Learn more about Search Results 写真 - Page 3

- You may be interested
- 「パンダとPythonでデータの整理をマスタ...
- Hugging FaceとAMDは、CPUおよびGPUプラッ...
- 生成AI:シームレスなデータ転送のための...
- 「2/10から8/10までの週のトップの重要な...
- MITの研究者たちは、スケーラブルな自己学...
- People Analyticsは新しい大きなトレンド...
- StableSRをご紹介します:事前トレーニン...
- 「データセンターは冷房を少なくしても同...
- 「データプライバシーを見る新しい方法」
- 「PythonとMatplotlibを使用して米国のデ...
- 「Pythonドキュメントの向上:ソースコー...
- データから洞察へ:データ分析のための生...
- 「時系列の外れ値を解読する:1/4」
- 「おそらく知らなかった4つのPython Itert...
- 「MLOpsを活用した顧客離反予測プロジェク...

「50 ミッドジャーニーノーリングのヒント(フラットレイ写真)」
「Midjourneyを使用してノーリング(フラットレイ)の写真を作成できることを知っていましたか?ここには始めるための50のプロンプトがあります」

「ODSC Europe 2023の写真とハイライト」
ODSC Europe 2023から数週間が経ちましたが、最高のノートで去ることができました週はデータサイエンスのトップトピック、AIのイノベーションに関する魅力的なセッションで満ち、しばらく会っていなかった笑顔の顔もありました以下はODSCのハイライトです...
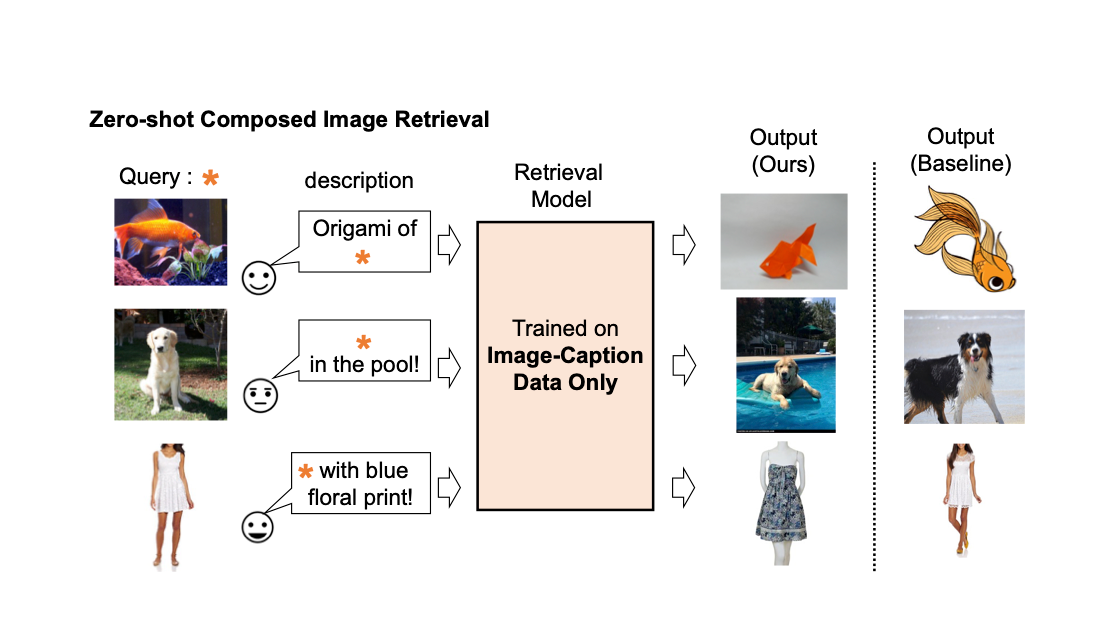
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検索エンジンでは、画像またはテキストをクエリとして使用して目的の画像を取得することが重要です。しかし、テキストに基づいた検索には限界があります。言葉で正確に目的の画像を説明することは難しいからです。たとえば、ファッションアイテムを検索する場合、ユーザーはウェブサイトで見つけたものとは異なる、ロゴの色やロゴ自体などの特定の属性を持つアイテムを求めるかもしれません。しかし、既存の検索エンジンでそのアイテムを検索することは容易ではありません。なぜなら、テキストでファッションアイテムを正確に説明することは難しいからです。この事実に対処するために、組み合わせ画像検索(CIR)は、画像とテキストの両方を組み合わせたクエリに基づいて画像を取得します。そのため、CIRは画像とテキストを組み合わせることで、目的の画像を正確に取得することができます。 しかし、CIRの方法には大量のラベル付きデータが必要です。つまり、1)クエリ画像、2)説明、および3)目標画像の3つ組を必要とします。このようなラベル付きデータを収集することはコストがかかり、このデータで訓練されたモデルはしばしば特定のユースケースに適応されており、異なるデータセットには一般化できる能力が制限されています。 これらの課題に対処するために、「Pic2Word:ゼロショット組み合わせ画像検索のための画像から単語へのマッピング」というタイトルの論文で、私たちはゼロショットCIR(ZS-CIR)というタスクを提案しています。ZS-CIRでは、ラベル付きの3つ組データを必要とせずに、オブジェクトの組み合わせ、属性の編集、またはドメインの変換など、さまざまなCIRのタスクを実行する単一のCIRモデルを構築することを目指しています。代わりに、大規模な画像キャプションのペアとラベルのない画像を使用して検索モデルを訓練することを提案しています。