Learn more about Search Results D2L - Page 3

- You may be interested
- 「前例のない緊急事態下でのオンライン機...
- 原子力輸送船のAI推進帆のテスト
- 「グラフとネットワーク上の表現学習」
- 「NExT-GPT あらゆるモダリティに対応した...
- 「3年以内に労働力の40%がAIの影響を受け...
- 直線回帰、カーネルトリック、リニアカーネル
- SSDを使用したリアルタイム物体検出:シン...
- 「ユナイテッド航空がコスト効率の高い光...
- AIが白人を好むとき
- 「時系列分析における移動平均の総合ガイド」
- 「迅速な最適化スタック」
- ロボティクスシミュレーションとは何ですか?
- NVIDIAがFlexiCubesを導入:フォトグラメ...
- 学習曲線の航行:AIの記憶保持との闘い
- Office 365の移行と管理を外部委託する主...

ハギングフェイスにおけるコンピュータビジョンの状況 🤗
弊社の自慢は、コミュニティとともに人工知能の分野を民主化することです。その使命の一環として、私たちは過去1年間でコンピュータビジョンに注力し始めました。🤗 Transformersにビジョントランスフォーマー(ViT)を含めるというPRから始まったこの取り組みは、現在では8つの主要なビジョンタスク、3000以上のモデル、およびHugging Face Hub上の100以上のデータセットに成長しました。 ViTがHubに参加して以来、多くのエキサイティングな出来事がありました。このブログ記事では、コンピュータビジョンの持続的な進歩をサポートするために何が起こったのか、そして今後何がやってくるのかをまとめます。 以下は、カバーする内容のリストです: サポートされているビジョンタスクとパイプライン 独自のビジョンモデルのトレーニング timmとの統合 Diffusers サードパーティーライブラリのサポート デプロイメント その他多数! コミュニティの支援:一つずつのタスクを可能にする 👁 Hugging Face Hubは、次の単語予測、マスクの埋め込み、トークン分類、シーケンス分類など、さまざまなタスクのために10万以上のパブリックモデルを収容しています。現在、我々は8つの主要なビジョンタスクをサポートし、多くのモデルチェックポイントを提供しています: 画像分類 画像セグメンテーション (ゼロショット)オブジェクト検出 ビデオ分類 奥行き推定 画像から画像への合成…

ビジョン-言語モデルへのダイブ
人間の学習は、複数の感覚を共同で活用することによって新しい情報をより良く理解し、分析することができるため、本質的にマルチモーダルです。最近のマルチモーダル学習の進歩は、このプロセスの効果的性質からインスピレーションを得て、画像、ビデオ、テキスト、音声、ボディジェスチャー、表情、生理的信号などのさまざまなモダリティを使用して情報を処理しリンクするモデルを作成することに取り組んでいます。 2021年以降、ビジョンと言語のモダリティ(またはジョイントビジョン言語モデルとも呼ばれる)を組み合わせたモデル、例えばOpenAIのCLIPなどへの関心が高まっています。ジョイントビジョン言語モデルは、画像キャプショニング、テキストによる画像生成および操作、視覚的な質問応答など、非常に困難なタスクにおいて特に印象的な能力を示しています。この分野は引き続き進化しており、ゼロショットの汎化性能向上に貢献し、さまざまな実用的なユースケースにつながっています。 このブログ記事では、ジョイントビジョン言語モデルについて、それらのトレーニング方法に焦点を当てて紹介します。