Learn more about Search Results CARTO - Page 3

- You may be interested
- カルテックとETHチューリッヒの研究者が画...
- アマゾンは、医師の診察内容を要約し、フ...
- ロボットウナギが魚の効率的な泳ぎ方を明...
- MLflowを使用した機械学習実験のトラッキング
- 手首に装着するモバイルアルコールセンサ...
- Microsoft BingはNVIDIA Tritonを使用して...
- フランス国立科学研究センター(CNRS)に...
- 「18/9から24/9までの週のトップ重要コン...
- 「2人が同じイニシャルを持っている確率は...
- ワシントン大学とAI2の研究者が、VQAを介...
- 黄金時代:『エイジ オブ エンパイア III...
- 「誰もがLLMプロンプトインジェクションか...
- 「新しいNVIDIA H100、H200 Tensor Core G...
- グーグルの研究者たちは、MEMORY-VQという...
- 「研究者たちが、数千の変形可能な結び目...

Hugging Face Spacesでタンパク質を可視化する
この投稿では、Hugging Face Spacesでタンパク質を可視化する方法について見ていきます。 動機 🤗 タンパク質は、医薬品から洗剤まで私たちの生活に大きな影響を与えています。タンパク質の機械学習は、新しい興味深いタンパク質の設計を支援するための急速に成長している分野です。タンパク質は、主にアミノ酸と呼ばれる一連の構成要素を3D空間に配列して、タンパク質の機能を与える複雑な3Dオブジェクトです。機械学習の目的で、タンパク質は、例えば座標、グラフ、またはタンパク質言語モデルで使用するための1次元の文字列として表現することができます。 タンパク質の有名な機械学習モデルの一つにAlphaFold2があります。AlphaFold2は、類似のタンパク質の多重配列と構造モジュールを使用してタンパク質配列の構造を予測します。 AlphaFold2が登場して以来、OmegaFold、OpenFoldなど、さまざまなモデルが登場しました(詳細はこのリストやこのリストを参照)。 見ることは信じること タンパク質の構造は、タンパク質の機能を理解する上で重要な要素です。現在、mol*や3dmol.jsなどのブラウザで直接タンパク質を可視化するためのツールがいくつか利用可能です。この投稿では、3Dmol.jsとHTMLブロックを使用して、Hugging Face Spaceに構造可視化を統合する方法を学びます。 必要条件 すでにgradio Pythonパッケージがインストールされていること、およびJavascript / JQueryの基本的な知識を持っていることを確認してください。 コードの概要 3Dmol.jsのセットアップ方法に入る前に、インターフェースの最小機能デモを作成する方法を見てみましょう。 以下のコードは、4桁のPDBコードまたはPDBファイルを受け入れる簡単なデモアプリを作成します。アプリは、RCSB Protein Databankからpdbファイルを取得して表示するか、アップロードされたファイルを使用して表示します。 import gradio…
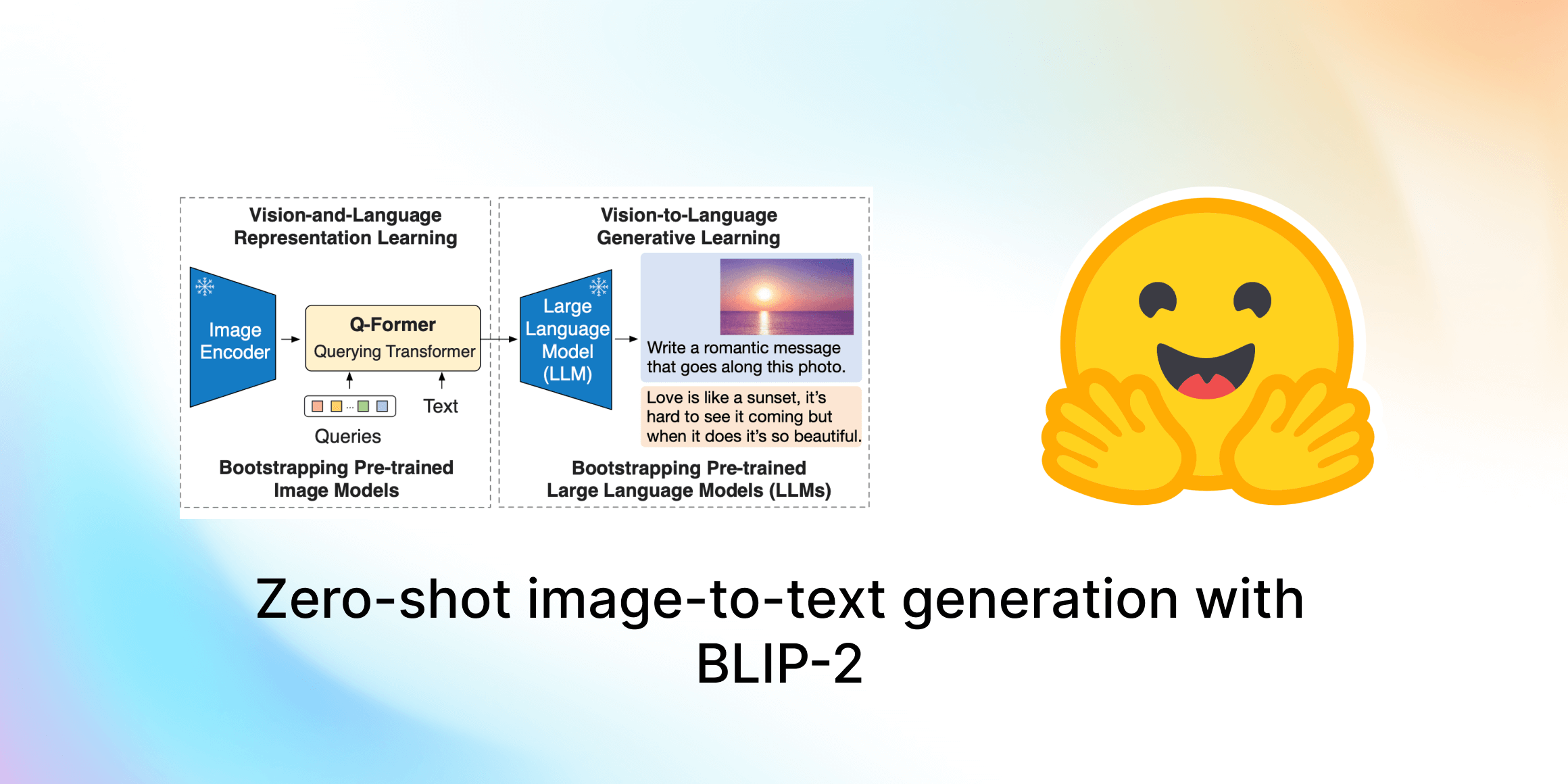
ゼロショット画像からテキスト生成 BLIP-2
