Learn more about Search Results CPU - Page 38

- You may be interested
- 「助成金交付における有望なプロジェクト...
- バックフィリングの熟練:データエンジニ...
- DeepSpeedを使用して大規模モデルトレーニ...
- ドメイン固有アプリケーションのためのLLM...
- 「InstagramがAIによって生成されたコンテ...
- 『Re Invent 2023の私のお勧め』
- ランチェーン101:パート2c PEFT、LORA、...
- AIがセキュリティを向上させる方法
- 映像作家のサラ・ディーチシーが今週の「N...
- 「Great Expectationsを始めよう Pythonに...
- 「ヒドラで実験を追跡し続けましょう」
- 「ChatGPTを使用して完全な製品を作成する...
- 「インテルCPU上での安定したディフューシ...
- 「オーディオソース分離のマスターキー:A...
- AlphaDevは、より高速なソートアルゴリズ...
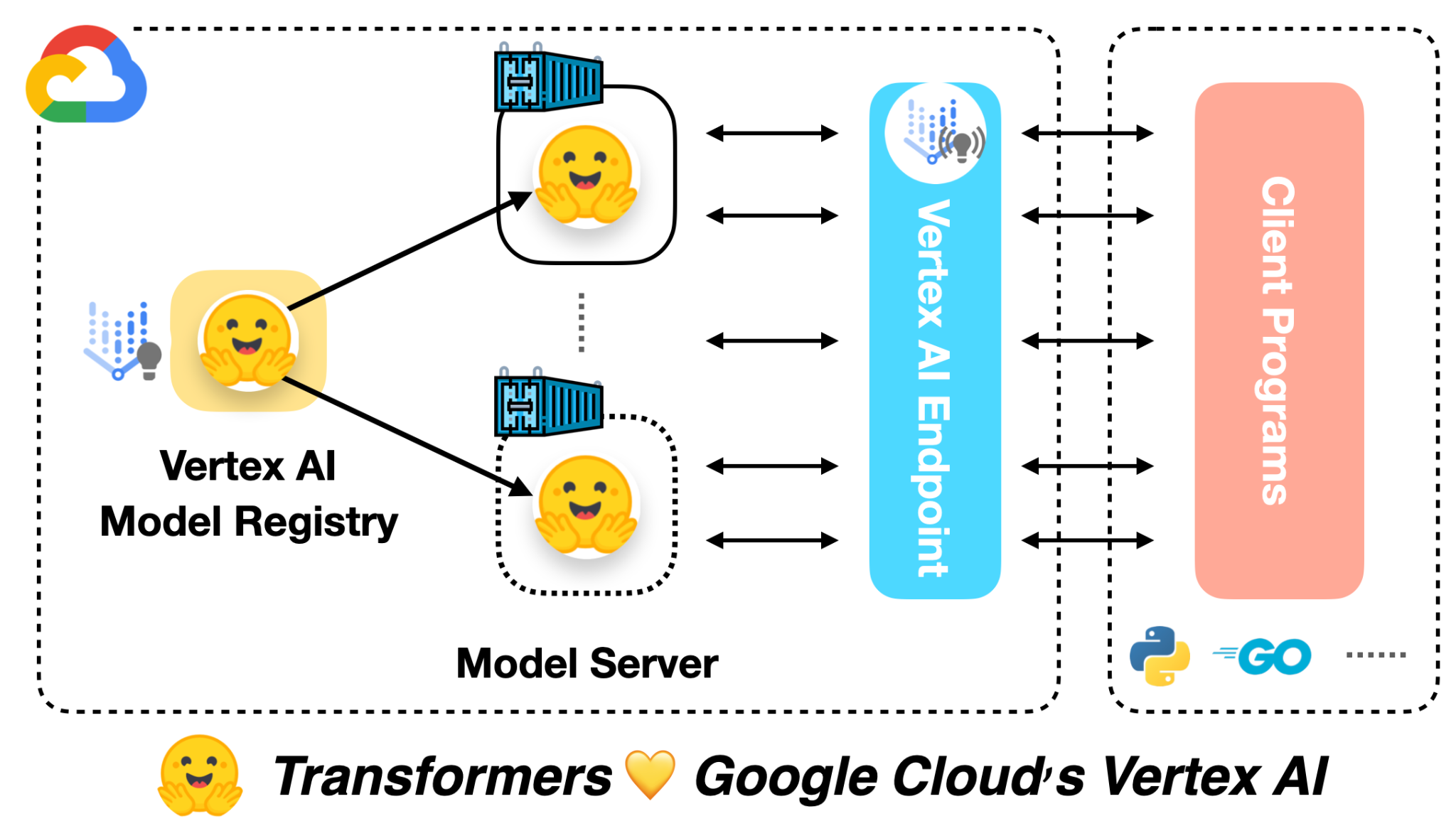
🤗 ViTをVertex AIに展開する
前の投稿では、Vision Transformers(ViT)モデルを🤗 Transformersを使用してローカルおよびKubernetesクラスター上に展開する方法を紹介しました。この投稿では、同じモデルをVertex AIプラットフォームに展開する方法を示します。Kubernetesベースの展開と同じスケーラビリティレベルを実現できますが、コードは大幅に簡略化されます。 この投稿は、上記にリンクされた前の2つの投稿を基に構築されています。まだチェックしていない場合は、それらを確認することをお勧めします。 この投稿の冒頭にリンクされたColab Notebookには、完全に作成された例があります。 Google Cloudによると: Vertex AIは、さまざまなモデルタイプと異なるレベルのMLの専門知識をサポートするツールを提供します。 モデルの展開に関しては、Vertex AIは次の重要な機能を統一されたAPIデザインで提供しています: 認証 トラフィックに基づく自動スケーリング モデルのバージョニング 異なるバージョンのモデル間のトラフィックの分割 レート制限 モデルの監視とログ記録 オンラインおよびバッチ予測のサポート TensorFlowモデルに対しては、この投稿で紹介されるいくつかの既製のユーティリティが提供されます。ただし、PyTorchやscikit-learnなどの他のフレームワークにも同様のサポートがあります。 Vertex AIを使用するには、請求が有効なGoogle Cloud…

Hugging Face TransformersとHabana Gaudiを使用して、BERTを事前に学習する
このチュートリアルでは、Habana GaudiベースのDL1インスタンスを使用してBERT-baseをゼロから事前トレーニングする方法を学びます。Gaudiのコストパフォーマンスの利点を活用するためにAWSで使用します。Hugging Face Transformers、Optimum Habana、およびDatasetsライブラリを使用して、マスクされた言語モデリングを使用してBERT-baseモデルを事前トレーニングします。これは、最初のBERT事前トレーニングタスクの一つです。始める前に、ディープラーニング環境をセットアップする必要があります。 コードを表示する 以下のことを学びます: データセットの準備 トークナイザのトレーニング データセットの前処理 Habana Gaudi上でBERTを事前トレーニングする 注意:ステップ1から3は、CPUを多く使用するタスクのため、異なるインスタンスサイズで実行することができます/すべきです。 要件 始める前に、以下の要件を満たしていることを確認してください DL1インスタンスタイプのクオータを持つAWSアカウント AWS CLIがインストールされていること AWS IAMユーザーがCLIで構成され、ec2インスタンスの作成と管理の権限を持っていること 役立つリソース Hugging Face TransformersとHabana…

🧨ディフューザーを使用した安定した拡散
