Learn more about Search Results ML - Page 382

- You may be interested
- AIは人間過ぎるようになったのでしょうか...
- 「NOAAの古い地球観測衛星が「延長寿命」...
- 「SnapLogicがAmazon Bedrockを使用してテ...
- 「トップAIベースのアートインペインティ...
- ソウルでのオーケストラ指揮者として、ロ...
- クラウドソーシングされたフィードバック...
- 「衛星画像のための基礎モデル」
- 「大規模な言語モデルの公正な評価に向けて」
- ハイパーパラメータ最適化のためのトップ...
- 「生成的なAIアプリケーションと3D仮想世...
- 北京大学の研究者は、FastServeを紹介しま...
- ChatGPTはデータサイエンティストを置き換...
- 「なぜ私がAIの博士課程をやめたのか」
- 「DeepMindの研究者たちは、AlphaStar Unp...
- AudioSep 記述するすべてを分離する

あなたのLLMアプリケーションは公開に準備ができていますか?
大規模言語モデル(LLM)は、現代の自然言語処理アプリケーションにおいてパンとバターとなり、固有表現認識モデルなどのより専門的なツールの多様性を多くの面で置き換えています

データサイエンティストのための必須ガイド:探索的データ分析
データを完全に理解するためのベストプラクティス、技術、ツール

フロントエンド開発のトレンド
最先端の進歩や最高水準のイノベーションが、現在ウェブ開発の世界を形作っている様子について、私たちと一緒に深く掘り下げてみませんか

量子AI:量子コンピューティングの潜在能力を機械学習で解き明かす
この記事では、量子機械学習について、現在の課題、機会、評価、成熟度、およびタイムリーさについて、読者がより詳しく学ぶことができます