また、最新の進歩をこの領域で試すために🤗 Transformersを活用する方法も示します。 目次 はじめに 学習戦略 コントラスティブラーニング PrefixLM クロスアテンションを用いたマルチモーダル融合 MLM / ITM トレーニングなし データセット 🤗 Transformersでのビジョン言語モデルのサポート 研究の新たな展開 結論 はじめに モデルを「ビジョン言語」モデルと呼ぶとはどういうことでしょうか?ビジョンと言語のモダリティの両方を組み合わせるモデルということでしょうか?しかし、それは具体的にどういう意味を持つのでしょうか? これらのモデルを定義するのに役立つ特徴の一つは、画像(ビジョン)と自然言語テキスト(言語)の両方を処理できる能力です。このプロセスは、モデルに求められる入力、出力、タスクに依存します。 たとえば、ゼロショット画像分類のタスクを考えてみましょう。入力画像といくつかのプロンプトを渡すことで、入力画像に対する最も可能性の高いプロンプトを取得します。 この猫と犬の画像はここから取得しました。…

カカオブレインからの新しいViTとALIGNモデル
Kakao BrainとHugging Faceは、新しいオープンソースの画像テキストデータセットCOYO(700億ペア)と、それに基づいてトレーニングされた2つの新しいビジュアル言語モデル、ViTとALIGNをリリースすることを発表しました。ALIGNモデルが無料かつオープンソースで公開されるのは初めてであり、ViTとALIGNモデルのリリースにトレーニングデータセットが付属するのも初めてです。 Kakao BrainのViTとALIGNモデルは、オリジナルのGoogleモデルと同じアーキテクチャとハイパーパラメータに従っていますが、オープンソースのCOYOデータセットでトレーニングされています。GoogleのViTとALIGNモデルは、巨大なデータセット(ViTは3億枚の画像、ALIGNは18億の画像テキストペア)でトレーニングされていますが、データセットが公開されていないため、複製することはできません。この貢献は、データへのアクセスも含めて、視覚言語モデリングを再現したい研究者にとって特に価値があります。Kakao ViTとALIGNモデルの詳細な情報は、こちらで確認できます。 このブログでは、新しいCOYOデータセット、Kakao BrainのViTとALIGNモデル、およびそれらの使用方法について紹介します!以下が主なポイントです: 史上初のオープンソースのALIGNモデル! オープンソースのデータセットCOYOでトレーニングされた初のViTとALIGNモデル Kakao BrainのViTとALIGNモデルは、Googleのバージョンと同等のパフォーマンスを示します ViTとALIGNのデモはHFで利用可能です!選んだ画像サンプルでオンラインでViTとALIGNのデモを試すことができます! パフォーマンスの比較 Kakao BrainのリリースされたViTとALIGNモデルは、Googleが報告した内容と同等またはそれ以上のパフォーマンスを示します。Kakao BrainのALIGN-B7-Baseモデルは、トレーニングペアが少ない(700億ペア対18億ペア)にもかかわらず、Image KNN分類タスクではGoogleのALIGN-B7-Baseと同等のパフォーマンスを発揮し、MS-COCO検索の画像からテキスト、テキストから画像へのタスクではより優れた結果を示します。Kakao BrainのViT-L/16は、モデル解像度384および512でImageNetとImageNet-ReaLで評価された場合、GoogleのViT-L/16と同様のパフォーマンスを発揮します。