…🧨 ディフューザーを使用して Stable Diffusionは、CompVis、Stability AI、およびLAIONの研究者とエンジニアによって作成されたテキストから画像への潜在的な拡散モデルです。これは、LAION-5Bデータベースのサブセットから512×512の画像でトレーニングされています。LAION-5Bは現在存在する最大の、自由にアクセス可能な多様性のあるデータセットです。 この記事では、Stable Diffusionと🧨 ディフューザーのライブラリを使用する方法、モデルの動作の説明、およびディフューザーを使用して画像生成パイプラインをカスタマイズする方法について説明します。 注意:ディフュージョンモデルの動作原理を基本的に理解することを強くお勧めします。ディフュージョンモデルが完全に新しいものである場合、次のブログ記事のいずれかを読むことをお勧めします: 注釈付きディフュージョンモデル 🧨 ディフューザーの始め方 それでは、いくつかの画像を生成しましょう 🎨。 Stable Diffusionの実行 ライセンス モデルを使用する前に、モデルのライセンスを受け入れて重みをダウンロードして使用する必要があります。 注意:ライセンスはもはやUIを介して明示的に受け入れる必要はありません。 このライセンスは、このような強力な機械学習システムの潜在的な有害な影響を緩和するために設計されています。ユーザーには、ライセンスを完全かつ注意深く読むことをお願いします。以下に要約を提供します: モデルを意図的に違法または有害な出力やコンテンツの生成や共有に使用することはできません。 生成した出力に対する権利は主張しません。使用は自由であり、使用に関してはライセンスで設定された規定に違反してはならず、その使用については責任があります。 重みを再配布し、モデルを商業的および/またはサービスとして使用することができます。ただし、その場合、ライセンスで設定された使用制限とCreativeML OpenRAIL-Mのコピーをすべてのユーザーに提供する必要があります。…

ディフューザーの新着情報は何ですか?🎨
1か月半前に、モダリティを横断する拡散モデルのためのモジュールツールボックスを提供するdiffusersライブラリをリリースしました。数週間後には、高品質なテキストから画像への変換モデルであるStable Diffusionのサポートを追加し、誰でも無料のデモを試すことができるようにしました。最後の3週間では、チームはライブラリに1つまたは2つの新機能を追加することを決定しました。このブログ投稿では、diffusersバージョン0.3の新機能について概説します!GitHubリポジトリに⭐を付けるのを忘れないでください。 画像から画像へのパイプライン テキストの逆転 インペインティング より小さなGPUに最適化 Mac上で実行 ONNXエクスポーター 新しいドキュメント コミュニティ SD潜在空間での動画生成 モデルの説明可能性 日本語のStable Diffusion 高品質なファインチューニングモデル Stable Diffusionによるクロスアテンション制御 再利用可能なシード 画像から画像へのパイプライン 最も要望の多かった機能の1つは、画像から画像の生成を行うことです。このパイプラインでは、画像とプロンプトを入力すると、それに基づいて画像が生成されます! 公式のColabノートブックに基づいたコードを見てみましょう。 from diffusers import…

Megatron-LMを使用して言語モデルをトレーニングする方法
PyTorchで大規模な言語モデルをトレーニングするには、単純なトレーニングループだけでは不十分です。通常、複数のデバイスに分散しており、安定した効率的なトレーニングのための多くの最適化技術があります。Hugging Face 🤗 Accelerateライブラリは、トレーニングループに非常に簡単に統合できるように、GPUとTPUを跨いで分散トレーニングをサポートするために作成されました。🤗 TransformersもTrainer APIを介して分散トレーニングをサポートしており、トレーニングループの実装を必要とせずにPyTorchでの完全なトレーニングを提供します。 大規模なトランスフォーマーモデルを事前トレーニングするための研究者の間でのもう一つの人気ツールはMegatron-LMです。