このGoogleのAI論文は、さまざまなデバイスで大規模な拡散モデルを実行するために画期的なレイテンシー数値を集めるための一連の最適化を提示しています
モデルのサイズと推論ワークロードは、画像生成のための大規模な拡散モデルが一般的になったために急激に増加しています。リソースの限界により、モバイルコンテキストにおけるオンデバイスML推論のパフォーマンス最適化はデリケートなバランスアクトです。これらのモデルのかなりのメモリ要件と計算要件のため、デバイス上で大規模な拡散モデル(LDM)の推論を実行することは、コスト効率とユーザープライバシーの必要性を考慮すると、さらに大きな障壁を生じます。 基礎モデルの迅速な作成と広範な使用は、人工知能を完全に変革しました。その多様性と写真のようなリアルな画像を生成する能力から、大規模な拡散モデルは多くの注目を集めています。サーバーコストの削減、オフライン機能、強化されたユーザープライバシーは、これらのモデルをユーザーのデバイスにローカルに展開することの利点の一部にすぎません。デバイス上の計算およびメモリリソースの制限により、典型的な大規模な拡散モデルには10億以上のパラメータがあり、困難が生じます。 Googleの研究者たちは、モバイルデバイスにおけるGPUを使用した最速の推論レイテンシを可能にする大規模な拡散モデルの実装の一連の変更を提供しています。これらの更新により、さまざまなデバイスで全体的なユーザーエクスペリエンスが向上し、生成AIの利用範囲が拡大します。 低レイテンシ、強化されたプライバシー、大規模なスケーラビリティなど、サーバーベースの方法に比べて多くの利点を持つオンデバイスモデル推論アクセラレーションは、最近注目を集めています。深層学習で頻繁に使用されるsoftmax演算の複雑さは、さまざまな加速戦略を生み出す動機となっています。ウィノグラード畳み込みは、必要な乗算の数を最小限に抑えることにより、畳み込み計算の効率を向上させるために開発されました。これは、グラフィックス処理ユニット(GPU)にとって特に役立ちます。 Transformerデザインの広範な成功と採用は、注意メカニズムの高速化に関する研究を引き起こしました。 Reformerは、計算コストを削減するために疎な近似を使用し、他の作品は低ランクまたは近似テクニックの組み合わせを使用しています。 FlashAttentionは、ハードウェア構成を考慮した正確な注意アルゴリズムであり、より良いパフォーマンスを実現するために使用されます。 主な焦点は、大規模な拡散モデルを使用して書かれた説明からビジュアルを作成するという課題にあります。提案された改善内容がStable Diffusionアーキテクチャとどのように機能するかに焦点が当てられているにもかかわらず、これらの最適化は他の大規模な拡散モデルにも簡単に転送できることは重要です。テキストからの推論は、逆拡散プロセスを誘導するために、望ましいテキストの説明に基づく追加の調整が必要です。 LDMのノイズリダクションモデルで広く使用される注意ブロックは、改善の主要な領域を示しています。モデルは、入力に注意ブロックの重みをより与えることで、関連する情報に絞り込むことができます。注意モジュールは、複数の方法で最適化することができます。以下に詳細を記載された2つの最適化のうち、どちらが最良の結果をもたらすかに応じて、研究者は通常1つだけを利用します。 