Learn more about Search Results ローン - Page 39

- You may be interested
- データアナリストのリアルライフでの確率...
- 「ChatGPTとCanvaを使用して1分で100のIns...
- 「Amazon SageMaker Data Wranglerを使用...
- ベイジアンマーケティングミックスモデル...
- 「カナダでウェブサイトを立ち上げる方法」
- アンサンブル学習技術:Pythonでのランダ...
- 完全に説明されたAdaBoostアンサンブルテ...
- 「ランバード効果と聴覚障害への役立ち方」
- 安定した拡散 コミュニティのAI
- 「UBCと本田技研が、敏感なロボット用の革...
- レオナルドAI:Midjourneyの新たな競合相手
- インターネット上のトップ8逆電話検索ツール
- Python __init__はコンストラクタではあり...
- 再抽出を用いた統計的実験
- 紛争のトレンドとパターンの探索:マニプ...

「BentoML入門:統合AIアプリケーションフレームワーク」
この記事では、統合されたAIアプリケーションフレームワークであるBentoMLを使用して、機械学習モデルの展開を効率化する方法について探求します

5分であなたのStreamlitウェブアプリをデプロイしましょう
データサイエンティストが自分の作業をダッシュボードや動作するウェブアプリで紹介することが求められるようになりましたウェブアプリを作成するために利用可能なツールを知っていると非常に便利です利用可能なツールはたくさんあります...
5分であなたのStreamlitウェブアプリを展開してください
データサイエンティストが自分の仕事をダッシュボードや動作するWebアプリで紹介する必要性が高まってきていますWebアプリを作成するための利用可能なツールを知っておくことは非常に便利です利用可能なツールはたくさんあります...

ChatGPTのコードインタプリター:知っておくべきすべてのこと
OpenAIは、興奮をもって発表を行っており、最新の発表はChatGPT Plusのユーザーを喜ばせることでしょう。数ヶ月の期待を経て、Code Interpreterプラグインは来週ベータモードでローンチされます。この画期的な機能により、ユーザーはChatGPT内でコードをシームレスに解釈・実行することが可能となり、データ分析から可視化など、さまざまなことが可能になります。Code Interpreterプラグインは、AIモデルとのインタラクション方法を革新的に変えます。 また読む:OpenAIが全てのChatGPT Plusユーザー向けにChatGPTプラグインを展開中 | 有効化方法を学ぶ コード解釈の力を解き放つ Code Interpreterプラグインの導入により、ChatGPT Plusのユーザーは様々な機能を持つ強力なツールにアクセスすることができます。これにより、データの分析、グラフの作成、ファイルの編集、数学的な操作、コードの直接実行などがChatGPTのインターフェース内で行えます。このプラグインの多様性は、特にデータサイエンスの領域で非常に有用です。 Code Interpreter:データサイエンティストの最良のパートナー データサイエンティストは特に、Code Interpreterプラグインから多くの恩恵を受けることができます。ChatGPT Plusパッケージに含まれるこの最先端のツールは、データサイエンティストのワークフローのさまざまな側面を効率化し向上させる潜在能力を持っています。データの可視化やトレンドの分析、データセットの変換など、このプラグインは従来のデータサイエンスツールと同等の機能を提供します。Code Interpreterプラグインは、追加のソフトウェアや専門知識を必要とせずに複雑なタスクを実行することができるため、この分野において画期的な存在となります。 興奮に満ちたコミュニティ Code Interpreterプラグインの利用可能性のニュースは、ChatGPT Plusユーザーコミュニティ全体に興奮をもたらしました。ユーザーは既にこの強力な新機能を最大限に活用するためのヒントやトリックを共有しています。4月の12のプラグインの初期発表以来、プラットフォームは200以上のプラグインに成長し、ユーザーの可能性をさらに拡大しています。ChatGPTを取り巻く活気あるサポートコミュニティは、ユーザーがCode Interpreterプラグインの活用を最大化するための指導とインスピレーションを簡単に見つけられることを保証します。 また読む:ChatGPTのビッグサプライズ:OpenAIがAIマーケットプレイスを作成…
「PolarsによるEDA:集計と分析関数のステップバイステップガイド(パート2)」
このシリーズの最初のパートでは、Polarsの基礎をカバーし、その機能と構文をPandasと比較しましたこのパートでは、クエリの複雑さをさらに一歩進めますので、...