これはNVIDIAのApplied Deep Learning Researchチームによって開発された強力なフレームワークです。🤗 AccelerateとTrainerとは異なり、Megatron-LMの使用は直感的ではなく、初心者には少し抵抗があるかもしれません。しかし、これはGPU上でのトレーニングに最適化されており、いくつかの高速化を提供することができます。このブログ記事では、Megatron-LMを使用してNVIDIAのGPU上で言語モデルをトレーニングし、それをtransformersと一緒に使用する方法を学びます。 このフレームワークでGPT2モデルをトレーニングするためのさまざまなステップを紹介します。これには以下が含まれます。 環境のセットアップ データの前処理 トレーニング モデルの🤗 Transformersへの変換 なぜMegatron-LMを選ぶのか? トレーニングの詳細に入る前に、他のフレームワークよりもこのフレームワークが効率的である理由を理解しましょう。このセクションは、Megatron-DeepSpeedでのBLOOMトレーニングについての素晴らしいブログから着想を得ています。詳細については参照してください。このブログ記事はMegatron-LMへの優しい入門を提供することを目的としています。 データローダー Megatron-LMには、データがトークン化され、トレーニング前にシャッフルされる効率的なデータローダーが付属しています。また、データは番号付きのシーケンスに分割され、それらは計算が必要な場合にのみ計算されるようにインデックスで保存されます。インデックスを作成するために、エポック数はトレーニングパラメータに基づいて計算され、順序が作成され、その後シャッフルされます。これは通常の場合とは異なり、データセット全体を繰り返し処理してから2番目のエポックのために繰り返すというものです。これにより、学習曲線が滑らかになり、トレーニング中の時間が節約されます。 組み込みCUDAカーネル GPU上で計算を実行する場合、必要なデータはメモリから取得され、計算が実行され、結果がメモリに保存されます。簡単に言えば、組み込みカーネルのアイデアは、通常はPyTorchによって別々に実行される類似の操作を、単一のハードウェア操作に統合することです。そのため、複数の個別の計算で行われるメモリ移動の回数を減らします。以下の図は、カーネルフュージョンのアイデアを示しています。これは、詳細について説明しているこの論文からインスピレーションを受けています。 f、g、hが1つのカーネルで結合された場合、fとgの中間結果x’とy’はGPUレジスタに保存され、hによって即座に使用されます。しかし、フュージョンがない場合、x’とy’はメモリにコピーされ、hによって読み込まれる必要があります。したがって、カーネルフュージョンは計算に著しいスピードアップをもたらします。Megatron-LMはまた、PyTorchの実装よりも高速なApexのFused…

DeepSpeedとAccelerateを使用した非常に高速なBLOOM推論
この記事では、176BパラメータのBLOOMモデルを使用してトークンごとのスループットを非常に高速に取得する方法を紹介します。 モデルは352GBのbf16(bfloat16)ウェイト(176*2)を必要とするため、最も効率的なセットアップは8x80GBのA100 GPUです。また、2x8x40GBのA100または2x8x48GBのA6000も使用できます。これらのGPUを使用する主な理由は、この執筆時点ではこれらのGPUが最大のGPUメモリを提供しているためですが、他のGPUも使用できます。たとえば、24x32GBのV100を使用することもできます。 単一のノードを使用すると、通常、最速のスループットが得られます。なぜなら、ほとんどの場合、ノード内のGPUリンクハードウェアの方がノード間のものよりも速いためですが、常にそうとは限りません。 もしハードウェアがそれほど多くない場合でも、CPUやNVMeのオフロードを使用してBLOOM推論を実行することは可能ですが、もちろん、生成時間は遅くなります。 また、GPUメモリの半分の容量を必要とする8ビット量子化ソリューションについても説明します。これにはBitsAndBytesとDeepspeed-Inferenceライブラリが必要です。 