つまり、コミュニティはKakao BrainのViTとALIGNモデルを使用して、特にトレーニングデータへのアクセスが必要な場合に、GoogleのViTとALIGNリリースを再現することができます。最先端の性能を発揮しつつ、オープンソースで透明性のあるこれらのモデルのリリースを見ることができるのはとても興奮します! COYOデータセット これらのモデルのリリースの特徴は、モデルが無料かつアクセス可能なCOYOデータセットでトレーニングされていることです。COYOは、GoogleのALIGN 1.8B画像テキストデータセットに似た700億ペアの画像テキストデータセットであり、ウェブページから取得した「ノイズのある」代替テキストと画像のペアのコレクションですが、オープンソースです。COYO-700MとALIGN 1.8Bは「ノイズのある」データセットですが、最小限のフィルタリングが適用されています。COYOは、他のオープンソースの画像テキストデータセットであるLAIONとは異なり、以下の点が異なります。…

パンダの力を解放する:.locと.ilocの深いダイブ
PythonのPandasのポテンシャルを引き出しましょうデータの選択における.locと.ilocの詳細を学び、データ分析プロセスを向上させましょう

キャッシュの遷移に対する自動フィードバックによる優先学習
Googleのソフトウェアエンジニア、Ramki GummadiとYouTubeのソフトウェアエンジニア、Kevin Chenによって投稿されました。 キャッシュは、リクエストパターンに基づいてクライアントに近い場所に人気のあるアイテムの一部を保存することで、ストレージおよび検索システムのパフォーマンスを大幅に向上させる、コンピュータサイエンスにおける普遍的なアイデアです。キャッシュの管理における重要なアルゴリズムの一部は、格納されるアイテムのセットを動的に更新するために使用される決定ポリシーであり、数十年にわたって広範に最適化されてきました。これにより、いくつかの効率的で堅牢なヒューリスティクスが生まれました。機械学習をキャッシュポリシーに適用することは、最近の研究で有望な結果を示していますが(例:LRB、LHD、ストレージアプリケーションなど)、競争力のある計算およびメモリの負荷を維持しながら、信頼性のあるヒューリスティクスをベンチマークを超えて信頼性のある汎用的な設定に対して上回ることはまだ課題です。 NSDI 2023で発表された「YouTubeコンテンツデリバリーネットワークのためのヒューリスティック支援学習優先エヴィクションポリシー(HALP)」では、学習された報酬を基にしたスケーラブルな最先端のキャッシュエヴィクションフレームワークを紹介しています。HALPフレームワークは、軽量なヒューリスティックベースラインエヴィクションルールと学習された報酬モデルを組み合わせるメタアルゴリズムです。報酬モデルは、オフラインのオラクルを模倣するために設計された選好比較に基づく継続的な自動フィードバックでトレーニングされる軽量なニューラルネットワークです。HALPがYouTubeのコンテンツデリバリーネットワークのインフラストラクチャの効率性とユーザーのビデオ再生遅延を改善した方法について説明します。 キャッシュエヴィクションの決定のための学習済みの選好 HALPフレームワークは、2つのコンポーネントに基づいてキャッシュエヴィクションの決定を行います:(1)自動フィードバックを介した選好学習によってトレーニングされたニューラル報酬モデル、および(2)学習された報酬モデルと高速ヒューリスティックを組み合わせるメタアルゴリズム。キャッシュが入力リクエストを観察すると、HALPはペアワイズの選好フィードバックを介した選好学習法として、各アイテムに対してスカラー報酬を予測する小規模なニューラルネットワークを継続的にトレーニングします。