Learn more about Search Results BART - Page 3

- You may be interested
- 🧨ディフューザーを使用した安定した拡散
- Rにおけるトップ10のエラーとそれらを修正...
- 「モジュラーディフュージョンを紹介しま...
- ネットワークの強化:異常検知におけるML...
- テキストブック品質の合成データを使用し...
- 20以上のスタートアップに最適なAIツール...
- VoAGIニュース、12月6日:機械学習をマス...
- 大規模な言語モデルをマスターするための...
- 「人工知能による在庫管理の革命:包括的...
- 「線形代数1:線形方程式とシステム」
- 初心者向けの転移学習
- 「2023年の公共セクターにおけるデータス...
- 大規模な言語モデルは本当に数学をできる...
- 「データセンターは冷房を少なくしても同...
- 「強化学習の実践者ガイド」

「CMUの研究者たちは、スロット中心のモデル(Slot-TTA)を用いたテスト時の適応を提案していますこれは、シーンを共通してセグメント化し、再構築するスロット中心のボトルネックを備えた半教師付きモデルです」
コンピュータビジョンの最も困難で重要なタスクの1つは、インスタンスセグメンテーションです。画像や3Dポイントクラウド内のオブジェクトを正確に区別し、カテゴリ分けする能力は、自律走行から医療画像解析までさまざまなアプリケーションに基盤となるものです。これらの最先端のインスタンスセグメンテーションモデルの開発においては、長年にわたって著しい進歩が達成されてきました。しかし、これらのモデルは、しばしばトレーニング分布から逸脱した多様な現実のシナリオとデータセットに対して助けが必要です。セグメンテーションモデルをこれらの分布外(OOD)シナリオに適応させるというこの課題は、革新的な研究を促しています。そのような画期的なアプローチの1つであるSlot-TTA(テスト時適応)は、非常に注目されています。 計算機ビジョンの急速な進化の中で、インスタンスセグメンテーションモデルは顕著な進歩を遂げ、画像や3Dポイントクラウド内のオブジェクトを認識し、正確にセグメント化することが可能となりました。これらのモデルは、医療画像解析から自動運転車まで、さまざまなアプリケーションの基盤となっています。しかし、それらは共通の困難な敵に直面しています。それは、トレーニングデータを超える多様な現実のシナリオとデータセットに適応することです。異なるドメイン間でシームレスに移行することのできなさは、これらのモデルを効果的に展開するための重要な障壁となっています。 カーネギーメロン大学、Google Deepmind、Google Researchの研究者たちは、この課題に対処する画期的なソリューションであるSlot-TTAを発表しました。この新しいアプローチは、インスタンスセグメンテーションのテスト時適応(TTA)に設計されています。Slot-TTAは、スロット中心の画像とポイントクラウドレンダリングコンポーネントの能力と最先端のセグメンテーション技術を結びつけています。Slot-TTAの核となるアイデアは、インスタンスセグメンテーションモデルがOODシナリオに動的に適応できるようにすることであり、これにより精度と汎用性が大幅に向上します。 Slot-TTAは、その主なセグメンテーション評価指標として調整済みランド指数(ARI)の基礎に基づいて動作します。