Learn more about Search Results インテル - Page 3

- You may be interested
- Google Researchが、凍結された大規模言語...
- 完全に説明されたAdaBoostアンサンブルテ...
- データサイエンスのスキルセットを拡大す...
- 「プログラマーのための10の数学の概念」
- クッキージャーで手を捕まれた:GPT4が私...
- 「リモートワーク技術の探究:トレンドと...
- 「エッセンシャルAI、シリーズAラウンドで...
- 「KOSMOS-2:Microsoftによるマルチモーダ...
- AIはモバイルネットワークをより効率的にする
- スターリング-7B AIフィードバックからの...
- 「AIプロジェクトに適したGPU戦略の選択」
- 「DCGANモデルの作成手順ガイド」
- 「このチューリング賞受賞者が伝説的な学...
- DALLE-3の5つの使用例
- Google DeepMindの研究者がDiLoCoを導入:...

「他のAIを教えるAI」
科学者は、ロボットが知識を共有することで他のロボットを訓練することができることを実証しました

「チップの戦いに勝ちたいですか?たくさんの水が必要です」
「アメリカは、半導体製造を促進するために数十億ドルを費やしています新しい工場がシリコンチップを生産するためには、数百万ガロンの超純水が必要です」

AIとディープラーニングに最適なGPU
AIとディープラーニングに深入りする際には、AIリグに適したGPUを選ぶことが重要です適切なGPUを選ぶことで、高度なタスクに対処する柔軟性が得られます

「人工知能(AI)企業に投資するトップのベンチャーキャピタル(VC)企業」
AI(人工知能)企業に投資しているベンチャーキャピタリストを見てみましょう。 かつてロボットのアイデアは少し不安定でしたが、現在は機械が自己学習し成長するためのアーキテクチャとシステムに多額の投資が行われています。これには人間の支援なしで学習と成長が可能なものも含まれます。 PwCの2018 Moneytree Reportによると、2017年にAI企業に93億ドルが投資されました。この巨額の数値は、テクノロジーへの関心の高まりや、公共・商業セクターの寄付者の間でのポテンシャルに対する理解の高まりを示しています。 人工知能は自動運転車のAIオペレーティングシステムから自己学習型の言語処理プラットフォームまで、あらゆるビジネス領域を横断しています。ベンチャーキャピタル企業はこれらのイニシアチブの背後にいる人々に資金を提供しており、これらのイニシアチブが多くの産業に変革をもたらす可能性があるため、競争力を保っています。 AI技術に投資している最も有名なベンチャーキャピタル企業は以下のとおりです。それぞれの目標についても概説しています。 ソフトバンクグループ ソフトバンクグループは、日本を拠点とするグローバルな持株会社です。同国で最も裕福な男性である孫正義氏がAI研究に97%の「時間と知識」を費やしていると主張し、その責任を担っています。同社は最大のグローバルファンドであり、技術の進歩のために特にAIに重点を置いた930億ドルのソフトバンクビジョンファンドを持っています。そのうち28億ドルが新しい投資ファンドに割り当てられており、機械学習、顔認識、拡張現実、Petuum Inc.などに特化した企業であるSenseTimeに以前に投資しています。 ジェネラルキャタリスト 2000年に設立されたジェネラルキャタリストは、アメリカのベンチャーキャピタル企業であり、成長段階や初期段階の株式投資を通じて企業の変革を支援しています。同社は企業の勢いを増し、成長を促進することに重点を置いています。彼らはすでに技術分野で自己を確立した成功したビジネスパーソンに投資しています。その中にはAIを活用したライティング支援のGrammarly、AIを活用した人事管理プラットフォームのEightfold.ai、現実世界の活動を刺激するAPIを作成するプログラムの6D.aiなどがあります。 Institutional Venture Partners アメリカに本拠を置く私募エクイティファームであるIVPは、企業の成長の最終段階においてしばしば資金を提供しています。IVPは、Slack、Github、Pindrop、Soundcloud、Indiegogoなどの有名な企業に投資した後、AIスタートアップへの重要な投資家となりました。2017年には投資ファンドにさらに15億ドルを追加し、総額7億ドルの投資資本を確保しました。特に、IVPは機械データ分析企業であるSumo Logicと、2018年のトップ5の資金調達を行ったAIベンチャーの1つであるZiprecruiterに投資しています。 Two Sigma Ventures 業界トップの企業であるTwo Sigma Investmentsには、Two Sigma…
CPU上でBERT推論をスケーリングアップする(パート1)
.centered { display: block; margin: 0 auto; } figure { text-align: center; display: table; max-width: 85%; /* デモです; 必要に応じていくつかの量 (px や %) を設定してください */…