このガイドでは、Salesforce ResearchのBLIP-2を紹介します。これは最先端のビジュアル言語モデルのスイートで、現在は🤗 Transformersで利用可能です。画像キャプショニング、プロンプト付き画像キャプショニング、ビジュアルな質問応答、チャットベースのプロンプトに使用する方法を紹介します。 目次 はじめに BLIP-2の内部構造は? Hugging Face TransformersでのBLIP-2の使用 画像キャプショニング プロンプト付き画像キャプショニング ビジュアルな質問応答 チャットベースのプロンプト 結論 謝辞 はじめに 近年、コンピュータビジョンと自然言語処理の分野で急速な進歩がありました。しかし、多くの現実世界の問題は本質的にマルチモーダルです。つまり、画像やテキストなど、複数の異なる形式のデータを含みます。ビジュアル言語モデルは、異なるモダリティを組み合わせることで、さまざまなアプリケーションの可能性を広げるという課題に直面しています。ビジュアル言語モデルが取り組むことができる画像からテキストへのタスクには、画像キャプショニング、画像テキスト検索、ビジュアルな質問応答などがあります。画像キャプショニングは視覚障害者の支援、有用な商品説明の作成、テキスト以外の不適切なコンテンツの特定などに役立ちます。画像テキスト検索はマルチモーダルな検索や自動運転などのアプリケーションに適用することができます。ビジュアルな質問応答は教育に役立ち、マルチモーダルなチャットボットを可能にし、さまざまなドメイン固有の情報検索アプリケーションを支援します。 現代のコンピュータビジョンと自然言語モデルは、より優れた性能を持つ一方で、以前のモデルと比べて大幅にサイズが増えています。単一のモダリティモデルの事前学習はリソースを消費し、高コストですが、ビジョンと言語のエンドツーエンドの事前学習のコストはますます高くなっています。BLIP-2は、事前学習済みのビジョンエンコーダとLLMの組み合わせを活用し、アーキテクチャ全体をエンドツーエンドで事前学習する必要なく、新しいビジュアル言語の事前学習パラダイムを導入することで、この課題に取り組んでいます。これにより、複数のビジュアル言語タスクで最先端の結果を実現しながら、訓練可能なパラメータの数と事前学習コストを大幅に削減することができます。さらに、この手法はマルチモーダルなChatGPTのモデルへの道を切り拓きます。 BLIP-2の内部構造は? BLIP-2は、既製の凍結された事前学習済み画像エンコーダと凍結された大規模言語モデルの間に、軽量なクエリングトランスフォーマ(Q-Former)を追加することで、ビジョンと言語モデルのモダリティのギャップを埋めます。Q-FormerはBLIP-2の唯一の訓練可能な部分であり、画像エンコーダと言語モデルは凍結されたままです。 Q-Formerは、2つのサブモジュールからなるトランスフォーマモデルであり、同じセルフアテンションレイヤを共有しています: 画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。 テキストトランスフォーマは、テキストエンコーダおよびテキストデコーダとして機能することができます。 画像トランスフォーマは、入力画像の解像度に関係なく、固定数の出力特徴を画像エンコーダから抽出し、学習可能なクエリ埋め込みを入力として受け取ります。クエリは同じセルフアテンションレイヤを介してテキストとも相互作用できます。…