HALPのこの側面は、人間のフィードバックからの強化学習(RLHF)システムに似ていますが、2つの重要な違いがあります: フィードバックは自動化されており、オフラインの最適キャッシュエヴィクションポリシーの構造に関するよく知られた結果を活用しています。 モデルは、自動フィードバックプロセスから構築されたトレーニングの例の一時バッファを使用して継続的に学習されます。 エヴィクションの決定は、2つのステップを持つフィルタリングメカニズムに依存しています。まず、パフォーマンスの観点ではサブオプティマルですが、効率的なヒューリスティックを使用して、小さな候補のサブセットが選択されます。次に、再ランキングステップによって、ベースラインの候補から内部の最終的な決定の品質を「ブーストする」ために、ニューラルネットワークのスコアリング関数が使用されます。 HALPは、エヴィクションの決定だけでなく、効率的なフィードバックの構築とモデルの更新に使用されるペアワイズの選好クエリのサンプリングのエンドツーエンドのプロセスを包括しています。 ニューラル報酬モデル HALPは、キャッシュ内の個々のアイテムを選択的にスコアリングするために、軽量な2層のマルチレイヤーパーセプトロン(MLP)を報酬モデルとして使用します。特徴は、メタデータのみの「ゴーストキャッシュ」として構築および管理されます(ARCなどの古典的なポリシーと同様)。任意のルックアップリクエストの後、通常のキャッシュ操作に加えて、HALPはダイナミックな内部表現を更新するために必要なブックキーピング(例:キャッシュルックアップリクエストと共にユーザーから提供される外部のタグ付き特徴、および各アイテムで観測されたルックアップ時間から構築された内部的な動的特徴など)を実行します。 HALPは、ランダムな重み初期化から完全にオンラインで報酬モデルを学習します。これは、報酬モデルを最適化するためにのみ決定が行われる場合、悪いアイデアのように思えるかもしれません。ただし、エヴィクションの決定は、学習された報酬モデルとLRUなどのサブオプティマルでシンプルかつ堅牢なヒューリスティックの両方に依存しています。これにより、報酬モデルが完全に一般化された場合に最適なパフォーマンスが得られる一方で、一時的に一般化されていないまたは変化する環境に追いつく途中の情報の少ない報酬モデルにも堅牢性があります。 オンライントレーニングのもう一つの利点は、専門化です。キャッシュサーバーはそれぞれ異なる環境(地理的位置など)で実行されるため、ローカルのネットワーク状況やローカルで人気のあるコンテンツなどに影響を受けます。オンライントレーニングは、この情報を自動的にキャプチャする一方で、単一のオフライントレーニングソリューションとは異なり、一般化の負担を軽減します。 ランダム化された優先度キューからのスコアリングサンプル エヴィクションの決定の品質を排他的に学習された目的に最適化することは、2つの理由で実用的ではありません。 計算効率の制約: 学習されたネットワークによる推論は、実際のキャッシュポリシーの計算に比べてかなり高コストになることがあります。これはネットワークと特徴の表現力だけでなく、各エビクションの決定時にこれらがどれくらい頻繁に呼び出されるかも制約します。 分布外の汎化のための堅牢性: HALPは、継続的な学習を伴うセットアップで展開されており、急速に変化するワークロードによって、以前に見たデータに関して一時的に分布外になるリクエストパターンが生成される可能性があります。 