Learn more about Search Results Anaconda - Page 3

- You may be interested
- 「7つの最高のクラウドデータベースプラッ...
- 「モデルガバナンスを向上させるために、A...
- 「IBMの研究者たちは、モダリティやタスク...
- Sentence Transformersモデルのトレーニン...
- FuncReAct OpenAIの関数呼び出しを利用し...
- 「6つの人工知能の神話を解明:事実とフィ...
- 「Amazon SageMakerは、個々のユーザーの...
- 「2023年のトップビデオ会議ツール」
- AIサージ:Stability AIのCEOは、2年以内...
- ジオスペーシャルデータ分析のための5つの...
- パーソナライズされたAIの簡単な作成方法...
- K最近傍法の例の応用
- トロント大学の研究者が、大規模な材料デ...
- 「Huggingface 🤗を使用したLLMsのためのR...
- AdCreative.aiレビュー:広告のための最高...
「Hugging Face Transformersライブラリを解剖する」
これは、実践的に大規模言語モデル(LLM)を使用するシリーズの3番目の記事ですここでは、Hugging Face Transformersライブラリについて初心者向けのガイドを提供しますこのライブラリは、簡単で...

「5分でPythonとTkinterを使用してシンプルなユーザーフォームを作成する-初心者ガイド」
「今日、全てのビジネスが『デジタル化』することがトレンドになってきましたそれが小さなビジネスであっても大きなビジネスであっても、情報を手動で収集するよりもアプリケーションを利用する方が便利ですそれは…」
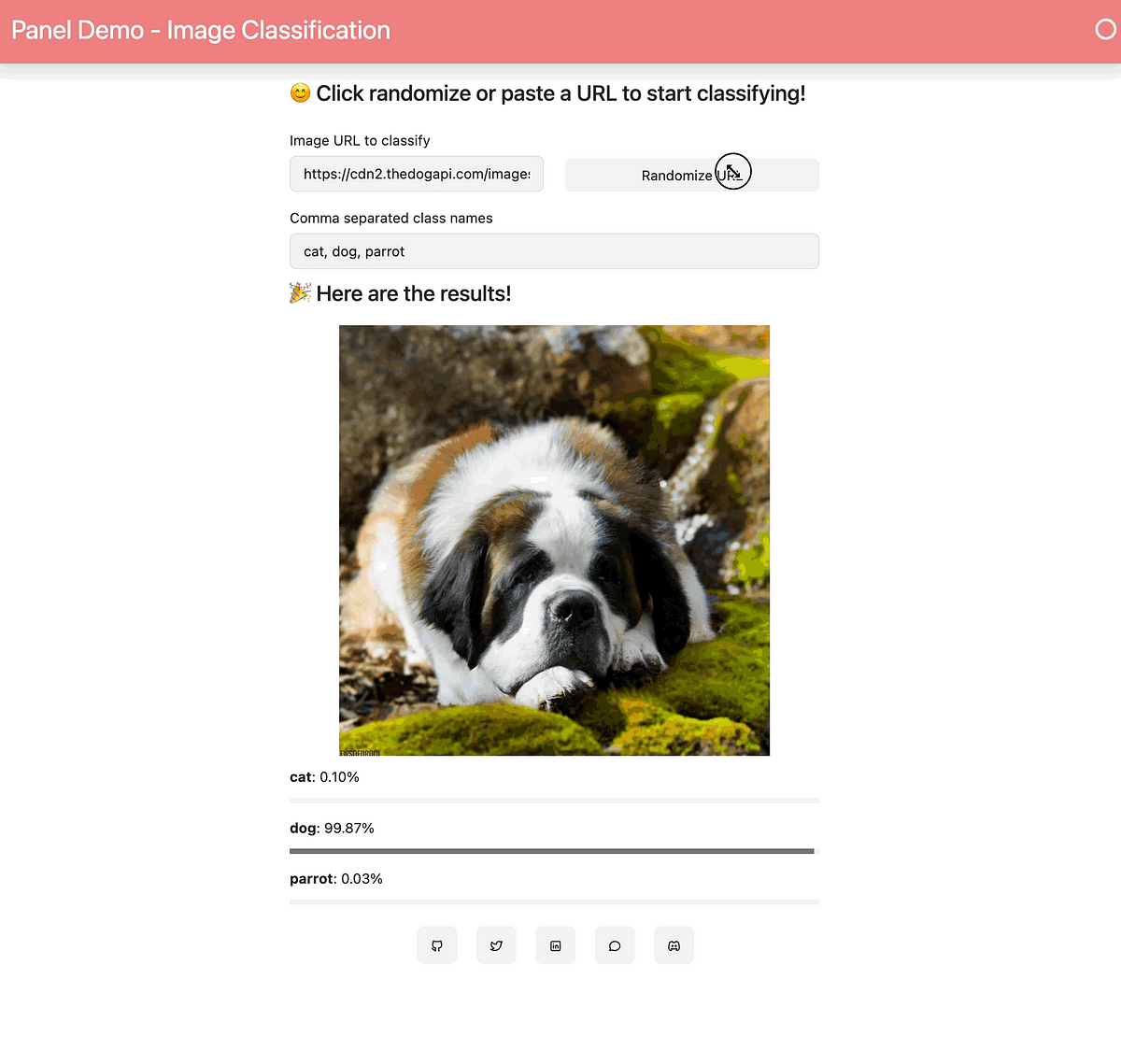
PanelでインタラクティブなMLダッシュボードを作成する
HoloViz Panelは、開発者やデータサイエンティストが簡単にインタラクティブな可視化を構築できる多目的なPythonライブラリです機械学習プロジェクトに取り組んでいるか、開発を行っているかに関わらず、HoloViz Panelはあなたをサポートします