Slot-TTAは、マルチビューの姿勢付きRGB画像、単一ビューのRGB画像、複雑な3Dポイントクラウドなど、さまざまなデータセットで厳密なトレーニングと評価を行います。Slot-TTAの特徴的な特徴は、テスト時適応のための再構成フィードバックを活用する能力です。このイノベーションは、以前に見たことのない視点とデータセットに対してセグメンテーションとレンダリングの品質を反復的に改善することを含みます。 マルチビューの姿勢付きRGB画像において、Slot-TTAは強力な競合相手として浮上します。その適応性は、MultiShapeNetHard(MSN)データセットの包括的な評価によって示されます。このデータセットには、リアルワールドのHDR背景に対して注意深くレンダリングされた51,000以上のShapeNetオブジェクトが含まれています。MSNデータセットの各シーンには、Slot-TTAのトレーニングとテストのために入力ビューとターゲットビューに戦略的に分割された9つの姿勢付きRGBレンダリング画像があります。研究者たちは、トレーニングセットとテストセットの間のオブジェクトインスタンスとシーン中のオブジェクトの数に重なりがないように特別な配慮をしています。この厳格なデータセットの構築は、Slot-TTAの堅牢性を評価するために重要です。 評価では、Slot-TTAはMask2Former、Mask2Former-BYOL、Mask2Former-Recon、Semantic-NeRFなどのいくつかのベースラインと対決します。これらのベースラインは、Slot-TTAのパフォーマンスをトレーニング分布内外で比較するためのベンチマークです。その結果は驚くべきものです。 まず最初に、OODシーンにおいて特にMask2Formerと比較して、Slot-TTA with TTAは優れた性能を発揮します。これは、Slot-TTAが多様な現実のシナリオに適応する能力の優れていることを示しています。 次に、Mask2Former-BYOLにおけるBartlerらの自己教師あり損失の追加は、改善をもたらさないことが明らかになります。これは、すべてのTTA手法が同じくらい効果的ではないことを強調しています。 さらに、セグメンテーション監督なしのSlot-TTAは、OSRT(Sajjadi et al., 2022a)のようなクロスビュー画像合成にのみトレーニングされたバリアントと比較して、Mask2Formerのような監督セグメンターに比べて大幅に性能が低下します。この観察結果は、効果的なTTAのためには訓練中のセグメンテーション監督の必要性を強調しています。 Slot-TTAの能力は、新しい、以前に見たことのないRGB画像ビューの合成と分解にも広がります。前述のデータセットとトレーニングとテストの分割を使用して、研究者はSlot-TTAのピクセル単位の再構成品質とセグメンテーションARIの精度を、5つの新しい、以前に見たことのない視点について評価します。この評価には、TTAのトレーニング中に見られなかったビューも含まれます。その結果は驚くべきものです。 Slot-TTA(Slot-centric Temporal Test-time Adaptation)による未知の視点におけるレンダリングの品質は、テスト時の適応によって大幅に向上し、新しいシナリオでのセグメンテーションとレンダリングの品質を向上させる能力を示しています。これに対し、強力な競合であるSemantic-NeRFは、これらの未知の視点への一般化に苦労しており、Slot-TTAの適応性と潜在能力を示しています。 