これらの問題に対処するために、HALPはまず、エビクションの優先順位に対応する安価なヒューリスティックスコアリングルールを適用し、小さな候補サンプルを特定します。このプロセスは、正確な優先順位キューを近似する効率的なランダムサンプリングに基づいています。候補サンプルを生成するための優先関数は、既存の手動調整アルゴリズム(例:LRU)を使用して素早く計算することを意図しています。ただし、これは簡単なコスト関数を編集することによって他のキャッシュ置換ヒューリスティックを近似するように構成できます。以前の研究とは異なり、ランダム化は近似と効率のトレードオフに使用されるものでしたが、HALPでは、トレーニングと推論の両方でサンプルされた候補の時間ステップごとの固有のランダム化にも依存しています。 最終的なエビクトされるアイテムは、提供された候補から選ばれ、ニューラル報酬モデルに従って予測された優先スコアを最大化するために再ランクされたサンプルに相当します。エビクションの決定に使用される候補のプールは、サンプル間のトレーニングと推論のズレを最小限に抑えるために、ペアワイズの優先クエリの構築にも使用されます。…

マルチヘッドアテンションを使用した注意機構の理解
はじめに Transformerモデルについて詳しく学ぶ良い方法は、アテンションメカニズムについて学ぶことです。特に他のタイプのアテンションメカニズムを学ぶ前に、マルチヘッドアテンションについて学ぶことは良い選択です。なぜなら、この概念は少し理解しやすい傾向があるためです。 アテンションメカニズムは、通常の深層学習モデルに追加できるニューラルネットワークレイヤーと見なすことができます。これにより、重要な部分に割り当てられた重みを使用して、入力の特定の部分に焦点を当てるモデルを作成することができます。ここでは、マルチヘッドアテンションメカニズムを使用して、アテンションメカニズムについて詳しく見ていきます。 学習目標 アテンションメカニズムの概念 マルチヘッドアテンションについて Transformerのマルチヘッドアテンションのアーキテクチャ 他のタイプのアテンションメカニズムの概要 この記事は、データサイエンスブログマラソンの一環として公開されました。 アテンションメカニズムの理解 まず、この概念を人間の心理学から見てみましょう。心理学では、注意は他の刺激の影響を除外して、イベントに意識を集中することです。つまり、他の注意を引くものがある場合でも、私たちは選択したものに焦点を合わせます。注意は全体の一部に集中します。 これがTransformerで使用される概念です。彼らは入力のターゲット部分に焦点を当て、残りの部分を無視することができます。これにより、非常に効果的な方法で動作することができます。 マルチヘッドアテンションとは? マルチヘッドアテンションは、Transformerにおいて中心的なメカニズムであり、ResNet50アーキテクチャにおけるskip-joiningに相当します。場合によっては、アテンドするべきシーケンスの複数の他の点があります。全体の平均を見つける方法では、重みを分散させて多様な値を重みとして与えることができません。これにより、複数のアテンションメカニズムを個別に作成するアイデアが生まれ、複数のアテンションメカニズムが生じます。実装では、1つの機能に複数の異なるクエリキー値トリプレットが表示されます。 出典:Pngwing.com 計算は、アテンションモジュールが何度も反復し、アテンションヘッドとして知られる並列レイヤーに組織化される方法で実行されます。各別のヘッドは、入力シーケンスと関連する出力シーケンスの要素を独立して処理します。各ヘッドからの累積スコアは、すべての入力シーケンスの詳細を組み合わせた最終的なアテンションスコアを得るために組み合わされます。 