Learn more about Search Results T5 - Page 38

- You may be interested
- マシュー・カーニー:AIと哲学を対話させる
- Langchainを使用してYouTube動画用のChatG...
- 「ジュニアデータサイエンティストのため...
- ネットワークの強化:異常検知のためのML...
- アリババのChatGPTの競合相手、統一千文と...
- 自分自身のデータを使用して、要約と質問...
- Amazon SageMaker JumpStartを通じてLlama...
- ロボット犬が世界記録を速度で打ち立てました
- 「PandasAIを使用してデータを自動的に探...
- 新鮮な視点で共通の機械学習タスクをどの...
- ウェイト、バイアス、ロスのアンボクシン...
- このAI研究は、DISC-MedLLMという包括的な...
- Amazon SageMaker Canvasを使用して、ノー...
- 「PolarsによるEDA:集計と分析関数のステ...
- 「MITの研究者がPFGM++を紹介:物理学とAI...
一度言えば十分です!単語の繰り返しはAIの向上に役立ちません
大規模言語モデル(LLM)はその能力を示し、世界中で話題になっています今や、すべての大手企業は洒落た名前を持つモデルを持っていますしかし、その裏にはすべてトランスフォーマーが動いています...

LLM-Blenderに会いましょう:複数のオープンソース大規模言語モデル(LLM)の多様な強みを活用して一貫して優れたパフォーマンスを達成するための新しいアンサンブルフレームワーク
大規模言語モデルは、さまざまなタスクにおいて驚異的なパフォーマンスを発揮しています。ユニークでクリエイティブなコンテンツの生成や回答の提供から、言語の翻訳や文章の要約まで、LLMは人間のまねをすることに成功しました。GPT、BERT、PaLMなどのよく知られたLLMは、正確に指示に従い、大量の高品質データにアクセスすることで、話題になっています。GPT4やPaLMのようなモデルはオープンソースではないため、アーキテクチャやトレーニングデータを理解することができない人がいるのに対して、Pythia、LLaMA、Flan-T5などのオープンソースLLMの存在により、研究者がカスタム指示データセットでモデルを微調整し、改善する機会を提供しています。これにより、Alpaca、Vicuna、OpenAssistant、MPTなどのより小型で効率的なLLMの開発が可能になります。 市場をリードするオープンソースLLMはひとつではありません。多様な例において最高のLLMは大きく異なるため、これらのLLMを動的にアンサンブルすることは、改良された回答を継続して生み出すために必要不可欠です。さまざまなLLMの独自の貢献を統合することで、バイアス、エラー、不確実性を低減し、人間の好みにより近い結果を得ることができます。この問題に対処するため、人工知能アレン研究所、南カリフォルニア大学、浙江大学の研究者らは、複数のオープンソース大規模言語モデルの多くの利点を利用して、常に優れたパフォーマンスを発揮するアンサンブルフレームワークであるLLM-BLENDERを提案しました。 LLM-BLENDERは、PAIRRANKERとGENFUSERの2つのモジュールで構成されています。これらのモジュールは、異なる例に対して最適なLLMが大きく異なることを示しています。最初のモジュールであるPAIRRANKERは、潜在的な出力の微小な変化を特定するために開発されました。これは、元のテキストと各LLMからの2つの候補出力を入力として、高度なペアワイズ比較技術を使用します。入力と候補ペアを共にエンコードするために、RoBERTaなどのクロスアテンションエンコーダを使用し、PAIRRANKERはこのエンコードを使用して2つの候補の品質を決定することができます。 