Learn more about Search Results 参考文献 - Page 38

- You may be interested
- In Japanese, the title would be written...
- 統計的推定と推論の初心者向け解説
- Q&A:ブラジルの政治、アマゾンの人権...
- 「PandasAIを用いたデータ分析における生...
- 「BERTをゼロからトレーニングする究極の...
- 「時系列分析を用いた回帰モデルの頑健性...
- 「あなたのLLM + Streamlitアプリケーショ...
- 初心者のための2023年の機械学習論文の読み方
- 未来に響く:NVIDIAとAmdocsが世界の電信...
- 話してください:モデルが読み取る単語の...
- インクから洞察:ブックショップの分析を...
- 「ビルドの学び方 — Towards AI コミュニ...
- 「AIは医療現場でどのような役割を果たす...
- 「推薦システムにおける二つのタワーモデ...
- コンピュータ芸術の先駆者、ヴェラ・モル...
トランスフォーマーにおける対比的探索を用いた人間レベルのテキスト生成 🤗
1. 紹介: 自然言語生成(テキスト生成)は自然言語処理(NLP)の中核的なタスクの一つです。このブログでは、現在の最先端のデコーディング手法であるコントラスティブサーチを神経テキスト生成のために紹介します。コントラスティブサーチは、元々「A Contrastive Framework for Neural Text Generation」[1]([論文] [公式実装])でNeurIPS 2022で提案されました。さらに、この続編の「Contrastive Search Is What You Need For Neural Text Generation」[2]([論文] [公式実装])では、コントラスティブサーチがオフザシェルフの言語モデルを使用して16の言語で人間レベルのテキストを生成できることが示されています。 [備考] テキスト生成に馴染みのないユーザーは、このブログ記事を詳しくご覧ください。 2.…

24GBのコンシューマーGPUでRLHFを使用して20B LLMを微調整する
私たちは、trlとpeftの統合を正式にリリースし、Reinforcement Learningを用いたLarge Language Model (LLM)のファインチューニングを誰でも簡単に利用できるようにしました!この投稿では、既存のファインチューニング手法と競合する代替手法である理由を説明します。 peftは一般的なツールであり、多くのMLユースケースに適用できますが、特にメモリを多く必要とするRLHFにとって興味深いです! コードに直接深く入りたい場合は、TRLのドキュメンテーションページで直接例のスクリプトをチェックしてください。 イントロダクション LLMとRLHF 言語モデルとRLHF(Reinforcement Learning with Human Feedback)を組み合わせることは、ChatGPTなどの非常に強力なAIシステムを構築するための次の手段として注目されています。 RLHFを用いた言語モデルのトレーニングは、通常以下の3つのステップを含みます: 1- 特定のドメインまたは命令のコーパスで事前学習されたLLMをファインチューニングする 2- 人間によって注釈付けされたデータセットを収集し、報酬モデルをトレーニングする 3- ステップ1で得られたLLMを報酬モデルとデータセットを用いてRL(例:PPO)でさらにファインチューニングする ここで、ベースとなるLLMの選択は非常に重要です。現時点では、多くのタスクに直接使用できる「最も優れた」オープンソースのLLMは、命令にファインチューニングされたLLMです。有名なモデルとしては、BLOOMZ、Flan-T5、Flan-UL2、OPT-IMLなどがあります。これらのモデルの欠点は、そのサイズです。まともなモデルを得るには、少なくとも10B+スケールのモデルを使用する必要がありますが、モデルを単一のGPUデバイスに合わせるだけでも40GBのGPUメモリが必要です。 TRLとは何ですか? trlライブラリは、カスタムデータセットとトレーニングセットアップを使用して、誰でも簡単に自分のLMをRLでファインチューニングできるようにすることを目指しています。他の多くのアプリケーションの中で、このアルゴリズムを使用して、ポジティブな映画のレビューを生成するモデルをファインチューニングしたり、制御された生成を行ったり、モデルをより毒性のないものにしたりすることができます。…

