Learn more about Search Results 調査 - Page 3

- You may be interested
- この人工知能論文は、画像認識における差...
- 「標準偏差を超えた真のデータ分散を明ら...
- 人間のデータなしでの堅牢なリアルタイム...
- 「ギザギザしたCOVIDチャートの謎を解決す...
- 「犯罪者がWormGPT(ダークウェブのChatGP...
- 「医師がAIを活用して診療を変革する方法」
- 「LangchainとOpenAIを使用したGoogleドキ...
- 「デジタルハイスト」がロゼッタストーン...
- 「NumPyのドット積のデコード:次元の魔術...
- ChatGPTとテスラのFull-Self-Drivingは同...
- ウェイト、バイアス、ロスのアンボクシン...
- 「ダークウェブを照らす」
- 合成データ生成のマスタリング:応用とベ...
- 「静止画や無音ビデオからオーディオを取...
- チェサピーク保護協会の保護イノベーショ...

メタAIとケンブリッジ大学の研究者は、大規模言語モデル(LLM)が音声認識能力でプロンプトされる方法を調査しました
大規模言語モデル(Large Language Models)は、有名なChatGPTの導入により新しいトレンドとなっています。OpenAIによって開発されたこのチャットボットは、質問に正確に答えたり、長いテキストデータの要約をしたり、コードの断片を補完したり、テキストを異なる言語に翻訳したりするなど、あらゆることができます。LLMsは人間の模倣能力を持ち、自然言語処理、自然言語理解、自然言語生成、コンピュータビジョンなどの人工知能のサブフィールドに基づいています。 明示的な監督なしで、LLMsは膨大な量のテキストデータで次の単語を予測することによって訓練されます。その結果、彼らは自分たちのニューラルネットワークの制約の中で外界に関する大量の知識をエンコードする能力を発展させ、さまざまな下流のタスクに役立つようになります。LLMsはさまざまな分野で優れたパフォーマンスを示していますが、最近の研究ではモデルに小さな音声エンコーダを組み込むことで、音声認識を可能にするというLLMsの能力を一段と拡張しています。 この手順では、既存のテキストトークンエンベッディングに音声データの表現などの一連の音声エンベッディングを直接組み込むことが含まれます。これにより、LLMは統合された表現のおかげで、テキストベースの相当するものと同様に自動音声認識(ASR)タスクを行うことができます。また、口頭でのコミュニケーションを印刷されたテキストに翻訳することもできます。研究チームは、デコーダのみの大規模言語モデルが多言語音声認識を行い、オーディオシーケンスで訓練された場合、教師ありの単一言語トレーニングのベースラインを上回ることを共有しています。オーディオエンコーダモデルのサイズやフレームレート、LLMパラメータの低ランク適応、テキストトークンのマスキング、使用される大規模言語モデルのタイプなど、研究は認識精度を向上させるために検討するいくつかの変数を検討しています。 オーディオエンコーダの出力を分析することにより、音声エンベッディングが対応するテキストトークンと正確に一致することを示し、音声情報とテキスト情報の効果的な融合を実証しています。評価には、Multilingual LibriSpeech(MLS)データセットを使用して、この戦略の効果を評価しています。オープンソースのLLaMA-7Bは、コンフォーマーエンコーダ(音声処理に特化した一種のニューラルネットワーク)を組み込んだ大規模言語モデルです。結果は、この調整により、LLMが単一言語のベースラインよりも音声認識タスクで18%優れたパフォーマンスを発揮することが可能になりました。主に英語テキストで訓練されたLLaMA-7Bは、多言語音声認識に優れています。 