結論として、Slot-TTAはコンピュータビジョンの分野における重要な進歩を表しており、多様な現実世界のシナリオにセグメンテーションモデルを適応させるという課題に取り組んでいます。スロット中心のレンダリング技術、高度なセグメンテーション手法、およびテスト時の適応を組み合わせることで、Slot-TTAはセグメンテーションの精度と汎用性の両方で顕著な改善を提供します。この研究は、モデルの制約を明らかにするだけでなく、コンピュータビジョンの将来のイノベーションへの道を開拓します。Slot-TTAは、コンピュータビジョンの絶えず進化する領域で、インスタンスセグメンテーションモデルの適応性を向上させることを約束します。
「場所の言語:生成AIのジオコーディング能力の評価」
「現代のジオコーディングAPIと比較したLLMsのパフォーマンスに関する応用プロジェクトの詳細」
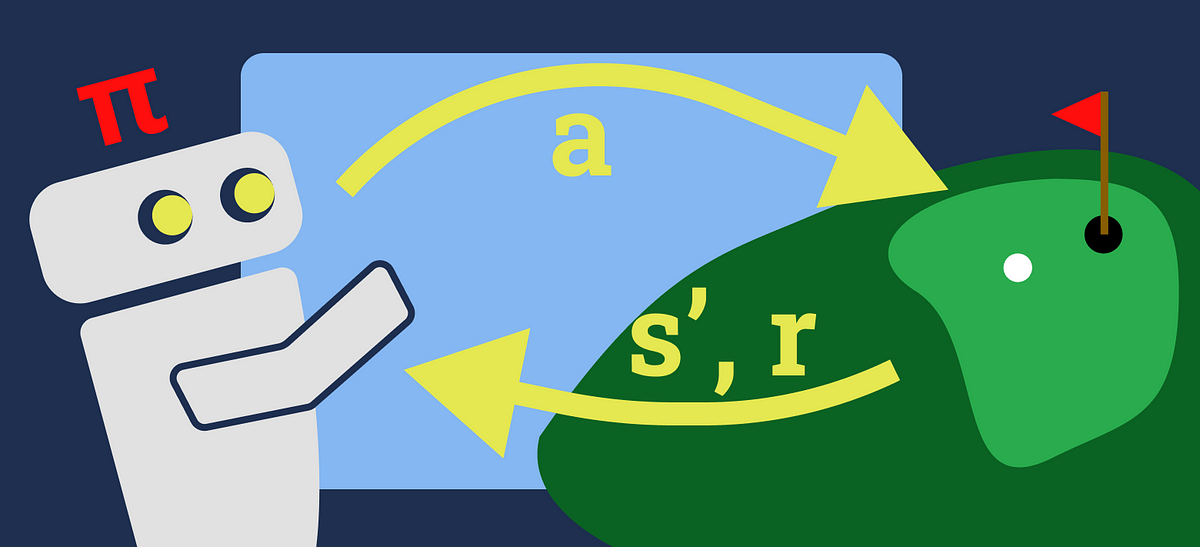
強化学習 価値反復の簡単な入門
価値反復(VI)は、通常、強化学習(RL)学習経路で最初に紹介されるアルゴリズムの一つですアルゴリズムの基本的な内容は、最も…

「LLMの力を活用する:ゼロショットとフューショットのプロンプティング」
はじめに LLMのパワーはAIコミュニティで新たなブームとなりました。GPT 3.5、GPT 4、BARDなどのさまざまな生成型AIソリューションが異なるユースケースで早期採用されています。これらは質問応答タスク、クリエイティブなテキストの執筆、批判的分析などに使用されています。これらのモデルは、さまざまなコーパス上で次の文予測などのタスクにトレーニングされているため、テキスト生成に優れていると期待されています。 頑健なトランスフォーマーベースのニューラルネットワークにより、モデルは分類、翻訳、予測、エンティティの認識などの言語に基づく機械学習タスクにも適応することができます。したがって、適切な指示を与えることで、データサイエンティストは生成型AIプラットフォームをより実践的で産業的な言語ベースのMLユースケースに活用することが容易になりました。本記事では、プロンプティングを使用した普及した言語ベースのMLタスクに対する生成型LLMの使用方法を示し、ゼロショットとフューショットのプロンプティングの利点と制限を厳密に分析することを目指します。 学習目標 ゼロショットとフューショットのプロンプティングについて学ぶ。 例として機械学習タスクのパフォーマンスを分析する。 フューショットのプロンプティングをファインチューニングなどのより高度な技術と比較評価する。 プロンプティング技術の利点と欠点を理解する。 この記事はData Science Blogathonの一部として公開されました。 プロンプティングとは? まず、LLMを定義しましょう。大規模言語モデル(LLM)とは、数億から数十億のパラメータを持つ、複数のトランスフォーマーとフィードフォワードニューラルネットワークの層で構築されたディープラーニングシステムです。これらはさまざまなソースの大規模なデータセットでトレーニングされ、テキストを理解し生成するために構築されています。言語翻訳、テキスト要約、質問応答、コンテンツ生成などが例です。LLMにはさまざまなタイプがあります:エンコーダのみ(BERT)、エンコーダ+デコーダ(BART、T5)、デコーダのみ(PALM、GPTなど)。デコーダコンポーネントを持つLLMは生成型LLMと呼ばれ、これがほとんどのモダンなLLMの場合です。 