大規模なネアデデュープリケーション:BigCodeの背後に
対象読者 大規模な文書レベルの近似除去に興味があり、ハッシュ、グラフ、テキスト処理のいくつかの理解を持つ人々。 動機 モデルにデータを供給する前にデータをきちんと扱うことは重要です。古い格言にあるように、ゴミを入れればゴミが出てきます。データ品質があまり重要ではないという幻想を作り出す見出しをつかんでいるモデル(またはAPIと言うべきか)が増えるにつれて、それがますます難しくなっています。 BigScienceとBigCodeの両方で直面する問題の1つは、ベンチマークの汚染を含む重複です。多くの重複がある場合、モデルはトレーニングデータをそのまま出力する傾向があることが示されています[1](ただし、他のドメインではそれほど明確ではありません[2])。また、重複はモデルをプライバシー攻撃に対しても脆弱にする要因となります[1]。さらに、重複除去の典型的な利点には以下があります: 効率的なトレーニング:トレーニングステップを少なくして、同じかそれ以上のパフォーマンスを達成できます[3][4]。 データ漏洩とベンチマークの汚染を防ぐ:ゼロでない重複は評価を信用できなくし、改善という主張が偽りになる可能性があります。 アクセシビリティ:私たちのほとんどは、何千ギガバイトものテキストを繰り返しダウンロードまたは転送する余裕がありません。固定サイズのデータセットに対して、重複除去は研究、転送、共同作業を容易にします。 BigScienceからBigCodeへ 近似除去のクエストに参加した経緯、結果の進展、そして途中で得た教訓について最初に共有させてください。 すべてはBigScienceがすでに数ヶ月前に始まっていたLinkedIn上の会話から始まりました。Huu Nguyenは、私のGitHubの個人プロジェクトに気付き、BigScienceのための重複除去に取り組むことに興味があるかどうか私に声をかけました。もちろん、私の答えは「はい」となりましたが、データの膨大さから単独でどれだけの努力が必要になるかは全く無知でした。 それは楽しくも挑戦的な経験でした。その大規模なデータの研究経験はほとんどなく、みんながまだ信じていたにもかかわらず、何千ドルものクラウドコンピュート予算を任せられるという意味で挑戦的でした。はい、数回マシンをオフにしたかどうかを確認するために寝床から起きなければならなかったのです。その結果、試行錯誤を通じて仕事を学びましたが、それによってBigScienceがなければ絶対に得られなかった新しい視点が開かれました。 さらに、1年後、私は学んだことをBigCodeに戻して、さらに大きなデータセットで作業をしています。英語向けにトレーニングされたLLMに加えて、重複除去がコードモデルの改善につながることも確認しました[4]。さらに、はるかに小さなデータセットを使用しています。そして今、私は学んだことを、親愛なる読者の皆さんと共有し、重複除去の視点を通じてBigCodeの裏側で何が起こっているかを感じていただければと思います。 興味がある場合、BigScienceで始めた重複除去の比較の最新バージョンをここで紹介します: これはBigCodeのために作成したコードデータセット用のものです。データセット名が利用できない場合はモデル名が使用されます。 MinHash + LSHパラメータ( P , T , K…