主な実験に加えて、研究では拡張されたLLMのパフォーマンスの他の側面も調査されています。LLMのパラメータを変更せずにトレーニング中にLLMを凍結できるかどうかを調べるために、抜粋試験が行われました。これにより、LLMが凍結されている間でも依然として優れた多言語ASRを実行できることが示されています。 研究チームはまた、オーディオエンコーダのスケーリングアップ、オーディオエンコーダストライド(オーディオが分割されるパラメータ)、およびより少ない音声エンベッディングの生成の影響についても調査しています。これらのテストを通じて、ASRシステムの効果と効率を向上させることを目指しています。結論として、結果は、LLMsが大きな音声エンコーダや長いストライドでも多言語ASRの実行が可能であることを示しており、LLMsが長い形式の音声入力を処理する能力を持っていることを示唆しています。

メリーランド大学の新しいAI研究は、1日で単一のGPU上で言語モデルのトレーニングをするためのクラミングの課題を調査しています
自然言語処理の多くの領域では、言語解釈や自然言語合成を含む機械学習モデルの大規模トレーニングにおいて、トランスフォーマーのトポロジーを利用した画期的な進展が生まれています。これらのシステムの広く認識されている特性は、モデルのパラメータ数やデータのボリュームが増えるにつれて安定的にスケーリングするか、さらなる性能向上を続ける能力です。 ほとんどの研究は、極端な計算の限界を押し上げる新しい方法を見つけることに焦点を当てていますが、メリーランド大学の研究チームは、言語モデルのトレーニングを縮小する最善の方法とそのトレードオフについて調査しています。 研究者たちは、スケールの力が引き起こした非常に大きなモデルを構築する競争のために、言語モデルのトレーニングが可能であると考えています。初期のBERTモデルは、自然言語処理の多くの実世界アプリケーションで使用されています。ただし、このモデルをトレーニングするには、かなりの計算が必要でした。 比較的限られたリソースで、BERTと同等の性能を持つ言語モデルをトレーニングすることが可能であり、それにはいくつかの興味深い結果があります。その1つは、大規模モデルでは現在難しい追加の学術的な問い合わせを可能にし、スケールダウンしたモデルの事前トレーニングが大規模な計算の事前トレーニングの有望な相互対応関係であるかどうかを明確にすることです。研究者によると、公共のデータでトレーニングされた、出所の疑わしいモデルが受け入れられるかどうかは法的な問題があります。 メリーランド大学の研究者による新しい研究は、「Cramming」というチャレンジに取り組んでいます。つまり、試験の前日に言語モデル全体を学習することです。彼らの研究は、この制約のある状況でも、パフォーマンスが大規模な計算環境で見つかるスケーリングルールに密接に従うことを証明しています。この研究では、トレーニングパイプラインの変更がスケールダウンした状況でのパフォーマンス向上につながるかどうかを調査しています。 スケールダウンは困難です。モデルのサイズを小さくすることで、より高速な勾配計算が可能になりますが、時間の経過に伴うモデルの改善率はほぼ一定です。ただし、スケーリング法則を利用するトレーニングレシピの変更により、モデルのサイズを減少させることなく、勾配計算の効果的な速度を増加させることで、利益を生み出すことができます。最終的に、チームは予算の制約の中でモデルをトレーニングし、尊敬できるパフォーマンスを提供し、GLUEタスクでBERTに頻繁に迫り、時には超えることもありました。 チームは、トランスフォーマーベースの言語モデルが非常に限られた計算環境に収まる状況でのパフォーマンスを評価しています。彼らは、さまざまな変更要素がGLUEでの尊敬できる下流パフォーマンスをもたらすことを発見しました。チームは、この研究が「Cramming」の問題に関する調査の出発点となり、さまざまな改善策や戦略にさらなる洞察をもたらすことを期待しています。

