Learn more about Search Results CPU - Page 39

- You may be interested
- マシンラーニングのロードマップ:コミュ...
- スタンフォード大学とFAIR Metaの研究者が...
- 「EU AI法案:AIの未来における有望な一歩...
- オープンAIのイリヤ・サツキバーは、超知...
- 化学プロセス開発のためのモデルフリー強...
- 「感覚AIの公開:人工汎用知能(AGI)の実...
- 「3Dシーン表現の境界を破る:新しいAIテ...
- あなたのモデルは良いですか?Amazon Sage...
- 「テキスト分類タスクについての迅速なエ...
- 「グラフ理論における重要な概念、グラフ...
- 「非常にシンプルな数学が大規模言語モデ...
- 検索増強視覚言語事前学習
- 「量子もつれ測定の革命:限られたデータ...
- 「データサイエンスを学ぶのにどれくらい...
- 「大数の法則の解明」

マルチリンガルASRのためのWhisperの調整を行います with 🤗 Transformers
このブログでは、ハギングフェイス🤗トランスフォーマーを使用して、Whisperを任意の多言語ASRデータセットに対して細かく調整する手順を段階的に説明します。このブログでは、Whisperモデル、Common Voiceデータセット、および細かな調整の背後にある理論について詳しく説明し、データの準備と細かい調整の手順を実行するためのコードセルと共に提供しています。説明は少ないですが、すべてのコードがあるより簡略化されたバージョンのノートブックは、関連するGoogle Colabを参照してください。 目次 はじめに Google ColabでのWhisperの細かい調整 環境の準備 データセットの読み込み 特徴抽出器、トークナイザー、およびデータの準備 トレーニングと評価 デモの作成 締めくくり はじめに Whisperは、OpenAIのAlec Radfordらによって2022年9月に発表された自動音声認識(ASR)のための事前学習モデルです。Whisperは、Wav2Vec 2.0などの先行研究とは異なり、ラベル付きの音声トランスクリプションデータで事前学習されています。具体的には、680,000時間のデータが使用されています。これは、Wav2Vec 2.0の訓練に使用されるラベルなしの音声データ(60,000時間)よりも桁違いに多いデータです。さらに、この事前学習データのうち117,000時間が多言語ASRデータです。これにより、96以上の言語に適用できるチェックポイントが生成され、その多くは低リソース言語とされています。 このような大量のラベル付きデータにより、Whisperは事前学習データから音声認識の教師ありタスクを直接学習し、音声トランスクリプションデータからテキストへのマッピングを学習します。そのため、Whisperはパフォーマンスの高いASRモデルを得るためにほとんど追加の細かい調整を必要としません。これに対して、Wav2Vec 2.0は非教師付きタスクのマスク予測で事前学習されており、音声から隠れた状態への中間的なマッピングを学習します。非教師付きの事前学習は音声の高品質な表現を生み出しますが、音声からテキストへのマッピングは学習されません。このマッピングは細かい調整中にのみ学習されるため、競争力のあるパフォーマンスを得るにはより多くの細かい調整が必要です。 680,000時間のラベル付き事前学習データにスケールされると、Whisperモデルは多くのデータセットとドメインに対して高い汎化能力を示します。事前学習されたチェックポイントは、LibriSpeech ASRのtest-cleanサブセットで約3%の単語エラーレート(WER)を達成し、TED-LIUMでは4.7%のWERで新たな最先端の結果を実現します(Whisper論文の表8を参照)。Whisperが事前学習中に獲得した多言語ASRの知識は、他の低リソース言語に活用することができます。細かい調整により、事前学習済みのチェックポイントを特定のデータセットと言語に適応させることで、これらの結果をさらに改善することができます。 Whisperは、Transformerベースのエンコーダーデコーダーモデルであり、シーケンスからシーケンスへのモデルとも呼ばれています。Whisperは、オーディオのスペクトログラム特徴のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は特徴抽出器によってログメルスペクトログラムに変換されます。次に、Transformerエンコーダーはスペクトログラムをエンコードしてエンコーダーの隠れ状態のシーケンスを形成します。最後に、デコーダーはエンコーダーの隠れ状態と以前に予測されたトークンの両方に依存して、テキストトークンを自己回帰的に予測します。図1はWhisperモデルを要約しています。 <img…