数式表現 具体的には、キーマトリックスとバリューマトリックスがある場合、値をℎサブクエリ、サブキー、サブバリューに変換し、アテンションを独立して通過させることができます。連結すると、ヘッドが得られ、最終的な重み行列でそれらを組み合わせます。 学習可能なパラメータは、アテンションに割り当てられた値であり、各パラメータはマルチヘッドアテンションレイヤーと呼ばれます。以下の図はこのプロセスを示しています。 これらの変数を簡単に見てみましょう。Xの値は、単語埋め込みの行列の連結です。 行列の説明 クエリ:シーケンスのターゲットについての洞察を提供する特徴ベクトルです。クエリは、何がアテンションを必要としているかをシーケンスに要求します。 キー:要素に含まれるものを説明する特徴ベクトルです。クエリによってアテンションが与えられ、要素のアイデンティティを提供します。 値:…
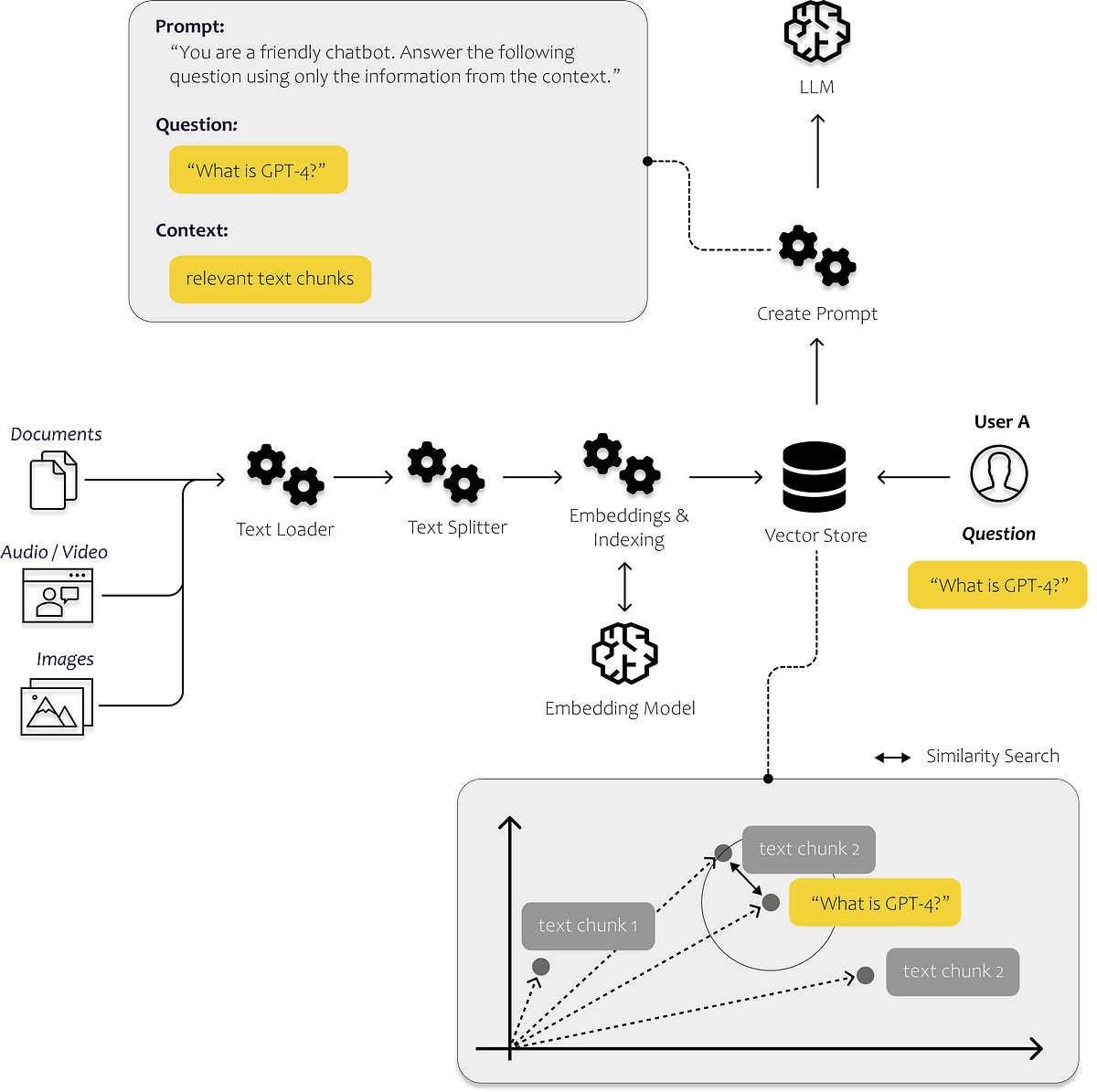
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...

非アーベル任意子の世界で初めてのブレードング
Google Quantum AIチームの研究員であるTrond AndersenとYuri Lenskyが投稿 同じ2つのオブジェクトを見せられて、目を閉じます。目を開けると、同じ2つのオブジェクトが同じ位置にあります。それらが交換されたかどうかをどのように判断できますか?直感と量子力学の法則は同意します:オブジェクトが本当に同じ場合、判断する方法はありません。 これは常識のように聞こえますが、これは私たちが知る3次元の世界にのみ適用されます。研究者たちは、2次元(2D)平面内でのみ移動することが制限された特別な粒子である任意子と呼ばれる特別なタイプの粒子に対して、量子力学がかなり異なるものを可能にすると予測しています。任意子は互いに区別できず、一部の非アーベル任意子は、交換時に共有量子状態の観測可能な差異を引き起こす特別な性質を持っており、互いに完全に区別できないにもかかわらず、交換されたときに判断できます。研究者たちは、その親戚であるアーベル任意子を検出することに成功しましたが、交換に対する変化が微妙で直接検出することができないため、「非アーベル交換行動」を実現することは、制御と検出の両方の課題によりより困難でした。 「超伝導プロセッサーにおけるグラフ頂点の非アーベル結び目」では、この非アーベル交換行動を初めて観測しました。非アーベル任意子は、粒子を交換し、まるでストリングが絡まるように交換し合うことで量子演算が実現される新しい方法を開く可能性があります。私たちの超伝導量子プロセッサーでこの新しい交換行動を実現することは、環境ノイズに対して頑強であるという利点を持つトポロジカル量子計算の代替ルートになる可能性があります。 交換統計と非アーベル任意子 この奇妙な非アーベル的な振る舞いがどのように発生するかを理解するには、2本のストリングを結ぶことの類比が役立ちます。同じ2本のストリングを取り、互いに平行に置きます。その後、エンドを交換してダブルヘリックス形状を形成します。ストリングは同じですが、エンドを交換するときにお互いを巻き込むため、エンドが交換されたときは非常に明確になります。 非アーベル任意子の交換は、同様の方法で視覚化できます。ここでは、ストリングは、粒子の位置を時間次元に拡張して「ワールドライン」を形成することによって作成されます。2つの粒子の位置を時間に対してプロットすることを想像してください。粒子がその場にとどまる場合、プロットは単に、それらの定常位置を表す2本の平行線になります。しかし、粒子の場所を交換すると、ワールドラインがお互いに絡み合います。