「新たなホワイトハウスの協定に基づき、AIの巨大企業が自社のアルゴリズムに外部からの調査を許可することを誓います」
「GoogleやOpenAIなど、主要なAI開発者たちは、バイアスのある出力などの問題をチェックするとバイデン政権に約束しました」

「ChatGPTのリリースはオープンデータの生産に影響を与えているのか? 研究者が調査し、人気を集めるLLMがStackOverflowのコンテンツの大幅な減少をもたらしていることを検証」
大規模言語モデル(LLM)は、新しいアップデートや新しいリリースごとに人気が高まっています。BERT、GPT、PaLMなどのLLMは、自然言語処理や自然言語理解の分野で非常に優れた能力を発揮しています。OpenAIが開発した有名なチャットボットChatGPTは、GPT 3.5やGPT 4のトランスフォーマーアーキテクチャに基づいており、100万以上のユーザーに使用されています。その人間のような性質から、研究者や開発者、学生など、あらゆる人の注目を浴びています。ChatGPTは、ユニークなコンテンツを効率的に生成し、人間のように質問に答え、長いテキストの段落を要約し、コードサンプルを完了させ、言語を翻訳するなど、さまざまなことができます。 ChatGPTは、さまざまなトピックに関する情報をユーザーに提供することに驚くほど優れていることが証明されており、これによって従来のウェブ検索の代わりや他のユーザーにオンラインでの支援を求めることができる可能性があります。しかし、私たちは制約もあります。ユーザーが大規模な言語モデルと個別に関与し続けると、一般にアクセス可能な人間生成データと知識リソースの量が劇的に減少する可能性があります。このオープンデータの減少は、将来のモデルのためのトレーニングデータの確保が困難になる可能性があります。 この問題についてさらなる研究を行うために、研究チームはStack Overflow上の活動を調査し、ChatGPTのリリースがオープンデータの生成にどのような影響を与えたかを調査しました。Stack Overflowは、コンピュータプログラマー向けのよく知られた質問応答サイトであり、多くの言語モデルが存在する場合のユーザーの行動と貢献を調査するための優れた事例研究として使用されました。チームは、ChatGPTなどのLLMが大きな人気を集めるにつれて、StackOverflowのコンテンツの減少につながっていることを調査しました。 評価の結果、チームはいくつかの興味深い結論を導き出しました。ChatGPTのリリース後、Stack Overflowの活動は、中国やロシアの競合サイト、および数学の類似のフォーラムと比較して大幅に減少しました。チームは、OpenAIのChatGPTのリリース後、Stack Overflowの週間投稿数が16%減少すると予測しました。また、ChatGPTのStack Overflowへの影響は時間とともに増加しました。これは、ユーザーがモデルの機能により慣れてくるにつれて、情報をより頼りにするようになり、サイトへの貢献がさらに制限されることを示唆しています。 チームは以下の3つの重要な結論に絞り込みました。 投稿活動の減少:ChatGPTのリリース後、Stack Overflowの投稿数(質問と回答)が減少しました。差分の差分法を使用して、活動の減少を計算し、他の4つのQ&Aプラットフォームと比較しました。ChatGPTの登場から6ヶ月以内にStack Overflowの投稿活動は元々約16%減少し、その後約25%に増加しました。 投稿の投票に変化なし – ChatGPTのリリース以降、Stack Overflowの投稿が受けた投票(上向きと下向きの両方)の数は、投稿活動の減少にもかかわらず、大きな変化はありませんでした。これは、ChatGPTが低品質の投稿だけでなく、高品質な記事も置き換えていることを示しています。 