2番目のモジュールであるGENFUSERは、上位ランクに入った候補を統合して改善された出力を生成することに焦点を当てています。GENFUSERは、選択されたLLMの利点を最大限に活用しつつ、欠点を最小限に抑えることを目的としています。GENFUSERは、さまざまなLLMの出力を統合することで、1つのLLMの出力よりも優れた出力を開発することを目指しています。 評価には、MixInstructというベンチマークデータセットが提供されており、Oracleペアワイズ比較を組み合わせ、さまざまな指示データセットを組み合わせています。このデータセットでは、11の人気のあるオープンソースLLMを使用して、各入力に対して複数の候補を生成し、さまざまな指示に従うタスクを実行します。自動評価のためにOracle比較が使用されており、候補出力に対するグランドトゥルースランキングが与えられているため、LLM-BLENDERや他のベンチマーク技術のパフォーマンスを評価することができます。 実験結果は、LLM-BLENDERが個別のLLMやベースライン技術よりも優れたパフォーマンスを発揮することを示しています。LLM-BLENDERのアンサンブル手法を使用することで、単一のLLMやベースライン方法を使用する場合と比較して、より高品質な出力が得られることが示されています。PAIRRANKERの選択は、参照ベースのメトリックやGPT-Rankにおいて、個別のLLMモデルを上回っています。GENFUSERは、PAIRRANKERのトップピックを利用して、効率的な融合を通じて応答品質を大幅に改善しています。 LLM-BLENDERは、Vicunaなどの個別のLLMを上回り、アンサンブル学習を通じてLLMの展開と研究を改善する可能性を示しています。

Python におけるカテゴリカル変数の扱い方ガイド
データサイエンスまたは機械学習プロジェクトでのカテゴリ変数の扱いは容易な仕事ではありませんこの種の作業には、アプリケーションの分野の深い知識と幅広い理解が必要です...

プレイヤーの離脱を予測する方法、ChatGPTの助けを借りる
ゲームの世界では、企業はプレイヤーを引きつけるだけでなく、特にゲーム内のマイクロトランザクションに頼る無料のゲームでは、できるだけ長く彼らを保持することを目指していますこれらの...
非教師あり学習シリーズ:階層クラスタリングの探索
前回の「教師なし学習シリーズ」の投稿では、最も有名なクラスタリング手法の1つであるK平均法クラスタリングについて探究しました今回の投稿では、別の手法の背後にある方法について説明します...
チャートの推論に基づくモデルの基盤
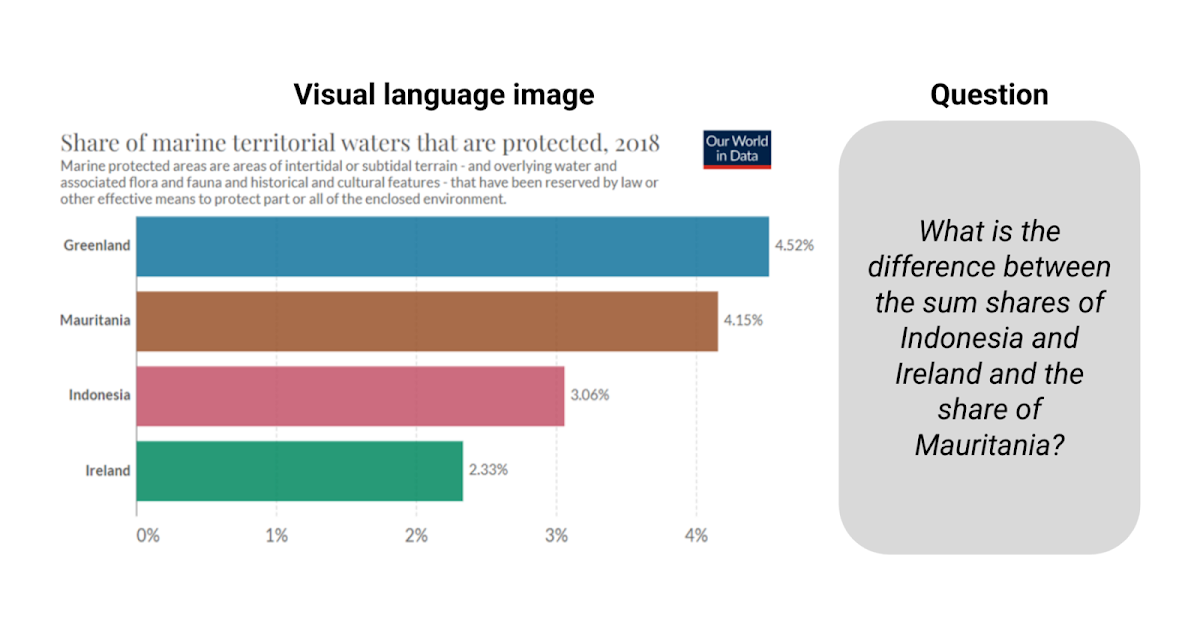
グーグルリサーチのリサーチソフトウェアエンジニア、ジュリアン・アイゼンシュロスによる投稿 ビジュアル言語は、情報を伝えるためにテキスト以外の絵文字を使用するコミュニケーション形式です。アイコノグラフィ、情報グラフィック、表、プロット、チャートなどの形でデジタルライフで普及しており、道路標識、コミックブック、食品ラベルなどの現実世界にも広がっています。このようなメディアをコンピュータがより理解できるようにすることは、科学的コミュニケーションと発見、アクセシビリティ、データの透過性に役立ちます。 ImageNetの登場以来、学習ベースのソリューションを使用してコンピュータビジョンモデルは大きな進歩を遂げてきましたが、焦点は自然画像にあり、分類、ビジュアルクエスチョンアンサリング(VQA)、キャプション、検出、セグメンテーションなどのさまざまなタスクが定義され、研究され、いくつかの場合には人間の性能に達成されています。しかし、ビジュアル言語は同じレベルの注目を集めていません。これは、この分野における大規模なトレーニングセットの不足のためかもしれません。しかし、PlotQA、InfographicsVQA、ChartQAなどの視覚言語イメージにおける質問応答システムの評価を目的とした新しい学術データセットが、ここ数年で作成されています。 