Learn more about Search Results 参考文献 - Page 39

- You may be interested
- MLモデルのトレーニングパイプラインの構...
- 「2023年の最高の人工知能AIベースのアー...
- 「ジェネラティブAIおよびMLモデルを使用...
- 合成データ生成のマスタリング:応用とベ...
- 初心者データサイエンティストが避けるべ...
- ロボットたちが助けを求める方法を学んで...
- 「ChatGPTを活用したデータクリーニングと...
- カルテックとETHチューリッヒの研究者が画...
- 「アジア競技大会、eスポーツがオリンピッ...
- 確率的なML(機械学習)とは、Pythonを使...
- 「Llama2が搭載されたチャットボットはCPU...
- (きんむかんりをかくめいかするみっつのほ...
- クラウドの保護:クラウドセキュリティの...
- メタAIは、CM3leonを紹介します:最先端の...
- 「修正策にもかかわらず、ハッカーたちが...

Pythonでトレーニング済みモデルを保存する方法
実世界の機械学習(ML)のユースケースに取り組む際、最適なアルゴリズム/モデルを見つけることは責任の終わりではありませんこれらのモデルを将来の使用や本番環境への展開のために保存、保管、パッケージ化することが重要ですこれらのプラクティスはいくつかの理由から必要です:再強調すると、MLモデルの保存と保管...

MLにおけるETLデータパイプラインの構築方法
データ処理から迅速な洞察まで、頑強なパイプラインはどんなMLシステムにとっても必須ですデータチーム(データとMLエンジニアで構成される)はしばしばこのインフラを構築する必要があり、この経験は苦痛となることがありますしかし、MLでETLパイプラインを効率的に使用することで、彼らの生活をはるかに楽にすることができます本記事では、その重要性について探求します...

小売およびeコマースにおけるMLプラットフォームの構築
組織内で機械学習を利用して難しい問題を解決することは素晴らしいですさらに、eコマース企業にはMLが役立つケースがたくさんありますただし、より多くのMLモデルやシステムが本番環境で稼働するにつれて、信頼性のある管理のためにより多くのインフラが必要になりますそのため、多くの...

MLモデルの最適化とデバッグにSHAP値を使用する方法
こんな状況を想像してください数え切れないほどの時間を費やして、モデルのトレーニングと微調整に取り組み、山ほどのデータを入念に分析しましたしかし、予測に影響を与える要因に明確な理解が欠けており、その結果、さらに改善することが難しいと感じていますもし過去にこうした状況に陥ったことがあるなら、…