Instruction-tuning Stable Diffusion with InstructPix2PixのHTMLを日本語に翻訳してください
この投稿では、安定拡散を教えるための指示調整について説明します。この方法では、入力画像と「指示」(例:自然画像に漫画フィルタを適用する)を使用して、安定拡散を促すことができます。 ユーザーの指示に従って安定拡散に画像編集を実行させるアイデアは、「InstructPix2Pix: Learning to Follow Image Editing Instructions」で紹介されました。InstructPix2Pixのトレーニング戦略を拡張して、画像変換(漫画化など)や低レベルな画像処理(画像の雨除去など)に関連するより具体的な指示に従う方法について説明します。以下をカバーします: 指示調整の紹介 この研究の動機 データセットの準備 トレーニング実験と結果 潜在的な応用と制約 オープンな問い コード、事前学習済みモデル、データセットはこちらで見つけることができます。 導入と動機 指示調整は、タスクを解決するために言語モデルに指示を従わせる教師ありの方法です。Googleの「Fine-tuned Language Models Are Zero-Shot Learners (FLAN)」で紹介されました。最近では、AlpacaやFLAN V2などの作品が良い例であり、指示調整がさまざまなタスクにどれだけ有益であるかを示しています。…

Intel CPUのNNCFと🤗 Optimumを使用した安定したディフュージョンの最適化
潜在的な拡散モデルは、テキストから画像の生成問題を解決する際にゲームチェンジャーとなります。 安定した拡散は、コミュニティや産業界で広く採用されている最も有名な例の一つです。 安定した拡散モデルのアイデアはシンプルで魅力的です:ノイズベクトルから画像を複数の小さなステップで生成し、ノイズを潜在的な画像表現に洗練させます。 ただし、このようなアプローチは、全体的な推論時間を増加させ、クライアントマシンで展開された場合にユーザーエクスペリエンスの低下を引き起こします。 通常のように、強力なGPUがここで役立つことに注意することができますが、これに伴うコストも著しく増加します。 参考までに、H1’23では、8つのvCPUと64GBのRAMを備えた強力なCPU r6i.2xlargeインスタンスの価格は1時間あたり$0.504であり、同様のNVIDIA T4を搭載したg4dn.2xlargeインスタンスの価格は1時間あたり$0.75で、これは1.5倍以上です.. これにより、画像生成サービスは所有者とユーザーにとって非常に高価になります。 クライアントアプリケーションでは、GPUがまったくない場合もあります! これにより、安定した拡散パイプラインの展開は困難な問題となります。 過去5年間、OpenVINO Toolkitは高性能推論のための多くの機能をカプセル化しました。 最初はコンピュータビジョンモデルに設計されたものですが、現在でも最先端のモデルを含む多くのコンテンポラリーモデルにおいて、最高の推論パフォーマンスを示しています。 ただし、リソース制約のあるアプリケーションに安定した拡散モデルを最適化するには、ランタイム最適化にとどまらず、さらに進んだモデル最適化機能がOpenVINO Neural Network Compression Framework(NNCF)から必要とされます。 このブログ記事では、安定した拡散モデルの最適化の問題を概説し、CPUなどのリソース制約のあるHWで実行される場合に、そのようなモデルのレイテンシを大幅に削減するワークフローを提案します。 特に、PyTorchと比較して5.1倍の推論高速化と4倍のモデルフットプリントの削減を達成しました。 安定した拡散の最適化 安定した拡散パイプラインでは、UNetモデルが計算上最もコストがかかります。そのため、単一のモデルの最適化によって推論速度が大幅に向上します。 しかし、このモデルに対しては、従来のモデル最適化手法であるポストトレーニングの8ビット量子化は機能しないことがわかりました。その理由は2つあります。まず、セマンティックセグメンテーション、スーパーレゾリューションなどのピクセルレベル予測モデルは、タスクの複雑さにより、モデル最適化の観点では最も複雑なものの一つであり、モデルパラメータと構造の微調整が結果を多数の方法で崩してしまいます。…