ChartQAからの例。質問に答えるには、情報を読み取り、合計と差を計算する必要があります。 これらのタスクに対して構築された既存のモデルは、光学的文字認識(OCR)情報とその座標を大規模なパイプラインに統合することに頼っていましたが、プロセスはエラーが発生しやすく、遅く、一般化が悪いです。既存の畳み込みニューラルネットワーク(CNN)またはトランスフォーマーに基づくエンドツーエンドのコンピュータビジョンモデルは、自然画像で事前にトレーニングされたモデルを簡単にビジュアル言語に適応させることができなかったため、これらの方法が広く使用されていました。しかし、既存のモデルは、棒グラフの相対高さや円グラフのスライスの角度を読み取り、軸のスケールを理解し、色、サイズ、テクスチャでピクトグラムを伝説値に正しくマッピングし、抽出された数字で数値演算を実行するなど、チャートの質問に対する課題には準備ができていません。 これらの課題に対応するために、「MatCha:数学推論とチャートディレンダリングを活用したビジュアル言語の事前トレーニングの強化」という提案を行います。 MatChaは数学とチャートを表す言葉であり、2つの補完的なタスクでトレーニングされたピクセルからテキストへの基礎モデル(複数のアプリケーションでファインチューニングできる組み込み帰納バイアスを備えた事前トレーニングモデル)です。1つはチャートディレンダリングであり、プロットまたはチャートが与えられた場合、画像からテキストモデルはその基礎となるデータテーブルまたはレンダリングに使用されるコードを生成する必要があります。数学推論の事前トレーニングでは、テキストベースの数値推論データセットを選択し、入力を画像にレンダリングし、画像からテキストモデルが回答をデコードする必要があります。また、「DePlot:プロットからテーブルへの翻訳によるワンショットビジュアル言語推論」という、テーブルへの翻訳を介したチャートのワンショット推論にMatChaの上に構築されたモデルを提案します。これらの方法により、ChartQAの以前の最高記録を20%以上超え、パラメータが1000倍多い最高の要約システムに達成します。両方の論文はACL2023で発表されます。 チャートディレンダリング プロットやチャートは、基礎となるデータテーブルとコードによって通常生成されます。コードは、図の全体的なレイアウト(タイプ、方向、色/形状スキームなど)を定義し、基礎となるデータテーブルは実際の数字とそのグループ化を確立します。データとコードの両方がコンパイラ/レンダリングエンジンに送信され、最終的な画像が作成されます。チャートを理解するには、イメージ内の視覚パターンを発見し、効果的に解析してグループ化し、主要な情報を抽出する必要があります。プロットレンダリングプロセスを逆転するには、すべてのこのような機能が必要であり、したがって理想的な事前トレーニングタスクとして機能することができます。 ランダムなプロットオプションを使用して、Airbus A380 Wikipediaページの表から作成されたチャートです。MatChaの事前トレーニングタスクは、イメージからソーステーブルまたはソースコードを回復することです。 チャート、その基礎となるデータテーブル、およびそのレンダリングコードを同時に取得することは、実践的には困難です。事前トレーニングデータを十分に収集するために、[chart、code]および[chart、table]のペアを独立して蓄積します。[chart、code]の場合、適切なライセンスを持つすべてのGitHub IPythonノートブックをクロールし、図を含むブロックを抽出します。図とそれに直前にあるコードブロックは、[chart、code]ペアとして保存されます。[chart、table]のペアについては、2つのソースを調査しました。最初のソースは、合成データで、TaPasコードベースからWebクロールされたWikipediaテーブルを手動でコードに変換します。