生成型LLMに特定のタスクを実行させるには、適切な指示を与えます。LLMは、プロンプトとも呼ばれる指示に基づいてエンドユーザーに応答するように設計されています。ChatGPTなどのLLMと対話したことがある場合、プロンプトを使用したことがあります。プロンプティングは、モデルが望ましい応答を返すための自然言語のクエリで私たちの意図をパッケージングすることです(例:図1、出典:Chat GPT)。 以下のセクションでは、ゼロショットとフューショットの2つの主要なプロンプティング技術を詳しく見ていきます。それぞれの詳細と基本的な例を見ていきましょう。 ゼロショットプロンプティング ゼロショットプロンプティングは、生成型LLMに特有のゼロショット学習の特定のシナリオです。ゼロショットでは、モデルにラベル付きのデータを提供せず、完全に新しい問題に取り組むことを期待します。例えば、適切な指示を提供することにより、新しいタスクに対してChatGPTをゼロショットプロンプティングに使用します。LLMは多くのリソースからコンテンツを理解しているため、未知の問題に適応することができます。いくつかの例を見てみましょう。 以下は、テキストをポジティブ、ニュートラル、ネガティブの感情クラスに分類するための例です。 ツイートの例 ツイートの例は、Twitter US…

高度な言語モデルの世界における倫理とプライバシーの探求
はじめに 現代の急速に進化する技術的な景観において、大規模言語モデル(LLM)は、産業を再構築し、人間とコンピュータの相互作用を革新する変革的なイノベーションです。高度な言語モデルの驚異的な能力は、人間のようなテキストを理解し生成することで、深いポジティブな影響をもたらす可能性を秘めています。しかし、これらの強力なツールは複雑な倫理的な課題を浮き彫りにします。 この記事は、LLMの倫理的な次元に深く立ち入り、バイアスとプライバシーの問題という重要な問題に焦点を当てています。LLMは、比類のない創造力と効率性を提供しますが、無意識にバイアスを持続させ、個人のプライバシーを損なう可能性があります。私たちの共有の責任は、これらの懸念に積極的に取り組み、倫理的な考慮事項がLLMの設計と展開を促進し、それによって社会的な幸福を優先することです。これらの倫理的な考慮事項を緻密に組み込むことで、私たちはAIの可能性を活かしながら、私たちを定義する価値と権利を守ります。 学習目標 大規模言語モデル(LLM)とその産業や人間とコンピュータの相互作用に与える変革的な影響について、深い理解を開発する。 バイアスとプライバシーの懸念に関連する、LLMが抱える複雑な倫理的な課題を探求する。これらの考慮事項がAI技術の倫理的な開発を形作る方法を学ぶ。 Pythonと必須の自然言語処理ライブラリを使用して、倫理的に優れたLLMを作成するためのプロジェクト環境を確立する実践的なスキルを習得する。 LLMの出力に潜在的なバイアスを特定し修正する能力を向上させ、公平かつ包括的なAI生成コンテンツを確保する。 データのプライバシーを保護する重要性を理解し、LLMプロジェクト内での機密情報の責任ある取り扱いのための技術を習得し、説明責任と透明性の環境を育成する。 この記事は、データサイエンスブログマラソンの一環として公開されました。 言語モデルとは何ですか? 言語モデルは、人間のようなテキストを理解し生成するために設計された人工知能システムです。言語モデルは、広範なテキストデータからパターンや関係を学び、一貫した文や文脈に即した文章を生成することができます。