ホモモーフィック暗号化による暗号化データの感情分析
感情分析モデルは、テキストがポジティブ、ネガティブ、または中立であるかを判断することが広く知られています。しかし、このプロセスには通常、暗号化されていないテキストへのアクセスが必要であり、プライバシー上の懸念が生じる可能性があります。 ホモモーフィック暗号化は、復号化することなく暗号化されたデータ上で計算を行うことができる暗号化の一種です。これにより、ユーザーの個人情報や潜在的に機密性の高いデータがリスクにさらされるアプリケーションに適しています(例:プライベートメッセージの感情分析)。 このブログ投稿では、Concrete-MLライブラリを使用して、データサイエンティストが暗号化されたデータ上で機械学習モデルを使用することができるようにしています。事前の暗号学の知識は必要ありません。暗号化されたデータ上で感情分析モデルを構築するための実践的なチュートリアルを提供しています。 この投稿では以下の内容をカバーしています: トランスフォーマー トランスフォーマーをXGBoostと組み合わせて感情分析を実行する方法 トレーニング方法 Concrete-MLを使用して予測を暗号化されたデータ上の予測に変換する方法 クライアント/サーバープロトコルを使用してクラウドにデプロイする方法 最後に、この機能を実際に使用するためのHugging Face Spaces上の完全なデモで締めくくります。 環境のセットアップ まず、次のコマンドを実行してpipとsetuptoolsが最新であることを確認します: pip install -U pip setuptools 次に、次のコマンドでこのブログに必要なすべてのライブラリをインストールします。 pip install concrete-ml transformers…
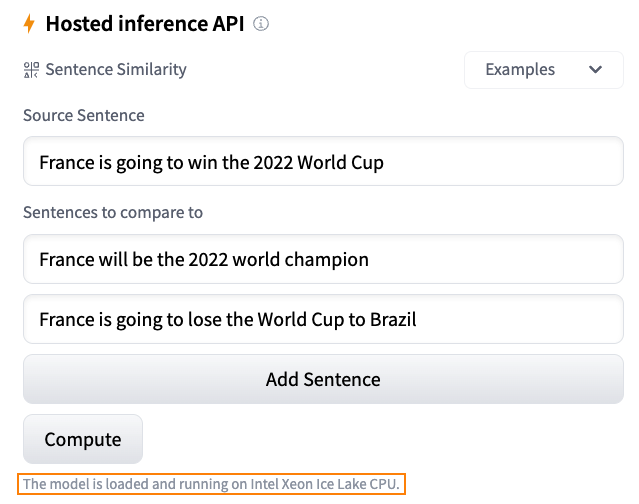
Hugging Faceにおける推論ソリューションの概要
毎日、開発者や組織はHugging Faceでホストされたモデルを採用し、アイデアを概念実証デモに、デモを本格的なアプリケーションに変えています。例えば、Transformerモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習(ML)アプリケーションの人気のあるアーキテクチャとなりました。最近では、ディフューザーがテキストから画像または画像から画像を生成するための人気のあるアーキテクチャとなりました。他のアーキテクチャも他のタスクで人気があり、私たちはそれらをすべてHF Hubでホストしています! Hugging Faceでは、最新のモデルを最小限の摩擦でテストおよび展開できる能力は、MLプロジェクトのライフサイクル全体で重要です。コストとパフォーマンスの比率を最適化することも同様に重要であり、無料のCPUベースの推論ソリューションを提供していただいたインテルの友人に感謝申し上げます。これは私たちのパートナーシップにおけるさらなる大きな一歩です。また、Intel Xeon Ice Lakeアーキテクチャによる高速化を無料でお楽しみいただけるため、ユーザーコミュニティの皆様にとっても素晴らしいニュースです。 さあ、Hugging Faceでの推論オプションを見てみましょう。 無料推論ウィジェット Hugging Faceハブでの私のお気に入りの機能の1つは、推論ウィジェットです。モデルページにある推論ウィジェットを使用すると、サンプルデータをアップロードして1クリックで予測することができます。 以下は、sentence-transformers/all-MiniLM-L6-v2モデルを使用した文の類似性の例です: モデルの動作、出力、およびデータセットのいくつかのサンプルでのパフォーマンスを素早く把握する最良の方法です。モデルはサーバー上でオンデマンドでロードされ、必要なくなるとアンロードされます。コードを書く必要はありませんし、この機能は無料です。どこが好きではないですか? 無料推論API 推論APIは、推論ウィジェットの内部で動作しています。単純なHTTPリクエストで、ハブの任意のモデルをロードし、数秒でデータを予測することができます。モデルのURLと有効なハブトークンが必要です。 以下は、xlm-roberta-baseモデルを1行でロードして予測する方法です: curl https://api-inference.huggingface.co/models/xlm-roberta-base \ -X POST \…