多様なプログラミング言語への影響:ChatGPTは、Stack Overflowで議論されるさまざまなプログラミング言語に多様な影響を与えました。PythonやJavaScriptなどの一部の言語では、グローバルサイトの平均に比べて投稿活動がより顕著に減少しました。投稿活動の相対的な減少は、GitHub上のプログラミング言語の普及率にも影響を受けました。 著者は、LLMの普及とStack Overflowのようなウェブサイトからの移行が、ユーザーや将来のモデルが学習できるオープンデータの量を制限する可能性があることを説明しています。これには、インターネット上の知識のアクセスと共有、AIエコシステムの長期的な持続可能性に影響があります。

「LLMは誰の意見を反映しているのか? スタンフォード大学のこのAI論文では、言語モデルLMが一般世論調査の観点から反映している意見について検証しています」
過去数年間、言語モデル(LM)は、医療、ソフトウェア開発、金融など、さまざまな産業において、自然言語処理アプリケーションのペースを加速する上で非常に重要な役割を果たしてきました。LMを使用してソフトウェアコードを書く、著者が執筆スタイルやストーリーラインを改善するのを支援するなど、トランスフォーマーベースのモデルの最も成功した人気のあるアプリケーションの1つです。しかし、これだけではありません!研究によると、LMは、主観的な質問をすることで、チャットボットや対話アシスタントのアプリケーションにおいて、オープンエンドの文脈で使用されることがますます増えています。たとえば、AIが将来世界を支配するか、安楽死合法化が良い考えかどうかといった主観的な質問を対話エージェントに尋ねる例があります。このような状況では、主観的な質問に対するLMの意見は、特定の偏見やバイアスに陥るかどうかだけでなく、社会全体の見解を形成する上でも重要な影響を与えることが示されています。 現在、オープンエンドのタスクにおけるLMのパフォーマンスを評価するために、LMがどのように主観的な質問に反応するかを正確に予測することは非常に困難です。その主な理由は、これらのモデルの設計と微調整を担当する人々が異なるバックグラウンドを持ち、異なる視点を持っているからです。また、主観的な質問に関しては、モデルを判断するために使用できる「正しい」回答はありません。その結果、モデルが示すどのような視点も、ユーザーの満足度や彼らが意見を形成する方法に大きな影響を与えることができます。したがって、オープンエンドのタスクにおいてLMを正しく評価するためには、まずLMによって反映されている意見が正確に誰のものであり、それが一般人口の大多数とどのように合致しているかを明確にすることが重要です。この目的のために、スタンフォード大学とコロンビア大学のポストドクター研究者チームは、LMによって生成される意見のスペクトルと、さまざまな人口グループとの一致を研究するための包括的な定量的フレームワークを開発しました。人間の意見を分析するために、チームは専門家によって選ばれた世論調査と、異なる人口グループに属する個人から収集された回答を利用しました。さらに、チームはOpinionQAという新しいデータセットを開発し、中絶や銃暴力などのさまざまな問題において、LMのアイデアが他の人口グループとどれだけ一致しているかを評価しました。 研究者たちは、専門家によって選ばれた公衆意見調査を使用し、オープンエンドの回答に関連する課題とLMのプロンプトへの容易な適応性のために、多肢選択形式の質問形式で設計された質問に頼りました。これらの調査では、アメリカの異なる民主的グループに属する個人の意見を収集し、スタンフォード大学とコロンビア大学の研究者たちがLMの意見に関する評価指標を作成するのに役立ちました。研究者たちの提案したフレームワークの基本的な基盤は、多肢選択の公衆意見調査をデータセットに変換し、LMの意見を評価するためのものです。