列のタイプに応じて、いくつかのプロットオプションをサンプリングして組み合わせます。さらに、事前トレーニングコーパスを多様化するために、PlotQAで生成された[chart、table]ペアも追加します。2番目のソースはWebクロールされた[chart、table]ペアです。Statista、Pew、Our World in Data、OECDの4つのWebサイトから合計約20,000ペアを含むChartQAトレーニングセットでクロールされた[chart、table]ペアを直接使用します。 数学的推論 MatChaに数値推論知識を組み込むために、テキスト数学データセットから数学的推論スキルを学習します。事前トレーニングには、MATHとDROPの2つの既存のテキスト数学推論データセットを使用します。MATHは合成的に作成され、各モジュール(タイプ)の質問ごとに200万のトレーニング例を含んでいます。DROPは読解型のQAデータセットで、入力はパラグラフのコンテキストと質問です。 DROPでの質問を解決するには、モデルがパラグラフを読み、関連する数字を抽出し、数値計算を実行する必要があります。私たちは、両方のデータセットが補完的であることを発見しました。MATHには、異なるカテゴリーにわたる多数の質問が含まれており、モデルに明示的に注入する必要がある数学的操作を特定するのに役立ちます。DROPの読解形式は、モデルが情報抽出と推論を同時に実行する典型的なQA形式に似ています。実際には、両方のデータセットの入力を画像にレンダリングします。モデルは答えをデコードするように訓練されます。 MATHとDROPからの例をMatChaの事前トレーニング目的に取り込むことにより、MatChaの数学的推論スキルを向上させます。入力テキストを画像としてレンダリングします。 エンドツーエンドの結果 Webサイト理解に特化した画像からテキストへの変換トランスフォーマーであるPix2Structモデルバックボーンを使用し、上記の2つのタスクで事前トレーニングを行います。MatChaの強みを示すために、表の基礎にアクセスできない質問応答や要約のためのチャートやプロットを含むいくつかの視覚言語タスクで微調整します。MatChaは、以前のモデルの性能を大幅に上回り、基礎となるテーブルにアクセスできると仮定する以前の最先端も上回ります。 以下の図では、チャートと作業するための標準的なアプローチであったOCRパイプラインから情報を取り込んだ2つのベースラインモデルを最初に評価します。最初のものはT5に基づき、2番目のものはVisionTaPasに基づきます。また、PaLI-17BとPix2Structのモデル結果を報告します。PaLI-17Bは、多様なタスクでトレーニングされた大型(他のモデルの約1000倍)のイメージプラステキスト・トゥ・テキスト・トランスフォーマーですが、テキストやその他の視覚言語の読み取り能力に限界があります。最後に、Pix2StructとMatChaのモデル結果を報告します。…

検索増強視覚言語事前学習
Google Research Perceptionチームの学生研究者Ziniu Huと研究科学者Alireza Fathiによる投稿 T5、GPT-3、PaLM、Flamingo、PaLIなどの大規模なモデルは、数百億のパラメータにスケーリングされ、大規模なテキストおよび画像データセットでトレーニングされると、多大な量の知識を格納する能力を示しました。これらのモデルは、画像キャプション、ビジュアルクエスチョンアンサリング、オープンボキャブラリー認識などのダウンストリームタスクで最先端の結果を達成しています。しかし、これらのモデルはトレーニングに膨大な量のデータを必要とし、数十億のパラメータ(多くの場合)を持ち、著しい計算要件を引き起こします。また、これらのモデルをトレーニングするために使用されるデータは古くなる可能性があり、世界の知識が更新されるたびに再トレーニングが必要になる場合があります。