言語モデルは、コンテンツの生成から翻訳、要約、会話の支援など、さまざまな分野で応用されています。 プロジェクト環境の設定 倫理的な大規模言語モデルの開発のためには、適切なプロジェクト環境の構築が重要です。このセクションでは、LLMプロジェクトの環境を構築するための基本的な手順を案内します。 必須のライブラリと依存関係のインストール 倫理的な大規模言語モデル(LLM)の開発には、最適な環境が不可欠です。このセグメントでは、Pythonの仮想環境を使用して、適切なLLMプロジェクトのセットアップ手順を案内します。 LLMの旅に乗り出す前に、必要なツールとライブラリが揃っていることを確認してください。このガイドでは、Pythonの仮想環境を介して重要なライブラリと依存関係のインストール手順を案内します。準備を入念に行って成功への道を切り開きます。 これらの手順は、効果的かつ倫理的な方法でLLMをプロジェクトで活用するための堅牢な基盤を築きます。 なぜ仮想環境が重要なのですか? 技術的な詳細に入る前に、仮想環境の目的を理解しましょう。それはプロジェクト用の砂場のようなものであり、プロジェクト固有のライブラリや依存関係をインストールする自己完結型のスペースを作成します。この隔離により、他のプロジェクトとの競合を防ぎ、LLMの開発におけるクリーンな作業スペースを確保します。 Hugging Face Transformersライブラリ:LLMプロジェクトの強化 Transformersライブラリは、事前学習済みの言語モデルやAI開発ツールのスイートにアクセスするためのゲートウェイです。これにより、LLMとの作業がシームレスで効率的になります。…

ランダムウォークタスクにおける時差0(Temporal-Difference(0))と定数αモンテカルロ法の比較
モンテカルロ(MC)法と時間差分(TD)法は、強化学習の分野での基本的な手法です経験に基づいて予測問題を解決します
データ、効率化された:より良い製品、ワークフロー、チームの構築方法
「利用可能なデータと有用なデータの間のギャップは、データプラクティショナーが実現するための唯一の目的である企業やツールの増加にもかかわらず、非常に困難であることが証明されています」

「Amazon SageMaker JumpStartを使用したゼロショットテキスト分類」
自然言語処理(NLP)は、機械学習(ML)の分野であり、コンピュータに人間と同じようにテキストや話された言葉を理解する能力を与えることに関心があります最近では、トランスフォーマーアーキテクチャなどの最先端のアーキテクチャが使用され、テキスト要約、テキスト分類、エンティティ認識などのNLP下流タスクでほぼ人間のパフォーマンスを実現するために使用されています
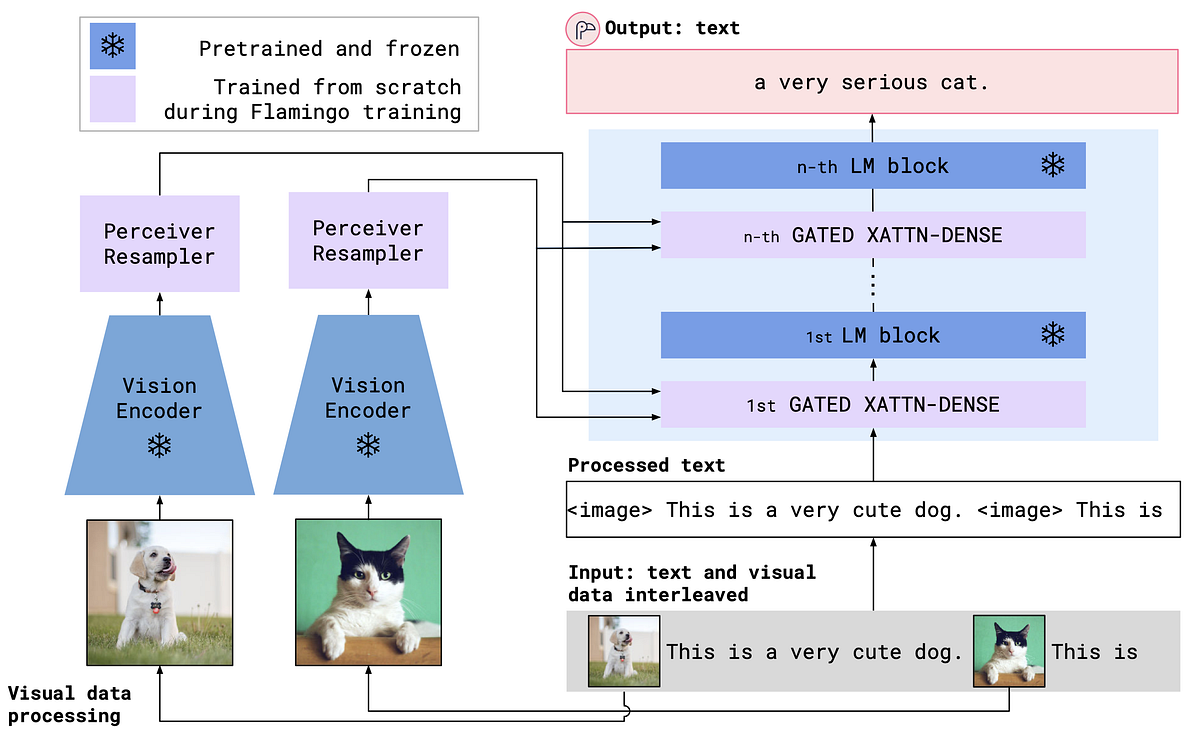
マルチモーダル言語モデルの解説:ビジュアル指示の調整
「LLMは、多くの自然言語タスクでゼロショット学習とフューショット学習の両方で有望な結果を示していますしかし、LLMは視覚的な推論を必要とするタスクにおいては不利です...」

オフポリシーモンテカルロ制御を用いた強化学習レーストラックの演習問題の解決
『「強化学習入門 第2版」の「オフポリシーモンテカルロ制御」セクション(112ページ)では、著者が興味深い演習を残してくれました:重み付けを使って…』
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.