ベンチマーク さらなる遅延なしでいくつかの数値を示しましょう。 一貫性を保つために、この記事のベンチマークはすべて同じ8x80GBのA100ノードで実行され、512GBのCPUメモリを持つJean Zay HPCで行われました。JeanZay HPCのユーザーは、約3GB/sの読み取り速度(GPFS)で非常に高速なIOを利用しています。これはチェックポイントの読み込み時間に重要です。遅いディスクは読み込み時間が遅くなります。特に複数のプロセスでIOを同時に行っている場合はさらに重要です。 すべてのベンチマークは、100トークンの出力を貪欲に生成しています: Generate args {'max_length': 100, 'do_sample': False} 入力プロンプトはわずかなトークンで構成されています。以前のトークンのキャッシュもオンになっています。常にそれらを再計算すると非常に遅くなるためです。 まず、生成の準備が完了するまでにかかった時間(つまり、モデルの読み込みと準備にかかった時間)を見てみましょう: Deepspeed-Inferenceには、事前にシャードされたウェイトリポジトリが付属しており、読み込みに約1分かかります。Accelerateの読み込み時間も優れており、わずか2分です。他のソリューションはここでははるかに遅いです。 読み込み時間は重要であるかどうかは、一度読み込んだら追加の読み込みオーバーヘッドなしに繰り返しトークンを生成できるため、場合によります。 次に、トークン生成の最も重要なベンチマークです。ここでのスループット指標は単純であり、100個の新しいトークンを生成するのにかかった時間を100で割り、バッチサイズで割ったものです。…
SetFit プロンプトなしで効率的なフューショット学習
SetFitは、通常のファインチューニングよりもサンプル効率が高く、ノイズに強いです。 事前学習済みの言語モデルを用いたフューショット学習は、データサイエンティストの悪夢であるほとんどラベルのないデータを扱うための有望な解決策として浮上しています 😱。 Intel LabsとUKP Labとの共同研究を通じて、Hugging FaceはSetFitを紹介できることを嬉しく思っています。SetFitは、Sentence Transformersのフューショットファインチューニングの効率的なフレームワークです。SetFitは少量のラベル付きデータで高い精度を達成します – 例えば、顧客レビュー(CR)感情データセットでクラスごとにわずか8つのラベル付きの例を使用すると、SetFitはフルトレーニングセットの3,000の例でRoBERTa Largeのファインチューニングと競争力を持ちます 🤯! 他のフューショット学習手法と比較して、SetFitにはいくつかの特徴があります: 🗣 プロンプトや口述者不要:フューショットファインチューニングの現在の技術は、例を基に言語モデルに適した形式に変換するための手作りのプロンプトや口述者が必要です。SetFitはプロンプトを一切必要とせず、わずかな数のラベル付きテキスト例から直接豊かな埋め込みを生成します。 🏎 高速トレーニング:SetFitは、高い精度を実現するためにT0やGPT-3のような大規模なモデルを必要としません。そのため、トレーニングと推論の速度は通常1桁以上速くなります。 🌎 多言語対応:SetFitはHubの任意のSentence Transformerと組み合わせて使用できるため、マルチリンガルなチェックポイントをファインチューニングするだけで、複数の言語でテキストを分類することができます。 詳細については、私たちの論文、データ、コードをご覧ください。このブログ投稿では、SetFitの動作方法と独自のモデルをトレーニングする方法について説明します。さあ、始めましょう! どのように動作するのか? SetFitは効率とシンプルさを考慮して設計されています。SetFitはまず、少数のラベル付き例(通常はクラスごとに8または16個)でSentence Transformerモデルをファインチューニングします。次に、ファインチューニングされたSentence…

🤗 Accelerateは、PyTorchのおかげで非常に大規模なモデルを実行する方法です