たとえば、2年前にトレーニングされたモデルは、現在のアメリカ合衆国大統領に関する古い情報を提供する可能性があります。 自然言語処理(RETRO、REALM)およびコンピュータビジョン(KAT)の分野では、検索増強モデルを使用してこれらの課題に取り組む研究がなされてきました。通常、これらのモデルは、単一のモダリティ(テキストのみまたは画像のみ)を処理できるバックボーンを使用して、知識コーパスから情報をエンコードおよび取得します。ただし、これらの検索増強モデルは、クエリと知識コーパスのすべての利用可能なモダリティを活用できず、モデルの出力を生成するために最も役立つ情報を見つけられない場合があります。 これらの問題に対処するために、「REVEAL:Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory」(CVPR 2023に掲載予定)では、複数のソースのマルチモーダル「メモリ」を利用して知識集中型クエリに答えることを学ぶビジュアル言語モデルを紹介します。REVEALは、ニューラル表現学習を使用して、さまざまな知識ソースをキー-バリューペアから成るメモリ構造に変換し、エンコードします。キーはメモリアイテムのインデックスとして機能し、対応する値はそれらのアイテムに関する関連情報を格納します。トレーニング中、REVEALは、キーエンベッディング、値トークン、およびこのメモリから情報を取得する能力を学習して、知識集中型クエリに対処します。このアプローチにより、モデルパラメータは暗記に専念するのではなく、クエリに関する推論に焦点を当てることができます。 多様な知識ソースから複数の知識エントリを取得する能力を持つビジュアル言語モデルを拡張することで、生成を支援します。 マルチモーダル知識コーパスからのメモリ構築 私たちのアプローチは、異なるソースからの知識アイテムのキーと値のエンベッディングを事前に計算し、キー-バリューペアにエンコードして統一された知識メモリにインデックスするREALMと似ています。各知識アイテムは、より詳細に表現されたトークンエンベッディングのシーケンスである値としてエンコードされます。以前の研究とは異なり、REVEALは、WikiData知識グラフ、Wikipediaのパッセージと画像、Web画像テキストペア、ビジュアルクエスチョンアンサリングデータなど、多様なマルチモーダル知識コーパスを活用しています。各知識アイテムは、テキスト、画像、両方の組み合わせ(たとえば、Wikipediaのページ)、または知識グラフからの関係または属性(たとえば、バラク・オバマは6’2 “の背丈)の場合があります。トレーニング中、モデルパラメータが更新されるたびに、REVEALはキーと値のエンベッディングを連続的に再計算します。ステップごとにメモリを非同期に更新します。 圧縮を使用したメモリのスケーリング メモリ値をエンコードするための素朴な解決策は、各知識アイテムのトークンのすべてのシーケンスを保持することです。次に、モデルは、すべてのトークンを連結してトランスフォーマーエンコーダーデコーダーパイプラインに送信することで、入力クエリとトップkの取得されたメモリ値を融合することができます。このアプローチには2つの問題があります。1つ目は、数億の知識アイテムをメモリに保持する場合、各メモリ値が数百のトークンから構成されている場合、実用的ではないことです。2つ目は、トランスフォーマーエンコーダーが自己注意のために合計トークン数×kに対して2次の複雑度を持っていることです。そのため、Perceiverアーキテクチャを使用して知識アイテムをエンコードおよび圧縮することを提案しています。Perceiverモデルは、トランスフォーマーデコーダーを使用して、フルトークンシーケンスを任意の長さに圧縮します。これにより、kが100にもなるトップkメモリエントリを取得できます。 以下の図は、メモリのキー-バリューペアを構築する手順を示しています。各知識項目は、マルチモーダル視覚言語エンコーダを介して処理され、画像とテキストのトークンのシーケンスに変換されます。キー・ヘッドはこれらのトークンをコンパクトな埋め込みベクトルに変換します。バリュー・ヘッド(パーセプター)は、これらのトークンを少なくし、知識項目に関する適切な情報を保持します。 異なるコーパスからの知識エントリを統一されたキーとバリューの埋め込みペアにエンコードし、キーはメモリのインデックスに使用され、値にはエントリに関する情報が含まれます。…