行動の組み合わせによる高速強化学習
新しいレシピを学ぶたびに、切る・皮をむく・かき混ぜる方法を再び学ばなければならないとしたらどうでしょうか多くの機械学習システムでは、新たな課題に直面するときに、エージェントは完全にゼロから学ばなければなりませんしかし、明らかなことは、人々はこれよりも効率的に学ぶことができるということです彼らは以前に学んだ能力を組み合わせることができます有限の単語の辞書がほぼ無限の意味を持つ文に再構成されるように、人々は既に持っているスキルを再利用し再組み合わせして新しい課題に取り組むのです
モデルの解釈のマスタリング:パーシャル依存プロットの包括的な解説
モデルの解釈方法を知っていることは、それが奇妙なことをしていないかを理解するために不可欠ですモデルをよりよく知っているほど、予測時の振る舞いに驚かされる可能性は低くなります
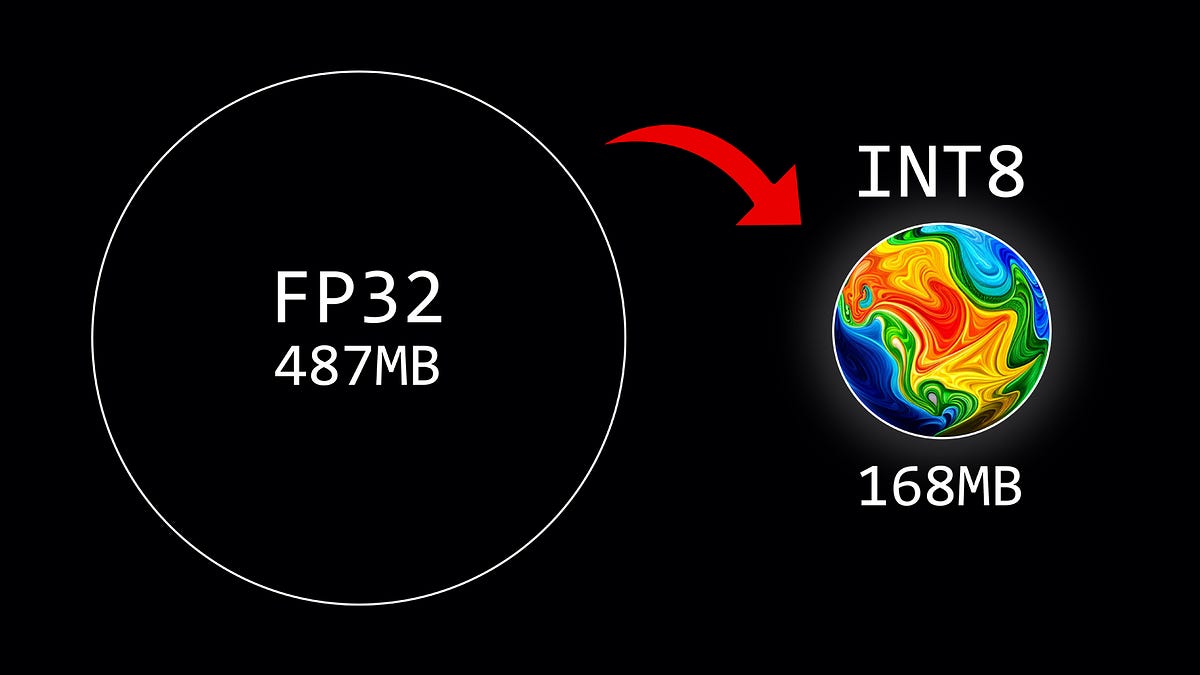
重み量子化の概要
この記事では、8ビットの量子化方式を使用して、大規模言語モデルのパラメータを量子化する方法について説明しています
極小データセットを用いたテキスト分類チャレンジ:ファインチューニング対ChatGPT
Toloka MLチームは、さまざまな条件下でのテキスト分類の異なるアプローチを継続的に研究し比較していますここでは、NLPのパフォーマンスに関する私たちの別の実験をご紹介します
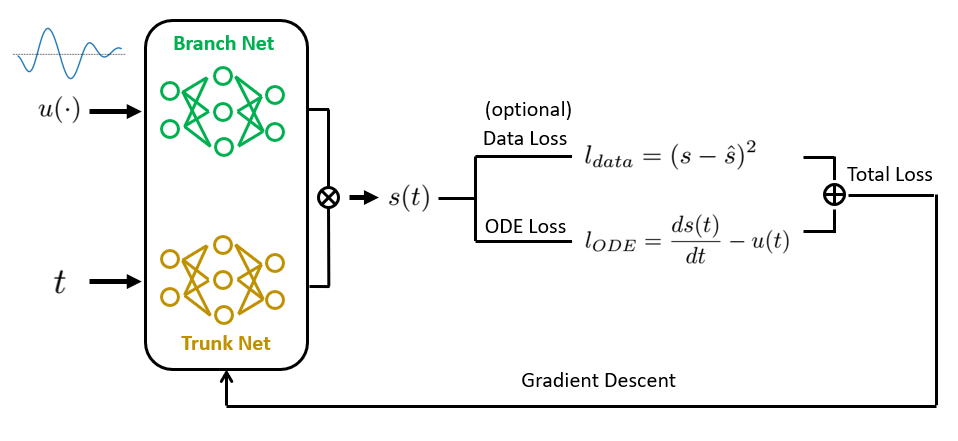
物理情報を組み込んだDeepONetによるオペレータ学習 ゼロから実装しましょう
普通微分方程式と偏微分方程式(ODEs / PDEs)は、物理学や生物学から経済学や気候科学まで、科学と工学の多くの分野の基礎ですそれらは...
OpenAIのモデレーションAPIを使用してコンテンツのモデレーションを強化する
プロンプトエンジニアリングの台頭や、言語モデルの大規模な成果により、私たちの問いに対する応答を生成する際の大変な成果を上げたLarge Language Modelsの注目すべき成果により、ChatGPTのようなチャットボットは私たちの日常生活の重要な一部となりつつあります...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.