🤗変換器を使用した確率的な時系列予測
はじめに 時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。 確率予測 通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。 一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。 つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。 確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。 時系列トランスフォーマ 時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。 このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。 まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。 第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。 トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。 Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。 🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。 環境のセットアップ…

Apple SiliconでのCore MLを使用した安定した拡散を利用する
Appleのエンジニアのおかげで、Core MLを使用してApple SiliconでStable Diffusionを実行できるようになりました! このAppleのレポジトリは、🧨 Diffusersを基にした変換スクリプトと推論コードを提供しており、私たちはそれが大好きです!できるだけ簡単にするために、私たちは重みを変換し、モデルのCore MLバージョンをHugging Face Hubに保存しました。 更新:この投稿が書かれてから数週間後、私たちはネイティブのSwiftアプリを作成しました。これを使用して、自分自身のハードウェアでStable Diffusionを簡単に実行できます。私たちはMac App Storeにアプリをリリースし、他のプロジェクトがそれを使用できるようにソースコードも公開しました。 この投稿の残りの部分では、変換された重みを自分自身のコードで使用する方法や、追加の重みを変換する方法について説明します。 利用可能なチェックポイント 公式のStable Diffusionのチェックポイントはすでに変換されて使用できる状態です: Stable Diffusion v1.4:変換されたオリジナル Stable Diffusion v1.5:変換されたオリジナル Stable…

GPT2からStable Diffusionへ:Hugging FaceがElixirコミュニティに参入します
エリクサーのコミュニティは、GPT2からStable Diffusionまでのいくつかのニューラルネットワークモデルがエリクサーに到着したことをお知らせいたします。これは、Hugging Face Transformersを純粋なエリクサーで実装したBumblebeeライブラリによって可能になりました。 これらのモデルで始めるために、エリクサーの計算ノートブックプラットフォームであるLivebookのチームが、「スマートセル」と呼ばれるコレクションを作成しました。これにより、開発者はわずか3回のクリックで異なるニューラルネットワークタスクのスキャフォールドを作成できます。詳細については、私のビデオアナウンスをご覧ください。 エリクサーが実行されるErlang仮想マシンの並行性と分散サポートのおかげで、開発者はこれらのモデルを既存のPhoenixウェブアプリケーションの一部として埋め込み、提供することができます。また、Broadwayを使用してデータ処理パイプラインに統合し、Nerves組み込みシステムと一緒にデプロイすることもできます。いずれのシナリオでも、BumblebeeモデルはCPUとGPUの両方にコンパイルされます。 背景 エリクサーに機械学習を導入する取り組みは、ほぼ2年前にNumerical Elixir(Nx)プロジェクトで始まりました。Nxプロジェクトは、マルチ次元テンソルと「数値定義」を実装しています。これは、CPU/GPUにコンパイルできるElixirのサブセットです。Nxは、Google XLA(EXLA)とLibtorch(Torchx)のバインディングを使用して、車輪の再発明を防いでいます。 Nxイニシアチブからは、他のいくつかのプロジェクトが生まれました。Axonは、FlaxやPyTorch Igniteなどのプロジェクトからインスピレーションを受け、エリクサーに機能的で組み合わせ可能なニューラルネットワークをもたらします。Explorerプロジェクトは、dplyrとRustのPolarsから借用して、エリクサーコミュニティに表現力豊かで高性能なデータフレームを提供します。 BumblebeeとTokenizersは、私たちが最近リリースしたものです。私たちは、Hugging Faceがコミュニティとツール間での協力的な機械学習を可能にすることに感謝しています。これは、エリクサーエコシステムを迅速に進化させる上で重要な役割を果たしました。 次に、エリクサーでのニューラルネットワークのトレーニングと転移学習に焦点を当てる予定です。これにより、開発者は事業やアプリケーションのニーズに合わせて事前学習済みモデルを拡張および特化することができます。また、伝統的な機械学習アルゴリズムの開発についても、さらに発表する予定です。 あなたの番です Bumblebeeを試してみたい場合は、次のことができます: Livebook v0.8をダウンロードし、ノートブック内の「+ Smart」セルメニューから「ニューラルネットワークタスク」を自動生成します。現在、Livebookを追加のプラットフォームとスペースで実行できるようにする作業を進めています(お楽しみに!😉)。 Bumblebeeモデルの例として、単一ファイルのPhoenixアプリケーションも作成しました。これは、Phoenix(+ LiveView)アプリケーションの一部として統合するための必要な基盤を提供します。 より実践的なアプローチに興味がある場合は、いくつかのノートブックを読んでみてください。 エリクサーの機械学習エコシステムの構築を支援したい場合は、上記のプロジェクトをチェックして試してみてください。コンパイラ開発からモデル構築まで、多くの興味深い領域があります。たとえば、Bumblebeeにさらにモデルやアーキテクチャを追加するプルリクエストは、歓迎されるでしょう。未来は並行、分散、そして楽しいです!
インテルのサファイアラピッズを使用してPyTorch Transformersを高速化する – パート1
約1年前、私たちはHugging Faceのtransformersをクラスターまたは第3世代のIntel Xeon Scalable CPU(別名:Ice Lake)でトレーニングする方法を紹介しました。最近、Intelは第4世代のXeon CPUであるSapphire Rapidsというコードネームの新しいCPUを発売しました。このCPUには、深層学習モデルでよく見られる操作を高速化するエキサイティングな新しい命令があります。 この投稿では、AWS上で実行するSapphire Rapidsサーバーのクラスターを使用して、PyTorchトレーニングジョブの処理を高速化する方法を学びます。ジョブの分散にはIntelのoneAPI Collective Communications Library(CCL)を使用し、新しいCPU命令を自動的に活用するためにIntel Extension for PyTorch(IPEX)ライブラリを使用します。両方のライブラリはすでにHugging Face transformersライブラリと統合されているため、コードの1行も変更せずにサンプルスクリプトをそのまま実行できます。 次の投稿では、Sapphire Rapids CPU上での推論とそれによるパフォーマンス向上について説明します。 CPUでのトレーニングを検討すべき理由 Intel Xeon…