多言語での音声合成の評価には、SQuIdを使用する
Googleの研究科学者Thibault Sellamです。 以前、私たちは1000言語イニシアチブとUniversal Speech Modelを紹介しました。これらのプロジェクトは、世界中の何十億人ものユーザーに音声および言語技術を提供することを目的としています。この取り組みの一部は、多様な言語を話すユーザー向けにVDTTSやAudioLMなどのプロジェクトをベースにした高品質の音声合成技術を開発することにあります。 新しいモデルを開発した後は、生成された音声が正確で自然であるかどうかを評価する必要があります。コンテンツはタスクに関連し、発音は正確で、トーンは適切で、クラックや信号相関ノイズなどの音響アーティファクトはない必要があります。このような評価は、多言語音声システムの開発において大きなボトルネックとなります。 音声合成モデルの品質を評価する最も一般的な方法は、人間の評価です。テキストから音声(TTS)エンジニアが最新のモデルから数千の発話を生成し、数日後に結果を受け取ります。この評価フェーズには、聴取テストが含まれることが一般的で、何十もの注釈者が一つずつ発話を聴取して、自然な音に聞こえるかどうかを判断します。人間はテキストが自然かどうかを検出することでまだ敵わないことがありますが、このプロセスは実用的ではない場合があります。特に研究プロジェクトの早い段階では、エンジニアがアプローチをテストして再戦略化するために迅速なフィードバックが必要な場合があります。人間の評価は費用がかかり、時間がかかり、対象言語の評価者の可用性によって制限される場合があります。 進展を妨げる別の障壁は、異なるプロジェクトや機関が通常、異なる評価、プラットフォーム、およびプロトコルを使用するため、apple-to-applesの比較が不可能であることです。この点で、音声合成技術はテキスト生成に遅れを取っており、研究者らが人間の評価をBLEUや最近ではBLEURTなどの自動評価指標と補完して長年にわたって利用してきたテキスト生成から大きく遅れています。 「SQuId: Measuring Speech Naturalness in Many Languages」でICASSP 2023に発表する予定です。SQuId(Speech Quality Identification)という600Mパラメーターの回帰モデルを紹介します。このモデルは、音声がどの程度自然かを示します。SQuIdは、Googleによって開発された事前学習された音声テキストモデルであるmSLAMをベースにしており、42言語で100万件以上の品質評価をファインチューニングし、65言語でテストされました。SQuIdが多言語の評価において人間の評価を補完するためにどのように使用できるかを示します。これは、今までに行われた最大の公開努力です。 SQuIdによるTTSの評価 SQuIdの主な仮説は、以前に収集された評価に基づいて回帰モデルをトレーニングすることで、TTSモデルの品質を評価するための低コストな方法を提供できるということです。このモデルは、TTS研究者の評価ツールボックスに貴重な追加となり、人間の評価に比べて正確性は劣るものの、ほぼ即時に提供されます。 SQuIdは、発話を入力とし、オプションのロケールタグ(つまり、”Brazilian Portuguese”や”British English”などのローカライズされた言語のバリアント)を指定することができます。