各調査には、さまざまなトピックに属するいくつかの質問が含まれており、各質問にはさまざまな可能な回答があります。研究の一環として、研究者たちはまず、LMの回答を比較するために、人間の意見の分布を作成する必要がありました。その後、チームはこの手法を用いてPew Researchのアメリカのトレンドパネル調査をOpinionQAデータセットを構築するために活用しました。この調査は、科学、政治、個人関係、医療などのさまざまなトピックをカバーし、アメリカ全土のさまざまな人口グループから収集された1498件の多肢選択質問とその回答で構成されています。 研究者たちは、AI21 LabsとOpenAIの9つのLM(パラメータ範囲:350M〜178B)をOpinionQAデータセットを使用して評価しました。評価では、モデルの意見を米国全体の人口と60の異なる人口グループ(民主党、65歳以上の個人、未亡人などを含む)と比較しました。研究者たちは、調査結果の3つの側面に主に注目しました:代表性、操作性、一貫性。「代表性」とは、デフォルトのLMの信念がアメリカの全人口または特定のセグメントとどれだけ近いかを指します。気候変動などのさまざまなトピックに関して、現代のLMの意見とアメリカの人口グループの意見との間には、大きな乖離があることがわかりました。また、これらのモデルをより人間に合わせるため、人間のフィードバックに基づいて微調整することで、この不一致はさらに増幅されることがわかりました。また、現在のLMは、65歳以上の人や未亡人などの一部のグループの視点を適切に表現していないことがわかりました。操作性(LMが適切にプロンプトされた場合、グループの意見分布に従うかどうか)に関しては、ほとんどのLMが特定の方法で行動するよう促されると、グループとの一致度が高まる傾向があることがわかりました。研究者たちは、さまざまな民主的グループの意見が、さまざまな問題にわたってLMと一貫しているかどうかを判断することに重点を置きました。この点では、一部のLMが特定のグループとよく一致している一方で、分布はすべてのトピックにわたって一致していないことがわかりました。 要するに、スタンフォード大学とコロンビア大学の研究者グループが、公衆意見調査の支援を受けて、LM(言語モデル)に反映される意見を分析するための素晴らしいフレームワークを提案しました。彼らのフレームワークにより、OpinionQAという新しいデータセットが作成されました。このデータセットによって、LMがアメリカの大部分の意見、異なるグループ(65歳以上と未亡人を含む)の意見、および操作性といった複数の面で人間の意見と乖離していることが明らかになりました。研究者たちはまた、OpinionQAデータセットがアメリカに特化しているものの、彼らのフレームワークは一般的な手法を使用しており、他の地域のデータセットにも拡張できると指摘しています。チームは、彼らの研究がLMをオープンエンドのタスクで評価し、バイアスやステレオタイプから自由なLMを作成するためのさらなる研究を推進することを強く望んでいます。OpinionQAデータセットの詳細については、こちらからアクセスできます。

「ChatGPTが連邦取引委員会によって潜在的な被害の調査を受ける」
重要な進展として、連邦取引委員会(FTC)が人工知能(AI)スタートアップ企業であるOpenAIの調査を開始しました。OpenAIはAIパワードのチャットボットChatGPTを開発したことで知られています。この調査は、データ収集の慣行やAIパワードのチャットボットによる虚偽情報の拡散による消費者への損害の疑いに関わります。AIの社会への影響に対する懸念が高まる中、この調査はAI技術に関連するリスクの評価において重要な瞬間となります。 