Hugging Faceデータセットとトランスフォーマーを使用した画像の類似性
この投稿では、🤗 Transformersを使用して画像の類似性システムを構築する方法を学びます。クエリ画像と候補画像の類似性を見つけることは、逆画像検索などの情報検索システムの重要なユースケースです。システムが答えようとしているのは、クエリ画像と候補画像セットが与えられた場合、どの画像がクエリ画像に最も類似しているかということです。 このシステムの構築には、このシステムの構築時に便利な並列処理をシームレスにサポートする🤗のdatasetsライブラリを活用します。 この投稿では、ViTベースのモデル( nateraw/vit-base-beans )と特定のデータセット(Beans)を使用していますが、ビジョンモダリティをサポートし、他の画像データセットを使用するために拡張することもできます。試してみることができるいくつかの注目すべきモデルには次のものがあります: Swin Transformer ConvNeXT RegNet また、投稿で紹介されているアプローチは、他のモダリティにも拡張できる可能性があります。 完全に動作する画像の類似性システムを学習するには、最初に2つの画像間の類似性をどのように定義するかを定義する必要があります。 このシステムを構築するためには、まず与えられた画像の密な表現(埋め込み)を計算し、その後、余弦類似性指標を使用して2つの画像の類似性を決定する一般的な方法があります。 この投稿では、画像をベクトル空間で表現するために「埋め込み」を使用します。これにより、画像の高次元ピクセル空間(たとえば224 x 224 x 3)を意味のある低次元空間(たとえば768)にうまく圧縮する方法が得られます。これによる主な利点は、後続のステップでの計算時間の削減です。 画像から埋め込みを計算するために、入力画像をベクトル空間で表現する方法について理解しているビジョンモデルを使用します。このタイプのモデルは画像エンコーダとも呼ばれます。 モデルをロードするために、AutoModelクラスを活用します。これにより、Hugging Face Hubから互換性のあるモデルチェックポイントをロードするためのインターフェースが提供されます。モデルと共に、データ前処理に関連するプロセッサもロードします。 from transformers…