これらのデータは、大規模な教師ありCIRデータセットよりも容易に収集できます。再現性を促進し、この分野をさらに進展させるために、私たちはコードも公開しています。 既存の組み合わせ画像検索モデルの説明。 私たちは、画像キャプションのデータのみを使用して組み合わせ画像検索モデルを訓練します。私たちのモデルは、クエリ画像とテキストの組み合わせに合わせた画像を取得します。 手法の概要 私たちは、コントラスト言語-画像事前学習モデル(CLIP)の言語エンコーダの言語能力を活用することを提案しています。CLIPは、さまざまなテキストの概念と属性に対して意味のある言語埋め込みを生成することに優れています。そのため、CLIP内の軽量なマッピングサブモジュールを使用して、画像の埋め込み空間からテキスト入力空間の単語トークンにマッピングすることを目指します。全体のネットワークは、ビジョン-言語コントラスト損失を最適化して、画像とテキストの埋め込み空間が可能な限り近接するようにします。そして、クエリ画像を単語のように扱うことができます。これにより、言語エンコーダによるクエリ画像の特徴とテキストの説明の柔軟でシームレスな組み合わせが可能になります。私たちはこの手法をPic2Wordと呼び、その訓練プロセスの概要を以下の図で提供します。マップされたトークンsは、単語トークン形式で入力画像を表すようにしたいと考えています。その後、マッピングネットワークを訓練して、言語埋め込みp内で画像埋め込みを再構築します。具体的には、CLIPで提案されたコントラスト損失を最適化し、ビジュアル埋め込みvとテキスト埋め込みpの間のコントラスト損失を計算します。 未ラベルの画像のみを使用してマッピングネットワーク(fM)のトレーニングを行います。視覚とテキストのエンコーダーは固定されたまま、マッピングネットワークのみを最適化します。 トレーニングされたマッピングネットワークを考慮すると、以下の図に示すように、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成することができます。 トレーニングされたマッピングネットワークを使用して、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成します。 評価 さまざまな実験を行って、Pic2WordのCIRタスクでの性能を評価します。 ドメイン変換 まず、提案手法の合成能力をドメイン変換で評価します。画像と変換先の画像ドメイン(例:彫刻、折り紙、漫画、おもちゃ)を与えられた場合、システムの出力は同じ内容の画像を新しい望ましい画像ドメインまたはスタイルで出力する必要があります。以下の図で示されるように、画像とテキストのカテゴリ情報やドメイン説明を柔軟に組み合わせる能力を評価します。ImageNetとImageNet-Rを使用して、実際の画像から4つのドメインへの変換を評価します。 教師付きトレーニングデータを必要としないアプローチとの比較のために、次の3つのアプローチを選びます:(i)画像のみは視覚埋め込みのみで検索を実行します、(ii)テキストのみはテキスト埋め込みのみを使用します、(iii)画像+テキストは視覚とテキストの埋め込みを平均化してクエリを構成します。 (iii)との比較では、言語エンコーダーを使用して画像とテキストを組み合わせる重要性が示されます。また、Fashion-IQまたはCIRRでCIRモデルをトレーニングするCombinerとも比較します。 入力クエリ画像のドメインを、テキストで指定されたドメイン(例:折り紙)に変換することを目指します。 下の図に示されているように、提案された手法はベースラインを大きく上回る結果を示しています。 ドメイン変換のための合成画像検索における結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)。…