関連記事:OpenAIがラジオホストに対して虚偽の告発を行い、名誉毀損の訴訟を受ける FTCがOpenAIのデータ収集およびセキュリティ慣行を調査 FTCは最近、20ページにわたる詳細な書簡をOpenAIに送り、同社のセキュリティ慣行や個人データの取り扱いについての懸念を示しました。FTCは同社から包括的な情報提供を要求しています。これにはAIモデルのトレーニングプロセスや個人データの収集・処理に関する詳細が含まれます。FTCは、OpenAIが公正または誤解を招く慣行に従事しているかどうか、特にプライバシー、データセキュリティ、および潜在的な消費者への損害に関して評価することを目指しています。 関連記事:OpenAIとMetaが著作権侵害で訴えられる OpenAIがアメリカで規制の脅威に直面 FTCの調査は、OpenAIにとってアメリカでの最初の主要な規制上の課題となります。OpenAIは最も著名なAI企業の一つであり、その苦境はAI技術に対する益々厳しい監視の傾向を示しています。この調査は、AIパワードの製品がより一般的になり、人間の雇用を脅かし、ディスインフォメーションの拡散を助長することに対する懸念を反映しています。 関連記事:アメリカ議会が行動を起こす:二つの新たな法案が人工知能の規制を提案 OpenAIが安全性とコンプライアンスの重要性を認識 調査に対して、OpenAIのCEOであるSam Altmanは、自社の技術の安全性を確保することの重要性を強調しました。Altmanは、法律への順守と調査機関との協力意欲に自信を示しました。OpenAIは、AIに関連する潜在的なリスクに対処するために、透明性の維持と法規制の遵守の重要性を認識しています。 関連記事:“私たちは幻覚の問題を修正します”とSam Altman氏は述べています OpenAIの国際的な規制上の課題 OpenAIはアメリカ以外でも規制当局の監視を受けています。3月には、イタリアのデータ保護当局がChatGPTを禁止し、個人データの違法な収集や未成年者に不適切なコンテンツから保護するための年齢確認システムの不在を理由に挙げました。OpenAIは要求された変更を行った後、システムへのアクセスを復旧させました。これらの国際的な圧力は、AI技術の包括的な監査と責任ある展開の必要性を一層強調しています。 関連記事:OpenAIとDeepMindが英国政府と協力し、AIの安全性と研究を進める FTCの迅速な行動がAI規制の緊急性を示す FTCによるOpenAIへの調査の迅速な開始は、AI規制に対する緊急性を示しています。ChatGPTの導入から1年も経たない内に行われたFTCの迅速な対応は、AI技術の発展初期における評価と監視の必要性を象徴しています。FTCの議長であるLina Khanは、進化するAIのリスクに対して積極的な規制の必要性を常に強調しています。 関連記事:ChatGPTが自らを規制する法律を制定 OpenAIのビルディングメソッドとデータソースの潜在的な開示 調査の一環として、OpenAIはChatGPTの開発方法やAIシステムのトレーニングに使用されたデータソースを開示することが求められる可能性があります。OpenAIは以前にこの情報を共有していましたが、最近の動向によりより慎重な回答が行われるようになりました。これは、競合他社が彼らの研究を複製し、特定のデータセットに関連する潜在的な法的問題にかかわる可能性があるためです。 関連記事:オンライン上のすべての投稿は今やAIの所有物、Googleが発表 アドボカシーグループの懸念が調査を増幅…
「PythonのリストとNumPyの配列:メモリレイアウトとパフォーマンスの利点についての詳細な調査」
「PythonのネイティブリストとNumPy配列のメモリレイアウトの違いを探り、NumPyの連続メモリ割り当てがその大幅なパフォーマンスの利点にどのように寄与するかを学びましょう」

「FTC、ChatGPTが消費者に悪影響を与えるか調査中」
「エージェンシーがOpenAIのAIリスクに関する文書を要求したことは、同社にとって最大の米国の規制上の脅威です」