大規模モデルの読み込みと実行 Meta AIとBigScienceは最近、ほとんどの一般的なハードウェアのメモリ(RAMまたはGPU)に収まらない非常に大きな言語モデルをオープンソース化しました。Hugging Faceでは、私たちの使命の一部として、それらの大きなモデルにアクセスできるようにするためのツールを開発しました。そのため、スーパーコンピュータを所有していなくても、これらのモデルを実行できるようにするためのツールを開発しました。このブログ投稿で選ばれたすべての例は、無料のColabインスタンス(制限付きのRAMとディスク容量)で実行されます。ディスク容量に余裕がある場合は、より大きなチェックポイントを選択することもできます。 ここでは、OPT-6.7Bを実行する方法を示します: import torch from transformers import pipeline # これは基本的なColabインスタンスで動作します。 # もし時間がかかっても待つ時間と十分なディスク容量がある場合は、より大きなチェックポイントを選択してください! checkpoint = "facebook/opt-6.7b" generator = pipeline("text-generation", model=checkpoint, device_map="auto", torch_dtype=torch.float16)…
最適化ストーリー:ブルーム推論
この記事では、bloomをパワーアップする効率的な推論サーバーの裏側について説明します。 数週間にわたり、レイテンシーを5倍削減し(スループットを50倍に増やしました)、このような速度向上を達成するために私たちが経験した苦労やエピックな勝利を共有したかったです。 さまざまな人々が多くの段階で関与していたため、ここではすべてをカバーすることはできません。また、最新のハードウェア機能やコンテンツが定期的に登場するため、一部の内容は古くなっているか、まったく間違っている可能性があることをご了承ください。 もし、お好みの最適化手法が議論されていなかったり、正しく表現されていなかったりした場合は、お詫び申し上げます。新しいことを試してみたり、間違いを修正するために、ぜひお知らせください。 言うまでもなく、まず大きなモデルが最初にアクセス可能でなければ、それを最適化する理由はありません。これは、多くの異なる人々によってリードされた信じられないほどの取り組みでした。 トレーニング中にGPUを最大限に活用するために、いくつかの解決策が検討され、結果としてMegatron-Deepspeedが最終的なモデルのトレーニングに選ばれました。これは、コードがそのままではtransformersライブラリと互換性がない可能性があることを意味します。 元のトレーニングコードのため、通常行っていることの1つである既存のモデルをtransformersに移植することに取り組みました。目標は、トレーニングコードから関連する部分を抽出し、transformers内に実装することでした。この取り組みには「Younes」が取り組みました。これは、1ヶ月近くかかり、200のコミットが必要でした。 後で戻ってくるいくつかの注意点があります: 小さなモデルbigscience/bigscience-small-testingとbigscience/bloom-560mを用意する必要があります。これは非常に重要です。なぜなら、それらと一緒に作業するとすべてが高速化されるからです。 まず、最後のログがバイトまで完全に同じになることを望むことをあきらめる必要があります。PyTorchのバージョンがカーネルを変更し、微妙な違いを導入する可能性があり、異なるハードウェアでは異なるアーキテクチャのため異なる結果が得られる場合があります(コストの理由から常にA100 GPUで開発したくはないでしょう)。 すべてのモデルにとって、良い厳格なテストスイートを作ることは非常に重要です 私たちが見つけた最高のテストは、固定された一連のプロンプトを持つことでした。プロンプトを知っており、決定論的な結果が得られる必要があります。2つの生成物が同じであれば、小さなログの違いは無視できます。ドリフトが見られるたびに調査する必要があります。それは、あなたのコードがやるべきことをしていないか、または実際にそのモデルがドメイン外であるためにノイズに対してより敏感であるかのいずれかです。いくつかのプロンプトと十分に長いプロンプトがあれば、すべてのプロンプトを誤ってトリガーする可能性は低くなります。