ビンガムトン大学の研究者たちは、社会的な写真共有ネットワークでの自分たちの顔の管理を可能にするプライバシー向上の匿名化システム(私の顔、私の選択)を紹介しました
匿名化は、顔認識や識別アルゴリズムの文脈において重要な問題です。これらの技術の商品化が進むにつれて、個人のプライバシーやセキュリティに関する倫理的な懸念が浮上しています。顔の特徴を通じて個人を認識し識別する能力は、同意、個人データの管理、潜在的な悪用について疑問を投げかけます。現在のソーシャルネットワークのタグ付けシステムは、写真に望ましくないまたは承認されていない顔が表示されるという問題に適切に対処する必要があります。 論争や倫理的な懸念が顔認識や識別アルゴリズムの最先端技術に影響を与えてきました。以前のシステムは適切な一般化と正確性の保証が欠けており、意図しない結果をもたらしました。顔認識をオフにするために、ぼかしやマスキングといった対策が取られていますが、これらは画像の内容を変えてしまい、簡単に検出されます。敵対的生成や没収の手法も開発されましたが、顔認識アルゴリズムはこのような攻撃に耐えるために改良されています。 このような状況の中、Binghamton Universityの研究チームが最近発表した新しい記事では、顔認識システムを誤認させるためにディープフェイクを活用するプライバシー強化システムを提案しています。彼らは「私の顔、私の選択」(MFMC)という概念を導入し、個人が自分が写真に表示されるのを制御し、非許可の閲覧者に対しては似たようなディープフェイクで自分の顔を置き換えることができるようにしています。 提案されたMFMCメソッドは、写真内の複数の人物を対象として、個人が付与した複雑なアクセス権に基づいてディープフェイクのバージョンを作成することを目指しています。このシステムは、アクセス権を画像ごとではなく顔ごとに定義するソーシャル写真共有ネットワーク上で動作します。画像がアップロードされると、アップローダーの友人はタグ付けできますが、残りの顔はディープフェイクで置き換えられます。これらのディープフェイクは、様々なメトリックに基づいて慎重に選択され、元の顔とは数量的に異なるが、文脈的および視覚的な連続性を維持します。著者たちは、さまざまなデータセット、ディープフェイク生成器、顔認識アプローチを用いて、提案されたシステムの有効性と品質を確認するために、包括的な評価を行っています。MFMCは、顔の埋め込みを利用して顔認識アルゴリズムに対する有用なディープフェイクを作成するための重要な進歩を表しています。 この記事では、合成ターゲット顔のアイデンティティを元のソース顔に移すと同時に、顔や環境の属性を保持することができるディープフェイク生成器の要件を示しています。著者たちは、Nirkin et al.、FTGAN、FSGAN、SimSwapなどの複数のディープフェイク生成器をフレームワークに統合しています。また、プロキシによる開示、明示的な認可による開示、アクセスルールに基づく開示などの3つのアクセスモデルを導入し、ソーシャルメディアの参加と個人のプライバシーをバランスさせています。 MFMCシステムの評価では、7つの最先端の顔認識システムを使用して顔認識の精度の低下を評価し、CIAGANやDeep Privacyなどの既存のプライバシー保護顔変更手法と比較しています。評価は、MFMCの顔認識の精度低下における効果を示しています。また、システムの設計、製品化、顔認識システムとの評価における他の手法に対する優位性を強調しています。 まとめると、この記事では顔認識や識別アルゴリズムに関連するプライバシーの懸念に対処するための新しいアプローチとしてMFMCシステムを紹介しています。個人が付与したアクセス権とディープフェイクを活用することにより、MFMCはユーザーが自身が写真に表示されることを制御し、非許可の閲覧者に対しては似たようなディープフェイクで顔を置き換えることができます。MFMCの評価は、既存のプライバシー保護顔変更手法を上回り、顔認識の精度の低下においてその有効性を示しています。この研究は、顔認識技術の時代におけるプライバシーの向上に向けた重要な一歩であり、この分野でのさらなる進歩の可能性を開拓しています。