🐶セーフテンソルは、本当に安全であり、デフォルトの選択肢として採用されました
Hugging Faceは、EleutherAIとStability AIとの緊密な協力のもと、safetensorsライブラリの外部セキュリティ監査を依頼しました。その結果、これらの組織はすべてライブラリを保存モデルのデフォルト形式にするために進むことができます。 Trail of Bitsによって実施されたセキュリティ監査の詳細な結果は、こちらでご覧いただけます: レポート。 以下のブログ投稿では、このライブラリの起源、この監査結果の重要性、および次のステップについて説明します。 safetensorsとは何ですか? 🐶 safetensorsは、最も一般的なフレームワーク(PyTorch、TensorFlow、JAX、PaddlePaddle、NumPyなど)でテンソルを保存およびロードするためのライブラリです。 具体的な説明のために、PyTorchを使用します。 import torch from safetensors.torch import load_file, save_file weights = {"embeddings": torch.zeros((10, 100))}…
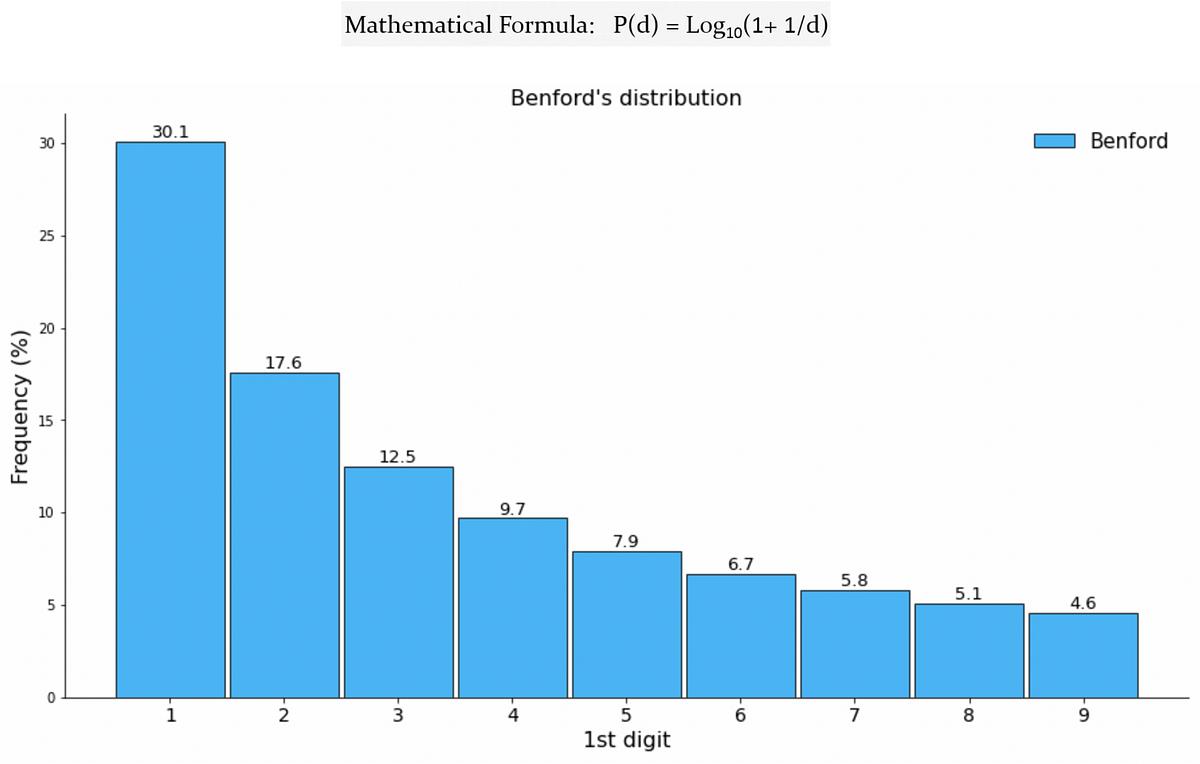
Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
ソーシャルメディアの広大なデジタル領域において、ユーザーの真正性は最も重要な懸念事項ですTwitterなどのプラットフォームが成長するにつれ、フェイクアカウントの増加も増えていますこれらのアカウントは本物のアカウントを模倣します

ドレスコードの解読👗 自動ファッションアイテム検出のためのディープラーニング
電子商取引の活気ある世界では、ファッション業界は独自のランウェイですしかし、もし我々がこのランウェイのドレスコードを、デザイナーの目ではなく、ディープラーニングの精度で解読できるとしたら...
Pythonを使った感情分析(Sentiment Analysis)のFlair
シリーズ記事の次のブログへようこそ!今日は、感情分析のためのPythonライブラリで使用される方法の1つであるFlairを探求しますFlairは、NLP(自然言語処理)ライブラリです...

MLモデルのパッケージング【究極のガイド】
機械学習モデルを数週間または数カ月かけて構築したことがありますか?そして、後でそれを本番環境に展開するのが複雑で時間がかかることがわかりましたか?または、モデルの複数のバージョンを管理し、展開に必要な依存関係と設定をすべて追跡するのに苦労しましたか?もし頷いているのであれば、...
実験追跡ツールの構築方法[Neptuneのエンジニアの学びから]
あなたのチームのMLOpsエンジニアとして、よくMLプラットフォームに機能を追加したり、データサイエンティストが利用するためのスタンドアロンツールを構築することで、彼らのワークフローを改善するように依頼されることがあります実験トラッキングはそのような機能の一つですそして、この記事を読んでいるのであれば、あなたがサポートしているデータサイエンティストはおそらく...

エンドツーエンドのMLパイプラインの構築方法
コミュニティ内のMLエンジニアから最もよく聞かれる不満の1つは、モデルの構築と展開のMLワークフローを手動で行うことがどれだけ費用がかかり、エラーが発生しやすいかということです彼らはトレーニングデータを前処理するためにスクリプトを手動で実行し、展開スクリプトを再実行し、モデルを手動で調整し、働く時間を費やします...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.