スケールにおけるトランスフォーマーの最適化ツールキット、Optimumをご紹介します
この投稿は、Hugging Faceが最先端の機械学習プロダクションパフォーマンスを民主化するための旅の第一歩です。目指すところに到達するために、私たちはハードウェアパートナーと手を組んで取り組む予定です。以下のIntelと協力しています。この旅に参加して、新しいオープンソースライブラリであるOptimumをフォローしてください! なぜ 🤗 Optimum なのか? 🤯 Transformersのスケーリングは難しい Tesla、Google、Microsoft、Facebook、これらの企業に共通するものは何でしょうか?もちろんいくつかありますが、その1つは毎日数十億のTransformerモデルの予測を実行していることです。TeslaのAutoPilotのためのTransformer、Gmailの文章補完のためのTransformer、Facebookの投稿のリアルタイム翻訳のためのTransformer、Bingの自然言語クエリに対する回答のためのTransformerなど、さまざまな用途で使用されています。 Transformerは機械学習モデルの精度を飛躍的に向上させ、NLPを征服し、SpeechやVisionなどの他のモダリティにも広がっています。しかし、これらの巨大なモデルを本番環境に持ち込み、スケールで高速に実行することは、どの機械学習エンジニアリングチームにとっても大きな課題です。 上記の企業のように、数百人の高度に熟練した機械学習エンジニアを雇っていない場合はどうでしょうか?私たちの新しいオープンソースライブラリであるOptimumを通じて、Transformerのプロダクションパフォーマンスのための究極のツールキットを構築し、特定のハードウェア上でモデルをトレーニングおよび実行するための最大の効率性を実現することを目指しています。 🏭 OptimumがTransformerを活用します 最適なパフォーマンスでモデルをトレーニングおよび提供するためには、モデルのアクセラレーション技術は対象のハードウェアと互換性が必要です。各ハードウェアプラットフォームは、パフォーマンスに大きな影響を与える特定のソフトウェアツール、機能、ノブを提供しています。同様に、スパース化や量子化などの高度なモデルアクセラレーション技術を活用するためには、最適化されたカーネルがシリコン上の演算子と互換性があり、モデルアーキテクチャから派生したニューラルネットワークグラフに特化している必要があります。この3次元の互換性行列やモデルアクセラレーションライブラリの使用方法について詳しく調査するのは、ほとんどの機械学習エンジニアにとって困難な作業です。 Optimumはこの作業を簡単にすることを目指し、効率的なAIハードウェアを対象としたパフォーマンス最適化ツールを提供し、ハードウェアパートナーとの共同開発で機械学習エンジニアをML最適化の魔術師に変えます。 Transformerライブラリでは、最先端のモデルを研究者やエンジニアが簡単に使用できるようにし、フレームワーク、アーキテクチャ、パイプラインの複雑さを抽象化しました。 Optimumライブラリでは、エンジニアが利用可能なすべてのハードウェア機能を活用し、ハードウェアプラットフォーム上でのモデルアクセラレーションの複雑さを抽象化することで、エンジニアに簡単になります。 🤗 Optimumの実践:Intel Xeon CPU向けのモデルの量子化方法 🤔 量子化の重要性と正しい方法 BERTなどの事前学習済み言語モデルは、さまざまな自然言語処理タスクで最先端の結果を達成しており、ViTやSpeech2Textなどの他のTransformerベースのモデルも、コンピュータビジョンや音声タスクで最先端の結果を達成しています。Transformerは機械学習の世界で広く使われており、今後も使われ続けます。…
モダンなCPU上でのBERTライクモデルの推論のスケーリングアップ – パート2
イントロダクション:CPU上でのAI効率を最適化するためのIntelソフトウェアの使用 前のブログ記事で詳細に説明したように、Intel Xeon CPUは、AVX512やVNNI(Vector Neural Network Instructions)などのAIワークロードに特に設計された機能を提供しており、整数量子化されたニューラルネットワークを使用した効率的な推論をサポートするための追加のシステムツールも提供しています。このブログ記事では、ソフトウェアの最適化に焦点を当て、Intelの新しいIce Lake世代のXeon CPUのパフォーマンスについて紹介します。私たちの目標は、Intelのハードウェアを最大限に活用するためにソフトウェア側で利用可能なものをすべて紹介することです。前のブログ記事と同様に、ベンチマークの結果とグラフとともに、これらのツールと機能を簡単に使用できるようにします。 4月にIntelは最新のIntel Xeonプロセッサ、コードネームIce Lakeを発売しました。これはより効率的で高性能なAIワークロードをターゲットにしています。具体的には、Ice Lake Xeon CPUは、以前のCascade Lake Xeonプロセッサと比較して、さまざまなNLPタスクで最大75%高速な推論が可能です。これは、新しいSunny Coveアーキテクチャ上での新しい命令やPCIe 4.0のようなハードウェアおよびソフトウェアの改善の組み合わせによって実現されています。最後になりますが、Intelは、IntelのExtension for Scikit Learn、Intel TensorFlow、Intel PyTorch…