2回交換すると、結び目ができます。 少し視覚化するのは難しいですが、4次元(3つの空間プラス1つの時間次元)の結び目は常に簡単に解除できます。それらは自明です。シューレースのように、片方の端を引っ張って解きます。しかし、粒子が2次元空間に制限されている場合、結び目は3次元にあり、私たちの日常的な3Dの生活から知っているように、常に簡単には解除できません。非アーベル任意子のワールドラインの結び目は、粒子の状態を変換するための量子計算操作として使用できます。 非アーベル任意子の重要な側面は「退化度」です。いくつかの分離された任意子の完全な状態はローカル情報によって完全に指定されるわけではなく、同じ任意子構成はいくつかの量子状態の重ね合わせを表すことができます。非アーベル任意子を互いに巻き付けることで、エンコードされた状態が変化する可能性があります。 非アーベル任意子の作り方 Googleの量子プロセッサーの1つで非アーベル結び目を実現するにはどうすればよいでしょうか?私たちは最近、量子誤り訂正のマイルストーンを達成したサーフェスコードから始めます。量子ビットはチェッカーボードパターンの頂点に配置されます。チェッカーボードの各色の正方形は、正方形の四隅にある量子ビットの2つの可能な共同測定の1つを表します。これらの「スタビライザー測定」は、+または-1の値を返すことができます。後者はプラケット違反と呼ばれ、単一量子ビットのXおよびZゲートを適用して、斜めに作成および移動できます(チェスのビショップのように)。最近、これらのビショップのようなプラケット違反はアーベル任意子であることを示しました。非アーベル任意子とは対照的に、アーベル任意子の状態は、交換されたときにわずかに変化します。非常に微妙で、直接検出することは不可能です。アーベル任意子は興味深いですが、非アーベル任意子ほどトポロジカル量子計算にとって有望ではありません。 非アーベルアニオンを生成するには、 degeneracy(つまり、すべてのスタビライザー測定が+1になる波動関数の数)を制御する必要があります。スタビライザー測定は2つの可能な値を返すため、各スタビライザーはシステムの degeneracy を半分に減らし、十分な数のスタビライザーで、1つの波動関数だけが基準を満たすようになります。したがって、 degeneracy を増やす簡単な方法は、2つのスタビライザーを合併することです。そうすることで、スタビライザーグリッドから1つのエッジを除去し、3つのエッジが交差する2つの点が生じます。これらの点は、「degree-3 vertices」(D3Vs)と呼ばれ、非アーベルアニオンであると予測されています。 D3Vをブレードするためには、それらを動かす必要があります。つまり、スタビライザーを新しい形に伸ばしたり、圧縮したりする必要があります。これは、アニオンとその近隣の間に2キュビットゲートを実装することによって実現します(下の中央と右のパネルを参照)。 スタビライザーコード内の非アーベルアニオン。a:…
Amazon TranslateのActive Custom Translationを使用して、マルチリンガル自動翻訳パイプラインを構築します
Deep Learning(D2L.ai)に飛び込むは、深層学習を誰にでもアクセス可能にするオープンソースのテキストブックですPyTorch、JAX、TensorFlow、MXNetで自己完結型のコードを含む対話型Jupyterノートブック、実世界の例、解説図、数学などが特徴ですこれまでに、D2Lは世界中の400以上の大学で採用されています、例えば[...]
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.