Intel Sapphire Rapidsを使用してPyTorch Transformersを高速化する – パート2
最近の投稿では、第4世代のIntel Xeon CPU(コードネーム:Sapphire Rapids)とその新しいAdvanced Matrix Extensions(AMX)命令セットについて紹介しました。Amazon EC2上で動作するSapphire Rapidsサーバーのクラスタと、Intel Extension for PyTorchなどのIntelライブラリを組み合わせることで、スケールでの効率的な分散トレーニングを実現し、前世代のXeon(Ice Lake)に比べて8倍の高速化とほぼ線形スケーリングを達成する方法を紹介しました。 この投稿では、推論に焦点を当てます。PyTorchで実装された人気のあるHuggingFaceトランスフォーマーと共に、Ice Lakeサーバーでの短いおよび長いNLPトークンシーケンスのパフォーマンスを測定します。そして、Sapphire RapidsサーバーとHugging Face Optimum Intelの最新バージョンを使用して同じことを行います。Hugging Face Optimum Intelは、Intelプラットフォームのハードウェアアクセラレーションに特化したオープンソースのライブラリです。 さあ、始めましょう! CPUベースの推論を検討すべき理由 CPUまたはGPUで深層学習の推論を実行するかどうかを決定する際には、いくつかの要素を考慮する必要があります。最も重要な要素は、モデルのサイズです。一般に、より大きなモデルはGPUによって提供される追加の計算能力からより多くの利益を得ることができますが、より小さいモデルはCPU上で効率的に実行することができます。…

パラメータ効率の高いファインチューニングを使用する 🤗 PEFT
動機 トランスフォーマーアーキテクチャに基づく大規模言語モデル(LLM)であるGPT、T5、BERTなどは、さまざまな自然言語処理(NLP)タスクで最先端の結果を達成しています。これらのモデルは、コンピュータビジョン(CV)(VIT、Stable Diffusion、LayoutLM)やオーディオ(Whisper、XLS-R)などの他の領域にも進出しています。従来のパラダイムは、一般的なWebスケールのデータでの大規模な事前学習に続いて、ダウンストリームのタスクに対する微調整です。ダウンストリームのデータセットでこれらの事前学習済みLLMを微調整することで、事前学習済みLLMをそのまま使用する場合(ゼロショット推論など)と比較して、大幅な性能向上が得られます。 しかし、モデルが大きくなるにつれて、完全な微調整は一般的なハードウェアで訓練することが不可能になります。また、各ダウンストリームタスクごとに微調整済みモデルを独立して保存および展開することは非常に高コストです。なぜなら、微調整済みモデルのサイズは元の事前学習済みモデルと同じサイズだからです。パラメータ効率の良い微調整(PEFT)アプローチは、これらの問題に対処するために開発されました! PEFTアプローチは、事前学習済みLLMのほとんどのパラメータを凍結しながら、わずかな(追加の)モデルパラメータのみを微調整するため、計算およびストレージコストを大幅に削減します。これにより、LLMの完全な微調整中に観察される「壊滅的な忘却」という問題も克服されます。PEFTアプローチは、低データレジメでの微調整よりも優れた性能を示し、ドメイン外のシナリオにもより適応します。これは、画像分類や安定拡散ドリームブースなどのさまざまなモダリティに適用することができます。 また、PEFTアプローチは移植性にも役立ちます。ユーザーはPEFTメソッドを使用してモデルを微調整し、完全な微調整の大きなチェックポイントと比較して数MBの小さなチェックポイントを取得することができます。たとえば、「bigscience/mt0-xxl」は40GBのストレージを使用し、完全な微調整では各ダウンストリームデータセットに40GBのチェックポイントが生成されますが、PEFTメソッドを使用すると、各ダウンストリームデータセットにはわずか数MBのチェックポイントでありながら、完全な微調整と同等の性能が得られます。PEFTアプローチからの小さなトレーニング済み重みは、事前学習済みLLMの上に追加されます。そのため、モデル全体を置き換えることなく、小さな重みを追加することで同じLLMを複数のタスクに使用することができます。 つまり、PEFTアプローチは、わずかなトレーニング可能なパラメータの数だけで完全な微調整と同等のパフォーマンスを実現できるようにします。 本日は、🤗 PEFTライブラリをご紹介いたします。このライブラリは、最新のパラメータ効率の良い微調整技術を🤗 Transformersと🤗 Accelerateにシームレスに統合しています。これにより、Transformersの最も人気のあるモデルを使用し、Accelerateのシンプルさとスケーラビリティを活用することができます。以下は現在サポートされているPEFTメソッドですが、今後も追加される予定です: LoRA:LORA:大規模言語モデルの低ランク適応 Prefix Tuning:P-Tuning v2:プロンプトチューニングは、スケールとタスクにわたって完全な微調整と同等の性能を発揮することができます Prompt Tuning:パラメータ効率の良いプロンプトチューニングの力 P-Tuning:GPTも理解しています ユースケース ここでは多くの興味深いユースケースを探求しています。以下はいくつかの興味深い例です: Google Colabで、Nvidia GeForce RTX…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.