「人工知能 vs 人間の知能:トップ7の違い」
はじめに 人工知能は、架空のAIキャラクターJARVISから現実のChatGPTまで、長い道のりを経て進化してきました。しかしながら、人間の知性は学習、理解、革新的な解決策の発見を支援する特性であり、データを基に人間を模倣する人工知能とは異なります。AIが今日、非常に普及したことで、人工知能 vs 人間の知能という新たな議論が浮上し、これら2つの競合するパラダイムを比較するようになりました。 人工知能とは何ですか? 人工知能と呼ばれるデータサイエンスのサブフィールドは、人間の知性と認識を必要とするさまざまなタスクを実行できる知的なコンピュータを作成することに関連しています。これらの洗練されたマシンは、過去のエラーや歴史的データから学び、周囲の状況を分析し、必要な手段を決定することができます。 AIは、計算科学、認知科学、言語学、神経科学、心理学、数学など、多くの他の学問からのアイデアと手法を統合した分野です。 この機械は自己学習、自己分析、自己改善の能力を持ち、処理中には最小限またはほとんど人間の努力を必要とします。 これは、メディア業界、医療業界、グラフィックスやアニメーションなど、あらゆるビジネスで、技術が行動を人間に基づいて再現するのを支援するために利用されています。 人間の知能とは何ですか? 人間の知能は、理性的に考え、さまざまな表現を理解し、難しい概念を理解し、数学の問題を解決し、変化する状況に適応し、知識を使って環境を制御し、他者とコミュニケーションする能力を指します。 それは、特定のスキルセットや知識の体系に関する情報を提供するかもしれず、別の人間に関連するかもしれません。また、情報エージェントやロケーターの場合は、アクセスしなければならない外交情報を提供するかもしれません。さらに、それはソーシャルネットワークや個人的なつながりについての情報を提供するかもしれません。 人間の知能と行動は、個人の独特な遺伝子、幼少期の成長、さまざまな出来事や環境への経験に根ざしています。さらに、それは個人の新しく獲得した知識を使って自分の環境を変える能力に完全に依存しています。 人工知能 vs 人間の知能 以下に人間の知能と人工知能の詳細な違いを説明します: パラメータ 人間の知能 人工知能 起源 人間は理性的に考え、思考し、評価し、他の認知的なタスクを実行する能力を持って生まれます。 AIは人間の洞察によって生み出された革新であり、Norbert Wienerは批判のメカニズムについて理論を進めることでこの分野の発展に貢献しました。…

「アリババが新しいAIツールを導入し、テキスト入力から画像を生成しました」
今日、テクノロジージャイアントのアリババは、期待されていたAIツール、同義ワンシャンを正式に発表しました報道によると、これはテキスト入力によって画像を生成することができます興味深いことに、このAIは、ユーザーが中国語と英語のプロンプトを入力して画像を生成することを可能にしますスタイルには、スケッチスタイルから3Dまで、さまざまなものが含まれています...