プロンプトが多ければ多いほど良く、プロンプトが長ければ長いほど良いです。 最初のモデル(small-testing)は、bloomと同じようにbfloat16であり、すべてが非常に似ているはずですが、それほどトレーニングされていないか、うまく機能しないため、出力が大きく変動します。そのため、これらの生成テストに問題がありました。2番目のモデルはより安定していましたが、bfloat16ではなくfloat16でトレーニングおよび保存されていました。そのため、2つの間にはエラーの余地があります。 完全に公平を期すために言えば、bfloat16→float16への変換は推論モードでは問題なさそうです(bfloat16は主に大きな勾配を扱うために存在しません)。 このステップでは、重要なトレードオフが発見され、実装されました。bloomは分散環境でトレーニングされたため、一部のコードはLinearレイヤー上でテンソル並列処理を行っており、単一のGPU上で同じ操作を実行すると異なる結果が得られていました。これを特定するのにかなりの時間がかかり、100%の準拠を選択した場合、モデルの速度が遅くなりましたが、少しの差がある場合は実行が速く、コードがシンプルになりました。設定可能なフラグを選択しました。 注:この文脈でのパイプライン並列処理(PP)は、各GPUがいくつかのレイヤーを所有し、各GPUがデータの一部を処理してから次のGPUに渡すことを意味します。 これで、動作可能なtransformersのクリーンなバージョンがあり、これに取り組むことができます。 Bloomは352GB(176Bパラメーターのbf16)のモデルであり、それに合わせるために少なくともそれだけのGPU RAMが必要です。一時的に小さなマシンでCPUにオフロードすることを検討しましたが、推論速度が桁違いに遅くなるため、それを取り下げました。 次に、基本的にはパイプラインを使用したかったのです。つまり、ドッグフーディングであり、これがAPIが常に裏で使用しているものです。 ただし、pipelinesは分散意識がありません(それがその目的ではありません)。オプションを簡単に話し合った後、新しく作成されたdevice_map="auto"を使用してモデルのシャーディングを管理するためにaccelerateを使用することにしました。いくつかのバグを修正し、transformersのコードを修正してaccelerateが正しい仕事をするのを助ける必要がありました。 これは、transformersのさまざまなレイヤーを分割し、各GPUにモデルの一部を与えて動作させることで機能します。つまり、GPU0が作業を行い、次にGPU1に引き渡し、それ以降同様に行います。 最終的には、上に小さなHTTPサーバーを置くことで、bloom(大規模なモデル)を提供できるようになりました!…

🧨 JAX / Flax での安定した拡散!
🤗 Hugging Face Diffusersはバージョン0.5.1からFlaxをサポートしています!これにより、Colab、Kaggle、またはGoogle Cloud PlatformなどのGoogle TPU上での超高速な推論が可能になります。 この投稿では、JAX / Flaxを使用して推論を実行する方法を示します。Stable Diffusionの動作詳細やGPUでの実行方法について詳細を知りたい場合は、このColabノートブックを参照してください。 一緒に進める場合は、上のボタンをクリックしてこの投稿をColabノートブックとして開きます。 まず、TPUバックエンドを使用していることを確認してください。このノートブックをColabで実行している場合は、上のメニューでランタイムを選択し、「ランタイムのタイプを変更」オプションを選択し、ハードウェアアクセラレータの設定でTPUを選択します。 JAXはTPUに限定されているわけではありませんが、TPUサーバーごとに8つのTPUアクセラレータが並列に動作するため、そのハードウェア上で輝きます。 セットアップ import jax num_devices = jax.device_count() device_type = jax.devices()[0].device_kind print(f"Found…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.