紛争のトレンドとパターンの探索:マニプールのACLEDデータ分析
はじめに データ分析と可視化は、複雑なデータセットを理解し、洞察を効果的に伝えるための強力なツールです。この現実世界の紛争データを深く掘り下げる没入型探索では、紛争の厳しい現実と複雑さに深く踏み込みます。焦点は、長期にわたる暴力と不安定状態によって悲惨な状況に陥ったインド北東部のマニプール州にあります。私たちは、武装紛争ロケーション&イベントデータプロジェクト(ACLED)データセット[1]を使用し、紛争の多面的な性質を明らかにするための詳細なデータ分析の旅に出ます。 学習目標 ACLEDデータセットのデータ分析技術に熟達する。 効果的なデータ可視化のスキルを開発する。 脆弱な人口に対する暴力の影響を理解する。 紛争の時間的および空間的な側面に関する洞察を得る。 人道的ニーズに対処するための根拠に基づくアプローチを支援する。 この記事は、データサイエンスブログマラソンの一環として公開されました。 利害の衝突 このブログで提示された分析と解釈に責任を持つ特定の組織や団体はありません。目的は、紛争分析におけるデータサイエンスの潜在力を紹介することです。さらに、これらの調査結果には個人的な利益や偏見が含まれておらず、紛争のダイナミクスを客観的に理解するアプローチが確保されています。データ駆動型の方法を促進し、紛争分析に関する広範な議論に情報を提供するために、積極的に利用することを推奨します。 実装 なぜACLEDデータセットを使用するのか? ACLEDデータセットを活用することで、データサイエンス技術の力を活用することができます。これにより、マニプール州の状況を理解するだけでなく、暴力に関連する人道的側面にも光を当てることができます。ACLEDコードブックは、このデータセット[2]で使用されるコーディングスキームと変数に関する詳細な情報を提供する包括的な参考資料です。 ACLEDの重要性は、共感的なデータ分析にあります。これにより、マニプール州の暴力に関する理解が深まり、人道的ニーズが明らかにされ、暴力の解決と軽減に貢献します。これにより、影響を受けるコミュニティに平和で包摂的な未来が促進されます。 このデータ駆動型の分析により、貴重な洞察力を得るだけでなく、マニプール州の暴力の人的コストにも光が当てられます。ACLEDデータを精査することで、市民人口、強制的移動、必要なサービスへのアクセスなど、地域で直面する人道的現実の包括的な描写が可能になります。 紛争のイベント まず、ACLEDデータセットを使用して、マニプール州の紛争のイベントを調査します。以下のコードスニペットは、インドのACLEDデータセットを読み込み、マニプール州のデータをフィルタリングして、形状が(行数、列数)のフィルタリングされたデータセットを生成します。フィルタリングされたデータの形状を出力します。 import pandas as pd # ACLEDデータをダウンロードして国別のcsvをインポートする…

2023年のトップ7人工知能絵画ジェネレーター
AIのペインティングジェネレーターは創造的な世界を革命化しました私たちはデジタルアートの分野での刺激的な進歩を熱望しています

カートゥーンキャラクターの中間プロンプト
Midjourneyは、芸術的なスキルや背景がなくても、漫画キャラクターを作成するのに役立つ素晴らしいツールです
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.