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…

🤗 Optimum IntelとOpenVINOでモデルを高速化しましょう
昨年7月、インテルとHugging Faceは、Transformerモデルのための最新かつシンプルなハードウェアアクセラレーションツールの開発で協力することを発表しました。本日、私たちはOptimum IntelにIntel OpenVINOを追加したことをお知らせできて非常に嬉しく思います。これにより、Hugging FaceハブまたはローカルにホストされるTransformerモデルを使用して、様々なIntelプロセッサ上でOpenVINOランタイムによる推論を簡単に実行できます(サポートされているデバイスの完全なリストを参照)。OpenVINOニューラルネットワーク圧縮フレームワーク(NNCF)を使用してモデルを量子化し、サイズと予測レイテンシをわずか数分で削減することもできます。 この最初のリリースはOpenVINO 2022.2をベースにしており、私たちのOVModelsを使用して、多くのPyTorchモデルに対する推論を実現しています。事後トレーニング静的量子化と量子化感知トレーニングは、多くのエンコーダモデル(BERT、DistilBERTなど)に適用することができます。今後のOpenVINOリリースでさらに多くのエンコーダモデルがサポートされる予定です。現在、エンコーダデコーダモデルの量子化は有効化されていませんが、次のOpenVINOリリースの統合により、この制限は解除されるはずです。 では、数分で始める方法をご紹介します! Optimum IntelとOpenVINOを使用してVision Transformerを量子化する この例では、食品101データセットでイメージ分類のためにファインチューニングされたVision Transformer(ViT)モデルに対して事後トレーニング静的量子化を実行します。 量子化は、モデルパラメータのビット幅を減らすことによってメモリと計算要件を低下させるプロセスです。ビット数を減らすことで、推論時に必要なメモリが少なくなり、行列乗算などの演算が整数演算によって高速に実行できるようになります。 まず、仮想環境を作成し、すべての依存関係をインストールしましょう。 virtualenv openvino source openvino/bin/activate pip install pip --upgrade pip…
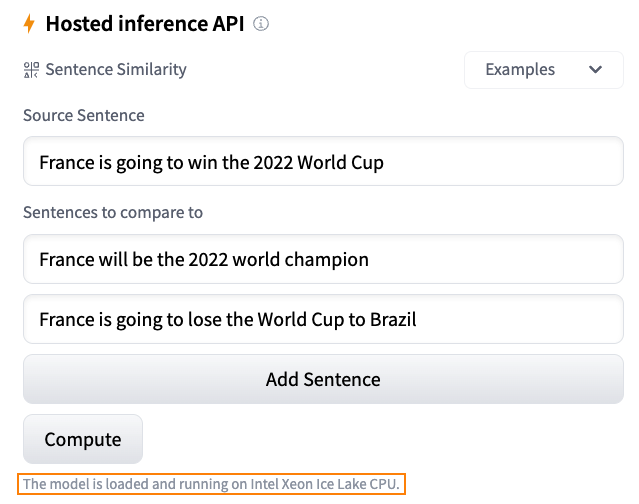
Hugging Faceにおける推論ソリューションの概要
毎日、開発者や組織はHugging Faceでホストされたモデルを採用し、アイデアを概念実証デモに、デモを本格的なアプリケーションに変えています。例えば、Transformerモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習(ML)アプリケーションの人気のあるアーキテクチャとなりました。最近では、ディフューザーがテキストから画像または画像から画像を生成するための人気のあるアーキテクチャとなりました。他のアーキテクチャも他のタスクで人気があり、私たちはそれらをすべてHF Hubでホストしています! Hugging Faceでは、最新のモデルを最小限の摩擦でテストおよび展開できる能力は、MLプロジェクトのライフサイクル全体で重要です。コストとパフォーマンスの比率を最適化することも同様に重要であり、無料のCPUベースの推論ソリューションを提供していただいたインテルの友人に感謝申し上げます。これは私たちのパートナーシップにおけるさらなる大きな一歩です。また、Intel Xeon Ice Lakeアーキテクチャによる高速化を無料でお楽しみいただけるため、ユーザーコミュニティの皆様にとっても素晴らしいニュースです。 さあ、Hugging Faceでの推論オプションを見てみましょう。 無料推論ウィジェット Hugging Faceハブでの私のお気に入りの機能の1つは、推論ウィジェットです。モデルページにある推論ウィジェットを使用すると、サンプルデータをアップロードして1クリックで予測することができます。 以下は、sentence-transformers/all-MiniLM-L6-v2モデルを使用した文の類似性の例です: モデルの動作、出力、およびデータセットのいくつかのサンプルでのパフォーマンスを素早く把握する最良の方法です。モデルはサーバー上でオンデマンドでロードされ、必要なくなるとアンロードされます。コードを書く必要はありませんし、この機能は無料です。どこが好きではないですか? 無料推論API 推論APIは、推論ウィジェットの内部で動作しています。単純なHTTPリクエストで、ハブの任意のモデルをロードし、数秒でデータを予測することができます。モデルのURLと有効なハブトークンが必要です。 以下は、xlm-roberta-baseモデルを1行でロードして予測する方法です: curl https://api-inference.huggingface.co/models/xlm-roberta-base \ -X POST \…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.