SQuIdは、音声波形がどの程度自然に聞こえるかを示す1から5までのスコアを返します。スコアが高いほど、より自然な波形を示します。 内部的には、モデルには3つのコンポーネントが含まれています:(1)エンコーダー、(2)プーリング/回帰層、および(3)完全接続層。最初に、エンコーダーはスペクトログラムを入力として受け取り、1,024サイズの3,200ベクトルを含む小さな2D行列に埋め込みます。各ベクトルは、時間ステップをエンコードします。プーリング/回帰層は、ベクトルを集約し、ロケールタグを追加し、スコアを返す完全接続層に入力します。最後に、アプリケーション固有の事後処理を適用して、スコアを再スケーリングまたは正規化して、自然な評価の範囲である[1、5]の範囲内に収まるようにします。回帰損失で全モデルをエンドツーエンドでトレーニングします。…

Imagen EditorとEditBench:テキストによる画像補完の進展と評価
グーグルリサーチの研究エンジニアであるスー・ワンとセズリー・モンゴメリーによる投稿 過去数年間、テキストから画像を生成する研究は、画期的な進展(特に、Imagen、Parti、DALL-E 2など)を見ており、これらは自然に関連するトピックに浸透しています。特に、テキストによる画像編集(TGIE)は、完全にやり直すのではなく、生成された物と撮影された視覚物を編集する実践的なタスクであり、素早く自動化されたコントロール可能な編集は、視覚物を再作成するのに時間がかかるか不可能な場合に便利な解決策です(例えば、バケーション写真のオブジェクトを微調整したり、ゼロから生成されたかわいい子犬の細かいディテールを完璧にする場合)。さらに、TGIEは、基礎となるモデルのトレーニングを改良する大きな機会を表しています。マルチモーダルモデルは、適切にトレーニングするために多様なデータが必要であり、TGIE編集は高品質でスケーラブルな合成データの生成と再結合を可能にすることができ、おそらく最も重要なことに、任意の軸に沿ってトレーニングデータの分布を最適化する方法を提供できます。 CVPR 2023で発表される「Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting」では、マスクインペインティングの課題に対する最先端の解決策であるImagen Editorを紹介します。つまり、ユーザーが、編集したい画像の領域を示すオーバーレイまたは「マスク」(通常、描画タイプのインターフェイス内で生成されるもの)と共にテキスト指示を提供する場合のことです。また、画像編集モデルの品質を評価する方法であるEditBenchも紹介します。EditBenchは、一般的に使用される粗い「この画像がこのテキストに一致するかどうか」の方法を超えて、モデルパフォーマンスのより細かい属性、オブジェクト、およびシーンについて詳細に分析します。特に、画像とテキストの整合性の信頼性に強い重点を置きつつ、画像の品質を見失わないでください。 Imagen Editorは、指定された領域にローカライズされた編集を行います。モデルはユーザーの意図を意味を持って取り入れ、写真のようなリアルな編集を実行します。 Imagen Editor Imagen Editorは、Imagenでファインチューニングされた拡散ベースのモデルで、編集を行うために改良された言語入力の表現、細かい制御、および高品質な出力を目的としています。Imagen Editorは、ユーザーから3つの入力を受け取ります。1)編集する画像、2)編集領域を指定するバイナリマスク、および3)テキストのプロンプトです。これら3つの入力は、出力サンプルを誘導します。 Imagen Editorは、高品質なテキストによる画像インペインティングを行うための3つの核心技術に依存しています。まず、ランダムなボックスとストロークマスクを適用する従来のインペインティングモデル(例:Palette、Context…

スピードは必要なすべてです:GPU意識の最適化による大規模拡散モデルのオンデバイス加速化