ウィスコンシン大学の新しい研究では、ランダム初期化から訓練された小さなトランスフォーマーが、次のトークン予測の目標を使用して効率的に算術演算を学ぶことができるかどうかを調査しています
言語やコードの翻訳、構成思考、基本的な算術演算など、さまざまな下流タスクにおいて、GPT-3/4、PaLM、LaMDAなどの大規模言語モデルは、一般的な特徴を示し、時には新たなスキルを獲得します。驚くべきことに、モデルの訓練目標は、次のトークンの予測に基づく自己回帰損失であることが多いですが、これらの目標を直接的にエンコードしていません。これらのスキルは、以前の研究で詳しく探求されており、トレーニングの計算規模、データタイプ、モデルのサイズによってどのように変化するかも調査されています。しかし、データの複雑さと評価されるジョブの範囲を考慮すると、要素を分離することはまだ困難です。彼らはこれらの能力の出現を促す要因に興味を持っていたため、これらの才能の出現を早める主な貢献を特定しました。 これらの要因には、データの形式とサイズ、モデルのサイズ、事前トレーニングの存在、促し方などが含まれます。彼らの研究は制御された環境で行われ、これらのパラメータのより詳細な分析を可能にしています。彼らは、NanoGPTやGPT-2などの小型トランスフォーマーモデルに数学を教えることに重点を置いています。彼らは、10.6百万パラメータのモデルから124百万パラメータのモデルまでスケールを変えながら、一般的な自己回帰の次のトークン予測損失を使用してトレーニングしています。UW Madisonの研究者たちは、これらのモデルが加算、減算、乗算、平方根、正弦などの基本的な数学演算を効果的に学習する方法を理解することを目指しており、新たな才能がどのように引き出されるのかについてより深い洞察を提供します。彼らは以下にその結論を示しています。 サンプルのサイズとデータ形式の両方が重要です。 まず、彼らは「A3A2A1 + B3B1B1 = C3C2C1」といった典型的な加算サンプルを使用してモデルに教えることは理想的ではないと指摘しています。なぜなら、これによりモデルは結果の最も重要な桁C3を最初に評価する必要があり、それは2つの被加数のすべての桁に依存しているからです。彼らは、「A3A2A1 + B3B1B1 = C1C2C3」といった逆の結果を持つサンプルでモデルを訓練することで、モデルがより単純な関数を学習できるようにしています。さらに、桁とキャリーに依存する「変種」の多くのサンプルをバランスよく取り入れることで学習をさらに向上させています。彼らは、この簡単なシナリオでもトレーニングデータの量に応じて0%から100%の精度の急激な位相変化が見られることに驚いています。予期せぬことに、低ランク行列の補完は、ランダムなサンプルからn桁の加算マップを学習することと類似しています。この関連性により、この位相変化の論理的な正当化を提供することができます。 トレーニング中の認知フローのデータ。 これらの結果に基づいて、彼らはトレーニング中にチェーンオブ思考データの利点を調査しました。この形式では、ステップバイステップの操作と中間出力が含まれているため、モデルは困難なタスクの異なる要素を学習することができます。彼らはこれを関連する文献から直接取り入れています。CoTのファインチューニングの文献によると、CoTタイプのトレーニングデータは、言語の事前トレーニングがなくても、サンプルの複雑性と精度の面で学習を大幅に向上させることがわかりました。彼らは、モデルが必要な構成関数を個々のコンポーネントに分解することで、より高次元で単純な関数マップを学習できるため、これが理由であると仮説を立てています。彼らは、彼らの研究で調査した4つのデータフォーマット技術のサンプルを図1に示しています。 テキストと数学の組み合わせでのトレーニング。 