな設定での利点を観察しました。 シンボルチューニングは、未知のインコンテキスト学習タスクにおいてパフォーマンスを向上させ、指示や自然言語のラベルがないような曖昧なプロンプトに対しても非常に頑健です。 シンボルチューニングされたモデルは、アルゴリズムの推論タスクにおいて非常に強力です。 最後に、シンボルチューニングされたモデルは、インコンテキストで提示された反転したラベルを追従する能力が大幅に向上しており、インコンテキスト情報を使用して以前の知識を上書きすることができます。 シンボルチューニングの概要。モデルは自然言語のラベルが任意のシンボルに置き換えられたタスクでファインチューニングされます。シンボルチューニングは、指示や関連するラベルが利用できない場合、モデルがインコンテキストの例を使用してタスクを学ぶ必要があるという直感に基づいています。 動機 指示チューニングは一般的なファインチューニング手法であり、パフォーマンスを向上させ、モデルがインコンテキストの例に従う能力を改善することが示されています。ただし、評価例に指示と自然言語のラベルを通じてタスクが冗長に定義されるため、モデルは例を使用する必要がありません。例えば、上の図の左側では、例がモデルがタスク(感情分析)を理解するのに役立つことができますが、モデルは例を無視してタスクを示す指示を読むことができます。 シンボルチューニングでは、モデルは指示が削除され、自然言語のラベルが意味的に関連のないラベル(例:「Foo」、「Bar」など)に置き換えられた例でファインチューニングされます。この設定では、インコンテキストの例を見ないとタスクが明確になりません。例えば、上の図の右側では、タスクを理解するために複数のインコンテキストの例が必要です。シンボルチューニングはモデルにインコンテキストの例を推論することを教えるため、シンボルチューニングされたモデルは、インコンテキストの例とそのラベルの間の推論を必要とするタスクにおいてより優れたパフォーマンスを発揮するはずです。 シンボルチューニングに使用されるデータセットとタスクの種類。 シンボル調整手順 私たちは、シンボル調整手順に使用するために、22の公開されている自然言語処理(NLP)データセットを選択しました。これらのタスクは過去に広く使用されており、私たちは離散的なラベルを必要とするため、分類タイプのタスクのみを選択しました。その後、ラベルを整数、文字の組み合わせ、および単語の3つのカテゴリから選択された約30,000の任意のラベルの1つにランダムにマッピングします。 実験では、PaLMの指示に調整されたバリアントであるFlan-PaLMをシンボル調整します。Flan-PaLMモデルの3つの異なるサイズを使用します:Flan-PaLM-8B、Flan-PaLM-62B、およびFlan-PaLM-540B。また、Flan-cont-PaLM-62B(780Bトークンではなく1.3TトークンでのFlan-PaLM-62B)もテストし、62B-cと略称します。…

ストーリーの生成:ゲーム開発のためのAI #5
AIゲーム開発へようこそ!このシリーズでは、AIツールを使用してわずか5日で完全な機能を備えた農業ゲームを作成します。このシリーズの終わりまでに、さまざまなAIツールをゲーム開発のワークフローに取り入れる方法を学ぶことができます。以下のような目的でAIツールを使用する方法をお見せします: アートスタイル ゲームデザイン 3Dアセット 2Dアセット ストーリー クイックビデオバージョンが欲しいですか? こちらでご覧いただけます。それ以外の場合は、技術的な詳細を読み続けてください! 注:この投稿では、ゲームデザインにChatGPTを使用したPart 2への参照がいくつかあります。ChatGPTの動作方法、言語モデルの概要、およびその制限についての追加のコンテキストについては、Part 2をお読みください。 Day 5: ストーリー このチュートリアルシリーズのPart 4では、Stable DiffusionとImage2Imageを2Dアセットのワークフローに使用する方法について説明しました。 この最終パートでは、ストーリーにAIを使用します。まず、農業ゲームのプロセスを説明し、注意すべき⚠️ 制限事項について説明します。次に、ゲーム開発の文脈での関連技術と今後の方向性について話します。最後に、最終的なゲームについてまとめます。 プロセス 要件:このプロセス全体でChatGPTを使用しています。ChatGPTと言語モデリングについての詳細については、シリーズのPart 2をお読みいただくことをおすすめします。ChatGPTは唯一の解決策ではありません。オープンソースの対話エージェントなど、数多くの新興競合他社が存在します。対話エージェントの新興市場についてさらに詳しく学ぶために、先を読んでください。 ChatGPTにストーリーの執筆を依頼します。ゲームに関する多くのコンテキストを提供した後、ChatGPTにストーリーの要約を書いてもらいます。 ChatGPTは、ゲームStardew…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.