LGBMClassifier 入門ガイド
このチュートリアルでは、PythonでLightGBMライブラリを使って、LGBMClassifierクラスを使用して分類モデルを構築する方法を探っていきます

機械学習の簡素化と標準化のためのトップツール
人工知能と機械学習は、技術の進歩によって世界中のさまざまな分野に恩恵をもたらす革新的なリーダーです。競争力を保つために、どのツールを選ぶかは難しい決断です。 機械学習ツールを選ぶことは、あなたの未来を選ぶことです。人工知能の分野では、すべてが非常に速く進化しているため、「昔の犬、昔の技」を守ることと、「昨日作ったばかり」のバランスを保つことが重要です。 機械学習ツールの数は増え続けており、それに伴い、それらを評価し、最適なものを選ぶ方法を理解する必要があります。 この記事では、いくつかのよく知られた機械学習ツールを紹介します。このレビューでは、MLライブラリ、フレームワーク、プラットフォームについて説明します。 Hermione 最新のオープンソースライブラリであるHermioneは、データサイエンティストがより整理されたスクリプトを簡単かつ迅速に設定できるようにします。また、Hermioneはデータビュー、テキストベクトル化、列の正規化と非正規化など、日常の活動を支援するためのトピックに関するクラスを提供しています。Hermioneを使用する場合、手順に従う必要があります。あとは彼女が魔法のように処理してくれます。 Hydra HydraというオープンソースのPythonフレームワークは、研究やその他の目的のために複雑なアプリを作成することを容易にします。Hydraは、多くの頭を持つヒドラのように多くの関連タスクを管理する能力を指します。主な機能は、階層的な構成を動的に作成し、構成ファイルとコマンドラインを介してそれをオーバーライドする能力です。 もう一つの機能は、動的なコマンドラインのタブ補完です。さまざまなソースから階層的に構成でき、構成はコマンドラインから指定または変更できます。また、単一のコマンドでリモートまたはローカルでプログラムを起動し、さまざまな引数で複数のタスクを実行することもできます。 Koalas Koalasプロジェクトは、巨大なデータ量で作業するデータサイエンティストの生産性を向上させるために、Apache Sparkの上にpandas DataFrame APIを統合しています。 pandasは(シングルノードの)Python DataFrameの事実上の標準実装であり、Sparkは大規模なデータ処理の事実上の標準です。pandasに慣れている場合、このパッケージを使用してすぐにSparkを使用し始め、学習曲線を回避することができます。単一のコードベースはSparkとPandasに互換性があります(テスト、より小さいデータセット)(分散データセット)。 Ludwig Ludwigは、機械学習パイプラインを定義するための明確で柔軟なデータ駆動型の設定アプローチを提供する宣言的な機械学習フレームワークです。Linux Foundation AI & DataがホストするLudwigは、さまざまなAI活動に使用することができます。 入力と出力の特徴と適切なデータ型は設定で宣言されます。ユーザーは、前処理、エンコード、デコードの追加のパラメータを指定したり、事前学習モデルからデータをロードしたり、内部モデルアーキテクチャを構築したり、トレーニングパラメータを調整したり、ハイパーパラメータ最適化を実行したりするための追加のパラメータを指定できます。 Ludwigは、設定の明示的なパラメータを使用してエンドツーエンドの機械学習パイプラインを自動的に作成し、設定されていない設定にはスマートなデフォルト値を使用します。…

「Amazon SageMakerトレーニングワークロードで@remoteデコレータを使用してプライベートリポジトリにアクセスする」
「ますます多くの顧客が機械学習(ML)のワークロードを本番環境に展開しようとする中、MLコードの開発ライフサイクルを短縮するために、組織内での大きな推進があります多くの組織は、試験的なスタイルではなく、Pythonのメソッドやクラスの形式でMLコードを本番向けに書くことを好みます」
「Amazon SageMakerのトレーニングワークロードで、@remoteデコレータを使用してプライベートリポジトリにアクセスする」
「機械学習(ML)のワークロードを本番環境に展開しようとする顧客がますます増えているため、MLコードの開発ライフサイクルを短縮するための組織内での大きな取り組みが行われています多くの組織は、探索的スタイルではなく、Pythonのメソッドとクラスの形式で、本番環境に対応したスタイルでMLコードを記述することを好む...」

5分であなたのStreamlitウェブアプリをデプロイしましょう
データサイエンティストが自分の作業をダッシュボードや動作するウェブアプリで紹介することが求められるようになりましたウェブアプリを作成するために利用可能なツールを知っていると非常に便利です利用可能なツールはたくさんあります...
5分であなたのStreamlitウェブアプリを展開してください
データサイエンティストが自分の仕事をダッシュボードや動作するWebアプリで紹介する必要性が高まってきていますWebアプリを作成するための利用可能なツールを知っておくことは非常に便利です利用可能なツールはたくさんあります...

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.