最初の最適化である部分的に融合されたsoftmaxは、行列の乗算と統合することにより、注意モジュールのsoftmax中に読み取られ、書き込まれるメモリ量を減らします。もう1つの微調整では、I/Oに配慮した正確な注意方法であるFlashAttentionを使用します。 GPUからの高帯域幅メモリアクセスの数を減らすことで、メモリ帯域幅の制限があるアプリケーションには優れた選択肢です。多数のレジスタが必要であり、彼らは、この方法が特定のサイズのSRAMに対してのみ機能することを発見しました。したがって、彼らは特定のサイズの注意行列に対して、一部のGPUでのみこの方法を使用します。 さらに、チームは、LDMの一般的に使用されるレイヤーやユニットの融合ウィンドウが、商用GPUアクセラレートML推論エンジンで現在使用可能なものよりもはるかに大きくなければならないことが判明しました。標準的な融合ルールの制限を考慮して、彼らは、より幅広い種類のニューラルオペレータを実行できるカスタム実装を考案しました。彼らの注意は、ガウス誤差線形ユニット(GELU)とグループ正規化層の2つのサブフィールドに向けられました。 モデルファイルサイズの制限、大量のランタイムメモリ要件、および長時間の推論レイテンシは、デバイス自体での大規模なモデルのML推論を行う際の重要な障害となっています。研究者は、メモリ帯域幅の使用が主要な制約であることを認識しました。したがって、ALU /メモリ効率比を健全に保ちながら、メモリ帯域幅の利用を改善することに焦点を当てました。彼らが実証した最適化は、記録的なレイテンシ値を持つさまざまなデバイスで大規模な拡散モデルを実行することを可能にしました。これらの改善により、モデルの適用範囲が拡大し、幅広いデバイスでユーザーエクスペリエンスが向上しました。
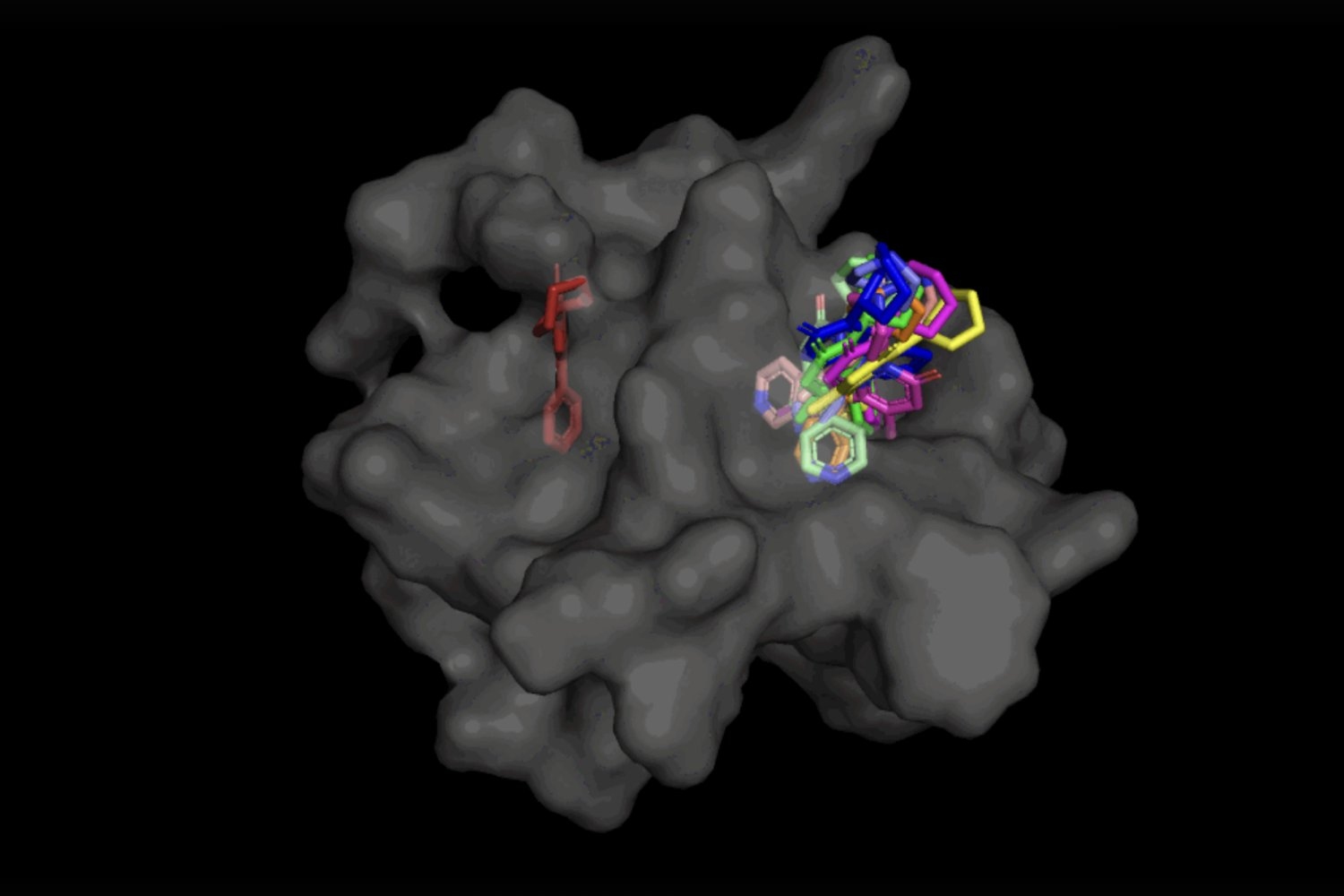
拡散生成モデルによる医薬品発見の加速化
MITの研究者たちは、DiffDockというモデルを構築しましたこのモデルは、いつか従来の方法よりも速く新しい薬剤を見つけ、副作用の可能性を低減することができるかもしれません

Pythonで絶対に犯してはいけない10の失敗
Pythonを学び始めると、多くの場合、悪い習慣に遭遇することがありますこの記事では、Python開発者としてのレベルを上げるためのベストプラクティスを学びます私が覚えているのは、私が...
ChatGPT:ウェブデザイナーの視点
もし最新のニュースやトレンドについて常にアップデートしているのであれば、おそらく「ChatGPT」という言葉とその成功について耳にしたことがあるでしょう簡単に言えば、ChatGPTとは人工知能のことです

GitHubトピックススクレイパー | PythonによるWebスクレイピング
「GitHub Topics Scraper」このプロジェクトは、GitHub Topicsページから情報を取得し、リポジトリ名と詳細を抽出することを目的としています

銀行業界と金融業界におけるAIの台頭:ユースケースとアプリケーション
人工知能(AI)は、様々な産業において革新的な技術として現れ、銀行業界も例外ではありません近年、銀行はAIを採用して、…を強化しています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.