コアシステム&エクスペリエンスのソフトウェアエンジニアであるJuhyun LeeとRaman Sarokinによる投稿 画像生成のための大規模な拡散モデルの普及により、モデルサイズと推論ワークロードは大幅に増加しました。モバイル環境でのオンデバイスML推論には、リソース制約のために緻密なパフォーマンス最適化とトレードオフの考慮が必要です。コスト効率とユーザープライバシーの必要性により、大規模拡散モデル(LDM)のオンデバイスでの実行は、これらのモデルの大幅なメモリ要件と計算要件のために更に大きな課題を提供します。 本稿では、私たちの「速さこそがすべて:GPUによる大規模拡散モデルのオンデバイスアクセラレーションによる最適化」に焦点を当て、モバイルGPU上の基本的なLDMモデルの最適化された実行について述べます。このブログ記事では、Stable Diffusionなどの大規模拡散モデルを高速で実行するために使用した主なテクニックをまとめ、512×512ピクセルのフル解像度で20回イテレーションを行い、蒸留なしでオリジナルモデルの高性能推論速度で12秒未満で実行できるようにしました。前回のブログ記事で述べたように、GPUアクセラレーションされたML推論は、メモリのパフォーマンスに制限されることがよくあります。そして、LDMの実行も例外ではありません。したがって、私たちの最適化の中心テーマは、演算論理ユニットの効率性を優先するものよりも、メモリの入出力(I/O)の効率性であり、ML推論の全体的なレイテンシを減らすことです。 LDMのサンプル出力。プロンプトテキスト:「周りの花と可愛い子犬の写真リアルな高解像度画像」。 メモリ効率のための強化されたアテンションモジュール ML推論エンジンは通常、最適化されたさまざまなML操作を提供します。しかし、各ニューラルネット演算子を実行するためのオーバーヘッドがあるため、最適なパフォーマンスを達成することは依然として難しい場合があります。このオーバーヘッドを緩和するため、ML推論エンジンは、複数の演算子を1つの演算子に統合する広範な演算子フュージョンルールを組み込んで、テンソル要素を横断するイテレーション数を減らすことで、イテレーションあたりの計算を最大限に増やします。たとえば、TensorFlow Liteは、畳み込みのような計算負荷の高い演算と、後続の活性化関数であるReLUのような演算を組み合わせる演算子フュージョンを利用しています。 最適化の明らかな機会は、LDMのデノイザーモデルで採用された頻繁に使用されるアテンションブロックです。アテンションブロックにより、重要な領域に重みを割り当てることで、モデルは入力の特定の部分に焦点を当てることができます。アテンションモジュールを最適化する方法は複数ありますが、以下に説明する2つの最適化のうち、どちらが優れたパフォーマンスを発揮するかに応じて、選択的に1つを使用します。 第1の最適化である部分的にフュージョンされたsoftmaxは、アテンションモジュール内のsoftmaxと行列乗算の間の詳細なメモリ書き込みと読み取りを省略します。アテンションブロックが単純な行列乗算であると仮定すると、Y = softmax(X)* Wの形式で表されます。ここで、XとWはそれぞれa×bおよびb×cの2D行列です(下図参照)。 数値の安定性のために、T= softmax(X)は、通常、3つのパスで計算されます。 リストの最大値を決定し、行ごとに行列Xを計算します 各リスト項目の指数関数と最大値(パス1から)の差を合計します アイテムから最大値を引いた指数関数を、パス2からの合計で除算します これらのパスを単純に実行すると、中間テンソル T に全体のsoftmax関数の出力が格納されるため、巨大なメモリ書き込みが必要になります。パス1と2の結果のみを保存するテクニックを使用することで、m と…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.