LLMはインターネットからダウンロードされた膨大なデータでトレーニングされるため、さまざまな形式のデータをきれいに分離するのは難しいです。そのため、彼らはトレーニング中にテキストと数値データがどのように相互作用するかを調査しています。テキストと算術入力の比率がモデルの困惑度と精度にどのように影響するかを追跡しています。彼らは、以前にカバーされた算術演算を知ることが各タスクのパフォーマンスを個別に向上させること、そしてゼロショットからワンショットのプロンプティングに切り替えることで精度が大幅に向上することを発見しました。ただし、さらに多くの例が提供されると、精度はそれほど顕著ではありません。モデルのサイズと事前トレーニングの重要性。 事前トレーニングとモデルのスケールの役割。 さらに、彼らはGPT-2やGPT-3などのモデルを事前トレーニングしてファインチューニングすることで事前トレーニングの機能を調査し、算術演算におけるゼロショットのパフォーマンスは劣るものの、事前トレーニング中に開発された「スキル」により、限られた数のファインチューニングサンプルでもいくつかの基本的な算術タスクで受け入れ可能なパフォーマンスが実現できることを発見しました。しかし、モデルが標準形式の操作で事前トレーニングされている場合、逆の形式などの非標準の書式でのファインチューニングはモデルのパフォーマンスに干渉し、精度を低下させることができます。最後に、彼らはスケールが算術パフォーマンスにどのように影響するかを研究し、スケールが算術演算の学習に助けになるが、必須ではないことを発見しました。 長さと構成の一般化。 自分たちの訓練済みモデルが数学をしっかり理解しているのか疑問に思うかもしれません。彼らの研究は複雑な回答を提供します。彼らは、訓練データの数字の桁数以外の長さを一般化することが難しいことを見つけました。例えば、ある特定の長さを除外して全てのn桁の長さで訓練されたモデルは、この欠けている桁数を適切に調整して正しく計算するのが困難です。その結果、モデルは訓練された数字の桁数範囲内では良いパフォーマンスを発揮しますが、それ以外ではずっと悪くなります。これは、モデルが算術を教えられた桁数に制限されたマッピング関数として学習していることを示しています。これは単なる暗記ではなく、数学の徹底的な「理解」には及ばないものです。 新規性と以前の取り組みとの比較。 彼らは、彼らの手法が利用する訓練データの種類に関してはオリジナルではないと主張していますが、むしろモデルのパフォーマンスを向上させるために指導的なデータを利用した先行研究に強く依存していると述べています。ランダムに初期化されたモデルと、さまざまなサンプリング/データ形式およびモデルのスケール設定についての詳細な削除研究に重点を置き、算術能力の急速な形成につながる要因を分離することが彼らの研究を他の研究と区別しています。さらに、彼らが検出したいくつかの現象は、研究の中でいくつかの直接的で可能性のある啓示的な理論的説明を持っています。 図1:この研究で検討された4つのデータ整形技術が示されています。…
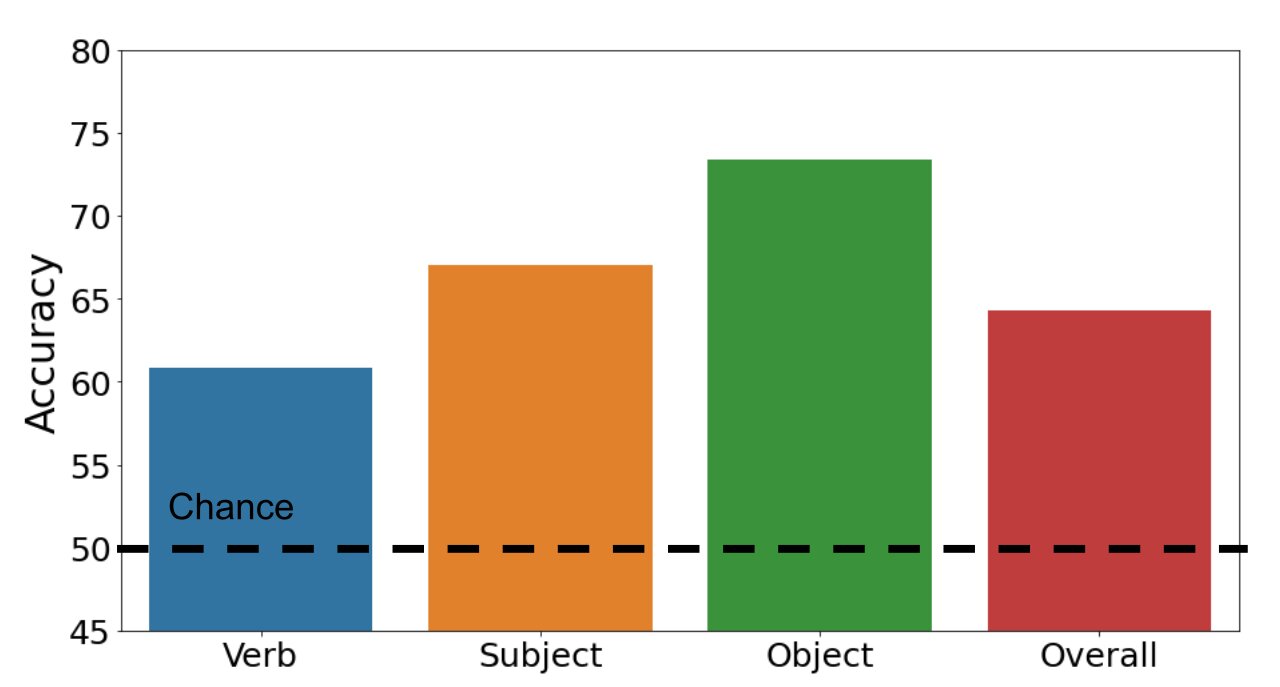
動詞理解のための画像言語トランスフォーマーの調査
マルチモーダル画像言語トランスフォーマーは、微調整に依存するさまざまなタスク(例:視覚的な質問応答や画像検索)で印象的な結果を達成しています私たちは、事前学習された表現の品質について明らかにし、特にこれらのモデルが動詞を区別できるのか、与えられた文において名詞のみを使用するのかどうかに興味がありますそのために、視覚的なものまたは事前学習データ(つまり、Conceptual Captionsデータセット)で一般的に見つかる447の動詞からなる画像-文のペアのデータセットを収集しますこのデータセットを使用して、事前学習モデルをゼロショットで評価します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.