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…
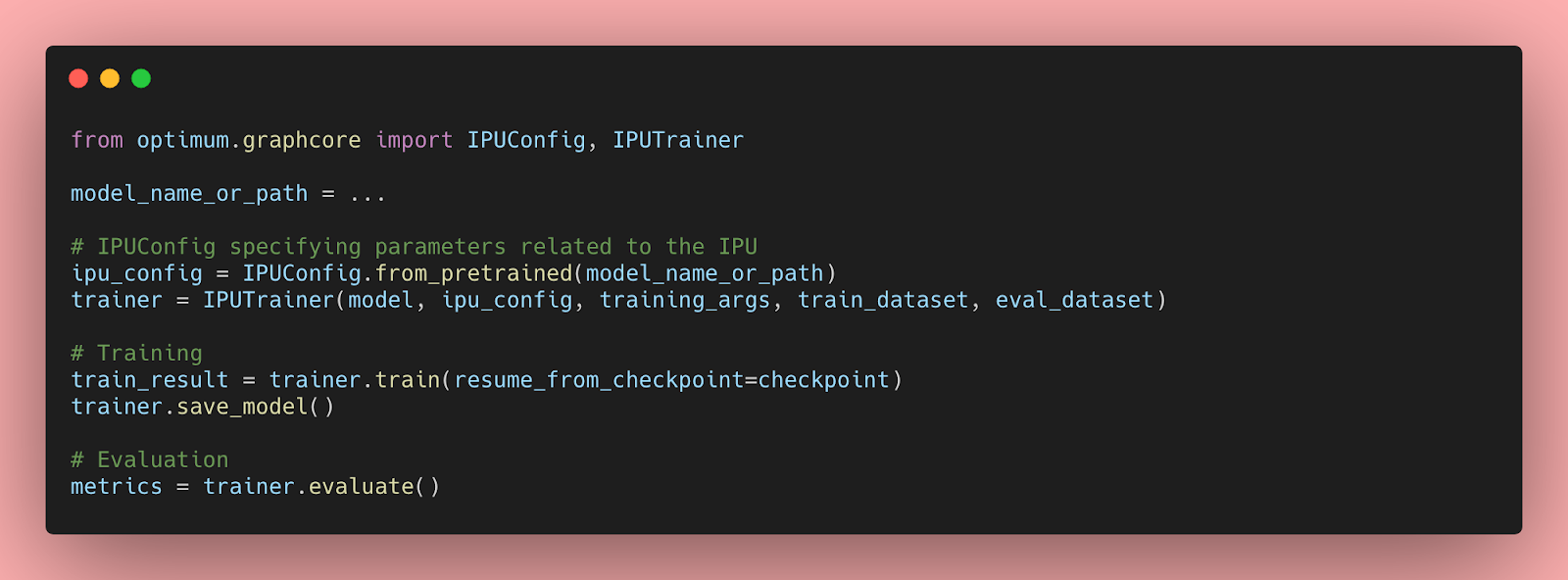
IPUを使用したHugging Face Transformersの始め方と最適化について
Transformerモデルは、自然言語処理、音声処理、コンピュータビジョンなど、さまざまな機械学習タスクで非常に効率的であることが証明されています。しかし、これらの大規模なモデルの予測速度は、会話型アプリケーションや検索などのレイテンシに敏感なユースケースでは実用的ではありません。さらに、実世界でのパフォーマンスを最適化するには、多くの企業や組織には到底手の届かない時間、労力、スキルが必要です。 幸いなことに、Hugging FaceはOptimumというオープンソースのライブラリを導入しました。このライブラリを使用すると、さまざまなハードウェアプラットフォーム上でTransformerモデルの予測レイテンシを大幅に削減することが容易になります。このブログ記事では、AIワークロードに最適化されたGraphcore Intelligence Processing Unit(IPU)向けにTransformerモデルを高速化する方法を学びます。 OptimumがGraphcore IPUと出会う GraphcoreとHugging Faceのパートナーシップにより、最初のIPUに最適化されたモデルとしてBERTが導入されました。今後数ヶ月にわたり、ビジョン、音声、翻訳、テキスト生成など、さまざまなアプリケーションに対応したIPUに最適化されたモデルをさらに導入していく予定です。 Graphcoreのエンジニアは、Hugging Faceのトランスフォーマーを使用してBERTをIPUシステムに実装し、最新のモデルを簡単にトレーニング、微調整、高速化できるように最適化しました。 IPUとOptimumの始め方 OptimumとIPUの使用を始めるために、BERTを例にして説明します。 このガイドでは、Graphcoreのクラウドベースの機械学習プラットフォームであるGraphcloudのIPU-POD16システムを使用し、Getting Started with Graphcloud のPyTorchのセットアップ手順に従います。 GraphcloudサーバーにはすでにPoplar SDKがインストールされています。別のセットアップを使用している場合は、PyTorch for the IPU:…

スクラッチからCodeParrot 🦜をトレーニングする
このブログポストでは、GitHub CoPilotの背後にある技術を構築するために必要なものについて説明します。GitHub CoPilotは、プログラマがコードを書く際に提案を行うアプリケーションです。このステップバイステップガイドでは、ゼロから完全にトレーニングされた大規模なGPT-2モデルであるCodeParrot 🦜を訓練する方法を学びます。CodeParrotはPythonのコードを自動補完することができます – こちらで試してみてください。さあ、ゼロから構築してみましょう! ソースコードの大規模なデータセットの作成 まず必要なものは、大規模なトレーニングデータセットです。Pythonのコード生成モデルを訓練することを目指して、GoogleのBigQueryで利用可能なGitHubのダンプにアクセスし、すべてのPythonファイルに絞り込みました。その結果、180GBのデータセットがあり、2000万のファイルが含まれています(こちらで入手可能)。初期のトレーニング実験の結果、データセットの重複はモデルの性能に深刻な影響を与えることがわかりました。データセットを調査すると、次のことがわかりました: ユニークなファイルの0.1%が全ファイルの15%を占めています ユニークなファイルの1%が全ファイルの35%を占めています ユニークなファイルの10%が全ファイルの66%を占めています 詳細は、このTwitterスレッドで調査結果について詳しくご覧いただけます。重複を削除し、CoPilotの背後にあるモデルであるCodexの論文で見つかった同じクリーニングヒューリスティックを適用しました。CodexはGitHubのコードでファインチューニングされたGPT-3モデルです。 クリーニングされたデータセットはまだ50GBの大きさであり、Hugging Face Hubで利用可能です:codeparrot-clean。これで新しいトークナイザーを設定し、モデルを訓練することができます。 トークナイザーとモデルの初期化 まず、トークナイザーが必要です。コードを適切にトークンに分割するために、コード専用のトークナイザーをトレーニングしましょう。既存のトークナイザー(例えばGPT-2)を取り、train_new_from_iterator()メソッドで独自のデータセットでトレーニングします。それから、Hubにプッシュします。コードの例からインポートや引数のパース、ログ出力は省略していますが、前処理やダウンストリームタスクの評価を含めた完全なコードはこちらで見つけることができます。 # トレーニング用のイテレーター def batch_iterator(batch_size=10): for _ in…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.