LinkedInとUCバークレーの研究者らは、AIによって生成されたプロフィール写真を検出する新しい方法を提案しています
人工知能(AI)による合成やテキストから画像生成されたメディアの普及とともに、偽プロフィールの洗練度が高まっています。LinkedInはUC Berkeleyと提携して、最先端の検出方法を研究しています。彼らの最近の検出方法は、人工的に生成されたプロフィール写真を99.6%の確率で正確に識別し、本物の写真を偽物として誤認識する割合はわずか1%です。 この問題を調査するには2種類の法科学的方法が使用できます。 仮説に基づく方法は、合成的に作られた顔の異常を見つけることができます。この方法は、明白な意味の外れ者を学習することで利益を得ます。しかし、学習可能な合成エンジンは既にこれらの機能を持っているようです。 機械学習などのデータ駆動型の方法は、自然な顔とCGIの顔を区別することができます。訓練システムに専門外の画像が提示されると、分類に苦労することはよくあります。 提案された手法は、まずコンピュータ生成の顔に固有の幾何学的属性を特定し、それを測定および検出するためにデータ駆動型の方法を使用するハイブリッドアプローチを採用しています。この方法は、軽量で素早く訓練可能な分類器を使用し、小さな合成顔のセットで訓練が必要です。5つの異なる合成エンジンを使用して、41,500の合成顔を作成し、追加のデータとして100,000のLinkedInプロフィール画像を使用しています。 公開されている実際のLinkedInプロフィール写真が合成生成された(StyleGAN2)顔とどのように比較されるかを見るために、彼らはそれぞれ平均400枚を並べて比較しました。人々の実際の写真は非常に異なっているため、ほとんどのプロフィール写真は一般的なヘッドショットにすぎません。一方、一般的なStyleGAN顔は非常に明確な特徴と鋭い目を持っています。これは、StyleGAN顔の眼底位置と眼間距離が標準化されているためです。実際のプロフィール写真は通常、上半身や肩に焦点を当てていますが、StyleGAN顔は首から上に合成される傾向があります。彼らは社会グループ内外の類似点と相違点を利用することを望んでいました。 FaceForensics++データセット内のディープフェイク顔交換を識別するために、研究者は1クラス変分オートエンコーダ(VAE)と基準1クラスオートエンコーダを組み合わせました。フェイススワップのディープフェイクに焦点を当てた過去の研究とは異なり、この研究では合成顔(例:StyleGAN)に重点が置かれています。研究者たちは、比較的少数の合成画像に対して非常に単純で訓練しやすい分類器も使用し、全体的な分類性能を同等に達成しています。 Generated.photosとStable Diffusionで生成された画像を使用して、モデルの汎化能力を評価します。生成的対抗ネットワーク(GAN)を使用して生成されたGenerated.photos顔は、比較的一般的な使用が可能であり、安定した拡散顔はそうではありません。 TPRは「真陽性率」を表し、偽の画像が正しく識別された割合を測定します。FPRを計算するには、偽のラベル付けがされた本物の画像の数を取ります。この研究の結果、提案された方法は、本物のLinkedInプロフィール写真のわずか1%(FPR)を偽物として正確に識別し、合成されたStyleGAN、StyleGAN2、およびStyleGAN3顔を99.6%(TPR)正しく識別します。 研究チームによると、この方法は切り抜き攻撃によって簡単に破られる可能性があり、これは大きな欠点です。StyleGANで生成された画像は既に顔の周りが切り取られているため、この攻撃によって異常なプロフィール写真が生成される可能性があります。彼らは高度な技術を使用し、スケールとトランスレーション不変表現を学習できるかもしれないと計画しています。

写真を撮るだけで、財産の査定を簡単にする
MIT卒業生によって設立されたHosta a.i.の技術は、写真から詳細な物件評価を作成します

Google フォトのマジックエディター:写真を再構築するための新しいAI編集機能
Magic Editorは、AIを使用して写真を再構想するのを手助けする実験的な編集体験です今年後半には、選択されたPixel電話での早期アクセスが計画されています

無料のAI製品写真ツール
全てのビジネスオーナーの皆様へ:高額な商品写真家に二度とお金を払う必要はありません!

「偉大なる遺伝子データの漏洩:知っておくべきこと」
A class action lawsuit has been launched against a genetic testing company for the protection of personal genetic data that was unfortunately stolen.

安定した拡散:インテリアデザインの芸術をマスターする
この速い世界で、パンデミックの後、私たちの多くは、現実から逃れるための心地よい環境を持つことがどれだけ貴重で、追求すべき目標であるかを実感しましたそれが家であろうと、外であろうと、私たちの日常生活において居心地の良い場所を作り出すことは、心の安息であり、幸福感を与えてくれるのです
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.